Harnesses are independent system layers.
Real-world reliability is shaped by execution controls, feedback loops, governance, evaluation, and operational design, not only by model capability.
Junjie Li1,6,*, Xi Xiao6,*, Yunbei Zhang5,*, Chen Liu2,*, Lin Zhao4, Xiaoying Liao3, Yingrui Ji6, Janet Wang5, Jianyang Gu7, Yingqiang Ge9, Weijie Xu9, Xi Fang9, Xiang Xu9, Tianchen Zhao9, Youngeun Kim9, Tianyang Wang6, Jihun Hamm5, Smita Krishnaswamy2, Jun Huan9,†, Chandan K Reddy8,9,†
1Carnegie Mellon University ·
2Yale University ·
3Johns Hopkins University ·
4Northeastern University ·
5Tulane University ·
6University of Alabama at Birmingham ·
7The Ohio State University ·
8Virginia Tech ·
9Amazon
*Equal contribution. †Corresponding authors.
Abstract
The rapid deployment of large language model agents in production has revealed a recurring pattern: task execution reliability depends less on the underlying model than on the infrastructure layer that wraps it, the agent execution harness.
This survey presents agent harness engineering as an independent system layer, proposes the seven-layer ETCLOVG taxonomy (Execution, Tooling, Context, Lifecycle, Observability, Verification, Governance), and maps a broad corpus of open-source projects onto that taxonomy to expose ecosystem patterns, coverage gaps, and emerging design principles.
Contributions
Real-world reliability is shaped by execution controls, feedback loops, governance, evaluation, and operational design, not only by model capability.
Execution, Tooling, Context, Lifecycle, Observability, Verification, and Governance expose architectural boundaries that earlier frameworks often conflate.
A systematic mapping of the open-source ecosystem surfaces adoption patterns across sandboxes, protocols, memory systems, orchestrators, observability platforms, benchmarks, and governance stacks.
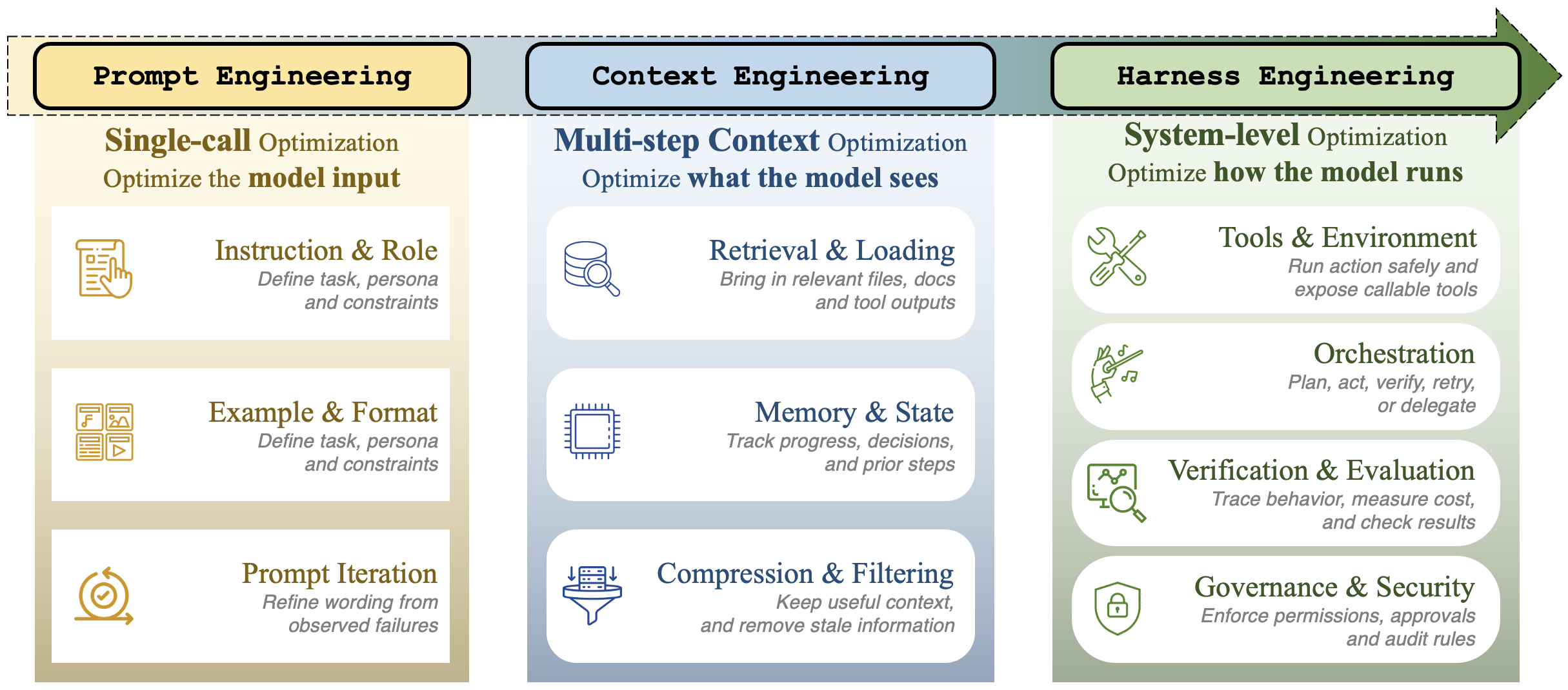
Read across 2022–2026, agent engineering has gone through a coherent shift in where the marginal effort lands. The three phases overlap in time and concept; they describe what the field has chosen to engineer, not a clean sequence of replacements.
Prompt engineering. The primary lever is the input prompt text: instructions, few-shot examples, and reasoning templates, all optimized for a single model call.
Context engineering. The question shifts from “what is the input?” to “what should the model see at each step?” The scope expands to retrieval, compaction, tool-result ranking, and managing context-window saturation across turns.
Harness engineering. As models become capable enough to attempt long-running tasks, the engineering focus expands to the full infrastructure wrapper: execution environment, tool interface, context, lifecycle, observability, verification, and governance.
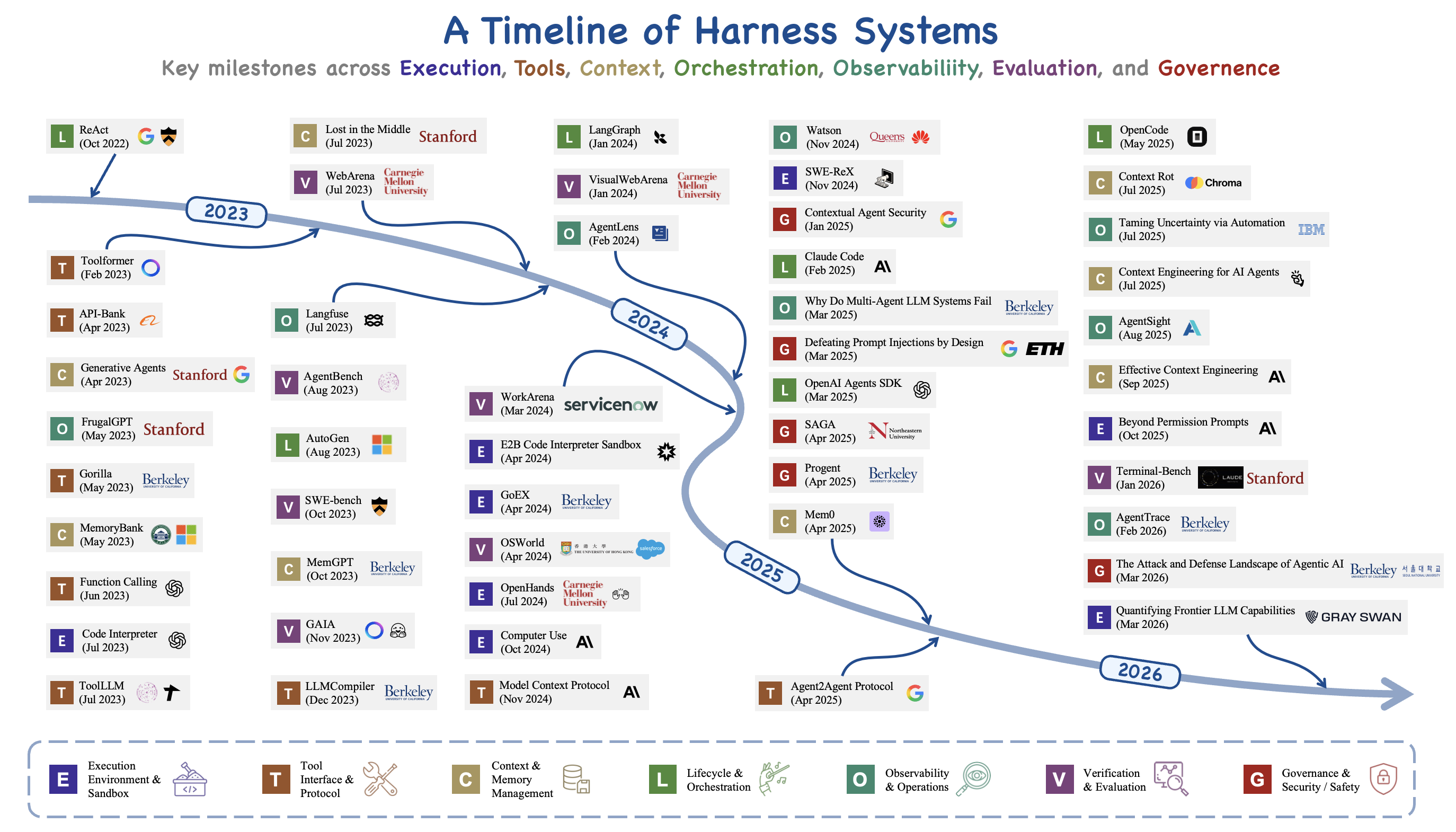
The same shift is visible in the systems themselves. The ReAct era of 2022–2023 wrapped a single model loop with a while-loop, a prompt template, and a small tool dispatch table; AutoGPT and BabyAGI exposed the resulting failures, including execution runaway, context blowout, state loss, and unmonitored side effects, as infrastructure problems rather than prompt problems. Tool integration and multi-agent coordination from 2023–2024 added learned tool use (Gorilla, ToolLLM, Toolformer), role-playing organizations (CAMEL, ChatDev, MetaGPT, Mixture-of-Agents), the first agent benchmarks (SWE-bench, AgentBench, WebArena, GAIA), and the beginnings of protocol standardization (MCP, A2A). By 2025–2026 enough deployment experience had accumulated that “harness engineering” began to be named as a discipline of its own, accompanied by automated harness optimization and a wave of results in which only the harness was varied.
We organize the harness into seven layers. The first four describe the structural core of a harness; the last three describe the control plane around it. Compared with earlier six-component frameworks, Observability and Governance appear here as independent layers because, in production deployments, each has its own tooling stack and is owned by a different team.
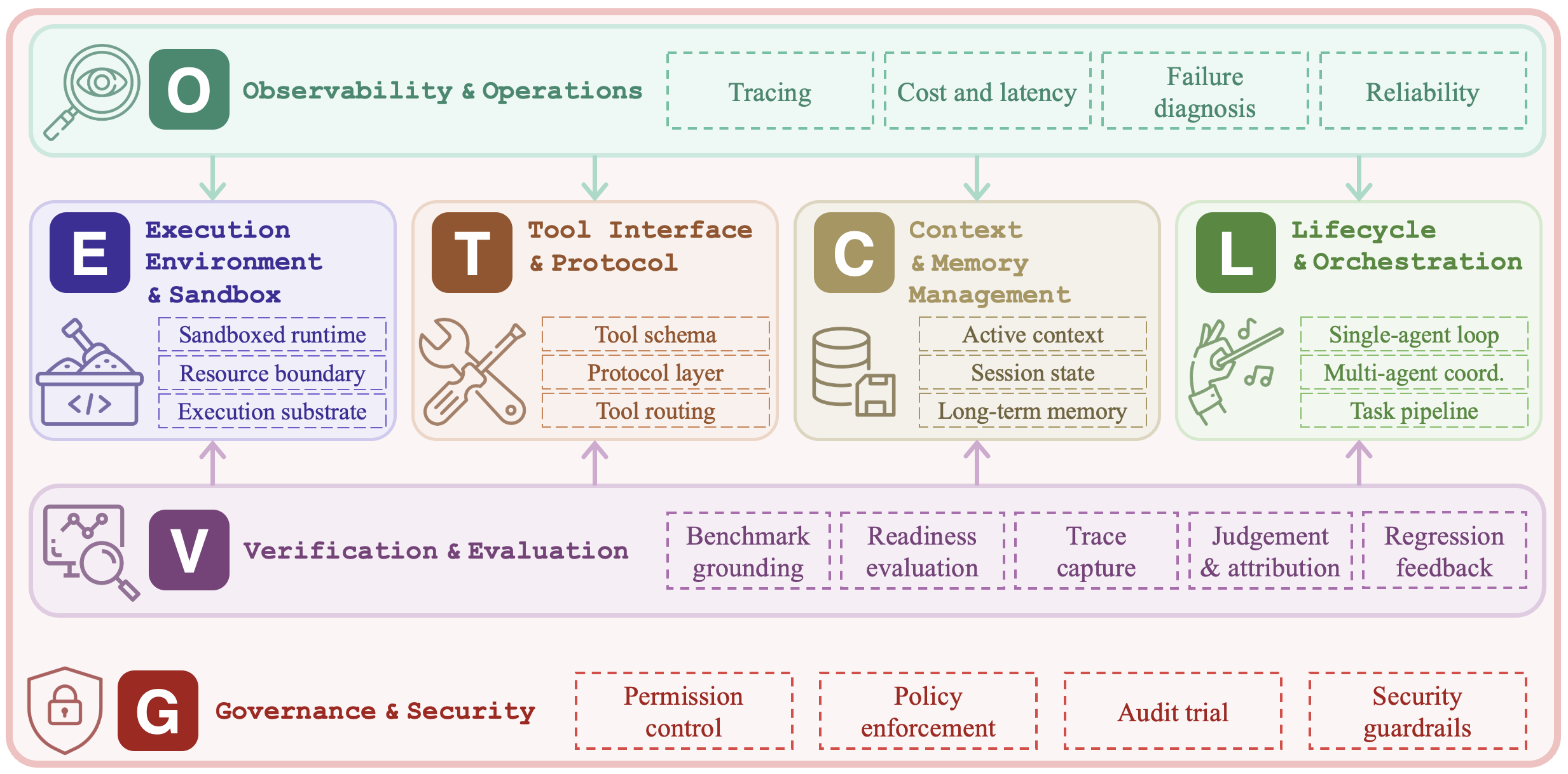
Execution environment. Determines where agent code runs and what sandbox constraints bound it: managed sandboxes, microVMs, code-specialized runtimes, computer-use environments, browser sandboxes, and OS-level permission models.
Tool interface and protocol. Specifies how external capabilities are described, discovered, and invoked, including protocol standards (MCP, A2A), tool description and selection, tool-augmented training, and session management.
Context and memory management. Controls what the model can see across short-term, session-level, and persistent horizons, including long-horizon context techniques and mitigations for context drift.
Lifecycle and orchestration. Organizes the control flow that reads and writes state, from the single-agent inner loop to multi-agent patterns and full issue-to-pull-request task pipelines.
Observability and operations. Captures traces, costs, failures, and reliability signals through tracing platforms, agent-specific operations tools, cost tracking, and unified observability.
Verification and evaluation. Turns tasks and traces into evaluation, failure attribution, and regression feedback, including benchmark grounding, controlled execution, multi-level judgement, and deployment-time evaluation loops.
Governance and security. Constrains behavior across model-level, system-level, and organizational-level sub-layers: permission models, lifecycle hooks, component hardening, declarative constitutions, and audit infrastructure.
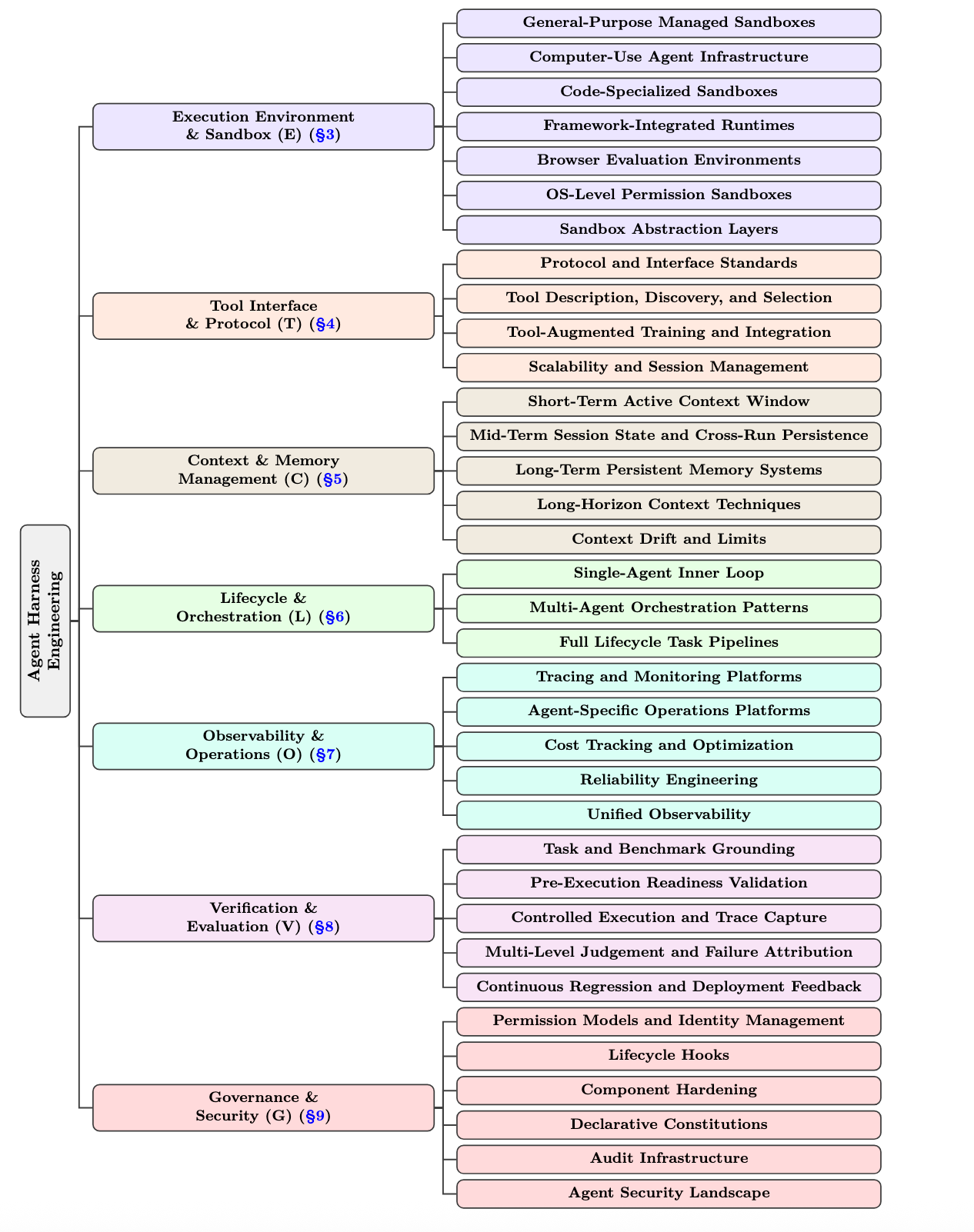
To make the taxonomy concrete, the survey codes a broad corpus of open-source agent-harness projects against ETCLOVG, using the public artifact itself (README files, documentation, papers, examples, release notes) as the evidence. The corpus is maintained as a living catalog at Awesome-Agent-Harness, and contributions are welcome through pull requests.
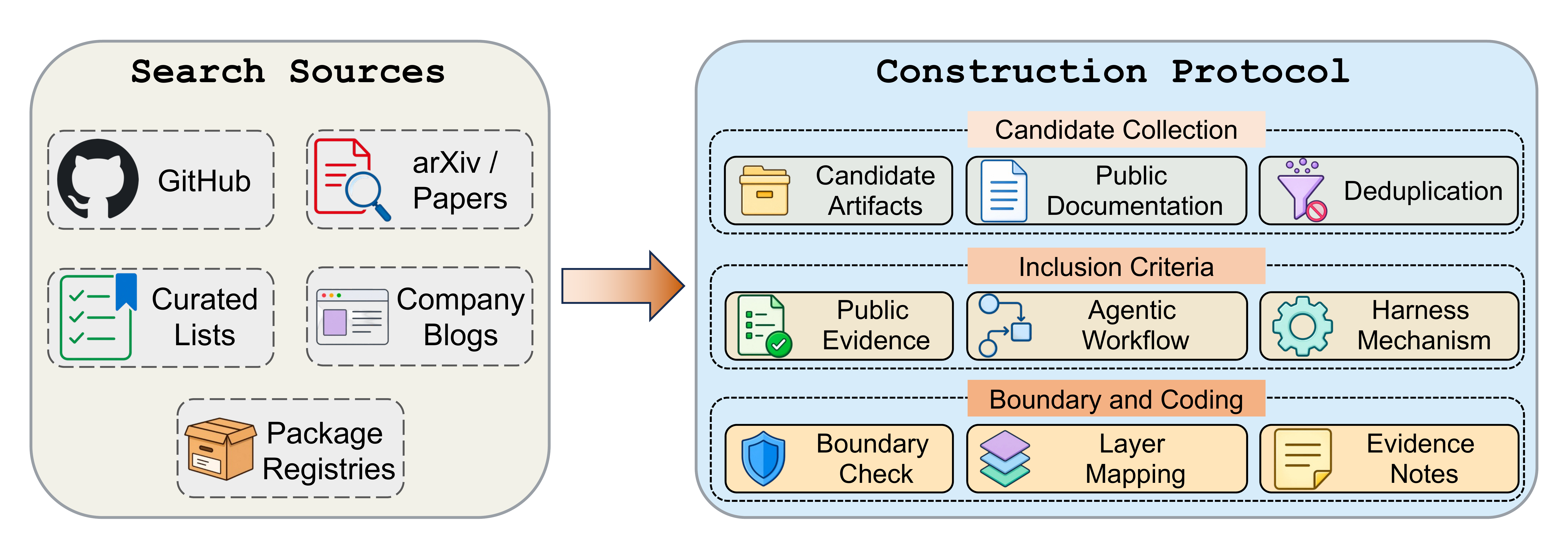
Coding is multi-label: a project's primary layer marks the mechanism most central to it, while secondary layers are assigned only when the public documentation exposes an independent capability. The counts below reflect primary assignments in the current snapshot.
| Layer | Scope | Primary projects |
|---|---|---|
| E | Execution environment & sandbox | 20 |
| T | Tool interface & protocol | 12 |
| C | Context & memory management | 9 |
| L | Lifecycle & orchestration | 47 |
| O | Observability & operations | 15 |
| V | Verification & evaluation | 21 |
| G | Governance & security | 14 |
Reading the corpus in aggregate, Execution, Tooling, Lifecycle, and Verification have the densest visible coverage: coding, web, terminal, and computer-use agents all require runnable environments, tool contracts, control loops, and repeatable evaluation before they can be useful. Context and memory appear across many projects but are often embedded inside larger frameworks rather than released as standalone components. Observability and Governance are thinner in open source and more often live inside commercial platforms, SDK features, or engineering writeups, suggesting that operational control has matured later than runtime and benchmark infrastructure.
Composing the seven layers creates system-level constraints that no single layer can resolve alone. The survey distils these effects into three recurring patterns.
A related shift runs through the corpus: from agent frameworks, which package local abstractions (agents, tools, memory, execution loops), to agent platforms, which add durable workspaces, identity, observability, evaluation, governance, and human handoff across many runs and many users.
Five questions remain open across the taxonomy. Each follows from the cross-layer synthesis rather than from a single ETCLOVG layer in isolation.
If you find this survey useful in your research, please consider citing:
@misc{li2026agentharness,
title={Agent Harness Engineering: A Survey},
author={Li, Junjie and Xiao, Xi and Zhang, Yunbei and Liu, Chen and
Zhao, Lin and Liao, Xiaoying and Ji, Yingrui and Wang, Janet and
Gu, Jianyang and Ge, Yingqiang and Xu, Weijie and Fang, Xi and
Xu, Xiang and Zhao, Tianchen and Kim, Youngeun and
Wang, Tianyang and Hamm, Jihun and Krishnaswamy, Smita and
Huan, Jun and Reddy, Chandan},
url={https://openreview.net/pdf?id=eONq7FdiHa},
year={2026}
}