Experiments
Direct Evaluations on Multiple Robot Platforms
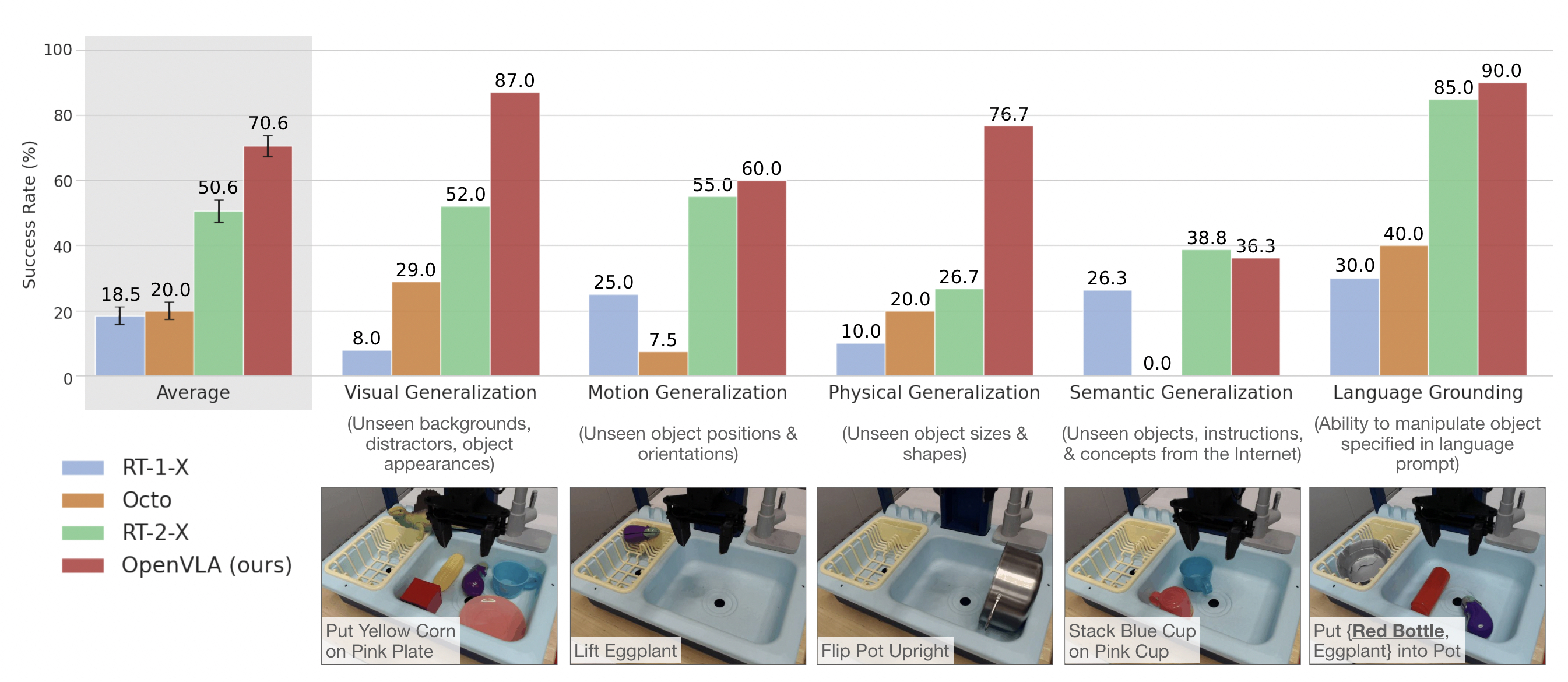
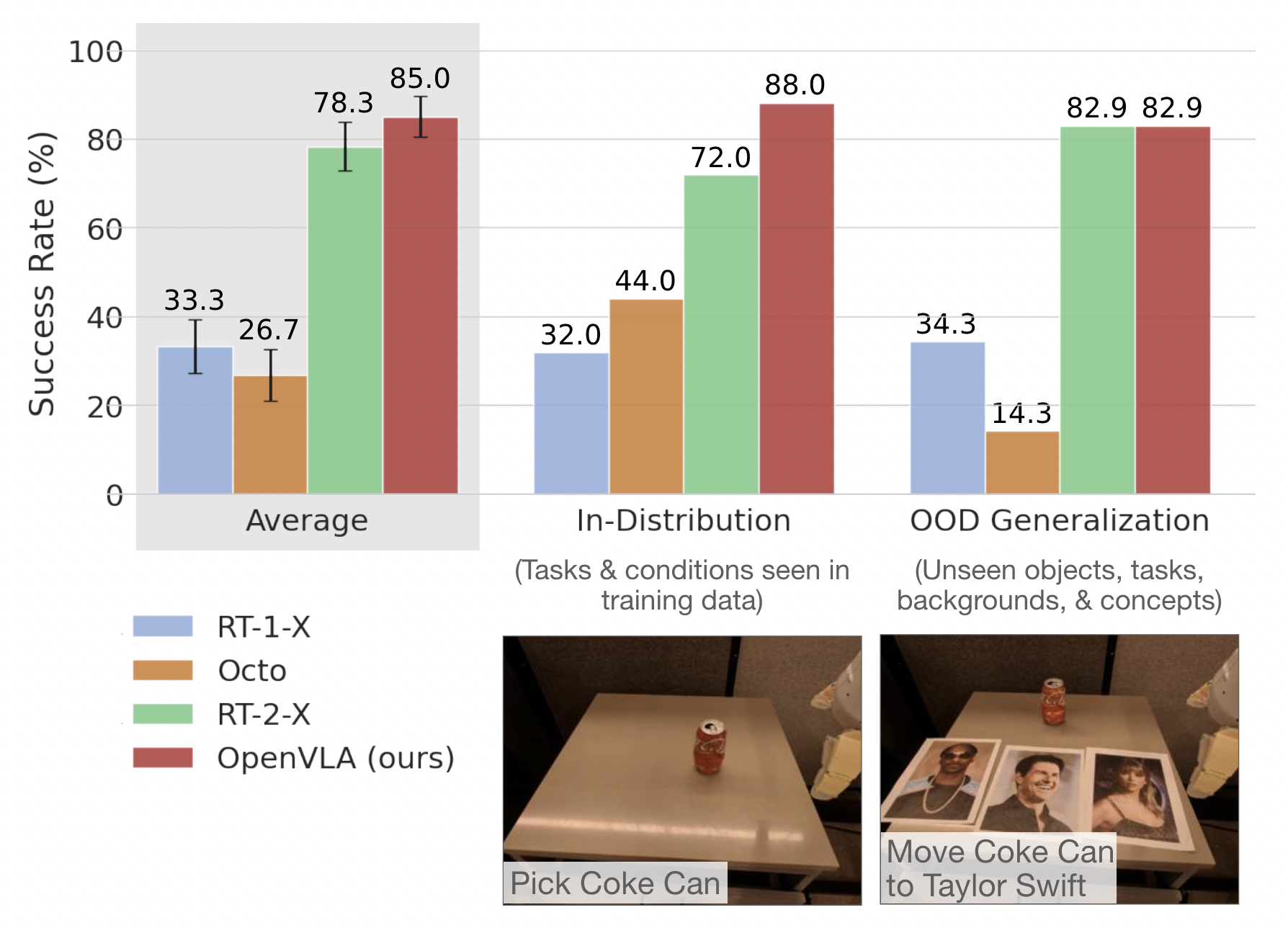
We evaluate OpenVLA's ability to control multiple robot platforms ``out-of-the-box'' across two setups: the WidowX setup from Bridge V2 and the Google Robot from the RT-series of papers. Our results show that OpenVLA sets a new state of the art, outperforming prior generalist policies RT-1-X and Octo. Notably, as a product of the added data diversity and new model components, it also outperforms RT-2-X, a 55B parameter closed VLA.
|
We test OpenVLA across a wide range of generalization tasks, such as visual (unseen backgrounds, distractor objects, colors/appearances of objects); motion (unseen object positions/orientations); physical (unseen object sizes/shapes); and semantic (unseen target objects, instructions, and concepts from the Internet) generalization. Qualitatively, we find that both RT-2-X and OpenVLA exhibit markedly more robust behaviors than the other tested model, such as approaching the correct object when distractor objects are present, properly orienting the robot's end-effector to align with the orientation of the target object, and even recovering from mistakes such as insecurely grasping objects |
|
Data-Efficient Adaptation to New Robot Setups
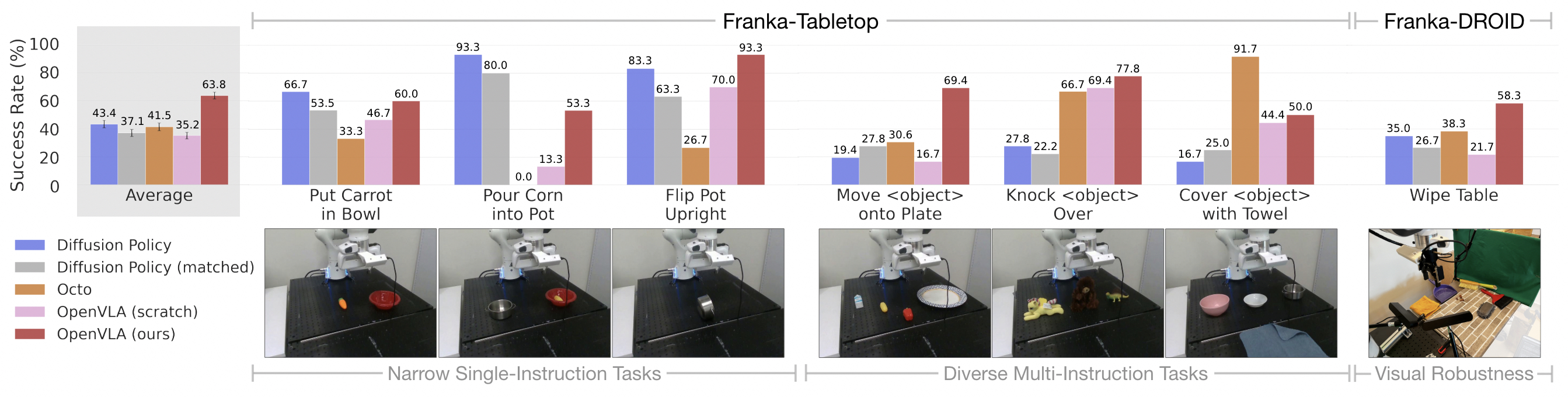
Effective fine-tuning of VLA models to new tasks and robot setups is largely unexplored, yet is key for their widespread adoption. We investigate OpenVLA’s ability to be quickly adapted to a new robot setup in two domains: Franka-Tabletop, a stationary, table-mounted Franka Emika Panda 7-DoF robot arm, controlled at a frequency of 5 Hz; and Franka-DROID, the Franka robot arm setup from the recently released DROID dataset, controlled at 15 Hz.
We compare to Diffusion Policy, a state of the art data-efficient imitation learning approach, trained from scratch. Additionally, we evaluate Octo fine-tuned on the target dataset. OpenVLA clearly outperforms Octo across most tasks. Diffusion policy is strongest on narrower, more precise tasks, while OpenVLA shows better performance on tasks that require grounding language to behavior in multi-task, multi-object settings. OpenVLA is the only approach that achieves at least 50% success rate across all tested tasks, suggesting that it can be a strong default option for imitation learning tasks, particularly if they involve a diverse set of language instructions.
Parameter-Efficient Fine-Tuning
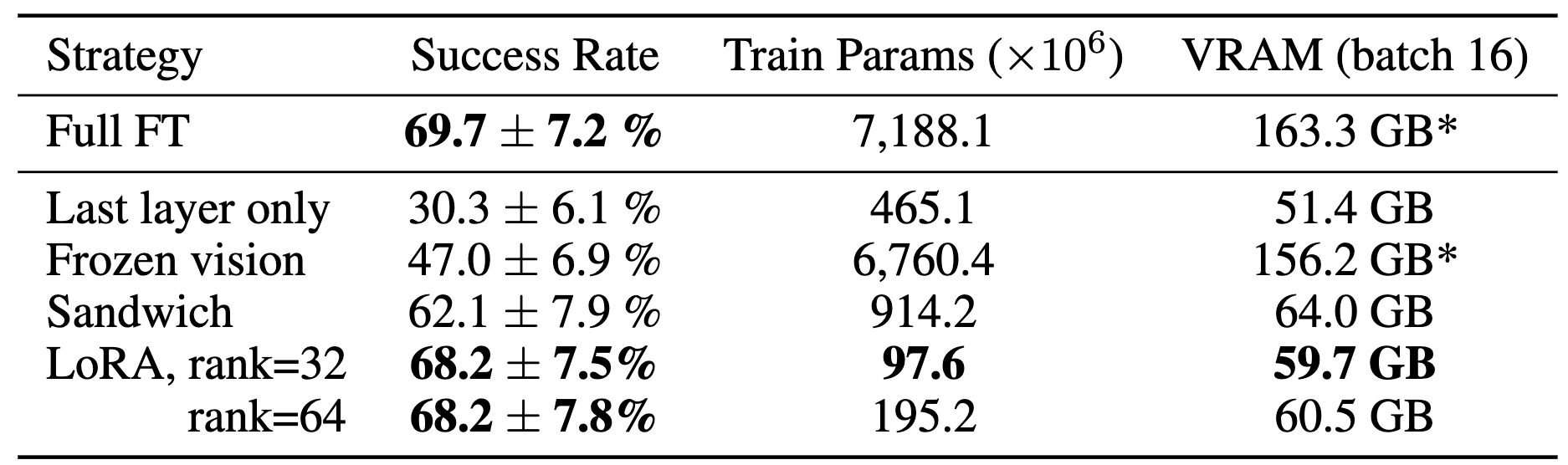
We test various approaches for parameter-efficient fine-tuning of OpenVLA policies across multiple Franka-Tabletop tasks. We find that only fine-tuning the network’s last layer or freezing the vision encoder leads to poor performance. LoRA achieves the best trade-off between performance and training memory consumption, matching full fine-tuning performance while fine-tuning only 1.4% of the parameters.
Sample OpenVLA Rollout Videos
Below are videos of the OpenVLA generalist policy demonstrating various robust behaviors. (Videos are sped up by 1.5x.)
Real-World Bridge V2 WidowX Robot Rollouts
In a scene with many distractor objects, OpenVLA is able to approach and manipulate the correct target object.
Put Eggplant into Pot
Put Yellow Corn on Pink Plate
Similarly, we assess the policy's language grounding by prompting it to manipulate different target objects given the same initial states. We find that OpenVLA reliably targets the correct object in most cases.
Lift Red Chili Pepper
Lift Cheese
Put Pink Cup on Plate
Put Blue Cup on Plate
OpenVLA properly orients the robot's end-effector to align with the orientation of the target object before grasping it.
Lift AAA Battery
Put Carrot on Plate
In some cases, after an initial mistake, OpenVLA can even recover and successfully complete the task.
Put Blue Cup on Plate
Put Eggplant into Pot
Comparisons with State-of-the-Art Models
Here we show how OpenVLA compares with other baseline methods in various evaluation tasks. (Videos are sped up by 2x.)
Real-World Google Robot Rollouts
Both RT-2-X (closed-source 55B-parameter model) and OpenVLA perform reliably on in-distribution and basic out-of-distribution (OOD) generalization tasks.
RT-2-X:
Pick Coke Can
(In-Distribution)
✅
OpenVLA:
Pick Coke Can
(In-Distribution)
✅
RT-2-X:
Move Banana near Plate
(OOD: unseen target object)
✅
OpenVLA:
Move Banana near Plate
(OOD: unseen target object)
✅
RT-2-X:
Place Banana on Plate
(OOD: unseen target object & instruction)
✅
OpenVLA:
Place Banana on Plate
(OOD: unseen target object & instruction)
✅
However, RT-2-X performs better than OpenVLA on difficult semantic generalization tasks, i.e., tasks that require knowledge of concepts from the Internet that do not appear in the robot action training data, such as Taylor Swift in the videos below.
This is expected given that RT-2-X uses larger-scale Internet pretraining data and is co-fine-tuned with both robot action data and Internet pretraining data to better preserve the pretraining knowledge (for OpenVLA, we fine-tune the pretrained vision-language model solely on robot action data for simplicity).
RT-2-X:
Move Coke Can near Taylor Swift
(OOD: unseen concept from Internet)
✅
OpenVLA:
Move Coke Can near Taylor Swift
(OOD: unseen concept from Internet)
❌
Real-World Franka Emika Panda Robot Rollouts: Fine-Tuning on Franka-Tabletop Datasets
In narrow single-instruction fine-tuning tasks, Diffusion Policy trained from scratch outperforms fine-tuned generalist policies, Octo and OpenVLA. (Videos are sped up by 5x.)
Diffusion Policy:
Put Carrot in Bowl
✅
Octo:
Put Carrot in Bowl
❌
OpenVLA:
Put Carrot in Bowl
❌
Diffusion Policy:
Pour Corn into Pot
✅
Octo:
Pour Corn into Pot
❌
OpenVLA:
Pour Corn into Pot
❌
However, in fine-tuning tasks that involve multiple objects in the scene and require language conditioning, Octo and OpenVLA generally perform better, as their OpenX pretraining enables them to better adapt to these more diverse tasks.
Diffusion Policy:
Move Yellow Corn onto Plate
❌
Octo:
Move Yellow Corn onto Plate
⚠️
OpenVLA:
Move Yellow Corn onto Plate
✅
Diffusion Policy:
Knock Brown Bear Over
❌
Octo:
Knock Brown Bear Over
⚠️
OpenVLA:
Knock Brown Bear Over
✅
Diffusion Policy:
Cover White Bowl with Towel
❌
Octo:
Cover White Bowl with Towel
✅
OpenVLA:
Cover White Bowl with Towel
⚠️
We see evidence of the benefits of OpenX pretraining when comparing OpenVLA to OpenVLA (Scratch), which ablates OpenX pretraining and directly fine-tunes the base vision-language model on the Franka-Tabletop dataset. The full OpenVLA model exhibits much more reliable behaviors than OpenVLA (Scratch).
OpenVLA (Scratch):
Flip Pot Upright
⚠️
OpenVLA:
Flip Pot Upright
✅
OpenVLA (Scratch):
Move White Salt Shaker onto Plate
❌