
SIMD = Single Instruction, Multiple Data
A simplified mental model:
Instead of…
Scalar:
[ a ] + [ b ] -> [ c ]The CPU executes…
SIMD 512-bit:
[ a1 a2 a3 a4 a5 a6 a7 a8 ]
+
[ b1 b2 b3 b4 b5 b6 b7 b8 ]
=
[ c1 c2 c3 c4 c5 c6 c7 c8 ]SIMD uses vector registers that hold multiple values packed together. One instruction operates on all values simultaneously.
Key hardware concepts:
Vector registers store packed values
Vector ALU executes operations on all lanes
Mask registers enable conditional processing (AVX-512)
Memory alignment strongly impacts performance
Think of a vector register as a tiny array inside the CPU.
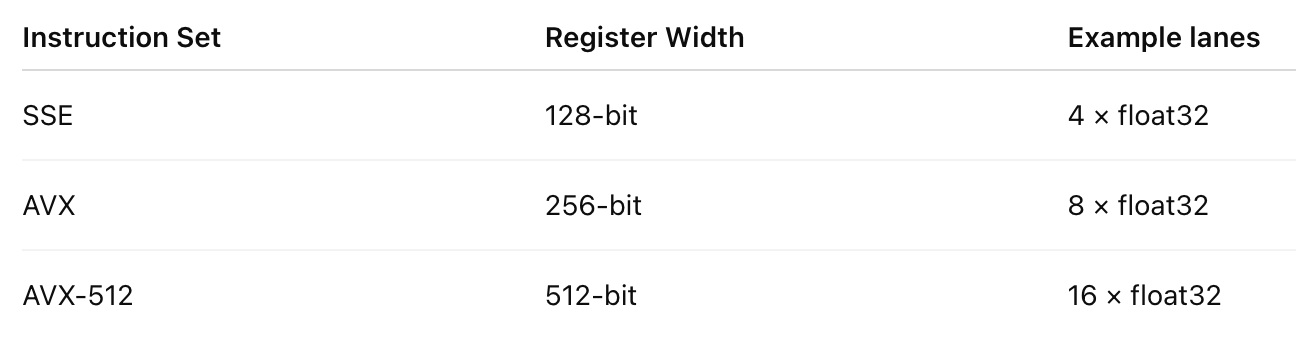
More width → more parallel math per cycle.
In SIMD, a mask is essentially a per-lane “on/off switch” that controls which elements in a vector are active for a given operation. Instead of operating on all lanes at once, a masked SIMD instruction only applies to lanes where the mask bit is set, leaving the others unchanged.
Vector: [ a , b , c , d ]
Mask: [ 1 , 0 , 1 , 0 ]
Operation: +10 to each active lane
Result: [a+10, b , c+10, d ]In modern SIMD like AVX-512, masks are stored in dedicated registers and can control 16–64 lanes, letting a single instruction act like many conditional statements in parallel.
These systems rely heavily on vectorized execution:
Apache Arrow → vectorized in-memory format
DuckDB → vectorized execution engine
ClickHouse → heavy AVX usage
Parquet readers/writers → SIMD decoding
HPC workloads → dense numeric computation
Why columnar systems love SIMD:
Columnar databases use SIMD because storing data column-by-column allows CPUs to operate on many values at once, making scans, filters, and aggregations much faster. By processing multiple elements in parallel with vectorized instructions, queries achieve significantly higher throughput and better cache efficiency.

👉 contiguous memory
👉 same operation across rows
👉 minimal branching
Perfect match.
Historically, Go performance hit a ceiling for:
analytics engines
columnar data processing
vectorized math
compression
encoding/decoding
High-performance systems often switched to C++, Rust, or assembly.
Go 1.26 moves toward native vectorization support, so Go can compete in: data engineering, scientific computing, HPC, OLAP systems, streaming pipelines…
The goal is simple: keep Go’s simplicity while unlocking CPU throughput.
CPU requirements for each vector size and SIMD operations are available in Godoc.
Since this is an experimental package, actual APIs may evolve, but usage follows this pattern:
Then run:
$ go version
go version go1.26.0 linux/amd64
$ export GOEXPERIMENT=simd
$ go run main.go The v1.26 iteration focuses on x86 vectorization first, building low-level primitives, and maintaining explicit control.
Still evolving:
ARM NEON / SVE support missing
Auto-vectorization still limited
Memory alignment APIs likely to improve
Compiler-driven vectorization may arrive later
The ecosystem may drive adoption faster than the standard library.
See progress on GitHub issue.
I already demonstrated the real-world impact in both samber/lo and samber/ro :
👉 https://lo.samber.dev/docs/experimental/simd
👉 https://ro.samber.dev/docs/plugins/exp-simd
Vectorized operations in lo can achieve up to ~50× speedups in tight loops where:
operations are pure
data is contiguous
branch-free transforms are used
Go can now be both ergonomic AND fast enough for data engines. Libraries that embrace this early will define the ecosystem.
Support for SIMD is experimental in both libraries. Please contribute!! 💖
Hyperthreading (SMT) does not double performance because it doesn’t add extra execution units: it only duplicates the core’s architectural state like registers and instruction pointers. Both threads share the same ALUs, caches, memory ports, and pipeline, so they compete for resources. If one thread already saturates the physical core, the second thread can only make use of idle slots, yielding typical gains of 10–40%, not 100%. Memory-bound workloads or heavy vector operations often see even less benefit because the bottleneck is outside the core.
SIMD, on the other hand, cannot be hyperthreaded because it is already designed to fully saturate its execution units with a single instruction operating on multiple data elements. Hyperthreading relies on interleaving instructions from multiple threads, but SIMD instructions occupy all vector lanes and pipeline ports. There’s no “unused hardware” to share. Allowing two threads to run on the same SIMD unit would require duplicating vector pipelines, which essentially means building another core.
If you enjoy my work, consider sponsoring me on GitHub. Your support helps me keep blogging and coding open-source projects 👉 github.com/sponsors/samber