
The Dawn of a World Simulator
A causal, multimodal system that learns to predict the world

Oliver Cameron
A New Form of Multimodal Intelligence
We now know that simple, causal prediction objectives give rise to surprisingly general intelligence. In language, predicting the next token forces models to internalize syntax, semantics, and long-range structure.
We now see this approach extend beyond language to world models, resulting in nascent world simulators. A world simulator—like Odyssey-2 Pro—is a model capable of predicting how the world evolves over time, learned from trillions of observations of the world found in video and interaction data.
Rather than relying on hand-crafted rules, it learns the laws of the world directly from data. We believe this will soon unlock systems that internalize physics, human behavior, and cause-and-effect at an unprecedented scale, revolutionizing robotics, science, healthcare, education, gaming, and beyond.
Odyssey-2 Pro, a nascent world simulator
Learning the World Through Observation
Why do we care about next-state prediction or next-token prediction as pretraining tasks? Because they are simple objectives that enable models with very little built-in knowledge to learn how the world works directly from data. Pretraining reduces uncertainty about what comes next in a sequence—whether that’s a state or a word. As that uncertainty drops, intelligent capabilities begin to emerge.
This is easy to see with language. Given only “=”, next-token prediction is ill-posed. Given “2+3=”, the next token is nearly deterministic. Train a language model on enough of these sequences and the predictions become more certain. Some capabilities emerge from scale alone, but others only appear once training sequences are long enough to include the information needed to resolve uncertainty.
Learning Video and the Actions That Shape It
The same logic applies to world models. To predict the next observation, a world model has to infer the underlying state of the world and how that state evolves over time. In practice, the best source for this is large-scale, general video and action data. This pushes the model to learn structure about physics, causality, and persistence.
Learning Long Horizons and Hidden State
This becomes especially clear in long-horizon settings. Imagine someone starts running a bath, leaves the room for several minutes, and then comes back. While the bath is out of view, the water level continues to rise, the temperature changes, and the tub may eventually overflow. To make a sensible prediction when the person returns, the model has to maintain an internal state of the world and reason about how that state evolved while it was unobserved.
There are a few ways to get this behavior. One is to build in explicit mechanisms for memory or state tracking. The other is to train on sequences long enough that remembering and updating hidden state is required to reduce predictive uncertainty. If we want world models that learn the world observation-by-observation—and remain coherent over tens of minutes or hours—we need training data and training procedures that span those horizons. We’ve already seen how this plays out in language: extending context length and improving sequence modeling unlocked capabilities that were not apparent at shorter horizons.
World models are on the same trajectory. As data, architectures, and training algorithms are pushed to longer temporal scales, we should expect similar step-changes in their ability to represent persistent state, causality, and long-horizon dynamics. This is incredibly exciting.
From Narrow Simulation to General Simulation
The Limits of Hand-Crafted Simulators
Simulation is about predicting how a system’s state evolves over time, using models, data, or both. In the limit, one could imagine simulating the world from first principles, down to elementary particle interactions. In practice, this is only feasible for very small systems today.
Most real-world simulations today narrow the problem considerably. Specialized, hand-crafted models capture just enough structure to reproduce a particular behavior, while irrelevant detail is ignored or averaged away. This makes simulation tractable, but also constrains each simulator to a specific domain and a fixed set of assumptions. For example, a rigid-body physics engine is not useful for simulating weather.
As systems become more complex, these limitations become more pronounced. Many real-world phenomena are impractical to simulate accurately from explicit rules alone, and building reliable simulators demands significant human effort.
Learning to Simulate the World From Video
World models approach simulation from a new perspective. Rather than designing a simulator for each domain, we train general-purpose, causal models on large amounts of video and interaction data, and task them with predicting what happens next. Because the data reflects how the world evolves over time, the learning problem is inherently causal. Through next-state prediction, the model learns internal representations of state, dynamics, and interactions without those structures needing to be specified in advance.
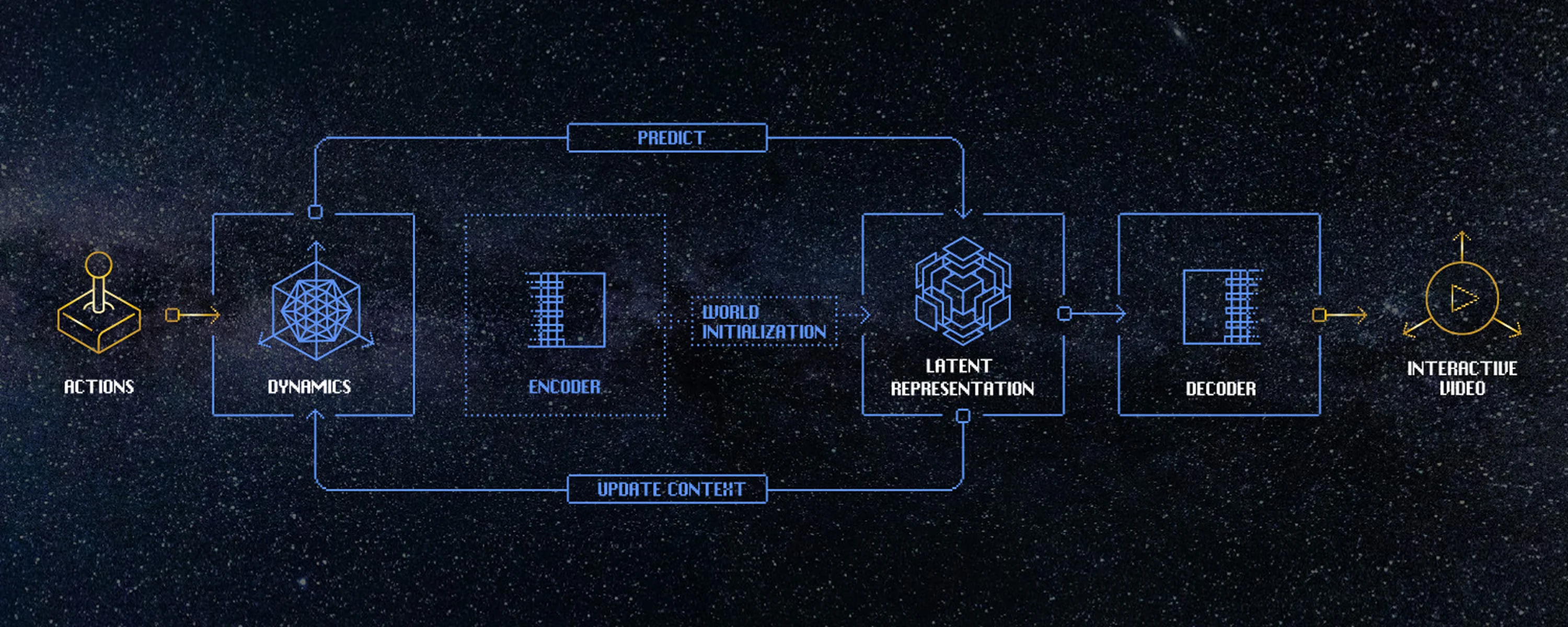
The architecture of a world model
A general world simulator, although nascent today, will enable us to test cause and effect in complex systems without writing a simulator for each one. If a model can predict how the world changes when you intervene—turn a knob, take an action, change an initial condition—it becomes a general tool for prediction and reasoning. Over time, this kind of simulator replaces many narrow, hand-built models, and becomes shared infrastructure for building and studying intelligent systems.
Odyssey-2 Pro, a nascent world simulator
Interacting With Simulations in Natural Ways
Today, simulations are mostly used as validation tools. They run offline, answer narrowly defined questions, and produce outputs that are inspected after the fact. The simulator itself is rarely something a user engages with continuously.
World models change this by turning simulation into an ongoing process. When a model generates a stream of simulation in real time—conditioned on past observations and user actions—the simulation becomes inherently interactive. This makes a different kind of interaction possible. Instead of issuing commands and waiting for results, a user can engage continuously with a simulation that maintains state over time.
A simple example is a tutor. Imagine a simulated instructor who explains a concept visually, responds to spoken questions, pauses when interrupted, and adapts based on your facial expression. For this to work, the model must learn jointly from long-horizon video, language, and interaction data: how explanations unfold over time, how dialogue and action relate, and how context is maintained across minutes or hours.
The broader implication is that simulations no longer need to be static tools or narrow. When learned from large amounts of multimodal data, world models can produce interactive systems that feel continuous and stateful, supporting richer forms of interaction than traditional simulators.

Multimodal inputs and outputs
Build the World Simulator With Us
If this direction resonates, we’re building it at Odyssey. We’re an AI lab focused on general-purpose world models: causal, multimodal systems that learn to predict and interact with the world over long horizons. If you’re a researcher interested in pushing beyond narrow models toward learned world simulators—and want to work on problems that won’t fit cleanly into existing paradigms—we’d love to talk. This is still extremely early, and the hardest problems remain open.
