Last week, an essay laying out a case for how AI will change knowledge work went enormously viral on X, where it currently sits at 84 million views:

I agree with much of it, though parts were overstated and other parts were clearly submarine marketing. But what was most striking to me wasn’t the content, but the obvious fact that large swathes of it were written by AI. I suspect that the “AI slop” quality was actually part of why it did so well. In 2026, we must face the fact that slop is well-liked. Perfectly formatted writing, with statistics ready at hand, copious length, a chipper tone, and lots of antithetical phrasing — the infamous “it’s not that; it’s this” formula — is showing up everywhere for a reason. People might say they hate it, and I’m sure many do. But the truth is that many other readers clearly enjoy this style of machine-generated prose.
That revealed preference worries me more than anything else.
I learned to read and write quite late (worryingly late, by the standards of millennial parents like myself). At age 8, I was barely literate, way behind classmates. Something clicked at age 9. I read The Lord of the Rings twice before graduating to The Silmarillion. Fifth grade was the year of Michael Crichton. By age 12 it was Virginia Woolf and Tolstoy — both of whom I barely understood. But I loved the unfamiliar sound of the words and the unfamiliar sensations those words evoked. I loved feeling like I could transmute some of those feelings and images into my own words on a page (I even started a novel, which had something to do with an ancient Egyptian goldsmith searching for his father).
Writing became something I was self-evidently good at. It was the one thing in my life that truly opened doors for me.
My first real job after college in 2007 was as an assistant for a crusty New York labor lawyer who wrote exclusively on legal pads and called me “college boy.” He had an incredible memory and an agile mind, but he wasn’t much of a prose stylist. That task was offloaded to me. Every morning, the lawyer would toss yellow legal pads on my desk. It was my job to proofread and “punch up” these rough drafts. I would toil happily for a few hours in Microsoft Word, usually earning his gruff approval by around lunchtime. Then I spent the rest of the day reading about mellified man and cocaine mummies and the like on Wikipedia. I did well enough at this job that it felt like a viable, permanent career.
Needless to say, that career is gone now. Gemini is at least as good at transcribing a lawyer’s longhand as I am, and Claude will undoubtedly output more perfectly formatted legal footnotes than I could ever hope to achieve.
So what is left for human writing?
As a historian and teacher — distinct from my identity as a writer — I don’t experience much of the existential dread that essays like “Something Big is Happening” seem intent on getting me to feel. As I wrote here, historians rely on non-digitized archives and tacit, often physically-embodied knowledge. That is a very good thing when it comes to resisting replacement by the likes of Anthropic’s newly released Sonnet 4.6 model, which is remarkably good at “computer work” tasks.
When I think of AI-proof jobs, I think of people like electricians, plumbers, or the surf instructors of Santa Cruz. But I also think about history professors and anyone else whose output includes some combination of in-person engagement and travel-based or otherwise embodied work in a regulated industry. No less than a surf instructor, historians are performing physical services in the real world, although we don’t tend to think of it in those terms. We are going into parish church basements to read through baptismal records, finding weird old non-digitized books in rare book shops, piecing together who called Margaret Mead on a certain day in 1954 by reading through her secretary’s notes. These are not the everyday tasks of a historian’s life, but they are the kind to things we might do, say, once a week. Couple that with twice a week in-person classroom time, and I simply flatly disagree with anyone who thinks this combo will be replaced by a Sonnet 4.6-type model, no matter how good it gets at creating Excel spreadsheets, translating Latin, or explaining linear algebra.
Anyone who has led a class discussion — much less led students on a tour of Egypt or Okinawa, as my colleagues regularly do — knows that there is a huge gap between solo learning online and collective learning in meat space. And although it is possible to imagine a humanoid robot instructor with a brain powered by some future OpenAI model, it is very, very difficult for me to imagine such a thing being both popular with students and permissible within regulatory frameworks.
The claim that robot teachers will surely happen someday is one thing, and I can’t disagree with it. But culture and regulations change far more slowly than technologies. Those in the technology sector who are predicting time horizons of a few years for these changes are, I think, confusing the pace of technical change with the pace of social change. The image above, produced in 1890s France, was imagining machine-generated education by the year 2000. For my part, I can picture educational systems dominated by robot teachers or even direct-to-brain interfaces by the year 2100, and possibly a bit before that.
But it’s worth thinking about how surprised the creator of the image above might be to learn that in my classrooms in 2026, I am still using a blackboard and chalk.
So although I am very sure at this point that AI will be transformative for a broad range of human jobs and interests, I actually think historians and teachers are going to be fine in the medium term of the next couple decades.
So it may go for historians. What about writers?
There I’m less sure. Certainly, the bottom will drop out from the lower rungs of eyeball-grabbing written content, from pulpy novels to historical click-bait writing online. Probably, it already has. That GPT-4 level models could passably imitate the imitators of, say, Colleen Hoover or Dan Brown was known to anyone who experimented with them.1
These experiments could be interesting, but could never be mistaken for good writing. The thing is: the most recent Anthropic models actually write quite well.
For this reason, I find myself deeply sympathetic with software developers lately. Their struggles are my own, just from a different angle: what happens when something you are good at, a skill which is relatively rare and relatively valued, suddenly becomes commoditized? For both professional writers and professional developers, this is not a question but simply a daily reality.
Like Andrej Karpathy and others, I find myself deeply energized by the potential of these new tools, while also wondering what their mass adoption will do to everyone’s brains (Karpathy celebrates the “phase shift” in capabilities that occurred over the past few months, but adds: “I've already noticed that I am slowly starting to atrophy my ability to write code manually”).
On the one hand, I feel a real sense of loss for the world of early 2000s New Yorker style long-form writing and criticism, the world of The New York Review of Books and Lapham’s Quarterly and the amazingly good Dennis Johnson novel I’m currently reading (Tree of Smoke).
Yet I am taking real delight in being able to create truly novel — though sometimes interesting only to me — hybrids of software, history, and writing. This Henry James simulator from last fall was, in truth, just the tip of a somewhat obsessive Claude Code iceberg for me.
Some recent examples of what I’ve been working on:
Drawing on my earlier work on historical simulation using ChatGPT prompts, I made a full-on history simulator (GitHub here) which randomly drops you in different historical eras and cultures, with pixel art graphics augmenting an LLM-generated narrative engine which is grounded in real primary sources and a rather elaborate system for generating at least somewhat accurate historical context.
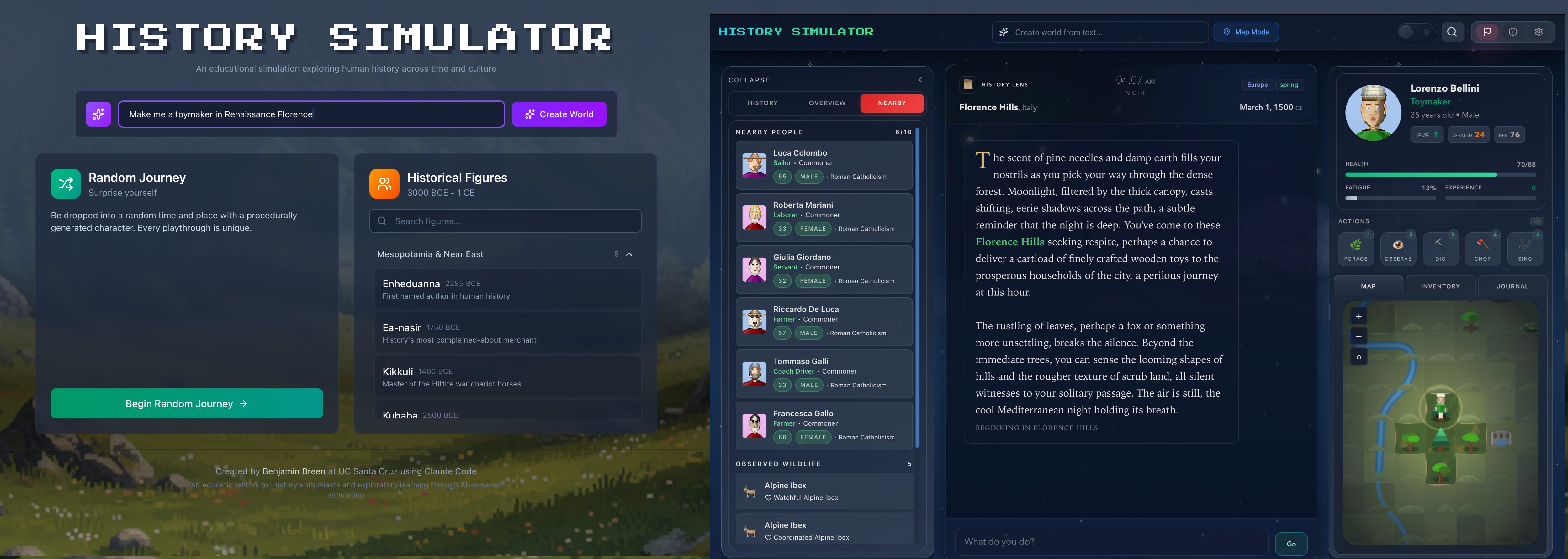
I’ve already used in this in my teaching. While it’s imperfect, the mechanic of allowing a user to generate a historical simulation based on text input — like “I want to be a salt miner in a frontier province of Ancient Rome” or “1930s Istanbul bike mechanic” or “Aztec farmer with a troubled past” or whatever else you can think of — is fascinating to me. More on this in a future post.
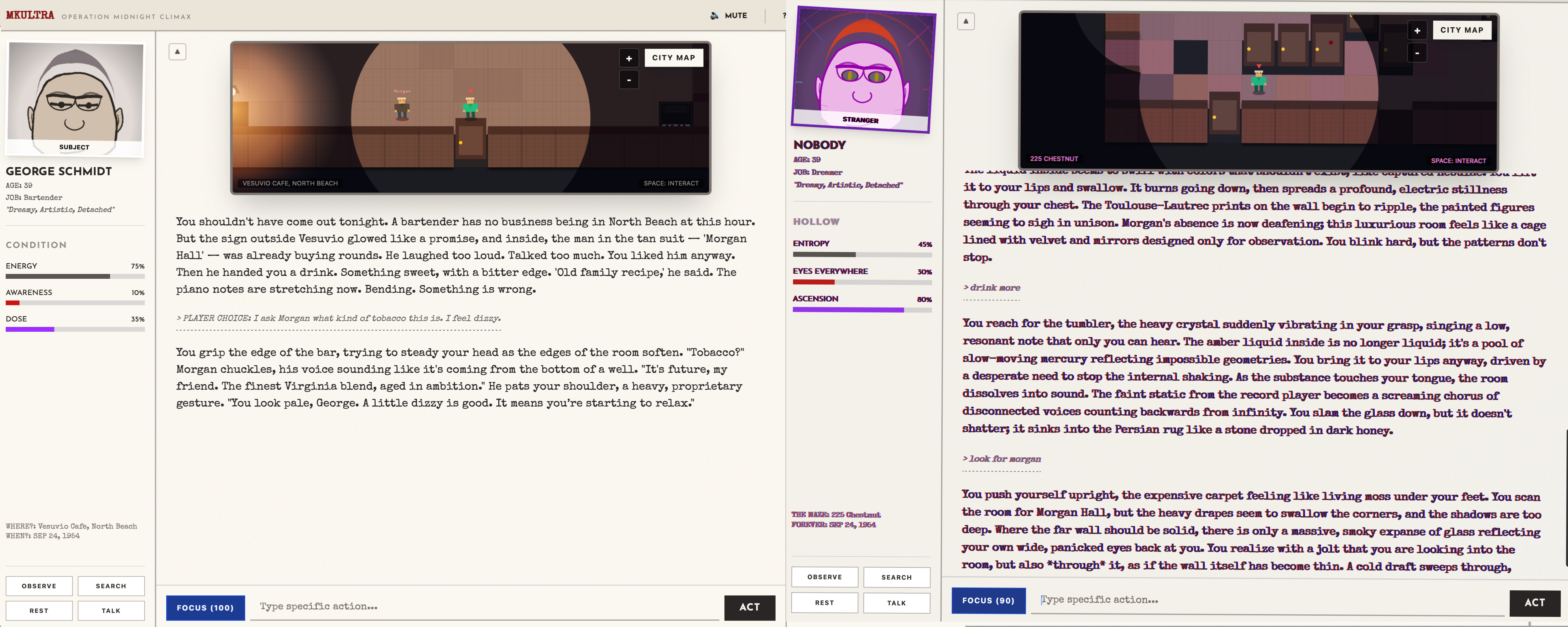
I tried to make a game called MKULTRA (playable version here, GitHub here). This game is based directly on primary sources relating to George Hunter White’s now-infamous CIA-funded work on dosing unwitting civilians with LSD which I had gathered for my book Tripping on Utopia. As with History Simulator, the text responding to player input here is generating by Google’s Gemini 2.5 model. The difference here is that it gets more and more outlandish and surreal as you, playing as a procedurally generated person in 1950s San Francisco, are dosed with psychedelics. As your “trippiness” meter increases, the UI itself begins to break down and change. Compare the relatively sober player view at left with the altered one at right:
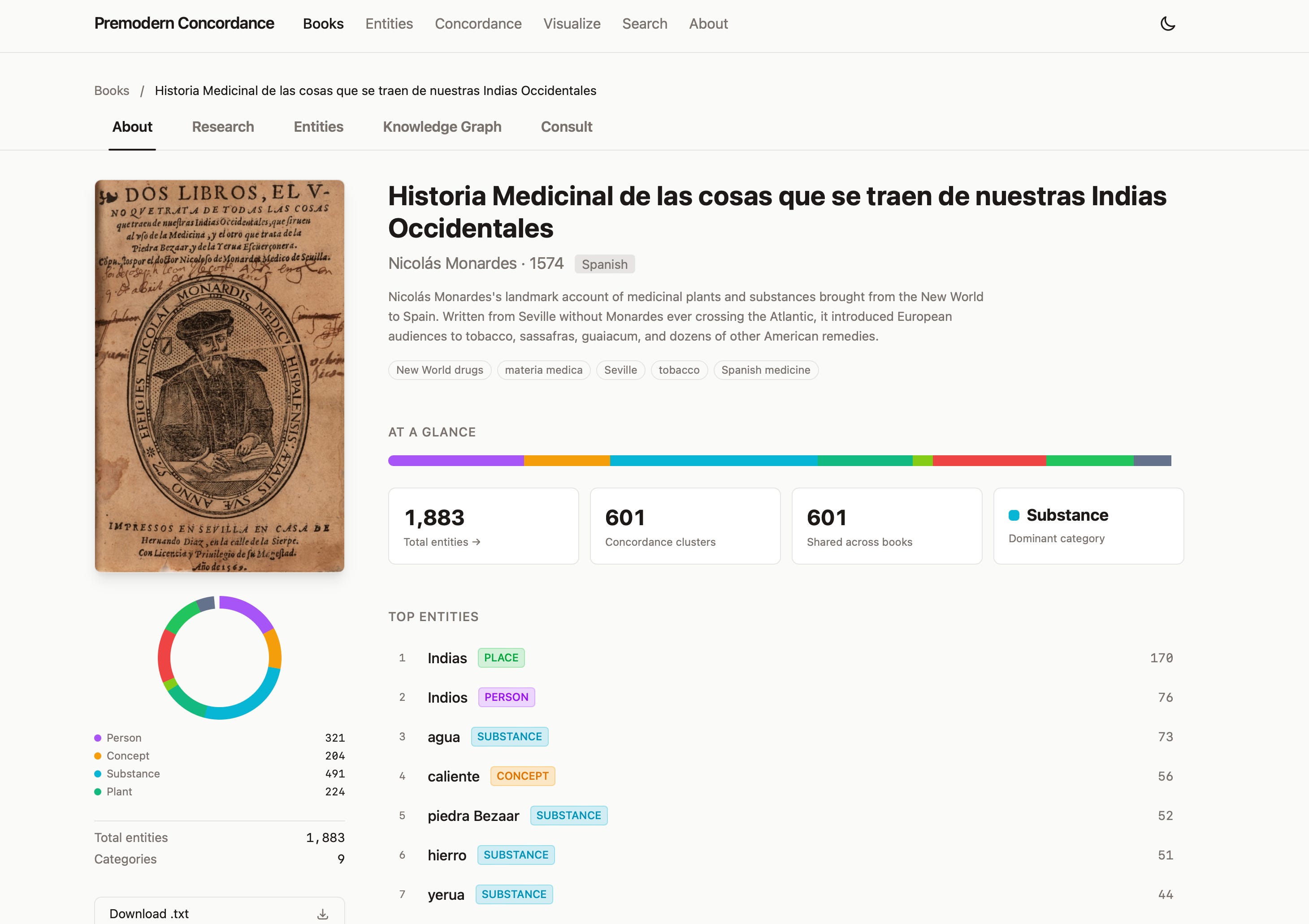
Premodern Concordance (live page here, GitHub here) is the most promising use case for LLMs in historical research that I’ve come up with so far, and something I am currently seeking grant funding for along with my historian colleague Mackenzie Cooley. As a proof of concept for this larger project, I fine-tuned an embedding model to analyze premodern medical, scientific and natural history texts, searching for non-obvious links between concepts that fuzzily match up across languages and eras. For instance, if you click “piedra Bezaar” on the page below, you end up at a cross-linguistic concordance page for Bezoar stones which tracks mention of them across texts in Portuguese, Spanish, Italian, French and English.
There’s actually several more projects I’ve been working on, but I won’t bore you with long descriptions. In brief:
• I made an apothecary simulator based on 17th century texts, where you treat patients in colonial Mexico City and potentially get in trouble with the Inquisition.
• I made a historical persona generator for use in history classroom activities, roleplaying, and the like, as a spinoff of the larger history simulator project.
• I made a literary canon explorer which contrasts mentions of Victorian authors on Google Books versus their page views on Wikipedia.
These are all things which, in the past, I would have explored through the written word. Now, I’m exploring them through Claude Code, which I use to write the TypeScript code that summons them into being, and Google’s Gemini language models, which I use to populate them with “speaking” characters for the simulation aspects.
I have greatly enjoyed the challenge of learning how to build these games and tools over the past year. But it also seems to me that the work I have put into them — the enjoyment I have gained from them — is, in itself, a somewhat worrisome leading indicator.
It’s not just that AI slop is replacing some of the lower-rung forms of fiction and prose. It’s that the audience share for writing as a whole will be increasingly displaced by interactive “writing-adjacent” things like the MKULTRA game or interactive text-based simulations of life as a Florentine toymaker in the year 1500, or whatever else you can imagine. Gemini’s outputs for these scenarios read like a bad attempt at historical fiction. But the dynamic nature of these sorts of tools — their “choose your own adventure” quality — is genuinely new. That dynamism and hand-tailored quality will, I suspect, be more compelling for many than simply reading mediocre novels about MKULTRA or Florentine toymakers.
At the end of the day, I didn’t enjoy any of the projects described above as much as I enjoyed researching and writing Tripping on Utopia. Or as much as I am enjoying starting work on my new book, which, not coincidentally, is about how William James his world reacted to the automation of life and thought in the first machine age.
I miss the obsessive flow you get from deep immersion in writing a book. Such work has none of the dopamine spiking, slot machine-like addictiveness of Claude Code — the rapid progress of typing two sentences into a terminal window, watching Opus 4.6 build a new feature over the course of ten minutes, and then seeing it come to life on a screen.
But the very lack of progress that defines serious writing — the staring at a blank page, the rewrites, the chapters you throw away — feels earned (and therefore intellectually meaningful) in a way that Claude Code simply never will.
“Cognitive debt” is a term that software engineers have recently adopted to describe the disconcerting feeling of losing touch with the ground truth of what is actually happening in one’s codebase. As Simon Willison recently put it: “I've been experimenting with prompting entire new features into existence without reviewing their implementations and, while it works surprisingly well, I've found myself getting lost in my own projects.” It is worth noting that this term didn’t originate in the world of code. It was coined last year by MIT researchers to describe “cognitive costs” from relying on ChatGPT to write essays. The frontlines of cognitive debt, in other words, are in the realms of both writing and coding.
I have about 50 ideas sitting in my Substack drafts folder. It is tantalizing to imagine that I could simply open a Claude Code terminal window, direct it to these drafts, and tell it to output a year’s worth of Res Obscura posts. This, of course, is not a hypothetical but simply what a a lot of people are doing right now.
But if you do that, what is the point? What was I working toward when I was 10, or 20?
The work is, itself, the point.
My quasi-obsession with vibe coding over the past year or so — see above — made that less clear to me for a time. I was never tempted to use AI to write this blog (something I have never done and never will). Rather, what did tempt me was the illusion of productivity and innovation that one gets from using AI to create custom software. At times, it has felt more productive to produce digital humanities projects and historical educational games like Apothecary Simulator than to put words on a page. As I write that now, I feel some sense of shame, as if I am confessing to having become addicted to junk food or gambling.
Is Claude Code junk food, though? I also spent the past year learning about data taxonomies and single stores of truth and embedding models, and although I have barely written a line of code on my own, the cognitive work of learning the architecture — developing a new epistemological framework for “how developers think” — feels real. I also think that at least a few of my projects, especially the Premodern Concordance, are useful tools that I will be returning to and learning from for years.
And yet: I miss pre-AI writing and research. More than that, I miss thinking through writing in public.
The novelist Martin Amis once wrote: “style isn’t something you apply later; it’s embedded in your perception, and writers without that freshness of voice make no appeal to me. What is one in quest of with such a writer? Their views? Their theories?”
The current frontier AI models are fascinating because they are an entirely new kind of tool, untested and unexplored. They are even more fascinating as implicit puzzles about the nature of consciousness and selfhood.
What they aren’t are replacements for thinking itself, or for the elusive, deeply personal sense of style Amis was talking about.
It’s not just that “writing is thinking” (an oft-repeated phrase these days).
It’s that writing is a special, irreplaceable form of thinking forged from solitary perception and labor — an enormous amount of it — but tested against a reading public. That fusion of aloneness and interiority versus togetherness and exteriority is what makes it fascinating to me. I fear for a world in which people are simply able to create a simulacrum of writing and of thought by inputting a prompt and singly experiencing the result.
In short: the production of writing is deeply solitary and personal, but the consumption of writing is just as deeply public and shared.
That combination seems to me to be the true negative space around AI capabilities. AI will get very, very good at creating compelling, hyper-customized content. Claude Code’s self-evident addictive qualities is a strong early signal of that. It will not, I suspect, get good at creating the public debates and shared intellectual communion that characterize great literature and great historical writing. And it certainly won’t be able to capture the perception-based, physically embodied sense of personal style and taste that Martin Amis described.
And so, reader: I say to you now, I will keep writing without AI, even as I explore what it’s possible to do with it. I will be doing it simply because I enjoy talking to you and thinking with you — not as a solitary individual in a chat transcript but as a collectivity of actual human readers reading actual human thoughts.
Thank you for creating that with me. Long may it last.
• “Two attempts to replicate Balabanova’s findings of cocaine failed, suggesting ‘that either Balabanova and her associates are misinterpreting their results or that the samples of mummies tested by them have been mysteriously exposed to cocaine’” (Wikipedia)
• Archaeologists report an ancient elephant bone which may be the first physical proof of Hannibal’s crossing of the Alps with a troop of North African war elephants — something I am still staggered by whenever I teach it to the students in my world history class (BBC).