Many AI memory systems are publishing scores on benchmarks that don’t measure what they claim to measure. We audited LoCoMo and found 6.4% of the answer key is wrong, the LLM judge accepts 63% of intentionally wrong answers, and 56% of per-category system comparisons are statistically indistinguishable from noise. LongMemEval-S fits entirely in modern context windows - it’s a context window test, not a memory test. Mem0’s answer generation prompt instructs the model to never acknowledge missing information: “If no relevant information is found, make sure you don’t say no information is found. Instead, accept the question and provide a general response.” The agentmemorybenchmark.ai site is a collection of these same flawed benchmark results bundled together.
Meanwhile, no one is prescribing a full end-to-end, apples-to-apples methodology. Each system uses its own ingestion, its own answer generation prompt, its own judge configuration, sometimes entirely different models. Scores are then published in the same table as if they share a common methodology. The Mem0/Zep benchmark dispute illustrates this perfectly: Mem0 reported Zep at 58.44% accuracy after replication; Zep claimed 75.14% after arguing their system was misconfigured in Mem0’s test; the disagreement extends to whether adversarial questions should be included, whether timestamp support was available at evaluation time, and which API version was tested. Both sides published in good faith, a third party cannot easily reproduce either result because the contested configuration choices (API version, category inclusion, timestamp support) aren’t prescribed by the benchmark. This is not an isolated incident - it’s the natural result of benchmarks that provide questions but not an end-to-end process.
The best strategy for a high LoCoMo score today is unfortunately context-stuffing and generating long, topically-adjacent answers that fool the judge.
We need a benchmark that actually tests what we care about: can your memory system make an AI agent a competent long-term colleague?
This proposal is an invitation to collaborate, not a finished specification. We’re looking for memory system builders, benchmark designers, and researchers who share the goal of honest measurement to help shape this into something the field can trust.
These come directly from our audit findings and group discussions with other builders.
A useful benchmark tests what memory systems actually do in production: manage a growing, evolving knowledge base. LongMemEval’s full corpus is ~57.5 million tokens across 500 questions, but each question only requires ~115K tokens of context - small enough that any frontier model can hold it in a single context window. An honest test requires ingesting the full 57.5M tokens and retrieving the right information from the whole corpus, but nothing stops a system from just stuffing each question’s 115K context and bypassing retrieval entirely.
Our target: 1–2 million tokens of total context. Large enough to approximate a real-world knowledge base - the kind of information a working professional accumulates over months of daily AI interactions. Small enough to be economically feasible to ingest and test against. The goal is not necessarily to exceed a particular context window but to require a memory system that can efficiently find the right information in a corpus too large and too interconnected for brute-force context stuffing alone to be practical. In any case, full transparency about the degree of context stuffing is required (see Principle 10).
LoCoMo tests recall of conversations between 10 pairs of random strangers engaged in disconnected chit-chat - roughly 17K tokens each. That's not what anyone is building a memory system for. Doctors need agents that track patient histories across hundreds of visits. Lawyers need agents that synthesize years of case work. Developers need agents that remember architectural decisions made six months ago. Even a personal assistant needs to connect your dietary restrictions to your travel plans to your team dinner next week. The benchmark should test the job the product is hired to do. We want to test what a real, persistent AI colleague can do: know your life, your work, your projects, your team, your family, your hobbies, your preferences, even your jokes. Can it switch topics effortlessly? Can it recall a decision from three weeks ago? Can it connect information across projects that were discussed in separate sessions?
The corpus should be: Many long, multi-session conversations between one person (or small team) and an AI assistant. Topics that shift naturally - work projects, personal preferences, travel planning, technical decisions, corrections of earlier statements, jokes, evolving relationships. Consistency throughout: the same people, the same ongoing projects, the same evolving facts.
Synthetic data, not real data. Real conversations have unsolvable privacy problems (scrubbing isn’t reliable, metadata leaks patterns). We generate the corpus using frontier models with careful steering, then human-verify the ground truth.
An alternative source of data we’re exploring is court documents released after the latest SOTA training cutoffs - public record, rich in factual detail, and not present in model training data.
Different architectures have fundamentally different ingestion strategies. Penfield lets the agent manage its own memory through tool calls. Virtual Context compresses and swaps context OS-style. Mem0 auto-extracts facts. Zep builds temporal knowledge graphs with validity-tracked relationships. Forcing everyone into the same ingestion pipeline would stifle innovation and inappropriately penalize architectures that don’t match the prescribed pattern.
Rule: Each system ingests the corpus however it wants. But it must publish:
Ingestion method (and prompt if applicable)
Model used for ingestion (if any)
Embedding model (if applicable)
Total tokens used to ingest and process
Total ingestion time
This becomes part of the score card, not hidden.
The current state: each system uses whatever answer generation prompt they want. EverMemOS uses chain-of-thought multi-step reasoning. Others use single-shot. You can’t compare a heavyweight to a featherweight.
Two tracks:
Standard track: Prescribed answer generation prompt, prescribed model, single-shot. This is the apples-to-apples comparison. Everyone uses the same prompt and model for the final answer. The only variable is what the memory system retrieves and presents.
Open track: Use whatever answer generation strategy you want (CoT, multi-step, custom prompts, retry logic). But you must publish the full methodology and the benchmark reports it separately. This is where you show what your system can really do - but it’s not directly comparable to systems on the standard track.
Both tracks score against the same questions and ground truth.
LoCoMo has an 8.8x ratio between its largest category (841 questions) and smallest (96 questions). The smallest category produces margins of error so wide that scores are noise. You shouldn’t put four category scores on the same chart when they have fundamentally different measurement precision.
Rule: Every category gets the same number of questions. The number per category must be large enough that a meaningful score difference between two systems is statistically distinguishable at 95% confidence. If a category is not important enough to measure to the same statistical significance as the other categories, it’s not important enough to measure in the first place.
Using Wilson Score intervals, 400 questions per category gives margins of error of ~3–4.5 points for systems scoring in the 70–90% range. With 6 categories (see below), that’s 2,400 questions total. This is a target - the right number may shift as we prototype and validate, but the principle of equal categories and sufficient sample sizes is non-negotiable.
LoCoMo’s 6.4% answer key error rate (99 errors in 1,540 questions) creates a noise floor that makes small score differences uninterpretable. The errors aren’t random - they cluster in specific categories (Open-domain has 9.4% error rate vs. Single-hop’s 4.3%), creating systematic bias.
Rule: Every question and answer must be reviewed by humans. Error rate target: <1%. The annotated ground truth should be published with inter-annotator agreement statistics.
We recognize that human verification at this scale (2,400 questions) is a significant undertaking. This is one reason we’re looking for collaborators. We’re also exploring complementary approaches to make this tractable:
Model council pre-screening: Use multiple frontier models as a first-pass review panel to flag obvious errors, disagreements, and ambiguous questions before human review. This doesn’t replace human verification - it focuses human attention where it’s most needed.
Public verification with incentives: A gamified public interface where contributors can review question-answer pairs and flag errors, with bounties for confirmed discoveries. Wisdom of crowds at scale, with individual contributions validated against the model council and human expert panel.
Iterative release: Start with a rigorously verified pilot set (e.g., 600 questions across 6 categories), expand as verification resources grow.
The combination - model council filters, crowd-sourced review, expert tiebreakers - can achieve the <1% error target without requiring a small team to manually verify 2,400 pairs in isolation.
LoCoMo’s gpt-4o-mini judge accepts 62.81% of intentionally wrong answers. The failure mode: vague answers that identify the correct topic while missing every specific detail pass nearly two-thirds of the time. This is exactly what weak retrieval produces - finding the right conversation but extracting nothing specific - and the benchmark rewards it.
Rule: The judge is validated before the benchmark launches. We generate intentionally wrong answers (wrong name, wrong date, topically-adjacent-but-wrong, vague-but-on-topic) and verify that the judge rejects them at >95%. Task-specific rubrics where needed. Judge model must be current-generation frontier (not gpt-4o-mini).
Mem0’s answer generation prompt instructs: “If no relevant information is found, make sure you don’t say no information is found. Instead, accept the question and provide a general response.” This rewards hallucination.
Rule: The scoring system explicitly handles abstention. Saying “I don’t know” or “I don’t have that information” when the answer IS in the corpus gets a lower score than a correct answer - but a HIGHER score than a confidently wrong answer. A memory system that knows its limits is more useful than one that makes things up.
Scoring:
Correct answer: 1.0
Correct abstention (answer not in corpus - adversarial question): 1.0
Incorrect abstention (answer IS in corpus, system says “I don’t know” - still better than a hallucinated answer): 0.10
Wrong answer (confident but incorrect): 0.0
Wrong answer on adversarial question (hallucinated answer to unanswerable question): 0.0
Consider the real-world version of this tradeoff. Your agent is helping you make a critical decision - a medical dosage, a legal filing deadline, a production deployment. Would you rather hear “I’m not sure, let me look further,” or get a confident wrong answer? In practice, when an agent says “I don’t know,” you rephrase the question, add context, or check another source. When an agent gives you a confidently wrong answer, you may act on it and in some cases an action based on incorrect information is disastrous. The cost asymmetry can be enormous.
Open question for the group: should confident wrong answers receive negative scores? The current scoring gives wrong answers 0.0, but a case can be made that a system which confidently fabricates information is actively worse than one that retrieves nothing at all. A negative penalty (e.g., -0.5 for a wrong answer, -1.0 for a hallucinated answer on an adversarial question) would more accurately reflect the real-world cost of false confidence. We would like input on this - the right calibration matters.
A single accuracy number hides interesting data useful in an apples-to-apples comparison. A 7,000-token retrieval operation is not comparable to a 1,200-token one if they yield the same accuracy.
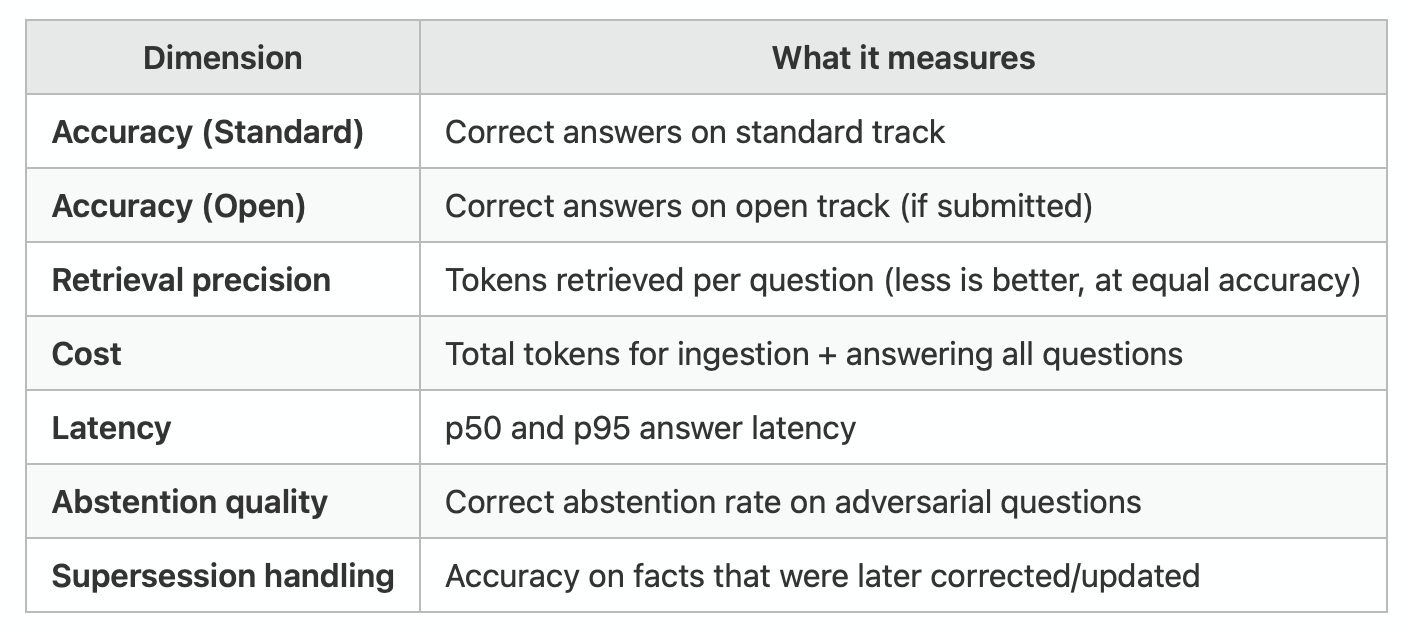
A composite score for quick comparison could be generated, with the explicit caveat that it compresses important tradeoffs. The dimensional breakdown is the primary view - the composite exists for convenience, not as the final word. Both will include confidence intervals and number of runs, so readers can judge for themselves whether differences between systems are meaningful or noise.
Current benchmarks don’t measure how much context a system injects into the answer generation prompt. A system that stuffs 20K tokens of retrieved context to answer a simple factual question “works” but is expensive relative to a system that retrieves only 500 targeted tokens to generate the same answer.
Rule: Systems must report the token count of context provided to the answer generation model for each question. This becomes part of the retrieval precision score.
Six categories, 400 questions each, 2,400 total. Categories informed by group discussion, existing benchmark designs (including LoCoMo's temporal and multi-hop categories and LoCoMo-Plus's cognitive inference concept), and gaps identified by multiple independent researchers.
Can you retrieve a specific fact that was stated explicitly?
“What restaurant did I recommend to Sarah for her birthday dinner?”
Baseline capability. Every memory system should handle this.
Can you reason about when things happened and how facts changed over time?
“Before I switched to the new project management tool, what were my complaints about the old one?”
Tests temporal awareness, not just fact lookup.
Can you connect information from different conversations to answer a question that was never explicitly discussed?
“Given my dietary restrictions and the restaurant preferences I mentioned, where should my team go for the client dinner?”
Tests graph traversal / knowledge connection.
Can you track when facts have been updated, corrected, or superseded?
“What’s my current stance on using TypeScript for the backend?” (when the user changed their mind across sessions)
Tests whether the system surfaces the current state, not stale information.
Can you make connections that require understanding implications rather than explicit statements?
“I just adopted a rescue dog. What kind of supplies should I get?” (when the user previously mentioned they live in a small apartment with no yard)
Borrows from LoCoMo-Plus’s cognitive category concept - the useful part of that paper.
Can you correctly identify when you DON’T have the information?
Questions that are topically adjacent to things in the corpus but whose answers are NOT present.
“What was the final budget for the Q3 marketing campaign?” (when Q3 budget was never discussed, only Q2)
Tests hallucination resistance. This replaces LoCoMo’s broken Cat 5 (446 questions with no ground truth).
Open design problem: A system that responds to "What was the Q3 budget?" with "We never discussed Q3 budgets, but we did discuss Q2 - here's what we concluded" is more useful than one that simply says "I don't know." But a keyword-matching or pattern-matching judge will mark the helpful correction as wrong because it doesn't match the expected abstention format. This is likely part of the reason why few projects run LoCoMo's Category 5. Solving this - scoring helpful corrections higher than bare abstention without rewarding hallucination - is a judging design problem in need of community input.
Use frontier models (Opus, Gemini Pro, GPT-5.x, etc. ) to generate synthetic multi-session conversations with careful steering. Each generation pass gets a different instruction:
A) Continue existing thread - natural progression of an ongoing topic
B) Reference back - pick up an earlier thread and continue it with new context
C) Start new thread - introduce a new topic area
D) Establish memorable detail - state a preference, fact, or personal detail that could be relevant to other threads (1 in 5 chance)
E) Supersede earlier fact - correct or update something previously stated (1 in ~8 chance)
The corpus represents one person’s AI interactions over ~6 months. Mix of work (multiple projects, team decisions, technical choices), personal (preferences, relationships, travel, health), and cross-domain (work decisions informed by personal context).
An alternative data source under consideration is public court documents released after current SOTA training cutoffs - these provide rich, factual, multi-party narratives that are public record and verifiably absent from model training data.
Why court documents may be preferable to synthetic data: Synthetic conversations generated by frontier models carry a fundamental verification problem. We can painstakingly verify that each question-answer pair ties back to a specific line in the corpus (e.g., “What is Susan’s dog’s name?” → “Fido” → Discussion 3, line 493). But if Discussion 7, line 794 also mentions Susan’s dog as “Rex” - an unintentional contradiction introduced by the generating model - nobody will catch it without reading the entire 1-2 million token corpus end to end. Court documents don’t have this problem: they’re authored by humans with legal accountability for consistency, they contain rich factual detail, they’re public record, and documents released after SOTA training cutoffs are verifiably absent from model training data.
That said, synthetic data gives us control over topic distribution, supersession frequency, and category balance that court documents don’t. The right answer may be a hybrid approach. This is one of several areas that could benefit from collaborator input.
Contradiction detection as a verification target: Regardless of which data source we use, finding unintentional contradictions in the corpus is itself a valuable task. We plan to include contradiction discovery in the public bounty/gamification layer - finding a genuine corpus contradiction that affects a scored question is exactly the kind of error that should carry a bounty.
Generate conversations with frontier model
Generate question-answer pairs targeting each category
Model council pre-screening: multiple frontier models flag errors, ambiguities, disagreements
Human annotators verify, with priority given to model-council-flagged items
Public verification bounty: a crowd-sourced review interface where contributors flag errors in question-answer pairs, with bounties for confirmed discoveries. We're seeding the pool with $500 USD and invite others to contribute.
Adversarial validation: generate intentionally wrong answers, verify judge rejects >95%
Publish inter-annotator agreement statistics and model council concordance rates
~50–80 conversation sessions
~1–2M total tokens
2,400 questions (400 per category)
All questions against the SAME corpus (not independent contexts per question like LongMemEval-S)
One of the many problems with current benchmarks is that multiple systems have reported scores using different models in the same table as if they are comparable. A system tested with GPT-4o-mini and a system tested with Claude Sonnet 4.6 cannot be meaningfully compared on the same leaderboard - differences in the reader model dominate differences in the memory architecture.
Our approach:
Reference configuration: The benchmark ships with a specific reference model and prompt for the standard track (e.g., Claude Sonnet 4.6 at launch). This is the baseline everyone can run for direct comparison.
Alternative models are welcome on both standard and open tracks, but must be clearly labeled. Scores from different reader models are reported in separate tables, never mixed.
Minimum disclosure for non-reference models: exact model version string, temperature, max tokens, any system prompt modifications (if any). This provides the framework for a third party to reproduce the result.
Cross-model comparison is explicitly flagged as invalid. The benchmark documentation, leaderboard UI, and score cards will state this clearly. No one can enforce it in the wild, but we can make it impossible to mix models without visibly violating the reference methodology.
When the reference model is updated (new model generation, deprecation), we publish a new benchmark season with updated reference scores. Prior seasons remain valid for within-season comparisons.
Not prescribing ingestion method. Each system handles this its own way. Just disclose it.
Not requiring a specific embedding model. Some systems don’t even use embeddings.
Not testing with outdated models. Judge and standard-track answer generation use current frontier models. We’re building memory systems for where models are going, not where they were.
Not making it cost-prohibitive to run. Processing tens or hundreds of millions of tokens with SOTA models is clearly out of reach for independent researchers and small teams. We want this benchmark to be accessible - SOTA models on a corpus sized to require real retrieval, at a cost that allows honest iteration.
Not handing down a tablet from on high. This is a proposal and an invitation to collaborate. The design will evolve based on feedback, pilot results, and contributions from other builders and researchers.
Corpus size sweet spot. We suggested 1-2M tokens. Virtual Context work suggests 3M is a natural breakpoint. Is that the right range? What’s the minimum to genuinely require retrieval vs. the maximum that’s still affordable?
Multiple runs and variance. Should the benchmark require multiple runs and report standard deviation? Mem0 does this in their LoCoMo submission, but most systems don’t. We could require 3 runs minimum, report mean ± std.
Second-attempt scoring. Should the benchmark give an opportunity for a second recall attempt, scored differently than first recall? It’s real-world behavior (”look harder, I know we discussed this, it was last August when we were working on…”) but it complicates both the benchmark pipeline and the scoring.
Incremental vs. batch ingestion. Should we offer both modes? (a) Feed all sessions at once (batch), (b) Feed session by session chronologically (incremental, models real usage). We’d argue for the latter because it more closely mirrors real world usage.
Repo and governance. Joint GitHub org? Who maintains the ground truth? How do we handle disputes about specific Q&A pairs?
Verification scale. What’s the right balance between model council pre-screening, crowd-sourced review, and expert human verification? How do we fund the human verification layer at 2,400 questions?
Discuss this proposal. Rip it apart. What’s missing? What’s wrong?
Agree on corpus parameters (size, session count, topic mix)
Prototype the generation pipeline - generate 2–3 sample sessions with the steering approach and see if the output is realistic enough
Set up a joint repo
Generate a pilot set - 50 questions across all 6 categories, human-verify, test judge reliability
Iterate based on pilot results
Ahmed Kidwai (ahmed@kidw.ai) - Virtual Context architecture insights and corpus design feedback.
Rohit Hazra (rohithzr) and Tomas Pflanzer (gizmax) who published independent third-party benchmark results demonstrating the importance of third-party replicability.
This is a living list. If you contributed to the discussions that shaped this proposal and would like to be credited, get in touch.
locomo-audit - Full audit with all 99 errors documented
STATISTICAL_VALIDITY.md - Wilson Score CI analysis
LoCoMo paper - Maharana et al., ACL 2024
LongMemEval - Wu et al., 2024
LoCoMo-Plus - Li et al., 2026
Evo-Memory (Google DeepMind) - Wei et al., 2025
MAGMA - Jiang et al., 2026
BEAM - Tavakoli et al., 2025
Northcutt et al. (NeurIPS 2021) - Label errors in major ML benchmarks
Virtual Context paper - Context virtualization and compression
Mastra observational memory research - Observation-based compression system; 94.87% on LongMemEval with GPT-5 Mini, also published full-context baseline comparisons
Mem0/Zep benchmark dispute - Methodology disagreement illustrating the need for standardized evaluation
Mem0 answer prompt - “make sure you don’t say no information is found”