Full Code and IR Dumps to Follow Along - https://github.com/patrick-toulme/justabyte/tree/main/tpu_compiler_post
Eight lines of JAX code in Python become 250 VLIW bundles across 5 fused kernels. A matrix multiply, RMS normalization, softmax, and another matrix multiply — the kind of operation that runs billions of times inside every transformer. Here’s what happens between jax.jit(f)(x) and electrons moving through a TPU.
There’s surprisingly little public information about this — Google’s TPU compiler is closed-source, and the internal IRs are undocumented. I rented a TPU v6e for under a dollar and traced a small computation through four layers of compiler IR.
The key insight: TPUs reward experimentation. GPUs have automatic codegen too — Inductor, XLA, Triton — but in practice, peak performance often still requires hand-tuned kernels. FlashAttention exists because no compiler found that optimization automatically. The TPU compiler gets you closer to the ceiling without manual intervention: it fuses operations, schedules hardware, and orchestrates memory in ways that would require expert kernel engineering on GPU. The performance ceiling might be lower than a perfect custom kernel, but the floor is much higher. This post shows exactly how that works.
Whether you’re debugging why a custom op is slow, deciding between TPUs and GPUs for a new workload, or just curious what jax.jit actually does — this post traces the full compilation path with real IR dumps.
I have rented a TPU V6e Trillium on Google Cloud for these experiments. The cost is pretty minimal. I think this entire experiment was under one dollar.

I have written some simple Jax code that we can use to trace the TPU’s compilation.
import os
# Create dump directories
DUMP_ROOT = "compiler_dump/"
HLO_DUMP_PATH = os.path.join(DUMP_ROOT, "hlo")
LLO_DUMP_PATH = os.path.join(DUMP_ROOT, "llo")
os.makedirs(HLO_DUMP_PATH, exist_ok=True)
os.makedirs(LLO_DUMP_PATH, exist_ok=True)
os.environ["XLA_FLAGS"] = (
f"--xla_dump_hlo_as_text "
f"--xla_dump_to={HLO_DUMP_PATH} "
f"--xla_dump_hlo_pass_re=.* "
)
os.environ["LIBTPU_INIT_ARGS"] = (
f"--xla_jf_dump_to={LLO_DUMP_PATH} "
f"--xla_jf_dump_hlo_text=true "
f"--xla_jf_dump_llo_text=true "
f"--xla_jf_dump_llo_html=false "
f"--xla_jf_dump_llo_static_gaps=true "
f"--xla_jf_emit_annotations=true "
f"--xla_jf_debug_level=2"
)
# Import JAX after setting env vars
import jax
import jax.numpy as jnp
@jax.named_call
def matmul_1(x, w1):
"""Stage 1: Linear projection (like Q @ K^T)"""
return x @ w1
@jax.named_call
def rms_norm(h):
"""Stage 2: RMS Normalization"""
rms = jnp.sqrt(jnp.mean(h ** 2, axis=-1, keepdims=True) + 1e-6)
return h / rms
@jax.named_call
def softmax(h):
"""Stage 3: Softmax (row-wise, numerically stable)"""
h_max = jnp.max(h, axis=-1, keepdims=True)
exp_h = jnp.exp(h - h_max)
return exp_h / jnp.sum(exp_h, axis=-1, keepdims=True)
@jax.named_call
def matmul_2(h, w2):
"""Stage 4: Output projection (like attention @ V)"""
return h @ w2
def mini_attention(x, w1, w2):
"""
A minimal attention-like block:
matmul → rms_norm → softmax → matmul
"""
h = matmul_1(x, w1)
h = rms_norm(h)
h = softmax(h)
out = matmul_2(h, w2)
return out
def main():
# Small shapes to keep IR readable
batch, d_in, d_mid, d_out = 16, 64, 64, 32
# Create inputs
key = jax.random.PRNGKey(42)
k1, k2, k3 = jax.random.split(key, 3)
x = jax.random.normal(k1, (batch, d_in))
w1 = jax.random.normal(k2, (d_in, d_mid)) * 0.02
w2 = jax.random.normal(k3, (d_mid, d_out)) * 0.02
# JIT compile and run
jitted_fn = jax.jit(mini_attention)
# First call triggers compilation (and IR dump)
result = jitted_fn(x, w1, w2)
# Block until computation is done
result.block_until_ready()
print(f"Input shape: {x.shape}")
print(f"Output shape: {result.shape}")
print(f"Output sample: {result[0, :5]}")
print(f"\nDumps written to:")
print(f" HLO: {HLO_DUMP_PATH}")
print(f" LLO: {LLO_DUMP_PATH}")
if __name__ == "__main__":
main()
The above Jax code is really just a compiled matmul + rms_norm + softmax + matmul. We jit the computation with jax.jit. Jax then traces this computation into HLO (High Level Operations) IR. HLO is heavily open source - HLO.

At a high level the TPU compiler pipeline is Jax→HLO→LLO→VLIW bundles. Technically there are other stages, such as StableHLO, Jaxpr, TPU TLP etc., but for our purposes we can follow this diagram.
The frontend TPU compiler uses XLA as it’s primary infrastructure. XLA works off an IR called HLO (High Level Operations), which is an SSA graph IR.
There is some information publicly available on the frontend TPU HLO compiler and some open sourcing at OpenXLA.
This is similar to PyTorch FX IR.
HloModule jit_mini_attention, entry_computation_layout={(f32[16,64]{1,0:T(8,128)}, f32[64,64]{1,0:T(8,128)}, f32[64,32]{0,1:T(8,128)})->f32[16,32]{1,0:T(8,128)}}, allow_spmd_sharding_propagation_to_parameters={true,true,true}, allow_spmd_sharding_propagation_to_output={true}
%region_0.15 (Arg_0.12: f32[], Arg_1.13: f32[]) -> f32[] {
%Arg_0.12 = f32[] parameter(0), metadata={op_name="jit(mini_attention)/jit(main)/rms_norm/reduce_sum"}
%Arg_1.13 = f32[] parameter(1), metadata={op_name="jit(mini_attention)/jit(main)/rms_norm/reduce_sum"}
ROOT %add.14 = f32[] add(%Arg_0.12, %Arg_1.13), metadata={op_name="jit(mini_attention)/jit(main)/rms_norm/reduce_sum" source_file="/home/ptoulme/tpu.py" source_line=41}
}
%region_1.28 (Arg_0.25: f32[], Arg_1.26: f32[]) -> f32[] {
%Arg_0.25 = f32[] parameter(0), metadata={op_name="jit(mini_attention)/jit(main)/softmax/reduce_max"}
%Arg_1.26 = f32[] parameter(1), metadata={op_name="jit(mini_attention)/jit(main)/softmax/reduce_max"}
ROOT %maximum.27 = f32[] maximum(%Arg_0.25, %Arg_1.26), metadata={op_name="jit(mini_attention)/jit(main)/softmax/reduce_max" source_file="/home/ptoulme/tpu.py" source_line=48}
}
%region_2.39 (Arg_0.36: f32[], Arg_1.37: f32[]) -> f32[] {
%Arg_0.36 = f32[] parameter(0), metadata={op_name="jit(mini_attention)/jit(main)/softmax/reduce_sum"}
%Arg_1.37 = f32[] parameter(1), metadata={op_name="jit(mini_attention)/jit(main)/softmax/reduce_sum"}
ROOT %add.38 = f32[] add(%Arg_0.36, %Arg_1.37), metadata={op_name="jit(mini_attention)/jit(main)/softmax/reduce_sum" source_file="/home/ptoulme/tpu.py" source_line=50}
}
ENTRY %main.47 (Arg_0.1: f32[16,64], Arg_1.2: f32[64,64], Arg_2.3: f32[64,32]) -> f32[16,32] {
%Arg_0.1 = f32[16,64]{1,0} parameter(0), metadata={op_name="x"}
%Arg_1.2 = f32[64,64]{1,0} parameter(1), metadata={op_name="w1"}
%dot.10 = f32[16,64]{1,0} dot(%Arg_0.1, %Arg_1.2), lhs_contracting_dims={1}, rhs_contracting_dims={0}, metadata={op_name="jit(mini_attention)/jit(main)/matmul_1/dot_general" source_file="/home/ptoulme/tpu.py" source_line=35}
%multiply.11 = f32[16,64]{1,0} multiply(%dot.10, %dot.10), metadata={op_name="jit(mini_attention)/jit(main)/rms_norm/integer_pow" source_file="/home/ptoulme/tpu.py" source_line=41}
%constant.9 = f32[] constant(0)
%reduce.16 = f32[16]{0} reduce(%multiply.11, %constant.9), dimensions={1}, to_apply=%region_0.15, metadata={op_name="jit(mini_attention)/jit(main)/rms_norm/reduce_sum" source_file="/home/ptoulme/tpu.py" source_line=41}
%reshape.17 = f32[16,1]{1,0} reshape(%reduce.16), metadata={op_name="jit(mini_attention)/jit(main)/rms_norm/broadcast_in_dim" source_file="/home/ptoulme/tpu.py" source_line=41}
%constant.6 = f32[] constant(64)
%broadcast.7 = f32[16,1]{1,0} broadcast(%constant.6), dimensions={}
%divide.18 = f32[16,1]{1,0} divide(%reshape.17, %broadcast.7), metadata={op_name="jit(mini_attention)/jit(main)/rms_norm/div" source_file="/home/ptoulme/tpu.py" source_line=41}
%constant.4 = f32[] constant(1e-06)
%broadcast.5 = f32[16,1]{1,0} broadcast(%constant.4), dimensions={}
%add.19 = f32[16,1]{1,0} add(%divide.18, %broadcast.5), metadata={op_name="jit(mini_attention)/jit(main)/rms_norm/add" source_file="/home/ptoulme/tpu.py" source_line=41}
%sqrt.20 = f32[16,1]{1,0} sqrt(%add.19), metadata={op_name="jit(mini_attention)/jit(main)/rms_norm/sqrt" source_file="/home/ptoulme/tpu.py" source_line=41}
%broadcast.21 = f32[16,1]{1,0} broadcast(%sqrt.20), dimensions={0,1}, metadata={op_name="jit(mini_attention)/jit(main)/rms_norm/div" source_file="/home/ptoulme/tpu.py" source_line=42}
%reshape.22 = f32[16]{0} reshape(%broadcast.21), metadata={op_name="jit(mini_attention)/jit(main)/rms_norm/div" source_file="/home/ptoulme/tpu.py" source_line=42}
%broadcast.23 = f32[16,64]{1,0} broadcast(%reshape.22), dimensions={0}, metadata={op_name="jit(mini_attention)/jit(main)/rms_norm/div" source_file="/home/ptoulme/tpu.py" source_line=42}
%divide.24 = f32[16,64]{1,0} divide(%dot.10, %broadcast.23), metadata={op_name="jit(mini_attention)/jit(main)/rms_norm/div" source_file="/home/ptoulme/tpu.py" source_line=42}
%constant.8 = f32[] constant(-inf)
%reduce.29 = f32[16]{0} reduce(%divide.24, %constant.8), dimensions={1}, to_apply=%region_1.28, metadata={op_name="jit(mini_attention)/jit(main)/softmax/reduce_max" source_file="/home/ptoulme/tpu.py" source_line=48}
%reshape.30 = f32[16,1]{1,0} reshape(%reduce.29), metadata={op_name="jit(mini_attention)/jit(main)/softmax/broadcast_in_dim" source_file="/home/ptoulme/tpu.py" source_line=48}
%broadcast.31 = f32[16,1]{1,0} broadcast(%reshape.30), dimensions={0,1}, metadata={op_name="jit(mini_attention)/jit(main)/softmax/sub" source_file="/home/ptoulme/tpu.py" source_line=49}
%reshape.32 = f32[16]{0} reshape(%broadcast.31), metadata={op_name="jit(mini_attention)/jit(main)/softmax/sub" source_file="/home/ptoulme/tpu.py" source_line=49}
%broadcast.33 = f32[16,64]{1,0} broadcast(%reshape.32), dimensions={0}, metadata={op_name="jit(mini_attention)/jit(main)/softmax/sub" source_file="/home/ptoulme/tpu.py" source_line=49}
%subtract.34 = f32[16,64]{1,0} subtract(%divide.24, %broadcast.33), metadata={op_name="jit(mini_attention)/jit(main)/softmax/sub" source_file="/home/ptoulme/tpu.py" source_line=49}
%exponential.35 = f32[16,64]{1,0} exponential(%subtract.34), metadata={op_name="jit(mini_attention)/jit(main)/softmax/exp" source_file="/home/ptoulme/tpu.py" source_line=49}
%reduce.40 = f32[16]{0} reduce(%exponential.35, %constant.9), dimensions={1}, to_apply=%region_2.39, metadata={op_name="jit(mini_attention)/jit(main)/softmax/reduce_sum" source_file="/home/ptoulme/tpu.py" source_line=50}
%reshape.41 = f32[16,1]{1,0} reshape(%reduce.40), metadata={op_name="jit(mini_attention)/jit(main)/softmax/broadcast_in_dim" source_file="/home/ptoulme/tpu.py" source_line=50}
%broadcast.42 = f32[16,1]{1,0} broadcast(%reshape.41), dimensions={0,1}, metadata={op_name="jit(mini_attention)/jit(main)/softmax/div" source_file="/home/ptoulme/tpu.py" source_line=50}
%reshape.43 = f32[16]{0} reshape(%broadcast.42), metadata={op_name="jit(mini_attention)/jit(main)/softmax/div" source_file="/home/ptoulme/tpu.py" source_line=50}
%broadcast.44 = f32[16,64]{1,0} broadcast(%reshape.43), dimensions={0}, metadata={op_name="jit(mini_attention)/jit(main)/softmax/div" source_file="/home/ptoulme/tpu.py" source_line=50}
%divide.45 = f32[16,64]{1,0} divide(%exponential.35, %broadcast.44), metadata={op_name="jit(mini_attention)/jit(main)/softmax/div" source_file="/home/ptoulme/tpu.py" source_line=50}
%Arg_2.3 = f32[64,32]{1,0} parameter(2), metadata={op_name="w2"}
ROOT %dot.46 = f32[16,32]{1,0} dot(%divide.45, %Arg_2.3), lhs_contracting_dims={1}, rhs_contracting_dims={0}, metadata={op_name="jit(mini_attention)/jit(main)/matmul_2/dot_general" source_file="/home/ptoulme/tpu.py" source_line=56}
}
The above HLO is the output of the Jax tracer after converting from StableHLO to HLO. No optimization passes have been performed yet.
We can clearly see - instructions, shapes, dtypes and metadata.
The XLA compiler ran 71 optimization passes on this module. Here are the key transformations for our small toy program.
The algebraic simplifier runs early in the pipeline (pass #6). The Algebraic Simplifier is open source at OpenXLA - algebraic_simplifier.cc The pass is nearly 10k lines of CPP code. One optimization is converting division by constants to multiplication:
// Before (pass #5)
%constant.6 = f32[] constant(64)
%broadcast.7 = f32[16,1]{1,0} broadcast(%constant.6), dimensions={}
%divide.18 = f32[16,1]{1,0} divide(%reshape.17, %broadcast.7)
// After (pass #6)
%constant = f32[] constant(0.015625)
%broadcast = f32[16,1]{1,0} broadcast(%constant), dimensions={}
%multiply = f32[16,1]{1,0} multiply(%reshape.17, %broadcast)
Division is expensive on most hardware. The compiler precomputes 1/64 = 0.015625 and converts the divide to a multiply. We see this in our toy program.
Layout assignment and tiling (pass #25 → #29) adds TPU tile annotations to all shapes.
Layout assignment is partially open source at OpenXLA - layout_assignment.cc
// Before
%dot.10 = f32[16,64]{1,0} dot(...)
%reduce.16 = f32[16]{0} reduce(...)
// After
%dot.10 = f32[16,64]{1,0:T(8,128)} dot(...)
%reduce.16 = f32[16]{0:T(128)} reduce(...)
The {1,0} specifies row-major layout (the last dimension is contiguous in memory). The :T(8,128) is TPU-specific tiling — the tensor is divided into tiles of 8 rows × 128 columns, matching the VPU's 8 sublanes × 128 lanes.
The fusion pass (pass #38-39) combines independent HLO operations into fused kernels.
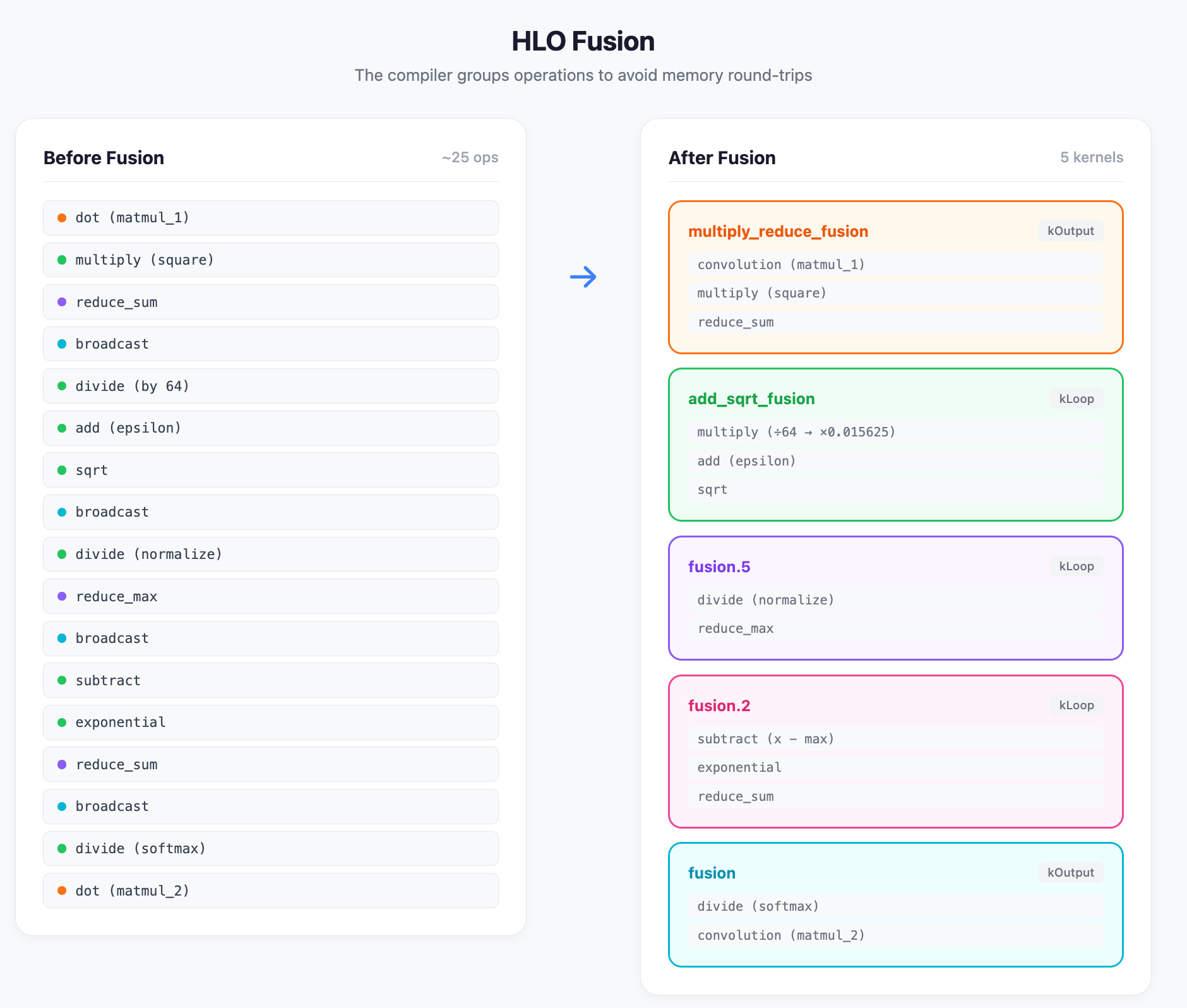
The TPU HLO fusion pass is also open source at OpenXLA - instruction_fusion.cc
ENTRY %main.47 (Arg_0.1: f32[16,64], Arg_1.2: f32[64,64], Arg_2.3: f32[64,32]) -> f32[16,32] {
%Arg_0.1 = f32[16,64]{1,0:T(8,128)} parameter(0), metadata={op_name="x"}
%Arg_1.2 = f32[64,64]{1,0:T(8,128)} parameter(1), metadata={op_name="w1"}
%Arg_2.3 = f32[64,32]{0,1:T(8,128)} parameter(2), metadata={op_name="w2"}
%convolution = f32[16,64]{1,0:T(8,128)} convolution(%Arg_0.1, %Arg_1.2), dim_labels=bf_io->bf
%multiply_reduce_fusion = f32[16]{0:T(128)} fusion(%convolution), kind=kLoop, calls=%fused_computation.3
%add_sqrt_fusion = f32[16]{0:T(128)} fusion(%multiply_reduce_fusion), kind=kLoop, calls=%fused_computation.9
%fusion.5 = f32[16]{0:T(128)} fusion(%convolution, %add_sqrt_fusion), kind=kLoop, calls=%fused_computation.8
%fusion.2 = f32[16]{0:T(128)} fusion(%fusion.5, %convolution, %add_sqrt_fusion), kind=kLoop, calls=%fused_computation.4
ROOT %fusion = f32[16,32]{1,0:T(8,128)} fusion(%Arg_2.3, %fusion.2, %fusion.5, %convolution, %add_sqrt_fusion), kind=kOutput
}
The original ~25 HLO ops collapse into 6 operations. Each fusion wraps multiple operations into a single kernel. The kind=kLoop indicates elementwise fusion; kind=kOutput indicates producer-consumer fusion (the producer’s output is immediately consumed).
Note that dot became convolution — the TPU compiler canonicalizes matrix multiplications this way, likely because both operations map to the same MXU hardware.
Each fusion has a body. The add_sqrt_fusion contains:
%fused_computation.9 (param_0.29: f32[16]) -> f32[16] {
%param_0.29 = f32[16]{0:T(128)} parameter(0)
%constant.12 = f32[] constant(0.015625)
%broadcast.37 = f32[16]{0:T(128)} broadcast(%constant.12), dimensions={}
%multiply.7 = f32[16]{0:T(128)} multiply(%param_0.29, %broadcast.37)
%constant.16 = f32[] constant(1e-06)
%broadcast.36 = f32[16]{0:T(128)} broadcast(%constant.16), dimensions={}
%add.5 = f32[16]{0:T(128)} add(%multiply.7, %broadcast.36)
ROOT %sqrt.5 = f32[16]{0:T(128)} sqrt(%add.5)
}This is the RMS norm denominator: sqrt(mean + epsilon).
When multiple fusions share a common operand, they can be merged. Multi-output fusion (pass #43) identifies sibling fusions with shared inputs and combines them, returning a tuple:
%fused_computation.3 (param_0.33: f32[16,64], param_1.35: f32[64,64]) -> (f32[16], f32[16,64]) {
%convolution.3 = f32[16,64]{1,0:T(8,128)} convolution(%param_0.33, %param_1.35), dim_labels=bf_io->bf
%multiply.6 = f32[16,64]{1,0:T(8,128)} multiply(%convolution.3, %convolution.3)
%constant.14 = f32[] constant(0)
%reduce.0 = f32[16]{0:T(128)} reduce(%multiply.6, %constant.14), dimensions={1}, to_apply=%region_0.15
ROOT %tuple = (f32[16]{0:T(128)}, f32[16,64]{1,0:T(8,128)}) tuple(%reduce.0, %convolution.3)
}Before this pass, the matmul feeding into both the normalization path and the RMS reduction path would have been computed in separate fusions. Multi-output fusion merges them — the matmul happens once, and both the normalized result (convolution.3) and the squared sum (reduce.0) are returned together. The alternative would be either recomputing the matmul or spilling it to HBM between fusions.
The caller extracts both values:
%multiply_reduce_fusion = (f32[16]{0:T(128)}, f32[16,64]{1,0:T(8,128)}) fusion(%Arg_0.1, %Arg_1.2), kind=kOutput
%get-tuple-element = f32[16]{0:T(128)} get-tuple-element(%multiply_reduce_fusion), index=0
%get-tuple-element.1 = f32[16,64]{1,0:T(8,128)} get-tuple-element(%multiply_reduce_fusion), index=1The final passes assign tensors to specific memory spaces and insert async memory operations. In HLO, memory spaces are annotated as S(n):
S(0)(often omitted) — HBM (high bandwidth memory, off-chip)S(1)— VMEM (on-chip SRAM)S(2),S(3), etc. — additional device-specific memory spaces
The after_codegen.txt shows the scheduled program:
ENTRY %main.47 (Arg_0.1: f32[16,64], Arg_1.2: f32[64,64], Arg_2.3: f32[64,32]) -> f32[16,32] {
%Arg_1.2 = f32[64,64]{1,0:T(8,128)} parameter(1), metadata={op_name="w1"}
%copy-start = (f32[64,64]{1,0:T(8,128)S(1)}, f32[64,64]{1,0:T(8,128)}, u32[]{:S(2)}) copy-start(%Arg_1.2), cross_program_prefetch_index=0
%Arg_2.3 = f32[64,32]{0,1:T(8,128)} parameter(2), metadata={op_name="w2"}
%Arg_0.1 = f32[16,64]{1,0:T(8,128)} parameter(0), metadata={op_name="x"}
%copy-done = f32[64,64]{1,0:T(8,128)S(1)} copy-done(%copy-start)
%multiply_reduce_fusion = (f32[16]{0:T(128)S(1)}, f32[16,64]{1,0:T(8,128)S(1)}) fusion(%Arg_0.1, %copy-done), kind=kOutput, ...
%copy-start.1 = (f32[64,32]{0,1:T(8,128)S(1)}, f32[64,32]{0,1:T(8,128)}, u32[]{:S(2)}) copy-start(%Arg_2.3)
%get-tuple-element.1 = f32[16,64]{1,0:T(8,128)S(1)} get-tuple-element(%multiply_reduce_fusion), index=1
%get-tuple-element = f32[16]{0:T(128)S(1)} get-tuple-element(%multiply_reduce_fusion), index=0
%add_sqrt_fusion = f32[16]{0:T(128)S(1)} fusion(%get-tuple-element), kind=kLoop, ...
%fusion.5 = f32[16]{0:T(128)S(1)} fusion(%get-tuple-element.1, %add_sqrt_fusion), kind=kLoop, ...
%fusion.2 = f32[16]{0:T(128)S(1)} fusion(%fusion.5, %get-tuple-element.1, %add_sqrt_fusion), kind=kLoop, ...
%copy-done.1 = f32[64,32]{0,1:T(8,128)S(1)} copy-done(%copy-start.1)
ROOT %fusion = f32[16,32]{1,0:T(8,128)} fusion(%copy-done.1, %fusion.2, %fusion.5, %get-tuple-element.1, %add_sqrt_fusion), kind=kOutput, ...
}
Notice the parameters start without S(1) — they live in HBM. The copy-start/copy-done pairs are async DMA operations that move data to VMEM. The tuple returned by copy-start contains the destination buffer (in S(1)), the source reference, and a sync token (in S(2)).
The compiler overlaps memory transfers with computation:
copy-start(w1)— initiate DMA of w1 from HBM → VMEMcopy-done(w1)— wait for transfer, then use in matmul₁copy-start(w2)— initiate DMA of w2 while RMS norm and softmax executecopy-done(w2)— wait for transfer, then use in matmul₂
The backend_config also shows estimated cycle counts per fusion:
"estimated_cycles":"2248" // multiply_reduce_fusion
"estimated_cycles":"2120" // add_sqrt_fusion
"estimated_cycles":"2143" // fusion.5 (reduce_max)
"estimated_cycles":"2162" // fusion.2 (reduce_sum)
"estimated_cycles":"3140" // final fusion (matmul_2)
Below is the final HLO that the frontend TPU compiler emits.
HloModule jit_mini_attention, is_scheduled=true, entry_computation_layout={(f32[16,64]{1,0:T(8,128)}, f32[64,64]{1,0:T(8,128)}, f32[64,32]{0,1:T(8,128)})->f32[16,32]{1,0:T(8,128)}}, allow_spmd_sharding_propagation_to_parameters={true,true,true}, allow_spmd_sharding_propagation_to_output={true}
%fused_computation.1 (param_0.21: f32[16], param_1.23: f32[16], param_2.10: f32[16,64], param_3.5: f32[16]) -> f32[16,64] {
%param_2.10 = f32[16,64]{1,0:T(8,128)S(1)} parameter(2)
%param_3.5 = f32[16]{0:T(128)S(1)} parameter(3)
%broadcast.29 = f32[16,64]{1,0:T(8,128)} broadcast(%param_3.5), dimensions={0}, metadata={op_name="jit(mini_attention)/jit(main)/rms_norm/div" source_file="/home/ptoulme/tpu.py" source_line=42}, backend_config={"flag_configs":[],"scoped_memory_configs":[],"used_scoped_memory_configs":[],"output_chunk_bound_config":{"output_chunk_bound":["8"]}}
%divide.5 = f32[16,64]{1,0:T(8,128)} divide(%param_2.10, %broadcast.29), metadata={op_name="jit(mini_attention)/jit(main)/rms_norm/div" source_file="/home/ptoulme/tpu.py" source_line=42}
%param_1.23 = f32[16]{0:T(128)S(1)} parameter(1)
%broadcast.24 = f32[16,64]{1,0:T(8,128)} broadcast(%param_1.23), dimensions={0}, metadata={op_name="jit(mini_attention)/jit(main)/softmax/sub" source_file="/home/ptoulme/tpu.py" source_line=49}, backend_config={"flag_configs":[],"scoped_memory_configs":[],"used_scoped_memory_configs":[],"output_chunk_bound_config":{"output_chunk_bound":["8"]}}
%subtract.3 = f32[16,64]{1,0:T(8,128)} subtract(%divide.5, %broadcast.24), metadata={op_name="jit(mini_attention)/jit(main)/softmax/sub" source_file="/home/ptoulme/tpu.py" source_line=49}
%exponential.3 = f32[16,64]{1,0:T(8,128)} exponential(%subtract.3), metadata={op_name="jit(mini_attention)/jit(main)/softmax/exp" source_file="/home/ptoulme/tpu.py" source_line=49}
%param_0.21 = f32[16]{0:T(128)S(1)} parameter(0)
%broadcast.18 = f32[16,64]{1,0:T(8,128)} broadcast(%param_0.21), dimensions={0}, metadata={op_name="jit(mini_attention)/jit(main)/softmax/div" source_file="/home/ptoulme/tpu.py" source_line=50}, backend_config={"flag_configs":[],"scoped_memory_configs":[],"used_scoped_memory_configs":[],"output_chunk_bound_config":{"output_chunk_bound":["8"]}}
ROOT %divide.1 = f32[16,64]{1,0:T(8,128)} divide(%exponential.3, %broadcast.18), metadata={op_name="jit(mini_attention)/jit(main)/softmax/div" source_file="/home/ptoulme/tpu.py" source_line=50}
}
%bitcast_fusion.1 (bitcast_input.1: f32[64,32]) -> f32[64,32] {
%bitcast_input.1 = f32[64,32]{0,1:T(8,128)S(1)} parameter(0)
ROOT %bitcast.1 = f32[64,32]{0,1:T(8,128)} bitcast(%bitcast_input.1)
}
%fused_computation (param_0.1: f32[64,32], param_1.21: f32[16], param_2.9: f32[16], param_3.3: f32[16,64], param_4: f32[16]) -> f32[16,32] {
%param_1.21 = f32[16]{0:T(128)S(1)} parameter(1)
%param_2.9 = f32[16]{0:T(128)S(1)} parameter(2)
%param_3.3 = f32[16,64]{1,0:T(8,128)S(1)} parameter(3)
%param_4 = f32[16]{0:T(128)S(1)} parameter(4)
%fusion.1 = f32[16,64]{1,0:T(8,128)} fusion(%param_1.21, %param_2.9, %param_3.3, %param_4), kind=kLoop, calls=%fused_computation.1, metadata={op_name="jit(mini_attention)/jit(main)/softmax/div" source_file="/home/ptoulme/tpu.py" source_line=50}
%param_0.1 = f32[64,32]{0,1:T(8,128)S(1)} parameter(0)
%fusion.7 = f32[64,32]{0,1:T(8,128)} fusion(%param_0.1), kind=kLoop, calls=%bitcast_fusion.1
ROOT %convolution.2 = f32[16,32]{1,0:T(8,128)} convolution(%fusion.1, %fusion.7), dim_labels=bf_io->bf, metadata={op_name="jit(mini_attention)/jit(main)/matmul_2/dot_general" source_file="/home/ptoulme/tpu.py" source_line=56}
}
%region_0.15 (Arg_0.12: f32[], Arg_1.13: f32[]) -> f32[] {
%Arg_1.13 = f32[]{:T(128)} parameter(1), metadata={op_name="jit(mini_attention)/jit(main)/rms_norm/reduce_sum"}
%Arg_0.12 = f32[]{:T(128)} parameter(0), metadata={op_name="jit(mini_attention)/jit(main)/rms_norm/reduce_sum"}
ROOT %add.14 = f32[]{:T(128)} add(%Arg_0.12, %Arg_1.13), metadata={op_name="jit(mini_attention)/jit(main)/rms_norm/reduce_sum" source_file="/home/ptoulme/tpu.py" source_line=41}
}
%bitcast_fusion (bitcast_input: f32[16,64]) -> f32[16,64] {
%bitcast_input = f32[16,64]{1,0:T(8,128)} parameter(0)
ROOT %bitcast = f32[16,64]{1,0:T(8,128)} bitcast(%bitcast_input)
}
%bitcast_fusion.2 (bitcast_input.2: f32[64,64]) -> f32[64,64] {
%bitcast_input.2 = f32[64,64]{1,0:T(8,128)S(1)} parameter(0)
ROOT %bitcast.2 = f32[64,64]{1,0:T(8,128)} bitcast(%bitcast_input.2)
}
%fused_computation.3 (param_0.33: f32[16,64], param_1.35: f32[64,64]) -> (f32[16], f32[16,64]) {
%param_0.33 = f32[16,64]{1,0:T(8,128)} parameter(0)
%fusion.6 = f32[16,64]{1,0:T(8,128)} fusion(%param_0.33), kind=kLoop, calls=%bitcast_fusion
%param_1.35 = f32[64,64]{1,0:T(8,128)S(1)} parameter(1)
%fusion.8 = f32[64,64]{1,0:T(8,128)} fusion(%param_1.35), kind=kLoop, calls=%bitcast_fusion.2
%convolution.3 = f32[16,64]{1,0:T(8,128)S(1)} convolution(%fusion.6, %fusion.8), dim_labels=bf_io->bf, metadata={op_name="jit(mini_attention)/jit(main)/matmul_1/dot_general" source_file="/home/ptoulme/tpu.py" source_line=35}
%multiply.6 = f32[16,64]{1,0:T(8,128)} multiply(%convolution.3, %convolution.3), metadata={op_name="jit(mini_attention)/jit(main)/rms_norm/integer_pow" source_file="/home/ptoulme/tpu.py" source_line=41}
%constant.14 = f32[]{:T(128)} constant(0)
%reduce.0 = f32[16]{0:T(128)S(1)} reduce(%multiply.6, %constant.14), dimensions={1}, to_apply=%region_0.15, metadata={op_name="jit(mini_attention)/jit(main)/rms_norm/reduce_sum" source_file="/home/ptoulme/tpu.py" source_line=41}
ROOT %tuple = (f32[16]{0:T(128)S(1)}, f32[16,64]{1,0:T(8,128)S(1)}) tuple(%reduce.0, %convolution.3)
}
%region_2.39 (Arg_0.36: f32[], Arg_1.37: f32[]) -> f32[] {
%Arg_1.37 = f32[]{:T(128)} parameter(1), metadata={op_name="jit(mini_attention)/jit(main)/softmax/reduce_sum"}
%Arg_0.36 = f32[]{:T(128)} parameter(0), metadata={op_name="jit(mini_attention)/jit(main)/softmax/reduce_sum"}
ROOT %add.38 = f32[]{:T(128)} add(%Arg_0.36, %Arg_1.37), metadata={op_name="jit(mini_attention)/jit(main)/softmax/reduce_sum" source_file="/home/ptoulme/tpu.py" source_line=50}
}
%fused_computation.4 (param_0.30: f32[16], param_1.33: f32[16,64], param_2.17: f32[16]) -> f32[16] {
%param_1.33 = f32[16,64]{1,0:T(8,128)S(1)} parameter(1)
%param_2.17 = f32[16]{0:T(128)S(1)} parameter(2)
%broadcast.32 = f32[16,64]{1,0:T(8,128)} broadcast(%param_2.17), dimensions={0}, metadata={op_name="jit(mini_attention)/jit(main)/rms_norm/div" source_file="/home/ptoulme/tpu.py" source_line=42}, backend_config={"flag_configs":[],"scoped_memory_configs":[],"used_scoped_memory_configs":[],"output_chunk_bound_config":{"output_chunk_bound":["8"]}}
%divide.7 = f32[16,64]{1,0:T(8,128)} divide(%param_1.33, %broadcast.32), metadata={op_name="jit(mini_attention)/jit(main)/rms_norm/div" source_file="/home/ptoulme/tpu.py" source_line=42}
%param_0.30 = f32[16]{0:T(128)S(1)} parameter(0)
%broadcast.25 = f32[16,64]{1,0:T(8,128)} broadcast(%param_0.30), dimensions={0}, metadata={op_name="jit(mini_attention)/jit(main)/softmax/sub" source_file="/home/ptoulme/tpu.py" source_line=49}, backend_config={"flag_configs":[],"scoped_memory_configs":[],"used_scoped_memory_configs":[],"output_chunk_bound_config":{"output_chunk_bound":["8"]}}
%subtract.5 = f32[16,64]{1,0:T(8,128)} subtract(%divide.7, %broadcast.25), metadata={op_name="jit(mini_attention)/jit(main)/softmax/sub" source_file="/home/ptoulme/tpu.py" source_line=49}
%exponential.5 = f32[16,64]{1,0:T(8,128)} exponential(%subtract.5), metadata={op_name="jit(mini_attention)/jit(main)/softmax/exp" source_file="/home/ptoulme/tpu.py" source_line=49}
%constant.13 = f32[]{:T(128)} constant(0)
ROOT %reduce.1 = f32[16]{0:T(128)S(1)} reduce(%exponential.5, %constant.13), dimensions={1}, to_apply=%region_2.39, metadata={op_name="jit(mini_attention)/jit(main)/softmax/reduce_sum" source_file="/home/ptoulme/tpu.py" source_line=50}
}
%region_1.28 (Arg_0.25: f32[], Arg_1.26: f32[]) -> f32[] {
%Arg_1.26 = f32[]{:T(128)} parameter(1), metadata={op_name="jit(mini_attention)/jit(main)/softmax/reduce_max"}
%Arg_0.25 = f32[]{:T(128)} parameter(0), metadata={op_name="jit(mini_attention)/jit(main)/softmax/reduce_max"}
ROOT %maximum.27 = f32[]{:T(128)} maximum(%Arg_0.25, %Arg_1.26), metadata={op_name="jit(mini_attention)/jit(main)/softmax/reduce_max" source_file="/home/ptoulme/tpu.py" source_line=48}
}
%fused_computation.8 (param_0.32: f32[16,64], param_1.34: f32[16]) -> f32[16] {
%param_0.32 = f32[16,64]{1,0:T(8,128)S(1)} parameter(0)
%param_1.34 = f32[16]{0:T(128)S(1)} parameter(1)
%broadcast.35 = f32[16,64]{1,0:T(8,128)} broadcast(%param_1.34), dimensions={0}, metadata={op_name="jit(mini_attention)/jit(main)/rms_norm/div" source_file="/home/ptoulme/tpu.py" source_line=42}, backend_config={"flag_configs":[],"scoped_memory_configs":[],"used_scoped_memory_configs":[],"output_chunk_bound_config":{"output_chunk_bound":["8"]}}
%divide.9 = f32[16,64]{1,0:T(8,128)} divide(%param_0.32, %broadcast.35), metadata={op_name="jit(mini_attention)/jit(main)/rms_norm/div" source_file="/home/ptoulme/tpu.py" source_line=42}
%constant.15 = f32[]{:T(128)} constant(-inf)
ROOT %reduce.2 = f32[16]{0:T(128)S(1)} reduce(%divide.9, %constant.15), dimensions={1}, to_apply=%region_1.28, metadata={op_name="jit(mini_attention)/jit(main)/softmax/reduce_max" source_file="/home/ptoulme/tpu.py" source_line=48}
}
%fused_computation.9 (param_0.29: f32[16]) -> f32[16] {
%param_0.29 = f32[16]{0:T(128)S(1)} parameter(0)
%constant.12 = f32[]{:T(128)} constant(0.015625)
%broadcast.37 = f32[16]{0:T(128)} broadcast(%constant.12), dimensions={}, backend_config={"flag_configs":[],"scoped_memory_configs":[],"used_scoped_memory_configs":[],"output_chunk_bound_config":{"output_chunk_bound":[]}}
%multiply.7 = f32[16]{0:T(128)} multiply(%param_0.29, %broadcast.37), metadata={op_name="jit(mini_attention)/jit(main)/rms_norm/div" source_file="/home/ptoulme/tpu.py" source_line=41}
%constant.16 = f32[]{:T(128)} constant(1e-06)
%broadcast.36 = f32[16]{0:T(128)} broadcast(%constant.16), dimensions={}, backend_config={"flag_configs":[],"scoped_memory_configs":[],"used_scoped_memory_configs":[],"output_chunk_bound_config":{"output_chunk_bound":[]}}
%add.5 = f32[16]{0:T(128)} add(%multiply.7, %broadcast.36), metadata={op_name="jit(mini_attention)/jit(main)/rms_norm/add" source_file="/home/ptoulme/tpu.py" source_line=41}
ROOT %sqrt.5 = f32[16]{0:T(128)S(1)} sqrt(%add.5), metadata={op_name="jit(mini_attention)/jit(main)/rms_norm/sqrt" source_file="/home/ptoulme/tpu.py" source_line=41}
}
ENTRY %main.47 (Arg_0.1: f32[16,64], Arg_1.2: f32[64,64], Arg_2.3: f32[64,32]) -> f32[16,32] {
%Arg_1.2 = f32[64,64]{1,0:T(8,128)} parameter(1), metadata={op_name="w1"}
%copy-start = (f32[64,64]{1,0:T(8,128)S(1)}, f32[64,64]{1,0:T(8,128)}, u32[]{:S(2)}) copy-start(%Arg_1.2), cross_program_prefetch_index=0
%Arg_2.3 = f32[64,32]{0,1:T(8,128)} parameter(2), metadata={op_name="w2"}
%Arg_0.1 = f32[16,64]{1,0:T(8,128)} parameter(0), metadata={op_name="x"}
%copy-done = f32[64,64]{1,0:T(8,128)S(1)} copy-done(%copy-start)
%multiply_reduce_fusion = (f32[16]{0:T(128)S(1)}, f32[16,64]{1,0:T(8,128)S(1)}) fusion(%Arg_0.1, %copy-done), kind=kOutput, calls=%fused_computation.3, metadata={op_name="jit(mini_attention)/jit(main)/matmul_1/dot_general" source_file="/home/ptoulme/tpu.py" source_line=35}
%copy-start.1 = (f32[64,32]{0,1:T(8,128)S(1)}, f32[64,32]{0,1:T(8,128)}, u32[]{:S(2)}) copy-start(%Arg_2.3)
%get-tuple-element.1 = f32[16,64]{1,0:T(8,128)S(1)} get-tuple-element(%multiply_reduce_fusion), index=1, metadata={op_name="jit(mini_attention)/jit(main)/rms_norm/reduce_sum" source_file="/home/ptoulme/tpu.py" source_line=41}
%get-tuple-element = f32[16]{0:T(128)S(1)} get-tuple-element(%multiply_reduce_fusion), index=0, metadata={op_name="jit(mini_attention)/jit(main)/rms_norm/reduce_sum" source_file="/home/ptoulme/tpu.py" source_line=41}
%add_sqrt_fusion = f32[16]{0:T(128)S(1)} fusion(%get-tuple-element), kind=kLoop, calls=%fused_computation.9, metadata={op_name="jit(mini_attention)/jit(main)/rms_norm/sqrt" source_file="/home/ptoulme/tpu.py" source_line=41}
%fusion.5 = f32[16]{0:T(128)S(1)} fusion(%get-tuple-element.1, %add_sqrt_fusion), kind=kLoop, calls=%fused_computation.8, metadata={op_name="jit(mini_attention)/jit(main)/softmax/reduce_max" source_file="/home/ptoulme/tpu.py" source_line=48}
%fusion.2 = f32[16]{0:T(128)S(1)} fusion(%fusion.5, %get-tuple-element.1, %add_sqrt_fusion), kind=kLoop, calls=%fused_computation.4, metadata={op_name="jit(mini_attention)/jit(main)/softmax/reduce_sum" source_file="/home/ptoulme/tpu.py" source_line=50}
%copy-done.1 = f32[64,32]{0,1:T(8,128)S(1)} copy-done(%copy-start.1)
ROOT %fusion = f32[16,32]{1,0:T(8,128)} fusion(%copy-done.1, %fusion.2, %fusion.5, %get-tuple-element.1, %add_sqrt_fusion), kind=kOutput, calls=%fused_computation, metadata={op_name="jit(mini_attention)/jit(main)/matmul_2/dot_general" source_file="/home/ptoulme/tpu.py" source_line=56}
}
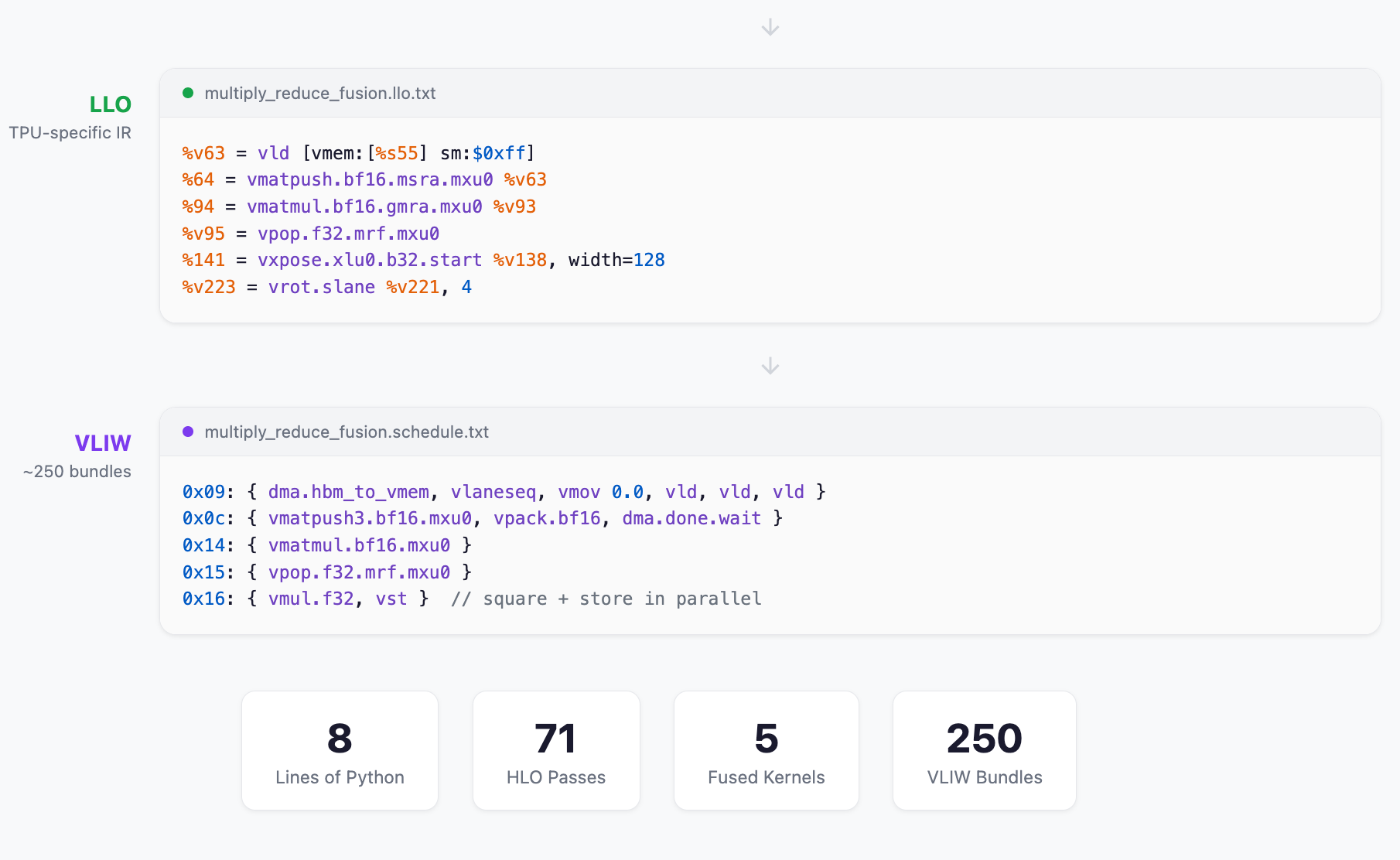
That covers the HLO optimization passes. At this point we have fused, scheduled operations with memory annotations — but it's still relatively hardware-agnostic. Next, the TPU backend translates each fusion into LLO (Low Level Operators), a representation that maps directly to physical hardware units: the MXU for matmuls, VPU for elementwise ops, XLU for transposes, and DMA engines for memory movement.
After HLO optimizations, XLA’s TPU backend translates each fusion into LLO (Low Level Operators)—a TPU-specific intermediate representation that maps directly to hardware units. Each fusion becomes a separate LLO program that goes through in my case 78 optimization passes before producing final VLIW bundles.
Before diving into LLO, here’s a quick orientation. Each TPU Trillium V6e TensorCore contains:
MXU (Matrix Unit): Two 256×256 systolic arrays for matrix multiplies. This is where the FLOPS come from.
VPU (Vector Processing Unit): Handles elementwise ops (add, mul, exp, etc.) across 8 sublanes × 128 lanes.
XLU (Transpose Unit): Cross-lane shuffles, transposes, and permutations.
Scalar Unit: Scalar operations, address calculation, and control flow.
DMA engines: Async memory transfers between HBM and VMEM.
The compiler’s job is to keep all of these busy simultaneously. A well-scheduled TPU program overlaps MXU matmuls with VPU elementwise ops with DMA transfers — all in the same VLIW bundle.
Let’s trace how multiply_reduce_fusion—which computes our first matrix multiply and the squared values for RMS normalization—transforms from initial LLO to final machine code.
Initial LLO (Pass 02)
The compiler first translates the fusion HLO region into a verbose, unscheduled LLO representation. Here’s how the matrix multiply setup begins:
$region0: #{multiply_reduce_fusion}
#allocation0 [shape = 'f32[1024]{0}', space=vmem, size = 0x1000, tag = 'scoped memory']
#allocation1 [shape = 'f32[16]{0:T(1024)S(1)}', space=vmem, size = 0x1000, tag = 'reduce buffer']
%s0 = inlined_call_operand.hbm [shape: f32[16,64], index: 0, kind: input]
%s1 = inlined_call_operand.vmem [shape: f32[64,64], index: 1, kind: input]
%s2 = inlined_call_operand.vmem [shape: f32[16], index: 2, kind: output]
%s3 = inlined_call_operand.vmem [shape: f32[16,64], index: 3, kind: output]
The compiler allocates VMEM buffers and establishes that operand 0 comes from HBM (High Bandwidth Memory) while operand 1 is already in VMEM. This is a multi-output fusion—it produces both the matmul result (%s3) and the sum of squares (%s2) for RMS norm.
The initial MXU operations use vmatpush to load weight columns into the systolic array:
%v63 = vld [vmem:[%s55] sm:$0xff]
%64 = vmatpush.bf16.msra.mxu0 %v63
...
%v93 = vld [vmem:[#allocation0] sm:$0xff]
%94 = vmatmul.bf16.gmra.mxu0 %v93
%v95 = vpop.f32.mrf.mxu0
This sequence streams weight tiles through the MXU in bf16 precision, then pops the accumulated f32 results.
The Reduction Pattern
After the matmul, we need to sum squared values across columns. The compiler generates a cross-lane reduction using the XLU (transpose unit):
%141 = vxpose.xlu0.b32.start [1/2] (short) /*vx=*/%v138, /*width=*/128
%142 = vxpose.xlu0.b32.end [2/2] (short) /*vx=*/%v140, /*width=*/128
%v143 = vpop.trf.xlu0
%v144 = vpop.trf.xlu0
...
%v158 = vpop.trf.xlu0 // 16 pops totalAfter transposing, a tree reduction sums the 16 lanes:
%v161 = vadd.f32 0.0, %v143
%v165 = vadd.f32 %v161, %v144
%v169 = vadd.f32 %v165, %v145
...
%v221 = vadd.f32 %v217, %v158
Then a sublane rotation pattern completes the reduction:
%v223 = vrot.slane %v221, 4 // rotate by 4
%v226 = vadd.f32 %v221, %v223
%v228 = vrot.slane %v226, 2 // rotate by 2
%v231 = vadd.f32 %v226, %v228
%v233 = vrot.slane %v231, 1 // rotate by 1
%v236 = vadd.f32 %v231, %v233
This classic parallel reduction pattern uses log₂(n) steps—rotate by 4, 2, then 1—to sum 8 sublanes into a single scalar.
Final VLIW Bundles (Pass 78)
After all optimization passes, the compiler produces 71 tightly-packed VLIW bundles. Each bundle groups independent operations that execute in parallel across hardware units:
This is VLIW (Very Long Instruction Word) execution — the compiler statically packs independent operations into fixed-width bundles, and the hardware executes everything in a bundle simultaneously without runtime dependency checking.
0x9 : { %22 = dma.hbm_to_vmem [thread:$0] /*hbm=*/%s359_s0, ...
%v28_v1 = vlaneseq
%v301_v2 = vmov 0.0
%vm302_vm0 = vmmov 0
%v247_v4 = vld [vmem:[%s360_s1 + $0x30] sm:$0xff]
%v248_v5 = vld [vmem:[%s360_s1 + $0x38] sm:$0xff]
%v249_v6 = vld [vmem:[%s360_s1 + $0x20] sm:$0xff] }This single bundle executes 7 operations simultaneously: one DMA transfer from HBM, one lane sequence generation, two constant materializations, and three VMEM loads. The compiler has carefully scheduled these to avoid resource conflicts.
The MXU operations use the optimized vmatpush3 instruction:
0xc : { %261 = vmatpush3.bf16.msra.mxu0 %v61_v7
%v89_v15 = vpack.c.bf16 %v253_v14, %v85_v13
%297 = dma.done.wait [#allocation4], 256 }
Three operations in parallel: push a weight tile, pack bf16 values for the next push, and synchronize the DMA. The bf16 suffix indicates this matmul uses bfloat16 precision on the MXU, which provides 2x throughput compared to f32.
The matmul result extraction uses a masked variant:
0x14 : { %269 = vmatmul.mubr.msk.bf16.vlgmr.msra.gmra.mxu0 %vm257_vm2, %v258_v18 }
0x15 : { %v95_v19 = vpop.f32.mrf.mxu0 }
0x16 : { %v98_v20 = vmul.f32 %v95_v19, %v95_v19
%105 = vst [vmem:[%s362_s3] sm:$0xff] /*vst_source=*/%v95_v19 }
The squaring happens immediately in bundle 0x16, overlapped with storing the matmul result—the multi-output fusion lets us reuse %v95_v19 for both outputs.
In the above video, we can visualize this fusion on a TPU V6e Trillium. Note we are using one MXU in this visualization, while a Trillium has 2 256x256 MXUs.
Our mini_attention function compiles into five fusions, each with its own LLO compilation producing different bundle counts and hardware utilization patterns.
multiply_reduce_fusion (71 bundles)
This is our largest fusion, implementing both matmul_1 (the first matrix multiply) and the sum-of-squares reduction for RMS normalization. The fusion demonstrates sophisticated hardware utilization:
MXU0 handles the 16×64 by 64×64 bf16 matmul
VPU computes the squared values immediately after MXU results
XLU0 performs the cross-lane transpose for reduction
DMA streams the input activations from HBM
The 71 bundles break down into: DMA setup, weight loading, matmul execution, squaring, transpose-based reduction, and sublane rotation reduction.
add_sqrt_fusion (10 bundles)
The smallest and simplest fusion computes sqrt(mean + epsilon) for RMS normalization:
0x1 : { %v2_v0 = vld [vmem:[%s37_s0] sm:$0x1] }
0x2 : { %v5_v1 = vmul.f32 0.015625, %v2_v0 }
0x3 : { %v9_v2 = vadd.f32 1e-06, %v5_v1 }
0x4 : { %19 = vrsqrt.f32 %v9_v2
%vm13_vm0 = vcmp.eq.f32.partialorder %v9_v2, inf
%v16_v4 = vand.u32 2147483648, %v9_v2
%vm15_vm1 = vcmp.eq.f32.partialorder %v9_v2, 0.0 }
0x5 : { %v20_v3 = vpop.eup %19 }
0x6 : { %v12_v5 = vmul.f32 %v20_v3, %v9_v2 }
0x7 : { %v14_v6 = vsel /*vm=*/%vm13_vm0, /*on_true_vy=*/%v9_v2, /*on_false_vx=*/%v12_v5 }
0x8 : { %v17_v7 = vsel /*vm=*/%vm15_vm1, /*on_true_vy=*/%v16_v4, /*on_false_vx=*/%v14_v6 }
0x9 : { %18 = vst [vmem:[%s38_s1] sm:$0x1] /*vst_source=*/%v17_v7 }
The constant 0.015625 is 1/64—the mean computation. The vrsqrt.f32 instruction computes reciprocal square root. Special case handling for infinity and zero ensures numerical correctness.
fusion.5 (56 bundles)
This fusion computes reduce_max across rows for the softmax numerically-stable computation. It follows a similar pattern to the sum reduction in multiply_reduce_fusion: XLU transpose followed by tree reduction, but using max operations instead of add.
fusion.2 (65 bundles)
Implements exp(x - max) + reduce_sum—the softmax numerator and denominator. The vpow2 instruction computes the exponential followed by another transpose-and-reduce pattern for the sum.
fusion (48 bundles)
The final matmul (matmul_2) multiplying the softmax output by the value matrix. This fusion is smaller than multiply_reduce_fusion because it’s a pure matmul without the additional reduction operations.
The TLP (Top Level Program) orchestrates the entire mini_attention execution. Looking at the correct TLP for our function, we can see how it coordinates all five fusions and manages data movement.
Program Structure Overview
The mini_attention TLP is 174 bundles (0x00-0xad) and follows this execution flow:
0x5f-0x65 : Program entry and mode checking
0x66-0x7d : DMA: Load weight matrix from HBM (copy-start)
0x7e-0x82 : Call multiply_reduce_fusion (matmul_1 + squares)
0x83-0x8d : DMA: Start loading value matrix (copy-start.1)
0x8e-0x91 : Call add_sqrt_fusion (sqrt for RMS norm)
0x92-0x96 : Call fusion.5 (reduce_max for softmax)
0x97-0x9b : Call fusion.2 (exp + reduce_sum for softmax)
0x9c-0xa0 : DMA: Wait for value matrix
0xa1-0xa6 : Call fusion (matmul_2)
0xa7-0xad : Program finalization
DMA Orchestration and Overlapping
The TLP carefully overlaps memory transfers with computation. First, it loads the weight matrix for the first matmul:
0x77 : { %26 = dma.hbm_to_vmem [thread:$1] /*hbm=*/%s10_s14,
/*size_in_granules=*/%s22_s17, /*vmem=*/%s24_s19,
/*dst_syncflagno=*/[#allocation8] }
The DMA uses thread:$1—the TPU has multiple DMA engines, allowing concurrent transfers. After initiating this transfer, the TLP immediately waits for completion and then calls the first fusion:
0x7a : { %293 = dma.done.wait [#allocation8], 1024 }
0x7b : { %294 = vsyncadd [#allocation8], 4294966272 }
0x7c : { %39 = vsyncpa [#allocation8], 1 }
0x81 : { %45 = inlined_call %s9_s0, %s299_s1, %s300_s2, %s301_s3
/* %multiply_reduce_fusion = fusion(%Arg_0.1, %copy-done) */ }
Overlapping DMA with Compute
While RMS normalization fusions run, the TLP starts loading the value matrix for the second matmul:
0x8c : { %56 = dma.hbm_to_vmem [thread:$1] /*hbm=*/%s354_s25,
/*size_in_granules=*/512, /*vmem=*/%s54_s23,
/*dst_syncflagno=*/[#allocation13] }
This DMA runs in the background while add_sqrt_fusion, fusion.5, and fusion.2 execute:
0x90 : { %66 = inlined_call ... /* %add_sqrt_fusion */ }
0x95 : { %71 = inlined_call ... /* %fusion.5 */ }
0x9a : { %76 = inlined_call ... /* %fusion.2 */ }
Only before the final matmul does the TLP wait for the value matrix:
0x9d : { %295 = dma.done.wait [#allocation13], 512 }
0xa5 : { %87 = inlined_call ... /* %fusion = final matmul */ }
This is double-buffering in action—the softmax computation hides the latency of loading the value matrix.
The above video visualizes this DMA and compute overlap on TPU.
Fusion Calling Convention
Each fusion call passes VMEM buffer addresses via inlined_call. For example, the final matmul:
0xa2 : { %s312_s0 = smov [#allocation12] /* materialized constant */
%s355_s5 = sld [smem:[#allocation25_spill]]
%s356_s5 = int_to_ptr.hbm [resolvable:$false] %s355_s5 }
0xa3 : { %s313_s1 = smov [#allocation16] /* materialized constant */
%s314_s2 = smov [#allocation15] /* materialized constant */ }
0xa4 : { %s315_s3 = smov [#allocation11] /* materialized constant */
%s316_s4 = smov [#allocation14] /* materialized constant */ }
0xa5 : { %87 = inlined_call %s312_s0, %s313_s1, %s314_s2, %s315_s3, %s316_s4, %s356_s5
/* %fusion = fusion(%copy-done.1, %fusion.2, %fusion.5,
%get-tuple-element.1, %add_sqrt_fusion) */ }
The fusion receives six operands: the value matrix from HBM (copy-done.1), plus intermediate results from all previous fusions. Note the #allocation25_spill—this is a register spill to scalar memory, indicating the compiler ran out of scalar registers and had to temporarily store a value.
Trace Points for Profiling
Throughout execution, the TLP emits trace markers:
0x78 : { %30 = vtrace 2415919104 } // After copy-start
0x82 : { %49 = vtrace 2415919106 } // After multiply_reduce_fusion
0x91 : { %69 = vtrace 2415919108 } // After add_sqrt_fusion
0x96 : { %74 = vtrace 2415919109 } // After fusion.5
0x9b : { %79 = vtrace 2415919110 } // After fusion.2
0xa6 : { %90 = vtrace 2415919112 } // After final fusion
These trace IDs let TPU profiling tools measure the time spent in each fusion, helping identify performance bottlenecks.
Program Finalization
The TLP concludes with synchronization:
0xa9 : { %95 = vsettm %s317_s26 } // Set timer mode
0xaa : { %96 = vdelay 1 } // Delay for pipeline drain
0xab : { %97 = sfence } // Memory fence
0xac : { %s318_s27 = smov 0 }
0xad : { %98 = sst [smem:[#allocation17]] %s318_s27 } // Signal completion
The sfence ensures all memory operations have completed before the final store signals to the host that the TPU program has finished.
Eight lines of JAX code became 250 VLIW bundles across 5 fused kernels. Here’s what the compiler did to get there:
The TPU compiler is a sophisticated codegen compiler. GPUs have codegen too (Triton, XLA/GPU, torch.compile), but the TPU compiler is doing something impressive: it takes your entire computation graph, fuses across operation boundaries, schedules VLIW bundles that saturate 5+ hardware units simultaneously, and orchestrates async DMA — all automatically. No manual tiling, no explicit shared memory management, no @triton.autotune. You write JAX and the compiler figures out the rest.
It generalizes to novel workloads. This matters more than it might seem. On GPUs, peak performance often requires hand-tuned kernels — FlashAttention exists because the compiler couldn’t find that optimization automatically. The TPU compiler’s approach is different: rather than relying on a library of pre-optimized patterns, it reasons about your specific computation from first principles. A weird custom attention variant, a novel normalization scheme, some exotic activation function — the compiler will fuse them, schedule them, and generate reasonable code without anyone having to write a custom kernel. The performance ceiling might be lower than a hand-tuned GPU kernel, but the floor is much higher.
Fusion is everything. The original ~25 HLO ops collapsed into 5 fusions. Each fusion keeps intermediates in VMEM, avoiding HBM round-trips. RMS norm and softmax never touch HBM — they execute entirely in fast on-chip memory.
Async DMA hides memory latency. While the VPU computes softmax, the DMA engine loads the value matrix in the background. By the time softmax finishes, the weights are already in VMEM — zero stall before the final matmul.
VLIW packs independent ops. A single bundle can execute a DMA transfer, three VMEM loads, and two vector ops simultaneously. The compiler statically schedules everything; the hardware just executes.
If you’re training or running inference on TPUs, you don’t need to understand any of this to get good performance — that’s the point. The compiler handles fusion, memory management, and scheduling automatically.
But if you’re debugging why a particular computation is slow, or curious whether a custom operation will perform well, you now know how to look under the hood. Dump the IR, find your fusion, count the bundles, check if DMA is overlapping with compute. The tools exist; they’re just undocumented.
And if you’re deciding between TPUs and GPUs for a new workload: TPUs reward experimentation. You can try unconventional architectures without writing custom kernels. The compiler will generate reasonable code for whatever you throw at it. That’s a different value proposition than “fastest possible matmul” — it’s “fast enough matmul for any shape, any fusion pattern, automatically.”
If you want to explore this yourself, the dump flags are straightforward:
XLA_FLAGS="--xla_dump_to=./hlo --xla_dump_hlo_pass_re=.*"
LIBTPU_INIT_ARGS="--xla_jf_dump_to=./llo --xla_jf_dump_llo_text=true"The HLO is readable. The LLO takes some squinting, but the patterns emerge — look for vmatpush/vmatmul pairs for matmuls, vxpose/vpop.trf for transposes, and vrot.slane for reductions.
Most of this compiler is closed-source, but the IRs tell the story.
Questions? Message me on Linkedin: https://www.linkedin.com/in/patrick-toulme-150b041a5/