
In March 2026, Yann LeCun raised $1 billion in Paris. Not to build another LLM. To build a different architecture, based on world models and latent-space learning, on the thesis that today's GPTs are a structural dead end. The largest seed round ever raised in Europe. (!)
Why? Ask an LLM a problem it knows how to solve. Change a few variables, its behavior will change and may fail. Teach it something over a conversation, open a new session, everything is lost. Fine-tune it on a domain, it gets good on that domain and forgets part of what it knew before.
Each symptom has a name in the literature: reformulation brittleness, lack of persistent memory, catastrophic forgetting. They all have the same cause: LLMs don't sleep.
In 1995, McClelland, McNaughton and O'Reilly published a paper on memory that remains, thirty years later, the most useful frame for understanding what LLMs lack. Complementary Learning Systems (CLS).
The idea: A single learning system cannot simultaneously learn specific events fast and extract stable regularities slowly.
If you try, each new piece of information overwrites the previous ones. This was called “catastrophic interference” in the 80s already. The brain solves it with two distinct structures:
Our Hippocampus. Fast store. Encodes an episode in a single pass. Sparse, near-orthogonal representations, so two distinct memories don't interfere. Limited retention: days, weeks. Stores the what-where-when.
Our Neocortex. Slow store. Gradual updates over thousands of examples. Distributed, overlapping representations, which is what enables generalization. Near-permanent retention. Stores concepts, schemas, rules.
And between the two: sleep.
During slow-wave sleep, the hippocampus replays recent episodes to the neocortex. Not a copy: a replay. The cortex receives these replays in small doses, adjusts its weights gradually, extracts recurring patterns, ignores noise. It does not overwrite what it already knew, because the updates are small and interleaved with old material replayed from its own representations.
That is why you learn a new face today, see fifty more tomorrow, and still recognize the first one three months later. No conflict between fast and slow. Because they are two systems, not one.
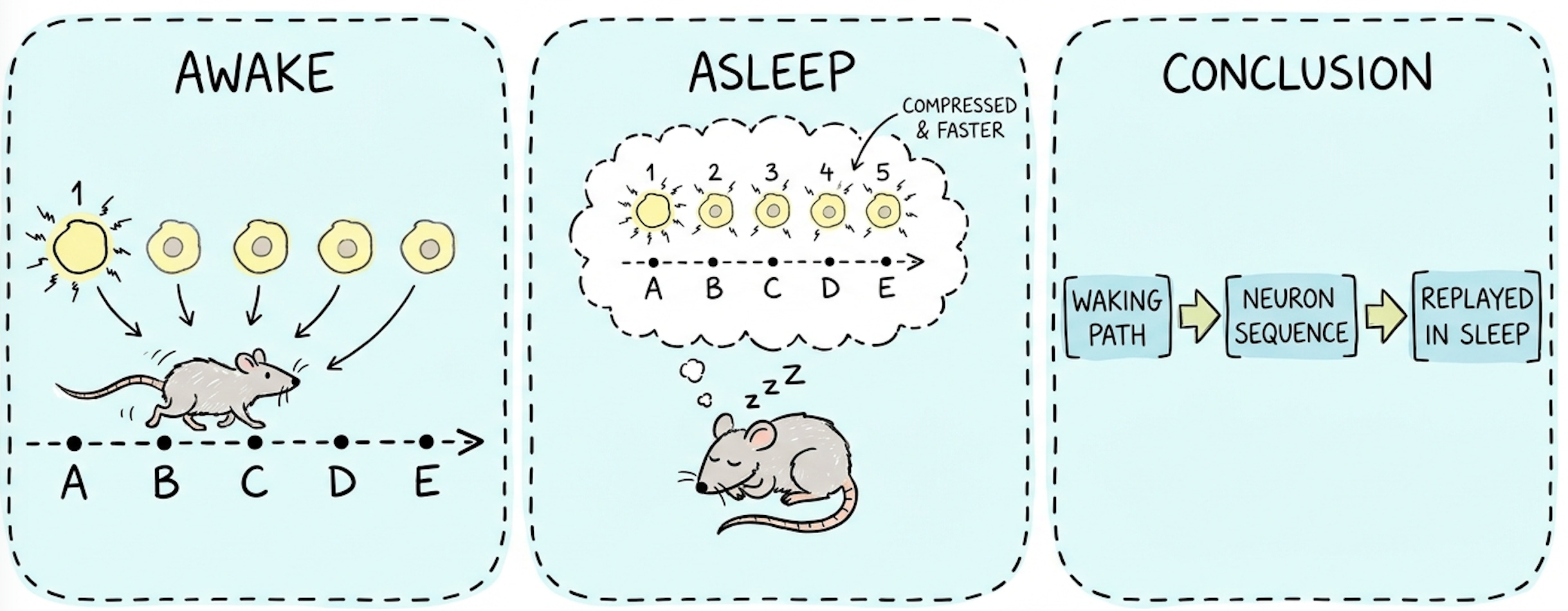
TLDR: You learn because you sleep. Not because you see examples. Because you replay them afterward offline, in a state where the system has nothing else to do but digest.
A modern transformer is the cortex part only. A slow system that learns through gradient descent over many (billions) examples, with distributed representations.
This suffers from:
catastrophic forgetting as soon as you fine-tune
impossible to learn a new fact without thousands of exposures
no way to remember a past interaction beyond the context window
no retrievable episodes
RAG and custom memory systems try to patch this. A vector store plus retrieval is passive storage with fast access. It is not a hippocampus. A real hippocampus encodes episodes (not documents chunked up), indexes temporally, and consolidates into the cortex: the episodes end up modifying the cortex's weights, not just being replayed in read-only mode. RAG is a hack.
Second missing piece, more subtle: LLMs also have no real latent state in the RL sense.
Quick explanation: in proper RL, an agent maintains a compressed internal representation of "where it is" on its trajectory. Not the raw observations: the state. Two identical observations in different contexts can correspond to very different states, and it is on the state that decisions and values are computed.
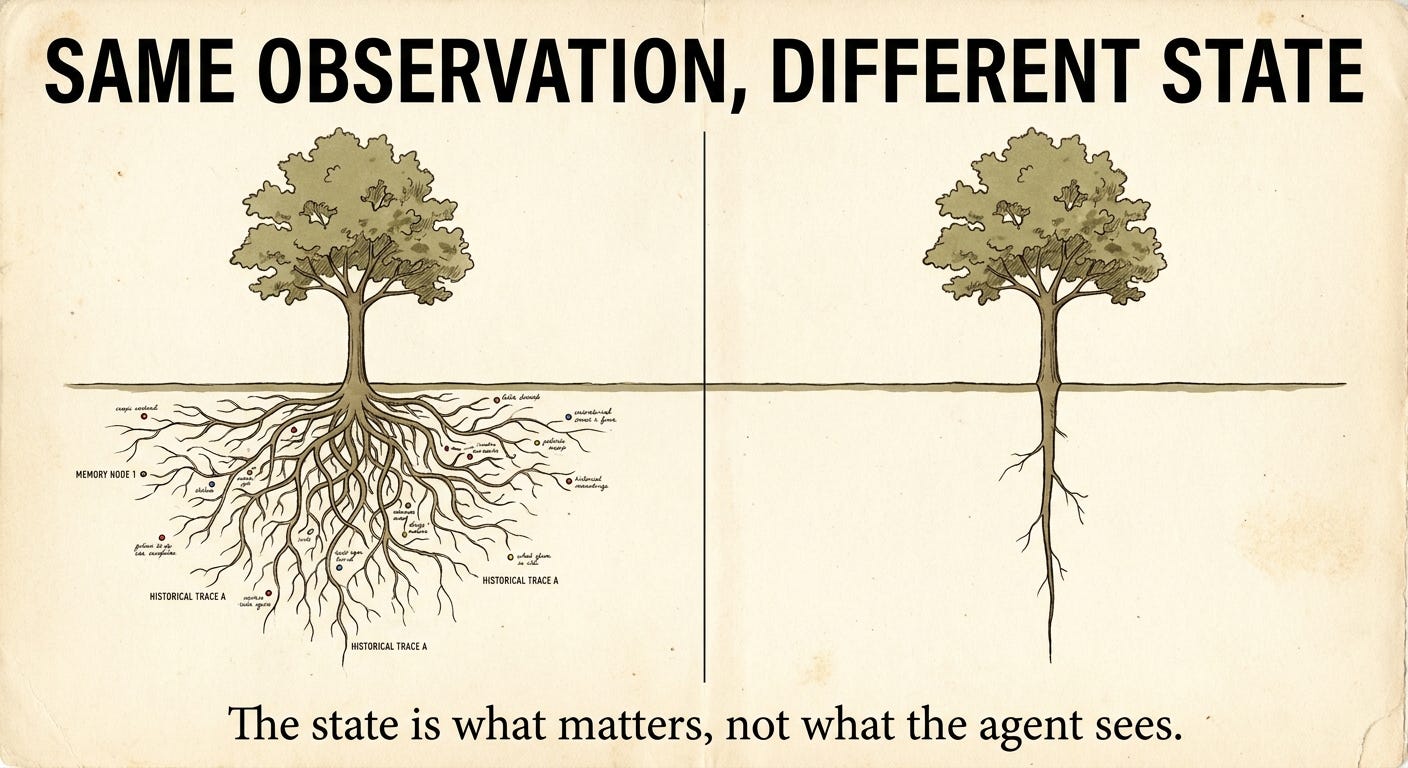
Transformers do have hidden states. Internal vectors. But they were optimized to predict the next token, not to represent the reasoning situation. It is not the same object. That is why a value function computed on these hidden states works poorly: the substrate was not designed to carry value.
e.g. oscillation: you ask a model to fix bug A, it fixes A by introducing B. You flag B, it reintroduces A. Why? Because the model has no internal state encoding "I already tried this direction and it broke something else." It reprocesses each step locally, at the token surface.
The problems have already been studied quite well. Below are all the components that will eventually form this new type of model:
Dual memory. A fast, differentiable store you write to immediately and read via attention. Slow weights that only move during offline windows. DeepMind prototyped this kind of architecture as early as 2017, Google has published several variants since.
Offline consolidation windows. During the window, the model is frozen on the inference side; it replays curated episodes from the fast store into the slow weights. That is what sleep does. No weight updates live during inference. It is both a technical property (stability) and a safety property (intervention point).
Multi-objective replay curator. Which episodes get replayed? Not just the ones with the highest value, but the surprising ones, where the model was wrong, where there is something to learn, and the relevant ones, tied to the current task. Curiosity is high weight on surprise. Focus is high weight on relevance. Fear is high weight on the negative side of value. What we call emotions.
Value function on latent state, not tokens. This presumes you construct an explicit latent state, an internal representation of the reasoning distinct from the generated token sequence. You compute value on that state, not on the textual surface. Architecturally, it is close to what model-based RL has been doing for a few years, adapted to language. Early publications in this direction in late 2024. Still embryonic.
Next, five “simple” capabilities where humans beat LLMs, you’ll be surprised:
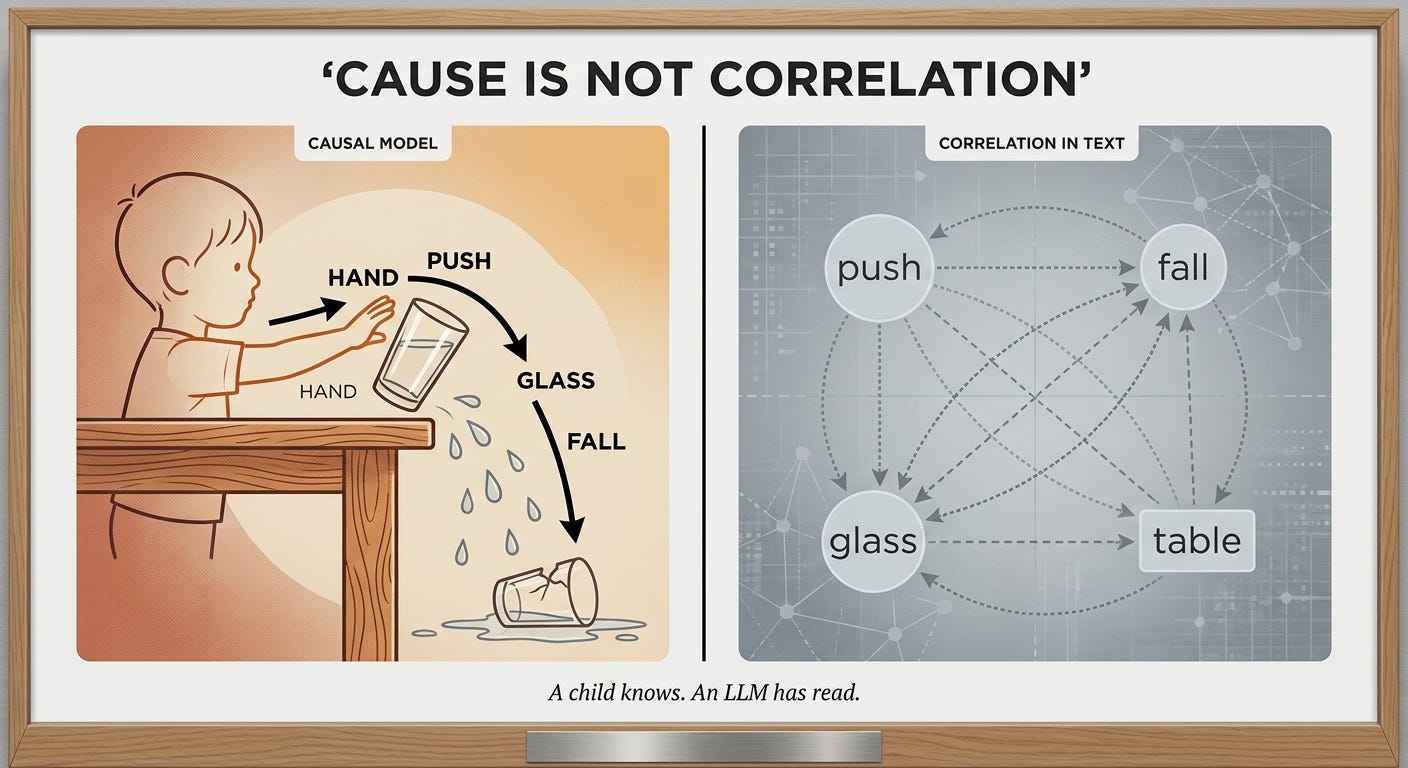
Reasoning about interventions, not correlations. A child knows a pushed glass will fall, even in a context it has never seen, because it has a causal model of the world. LLMs learn on text: they see that "push" and "fall" co-occur. They do not distinguish cause from correlation. The mathematical formalization has existed for a long time. No LLM implements it natively.
Compositional generalization. If you know what "jump" means and what "twice" means, you understand "jump twice" without ever having heard the combination. Transformers systematically fail on benchmarks designed to measure this: they learn the sequences they saw, not the rule that generates them.
Theory of Mind. Modeling what others know, believe, want. A four-year-old does it. LLMs produce responses that look like ToM, but they come from pattern matching over millions of dialogues, not from a real internal model of the other. It breaks the moment you leave standard situations.
Physical intuition. A six-month-old baby already knows a hidden object keeps existing and that one solid does not pass through another. Learned through interaction, not reading. LLMs "know" these rules because humans wrote them down somewhere. It is not the same thing: it breaks the moment you leave the cases that were described.
Preferring the short rule to the enumeration. Faced with data, humans look for the underlying regularity rather than memorize the table. That is Occam's razor, formalized in ML as MDL (Minimum Description Length): penalize the complexity of latent representations so the model prefers "always even plus one" over "here are 500 enumerated cases." Underused in training.
That is exactly what AMI Labs is building, the company LeCun just launched in Paris. Not an LLM. A system that learns a latent representation of the world, without token prediction or autoregressive generation, with persistent memory and reasoning over that representation.
The bottleneck is not research. The bottleneck is integration, plus a dataset problem: interventional causal data at scale does not exist yet. You need physical simulators, robotics, deployment instrumentation. Every system already operating in the physical world is gathering tons of data that will be massively valuable (think: Tesla, Waymo, robotics fleets). The architecture race is coupled to a physical-world data race, and the pure-software labs are not positioned for that one.
If the next generation learns post-deployment, then deploying = training. Everything changes.
Whoever controls where the model runs controls what it learns.
A model deployed in hospitals becomes medical.
Deployed in an IDE, a coder.
Deployed inside a bank, it absorbs that bank’s patterns.
The daily stream of interactions is the curriculum, and the enterprise providing that stream stops being a customer. It becomes a co-educator. Companies using these systems will not pay only in money anymore; they will pay in interaction data, and in return they get a model progressively shaped for their context. Developer holds the architecture, deployer holds the curriculum. That bilateral dependency is the central political-economic dynamic of the next cycle.