Last night, I ended up watching the AFC Champions League Two, Group G match : Persib Bandung vs Selangor FC.
Persib took the lead in the 29th minute with a fast counterattack finished by Adam Alis, and later sealed the win when Andrew Jung converted a penalty in the 66th. Final score: Persib 2, Selangor 0. With that, Persib now tops Group G.
But what really caught my attention wasn’t the football itself . It was a huge banner in the stands, written entirely in Sundanese script.

I wanted to read it.
Naturally, I reached for the nearest tool I had : code (well, specifically “vibecode”). I threw together a quick Latin-to-Sundanese converter script. But the first few versions failed miserably. ChatGPT didn’t quite handle Sundanese characters well enough yet, and the output looked like gibberish.
So I tried a shortcut. I asked Gemini to transcribe the script instead. Gemini confidently provided an answer. I can’t prove it, but somehow I strongly believe Gemini is lying right to my face right now.
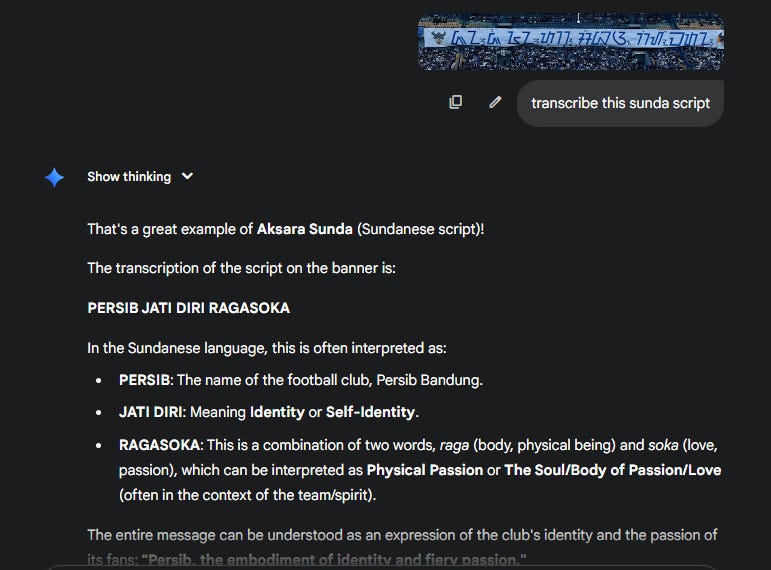
Fine, I thought. Let’s do this the old-fashioned way. I pulled up the official guidebook from the West Java Province Language Council on “Reading and Writing Sundanese Script” and started decoding the banner manually.
After a few minutes, I managed to read the entire thing.

That’s when another idea hit me: could I actually build a simple translator. Latin to Sundanese and vice versa?
So I started a quick proof of concept. The goal wasn’t linguistic accuracy. I wasn’t trying to model the full Sundanese phoneme system, but rather to see if a one-to-one character mapping could work. Treat it like a cipher, not a linguistic translation.
After some analysis, it turned out that the Sundanese script system (ngalagena letters plus the pamaéh modifier) could represent all Latin consonants. The vowels were also covered: “a” is inherent, while “i”, “u”, “e”, and “o” can be applied with the appropriate diacritics (panghulu, panyuku, pamepet, panolong).
So yes — it’s doable.
I drafted a rough algorithm sketch in PowerPoint, then fed it into ChatGPT to build the prototype.

Within minutes, I had a working Latin–Sundanese converter.
Naturally, I used it right away on that Persib banner.
And… it failed again.
Apparently, the banner used a more “authentic” Sundanese orthography, complete with specialized diacritics that my simplistic algorithm didn’t account for — particularly the pangwisad (to mark a final “h”) and panglayar (to mark a final “r”) modifiers.
To be fair, my prototype didn’t even cover the full vowel set yet (Sundanese also has é and eu), nor the special ligatures for clusters like -ng, -l-, -r-, and -ky-.
But for this task, I decided to at least implement pangwisad and panglayar, out of respect for that Persib banner at the stadium.
After that update : success. The banner text was finally readable.
It said: “Janji untuk sebuah kehormatan.”
Or in English: “Promise for an Honor.”