CRUD apps are by far the simplest, and most ubiquitous, software systems in the world today — the boring business applications which fund software consultancies, glorified spreadsheets. A number of tables where you can view, add, modify and delete data. That's the CRUD in CRUD: Create, Read, Update, Delete. At their core, these apps are just UIs on top of a (usually) relational database. Maybe they have more views, more functions, but effectively they are portals to interact with a database.
It's popular online for engineers to make fun of CRUD apps, since they're (and usually rightfully so) viewed as the simplest, least glamorous thing a software engineer can build. Most software engineers who work for a company that builds websites have made a CRUD app. I certainly have built my share. I've written countless endpoints for taking a client request and transforming it to SQL to run against a database. These systems usually work, they solve real business problems, and they actually increase productivity. But, over time they start to slow down and become more and more difficult to manage and modify.
There's something fundamentally wrong and inefficient with the standard way of building web applications. Let me explain.
A Food Distribution Platform
A few years ago I had the chance to work for a large food bank in the Midwest, designing an e-commerce site for ordering free or heavily discounted food. People who were in need of food assistance (we'll call them "neighbors" from now on) were able to use this system to place an order from their local food bank ahead of time, instead of receiving whatever was given. The system I helped build for them tracked a central inventory, provided an online shopping experience to neighbors, and coordinated the in-warehouse fulfillment, and eventual shipment, of all those orders. Imagine 1-2 dozen volunteers in a big warehouse, carrying tablets, all receiving a feed of items they need to go grab and where to put them.
This application used a standard, ubiquitous architecture.
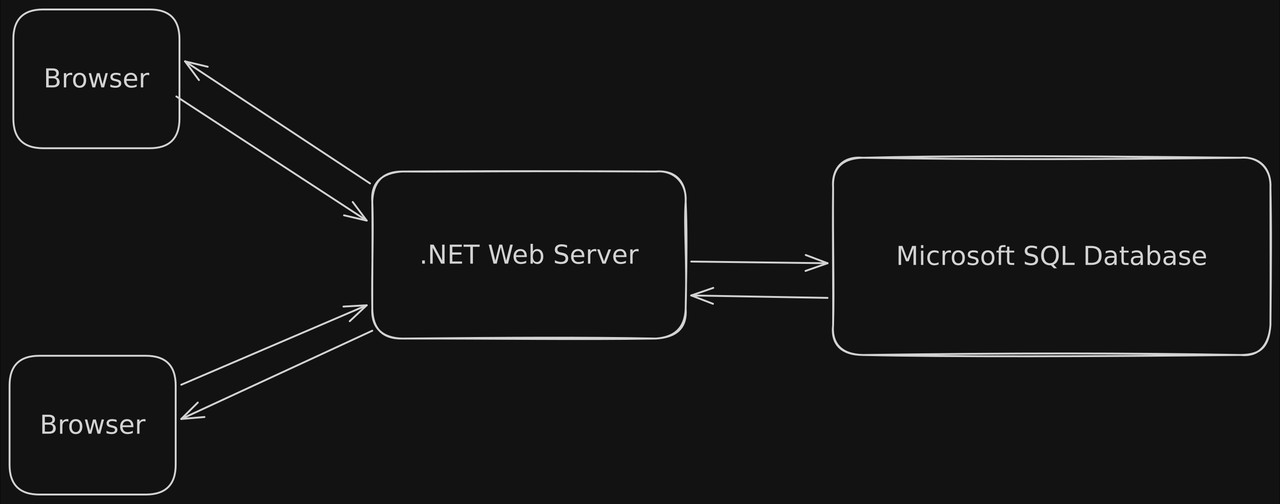
The client's browser, using our frontend UI, makes HTTP requests to the web server which in turn responds by querying the database.
In the database schema we had a number of tables we were tracking. Here are some noteworthy ones for our purposes right now:
- A users table with user info + password hashes and salts
- A products table for tracking everything in inventory
- A carts table for tracking everything in people's carts
- An orders table, connected to the carts table, for tracking higher level info like order status, fulfillment status, etc.
These tables powered login, views of order history, inventory, user management, etc. Of course we also built a large number of admin panels and pages for editing, creating, and deleting this data.
However, as we started building the ordering and fulfillment systems, we ran into two somewhat difficult, but common, technical problems:
- Real time warehouse fulfillment required a durable system driving what volunteers see on their tablet screens.
- We needed a way to ensure that customers do not order more items than what we currently have in inventory.
The solutions we came up with worked but weren't great.
For solving real time fulfillment, we had an in-memory process keeping track of all orders, built on a recoverable message queue. State would get loaded from the database regularly, and massaged into our message queue and its accompanying in memory state. As the system moved orders to a "fulfilled" state, we then issued updates to the database. This sounds reasonable, but note that this means we managed two sources of truth — one in the database and another in our message queue — and had to continually resolve the two of them.
Our solution to ensuring customers don't order more than our inventory involved a classic family of solutions: locks, atomics, and transactions. We could maintain atomic counters against our inventory and perform the checkout using a transaction. In reality, our solution ended up having to use in-memory, then eventually distributed, locks to perform a series of calls and checks for each checkout.
I was involved with the project for about a year and a half, but at the time of writing this system is still running. Current challenges likely involve scaling the checkout experience, the real time fulfillment experience, and dealing with accumulated data. Accumulated data is a real problem, especially for smaller shops. Once you have a table that needs to be loaded into web views that's in the gigabyte range, keeping the web experience responsive becomes much harder. Pagination doesn't necessarily save you, especially when the views need complicated joins. This is where many start reaching for caches, persistent views, read replicas, etc.
Observability is hard too. What if I want to see the status of all customer orders in real time? When something goes wrong, what exactly happened to cause it? The answers to both these questions kinda suck. Maybe we poll the database. Maybe our database can update us when things change. When something goes wrong, we just try to identify reproduction steps.
Testing is also hard. Sure, it's easy to write a unit test, but good integration tests mean you need to have a way of deterministically seeding the whole system. How many companies building things this way can realistically say they can spin up their entire system in a sandbox, and validate invariants? I think the number of orgs that can do real, robust testing against their entire systems is vanishingly small.
This is normal
All of the problems I've described above probably feel normal for most software engineers. But I hope you're starting to smell something off. Something is horribly wrong about building software this way. This approach produces software that we can't even get close to proving works. Software which is wildly inefficient and very hard to scale.
A note on efficiency
Think about the volume of data our system above needed to handle, and the complexity of computations. We might have 50-100 requests per minute. Maybe now as the system is scaling to more users we're in the 100+ range regularly in peak hours. Let's say 120 on average just to make math easier.
Requests are typically small — let's assume 1kb of data on average. This means we need a system which can handle 120kb of data per minute, so 2kb per second. And for each request, let's make a ballpark estimate of 50k CPU instructions to generate a response, assuming we're doing JSON decoding and encoding, organizing data, etc. So 100k instructions per second.
What can a raspberry pi 4 do?
A raspberry pi 4 has a memory bandwidth of around half a gigabyte per second, and a CPU clock speed of around 1.5GHz. That means it can do 500,000 kilobytes per second, and (conservatively) at least 1.5 billion CPU instructions per second. That means we could theoretically handle 10,000x more requests with comfortable headroom on the pi.
This is a general estimate, and a conservative one. If you have ever built a system like this, alarm bells should be sounding right now. You know the cloud costs involved. You know how your laptop heats up just starting the local dev server. This is a system that should be able to comfortably run on a raspberry pi if engineered sanely. The orders of magnitude at play here are so immense that slowdowns from IO, OS scheduling, etc, simply cannot explain away the sheer inefficiency of the status quo.
Let's talk about storage too. Assume we save every single request. What does that look like? 2kb per second, that's 172mb per day, or 62gb over the course of a year. That's the entire history of the system, small enough to be easily saved and stored somewhere cheaply.
The food distribution project started at hundreds of dollars per month on Azure. When I ran the system locally, it used hundreds of megabytes of memory, excluding my local db. I don't see any other way to put it: our current way of building web applications is catastrophically inefficient.
Turning the Database Inside Out
Back in 2014, Martin Kleppmann gave a fantastic talk at the Strange Loop conference called Turning the Database Inside Out. I highly recommend watching the video; the talk itself is a little under 40 minutes. The core argument by Kleppmann goes like this:
- For durability and recoverability, databases typically have at their hearts a write ahead log (WAL). They receive requests, requests are written to the log, requests are processed.
- Databases also usually offer abilities to take underlying data and create what are called materialized views. Effectively copies of the underlying data, but written according to a view function.
- Web systems are actually just stacks of materialized views of the underlying events powering the WAL. The database is just a materialized view of the log entries in the WAL, the API responses are just materialized views of the database, and the UI on a web page is just a materialized view of the API responses.
- The core source of truth for our data systems shouldn't be a database, but instead a log of everything our system is doing, and what the world is doing to our system. In our food distribution system that's people adding items to carts, tapping on their tablet screens, the system marking orders as fulfilled, etc.
When you take Kleppmann's arguments seriously and think about what a business application like our food distribution system could look like, you realize that our performance, complexity, observability, and testability problems begin to disappear.
Redesigning our food platform with a durable message queue
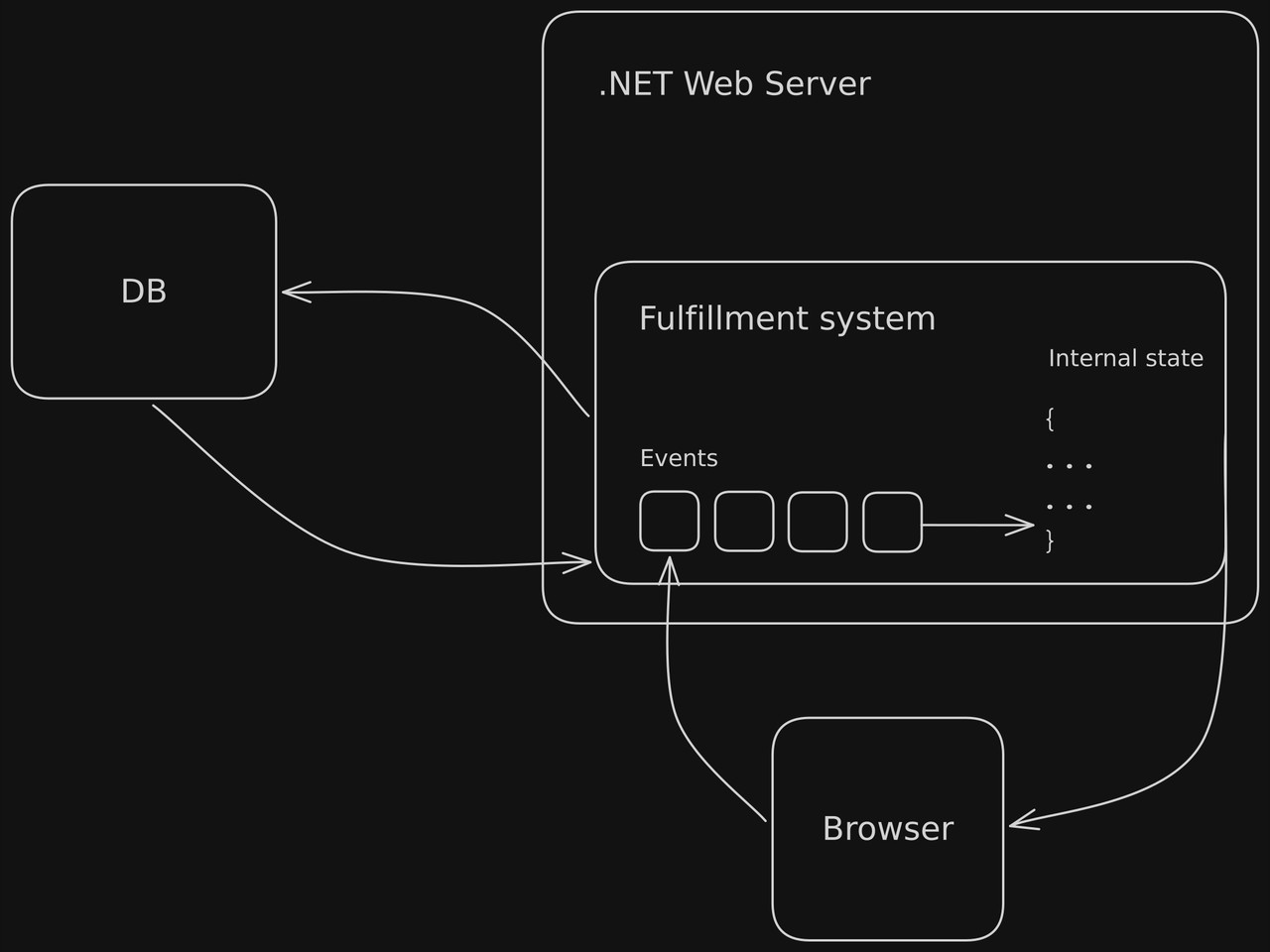
Let's explore a radical redesign. No database at the center. The heart of the system is a log of events, powered by simple persistence mechanisms. Every time we receive an event, we append it to our file, and dispatch any registered handlers. Think of a simplified version of NATS or Kafka, but the message queue isn't used for communicating between services, it is the source of truth for our data. The entire state of the system can be constructed by replaying the message queue. Instead of mutating the state directly, mutations are done by just adding a message to the queue describing the mutation.
Let's imagine what the shopping experience would look like.
An admin's view
- From the admin UI, admins would fill out modals or upload excel files to update the system's records of product inventory.
- Events would be added to the queue, simply recording that the user uploaded a file or updated an individual product.
- The core of the system is focused on processing events as quickly as possible. Once those events reach the front of the queue, they're dispatched to a handler.
- The file upload handler would then grab the file, process it, then create an event, or events, to record the products found in the file.
- The system is maintaining stateful computed views of the system. So for inventory, on every inventory update event, some handler updates appropriate views. These probably look like structs, or objects readable globally in the app.
Notice that if we want to maintain accurate inventory counts, this is dead simple — just create a handler to maintain a computed view. Real time dashboards for admins? Easy. Another table in the web UI? Just as easy.
All of these problems can be solved by just defining a handler that updates some state in the application. A simple performance optimization is to regularly serialize that state so we don't need to read the whole queue to reconstruct it. As long as our message queue is durable, which is effectively a solved problem (even for distributed systems), the entire application can be recovered.
A customer's view
- From the e-commerce UI the customer can hit add to cart on a product
- This dispatches an event to our message queue that the customer wants to add the product to their cart
- Our message queue is single threaded, no atomics needed, no transactions needed. See their intention, read our view of inventory counts, and then send a message back to the user whether they can add the item or not.
One fair question: wouldn't this increase latency? Instead of responding immediately, the user has to wait for their request to be processed behind every other unprocessed event. For modestly sized systems running on a single machine, I think this system will actually respond significantly faster than a traditional database application. For a few reasons:
- The core of the system is an engine for chewing through an array of events. CPUs are optimized specifically for tasks like this. By having everything processed single-threaded, you get incredible cache locality. Think about the compute needed for processing a request in a traditional application versus an event system like this. Our system just involves appending an event, and updating some views which live in memory.
- No locking required. Locks are hard to reason about, and can easily bring a system to its knees. Our system is single threaded, no coordination overhead. Each request is processed one at a time.
The user would only have events ahead of them if for some reason:
- We wrote event handlers which were blocking the event dispatcher
- We are running out of system resources
We know system resources are not a concern, and the blocking issue can be simply solved using an async runtime.
This isn't speculation either. It's a core part of the design of SpaceTimeDB, which is fast enough to power a real MMO.
What about real time fulfillment?
Part of the beauty of this architecture is that it makes real time systems easy. Real time is not some foreign isolated system you need to bolt onto your application, the application is real time by default. We solve all the real time fulfillment business requirements in the same way as the CRUD sections of our app.
What about testability, observability, and debuggability?
Hopefully it's clear that this architecture solves all these problems elegantly. The entire system state is described as a sequence of messages, so observability is just creating computed views on top of that state, and debugging involves replaying the history to see exactly what went wrong.
Testing becomes far more rigorous too. Want to verify that inventory never goes negative? Replay the log, assert the invariant after every event. Want to reproduce a bug a customer hit? Just replay their session. You're not limited to checking whether API endpoints return the right responses, you can test what happens when hundreds of users are concurrently interacting with the system, simulate enormous loads. These are trivial operations on an append-only event stream.
Final thoughts
Why isn't this the norm? If this architecture is so great, why isn't everyone using it? I think what it comes down to is inertia. Inertia dictates a lot of why we build systems the way we do, and what software we use to build those systems. Relational databases came out of a time when people wanted a way to collect lots of disparate data into a central location and query it. The databases we have today, the theory behind SQL, are engineering marvels. Genuinely impressive and useful technology.
Because a database exists, it's easy to just build a system which queries and updates the database. Back in the day, those operations being somewhat slow was fine because they were infrequent. Event processing systems did exist in the late 20th century, but it just didn't make much sense to maintain a large event log when memory and storage resources were so constrained. That era set the tone for business applications, a tone which has lasted decades. Today, our computers are so incredibly fast that it doesn't make sense to accept that slowdown, especially as our systems are more interactive and our volumes of data are larger.
Relational DBs have serious advantages in how flexibly they decouple data storage from how we view it. SQL is incredibly useful for people who aren't direct participants in the system, e.g. data scientists. But event based architectures are not antithetical to DBs, they just require us to think of DBs, like everything else, as another materialized view of our central message queue.