The emergence of a new form of intelligence
Odyssey is an AI lab pioneering general-purpose world models—a new form of multimodal intelligence. Through our research, we’re now seeing the earliest glimpses of an entirely new form of intelligence, powered by world models.
We’re launching our first interactive video experience
A research preview of Odyssey-1
Today marks the beginning of our journey to bring this to life, with the public launch of our first playable experience. Powering this is a new world model called Odyssey-1, demonstrating capabilities like generating pixels that feel realistic, maintaining spatial consistency, learning actions from video, and outputting coherent video streams for 5 minutes or more. What’s particularly remarkable is its ability to generate and stream new, realistic video frames every 40ms.
The experience today feels like exploring a glitchy dream—raw, unstable, but undeniably new. While its utility is limited for now, improvements won’t be driven by hand-built game engines, but rather by models and data. We believe this shift will rapidly unlock lifelike visuals, deeper interactivity, richer physics, and entirely new experiences. On a long enough time horizon, this becomes the world simulator, where pixels and actions look and feel indistinguishable from reality, enabling thousands of never-before-possible experiences.
Powered by a world model
A world model is, at its core, an action-conditioned dynamics model. Given the current state, an incoming action, and a history of states and actions, the model attempts to predict the next state in the form of a video frame. It's this architecture that's unlocking interactive video, along with other profound applications.
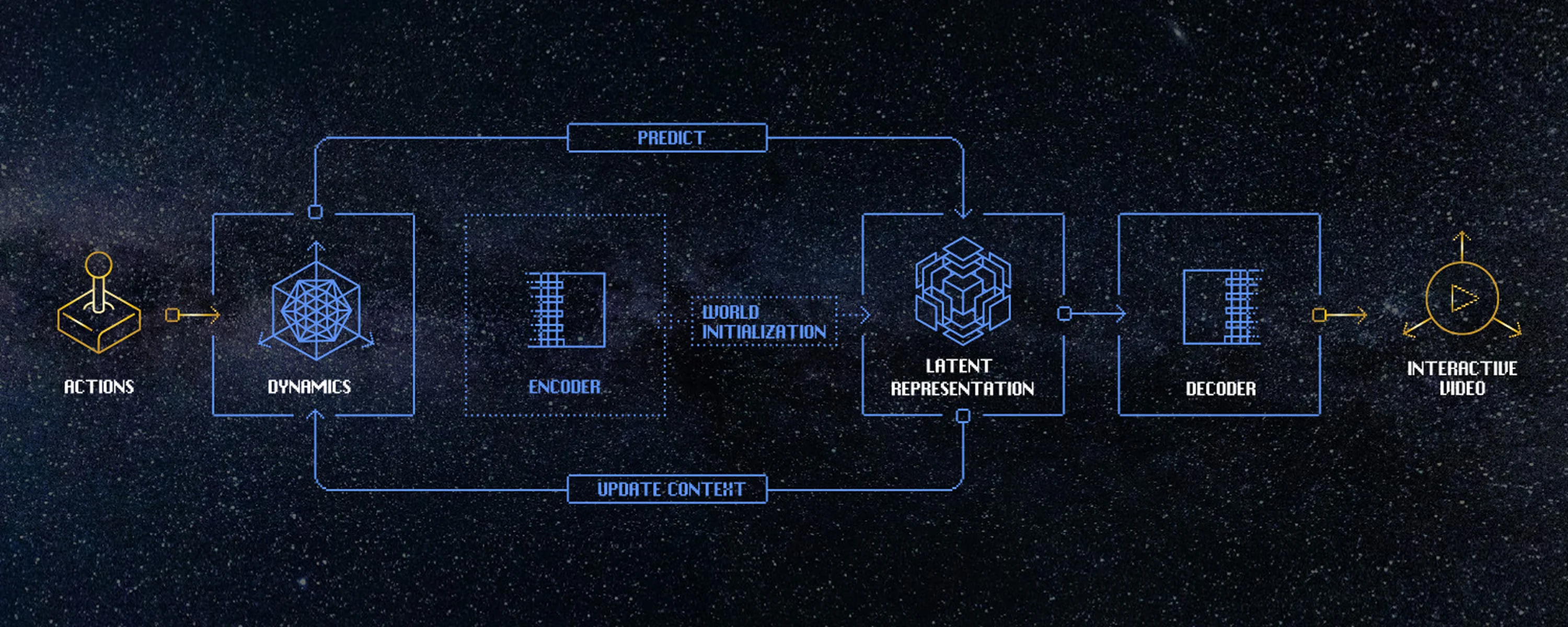
The architecture of a world model
Compared to language, image, or video models, world models are still nascent. One of the biggest challenges is that world models require autoregressive modeling, predicting future state based on previous state. This means the generated outputs are fed back into the context of the model. In language, this is less of an issue due to its more bounded state space. But in world models—with a far higher-dimensional state—it can lead to instability, as the model drifts outside the support of its training distribution. Improving this is an area of research we're deeply invested in.
To improve autoregressive stability for this research preview, what we’re sharing today can be considered a narrow distribution model: it's pre-trained on video of the world, and post-trained on video from a smaller set of places with dense coverage. The tradeoff of this post-training is that we lose some generality, but gain more stable, long-running autoregressive generation.
To broaden generalization, we’re already making fast progress on our next-generation world model. That model—with outputs you can see below—is already demonstrating a richer range of pixels, dynamics, and actions, with noticeably stronger generalization.
Learning not just video, but the actions that shape it
Early research on world models has focused on learning pixels and actions from game worlds like Minecraft or Quake, where the pixels are constrained, the motion is basic, the actions possible are limited, and the physics simplified. These limitations and lack of diversity make it easier to model how actions affect pixels, but game worlds enforce a low, known ceiling on what’s possible with these models.
Oasis by Decart
WHAMM by Microsoft
It's our belief that learning both pixels and actions from decades of real-life video—like what you see below—has the potential to lift that ceiling, unlocking models that learn life-like visuals and the full, unbounded range of actions we take in the world—beyond the traditional game logic of walk here, run there, shoot that.
Learning the real world
Learning from open-ended real-life video is an incredibly hard problem. The visuals are noisy and diverse, actions are continuous and unpredictable, and the physics are—well—real. But, it’s what will ultimately unlock models to generate unprecedented realism.
A world model, not a video model
The architecture, parameter count, and datasets of typical video models aren’t conducive to generating video in real-time that’s influenced by user actions.
World Model
Video Model
Predicts one frame at a time, reacting to what happens.
Generates a full video in one go.
Every future is possible.
The model knows the end from the start.
Fully interactive—responds instantly to user input at any time.
No interactivity—the clip plays out the same every time.
As one example difference, video models generate a fixed set of frames in one go. They do this by building a structured embedding that represents a whole clip—which works great for clip generation, where nothing needs to change mid-stream—but is a non-starter for interactivity. Once the video embedding is set, you’re locked in, meaning you can only adjust the video at fixed intervals.
A world model however, works very differently. They predict the next state given the current state and an action, and can do so at a flexible interval. Because new inputs from the user can happen at any moment, that interval can be as short as a single frame of video—allowing the user to guide video generation in real-time with their actions. For interactive video, this is essential.
Served by real-time infrastructure
The model in our research preview is capable of streaming video at up to 30 FPS from clusters of H100 GPUs in the US and EU. Behind the scenes, the moment you press a key, tap a screen, or move a joystick, that input is sent over the wire to the model. Using that input and frame history, the model then generates what it thinks the next frame should be, streaming it back to you in real-time.
This series of steps can take as little as 40 ms, meaning the actions you take feel like they’re instantaneously reflected in the video you see. The cost of the infrastructure enabling this experience is today $1-$2 per user-hour, depending on the quality of video we serve. This cost is decreasing fast, driven by model optimization, infrastructure investments, and tailwinds from language models.
A new form of intelligence is emerging
World models open the door to an entirely new form of intelligence, and presents incredible possibilities for the next generation of gaming, film, education, social media, advertising, training, companionship, simulation, and much more. The research preview we’re sharing today is a humble beginning toward this incredibly exciting future, and we can’t wait for you to try it and to hear what you think!
The team that brought this to life
This research preview was made possible by the incredible Odyssey team.
Technical Staff
Ben Graham, Boyu Liu, Gareth Cross, James Grieve, Jeff Hawke, Jon Sadeghi, Oliver Cameron, Philip Petrakian, Richard Shen, Robin Tweedie, Ryan Burgoyne, Sarah King, Sirish Srinivasan, Vinh-Dieu Lam, Zygmunt Łenyk.
Operational Staff
Andy Kolkhorst, Jessica Inman.