Draw Things is the fastest way to generate images or videos with your Apple silicon, locally and privately. Our work on Metal FlashAttention has been the bedrock of this claim.
The recent release of M5 debuts Draw Things with 3.5× performance improvements over M4. This was achieved through Apple’s MPSGraph API, first enabled in our 1.20250912.0 release. While MPSGraph API adequately implements Neural Accelerators support, it lacks the fine-grained memory and performance optimizations that we have developed through our ongoing Metal FlashAttention research.
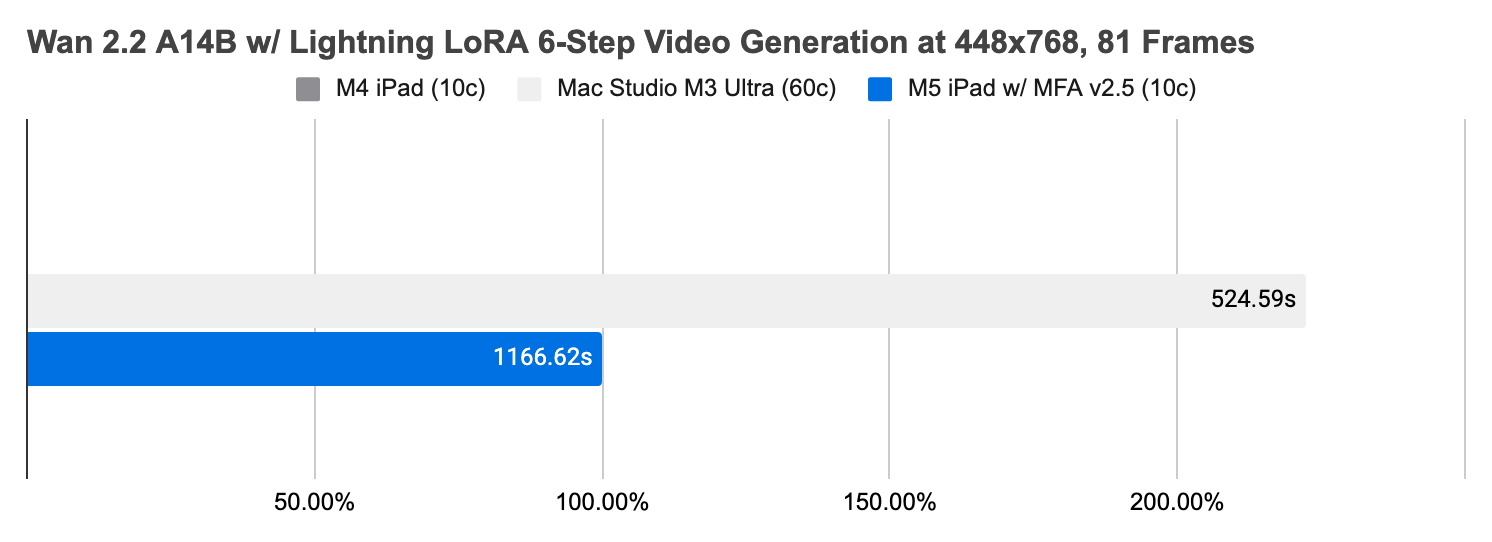
Version 1.20251107.1 is our first release containing the preview version of Metal FlashAttention v2.5 w/ Neural Accelerators. It delivers up to 4.6× performance improvements on M5 over M41. With adequate cooling2, it sometimes outperforms M2 Max and narrows the gap to M3 Ultra. Its efficient memory management allows 5-second, 480p (448×768) video generation (with Wan 2.2 A14B models) on an M5 iPad with 16GiB of RAM.
We will discuss more Metal FlashAttention v2.5 w/ Neural Accelerators implementation details in a separate post on the Engineering@Draw Things channel, stay tuned!
Metal FlashAttention v2.5 w/ Neural Accelerators delivers the fastest performance on Apple’s non-Pro M-series chips, often rivaling or exceeding previous Max M-series chips. With several large image-generation models (FLUX.1 [schnell], a 12B-parameter model; Qwen Image, a 20B-parameter model; and HiDream, a 17B-parameter model), the M5 iPad can now generate high-resolution images in under a minute.
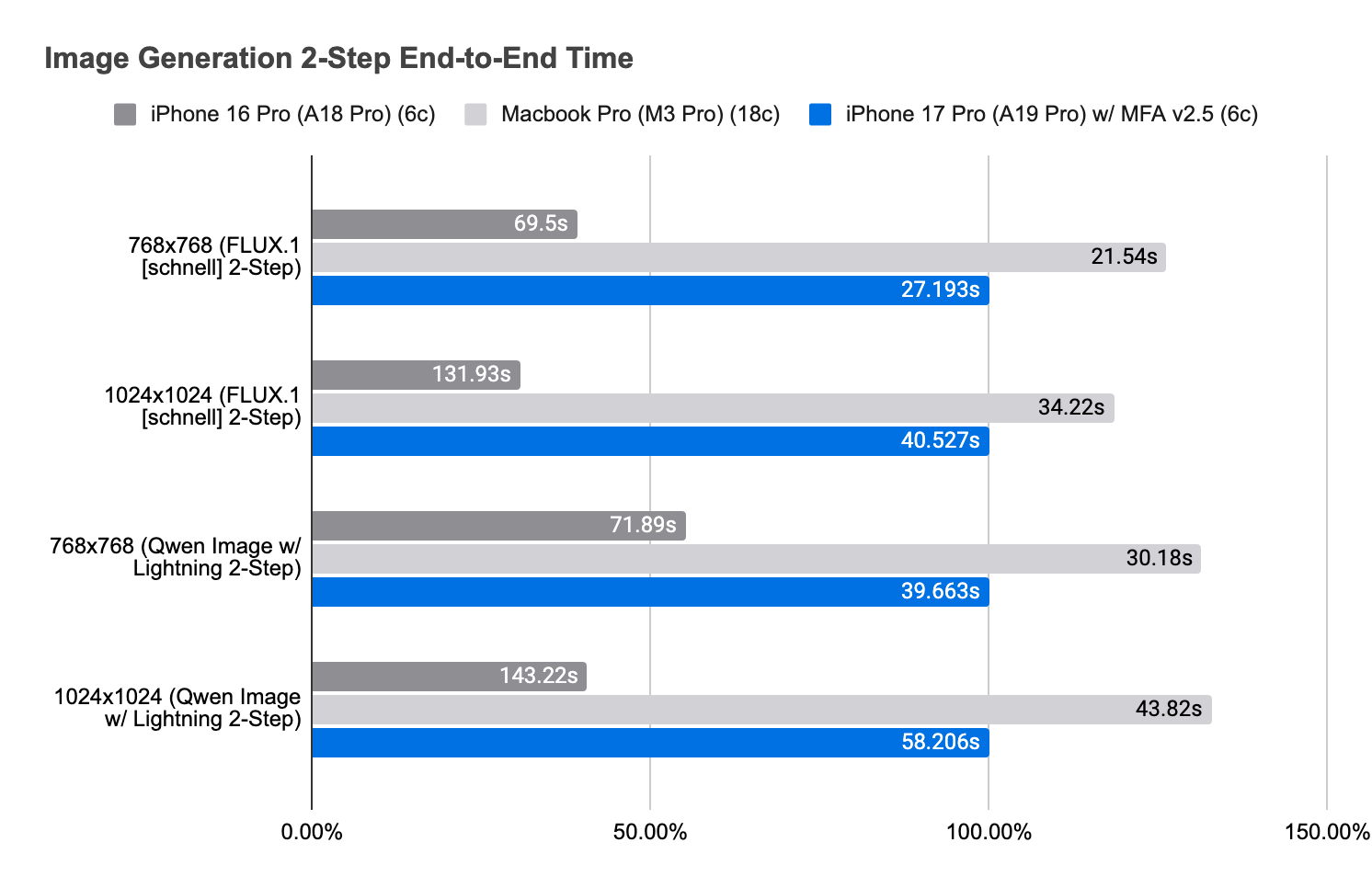
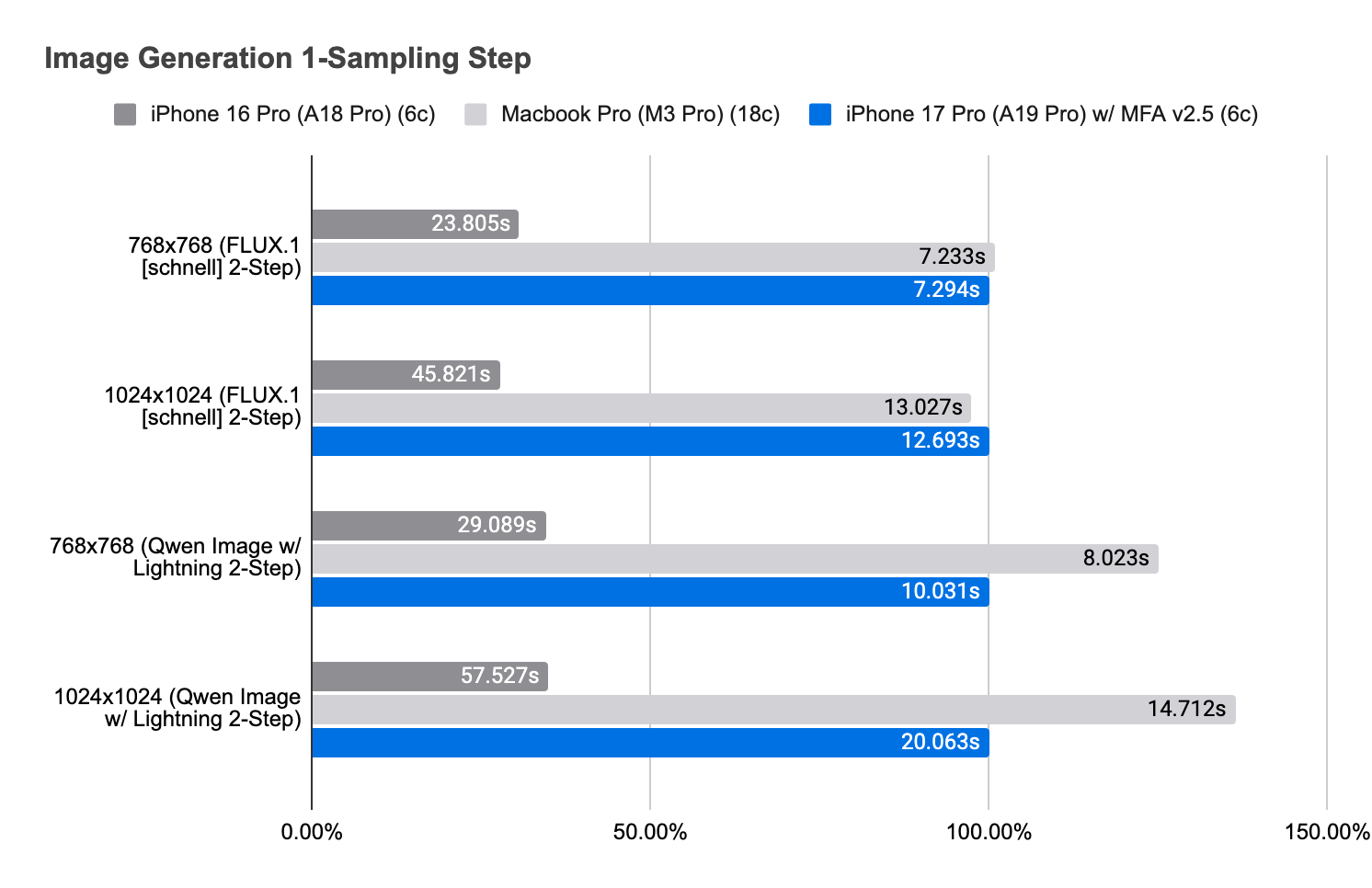
On A19 Pro, it improves on our previously reported numbers (with MPSGraph API), and now rivals M3 Pro (18c) performance.
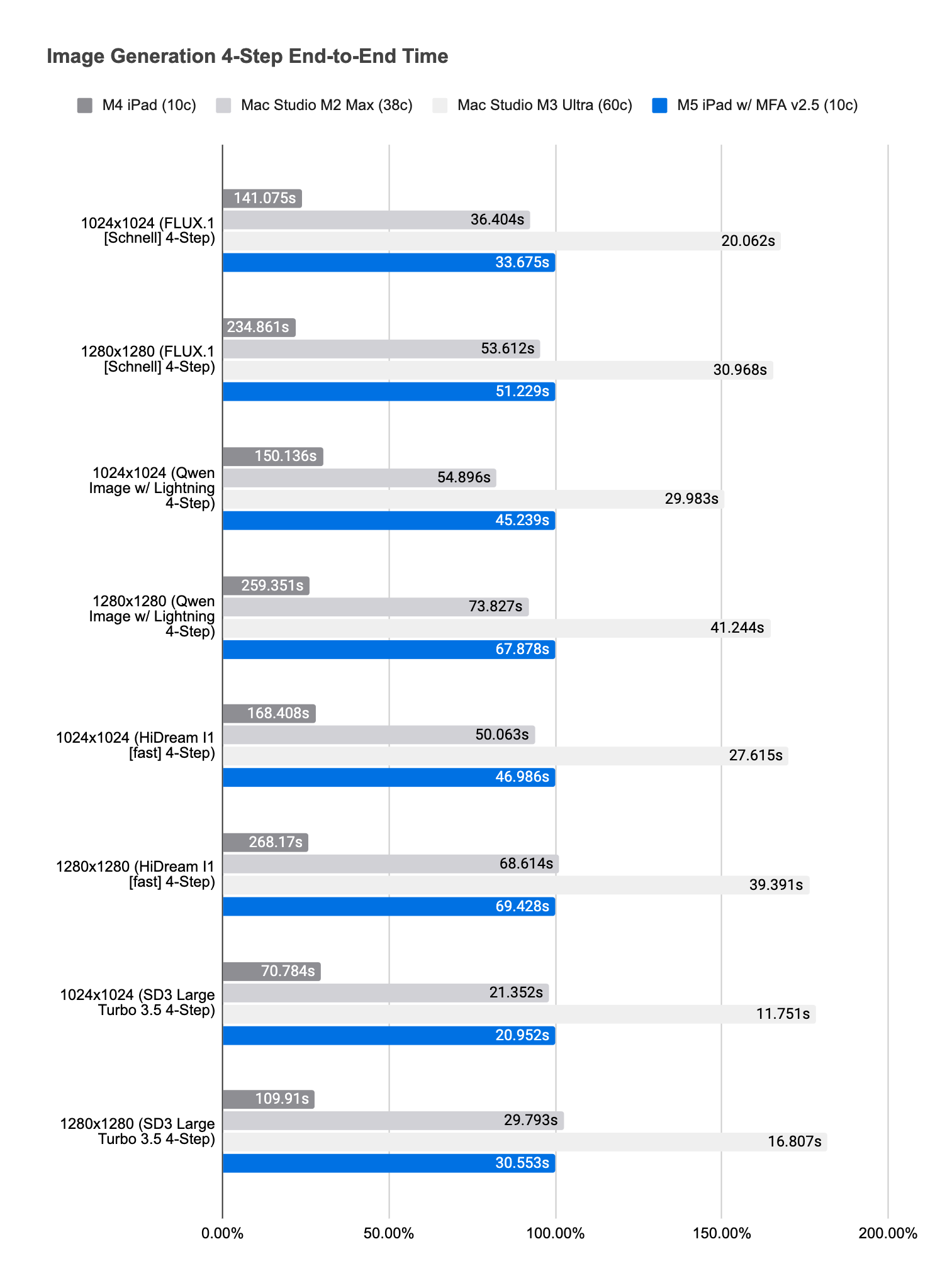
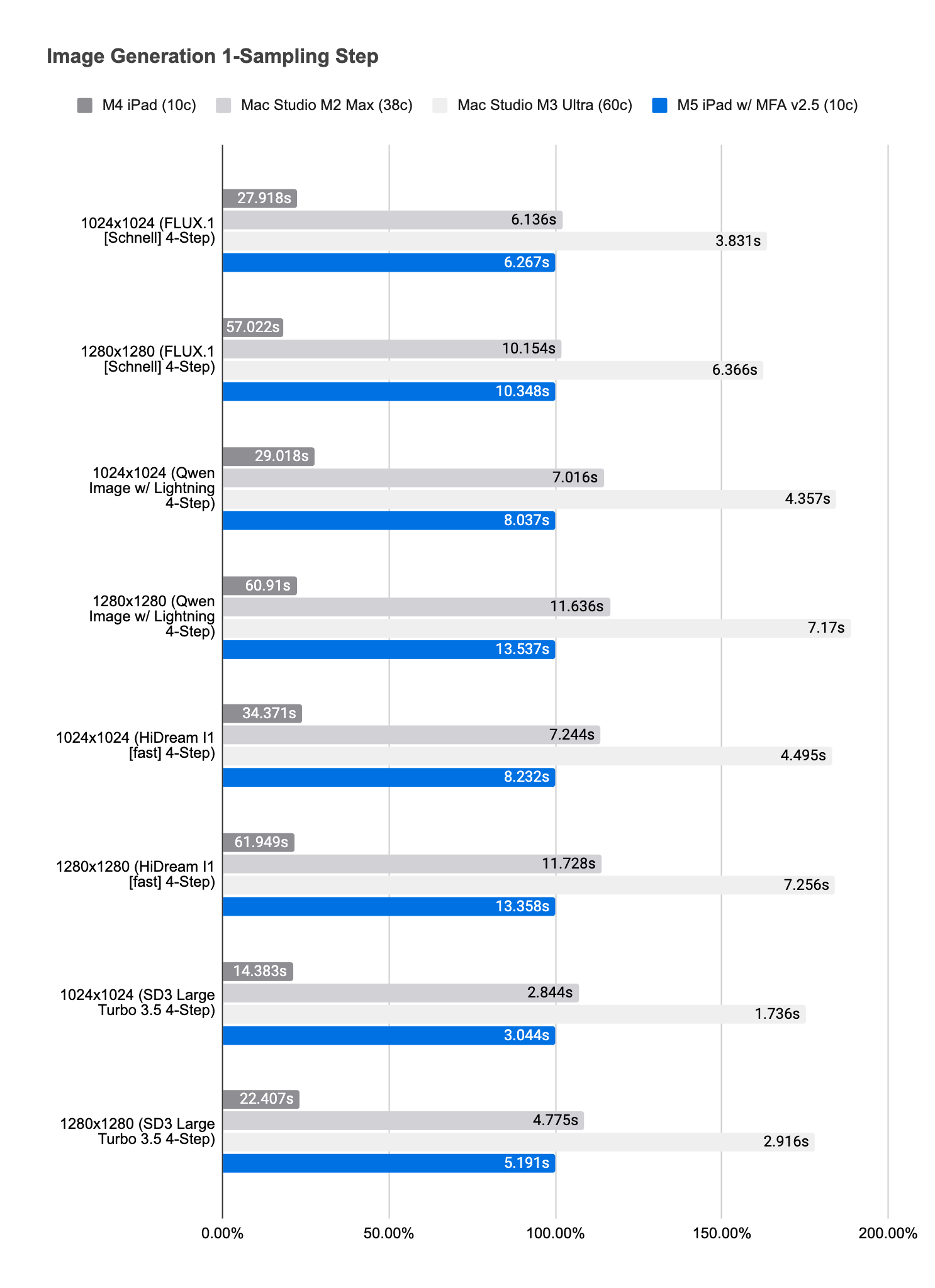
On M5 iPad, we observe 3.6× to 5.5× raw performance improvements over M4 iPad, and 3.3× to 4.6× end-to-end improvements. In the mid-range, M5 iPad performs as well as M2 Max3. At the high end, M5 iPad often runs about 80% slower than M3 Ultra (60c).4
Metal FlashAttention v2.5 w/ Neural Accelerators leverages the Neural Accelerators across all key operators — including matrix multiplication, attention, and segmented matrix multiplication, the latter being essential for Mixture-of-Experts models.
The source code of Metal FlashAttention v2.5 w/ Neural Accelerators is available at https://github.com/liuliu/ccv/tree/unstable/lib/nnc/mfa/v2. Draw Things 1.20251107.1 integrates the full implementation of Metal FlashAttention 2.5 w/ Neural Accelerators. It is currently released as a preview because there are still performance cliffs around odd attention sequence lengths and large head dimensions. BF16 support is turned off due to unsolved bugs. The neural accelerators-enabled shaders also take a significantly longer time to specialize (often 10s or more for the first generation). We expect to resolve these issues in future updates.
Edit (20251118): 1.20251117.1 now supports BF16 as well as binary artifacts cache for neural accelerators-enabled shaders.