
Apparently, tomorrow's artists will all be art directors, curating AI outputs as if they're assembling Pinterest mood boards. Now that AI can imitate every artist’s visual style and mimic every writer’s voice, being an artist of tomorrow seems to boil down to curation and prompting skills. We disagree.
We believe we're in the skeuomorphic phase of AI art, where we're still creating websites that mimic newspapers and films that mimic theatre. It's like watching someone use a Ferrari to pull a cart.
Simon and I are arguing that just like with previous technological revolutions, a new art form will arise; one we can already see the outlines of if we squint.

Right now, LLMs are used to shortcut the artistic creation process. The model creates simulacra from humanity's media corpus, approximating whatever the prompter had in mind. You input a prompt, the AI spits back a result. And then you iterate until you decide that the result is good enough.
Because of this iterative process, an opinion in the water of the AI art discourse is that
“Curation is the new creation”.
The images illustrating this article have been generated in this way. However, “true artists” have been critical of this curation-based approach to art.
Visual artists laugh about spaghetti fingers and writers mock that AI written text is not a creative shortcut—it’s a parody.
But as Cristobal (of RunwayML) notes:
“When photography emerged, we made a critical error: we let painters judge it. (...) They dissected this new form through the lens of their own medium, anchoring on what they knew. Predictably, they concluded photography would never match oil's texture, never capture color the way mixed pigments could. They were right and also completely missed the point. Photography wasn't trying to be painting.”
Soon enough, AI will overcome its current limitations. Until then, the limits in capacity are actually contributing to novel art: New genres emerge by leaning into limits as creative constraints. Google Translate Poetry has been flourishing for years on a dedicated subreddit. When visual AI still had problems with rendering fingers correctly, Finger Horror summoned eldritch hands that had Guayasamin turn in his grave. AI's surrealist tendencies gave rise to the Italian Brainrot phenomenon. The fact that current video generation models are limited to a few seconds has spawned multiple sub-genres from vlog-based storytelling to Gossip Goblin’s world-building.
These capacity-constrained genres are delightful historical curiosities, like watching evolution in fast-forward. But they're also obviously temporary. The more disruptive a new technology, the more radical the break in the media. And as weird as Gossip Goblin’s Cronenberg TikTok rabbit holes are, we’re confident it will get much weirder. The real question is what comes after we stop being charmed by AI's current awkwardness.

The first time that I encountered visual art that felt AI-native was a couple of years ago when I saw Xander Steenbrugge interact with diffusion models not by prompting them to generate images, but to sample the latent space directly, producing surrealist images that had a strikingly non-human vibe.
I think Xander was on the right track: AI-native art will be made of vectors, artistically sculpted corners of latent space.
The model is the art.
After all, the ethereal space of floating point vectors is the foundation of AI’s creative capacity, so it seems intuitive that art native to this technology would start there. But Xander was only halfway there; he was still doing the curatorial heavy lifting himself. Interacting with AI-models through prompting and selecting outputs has become second nature to frequent users of the technology, so I’d expect that to be a feature of how people will interact with art too.
In AI-native art, curation will be done by the consumer, not the artist.
One of the first examples of the AI-native art we imagine is Holly Herndon and Mat Dryhurst’s xhairymutantx that was commissioned for the 2024 Whitney Biennial.
People could prompt the model, and regardless of the image they tried to generate, it would always include some version of Holly (and her hair).

xhairymutantx can output arbitrary images, as long as Holly is somehow included. The output is constrained in a specific way, creating consistency throughout infinite variation.
The art is in the constraints of the model.
These constraints form the kernel of an artistic idea, the strange attractor that all variations orbit around. The kernel only becomes visible through its infinite mutations.
Practically, a kernel is a bundle of choices: which foundation model, which coordinates in latent space, what sampling parameters, what conditioning prompt. A recipe for a possibility space rather than a thing.
As in xhairymutantx, an artistic kernel could be a specific character or a distinct visual style. It could also include plot points, atmosphere, or a whole world. Fan fiction (e.g., for Harry Potter or Star Wars) can be seen as a precursor to this idea.
AI's multi-modal nature means one artistic kernel can spawn a whole ecosystem of artefacts. In the case of Star Wars fan-fiction: One person falls in love with those Stormtrooper vlogs, another wants to compose Death Star symphonies, and someone else finally puts the “opera” in space opera. Unlike fan fiction, there's no canon to rebel against, just infinite, jazz-like variations on a theme. Each co-created artefact is unique as a snowflake, yet they all share that same underlying structure, the artistic kernel that makes them recognisably part of the same creative constellation. It's like fairy tales (before the brothers Grimm and Disney got to them): there's no “original” Cinderella, but something essential persists through every cultural mutation.
The art is in the conversation of the artist and the consumer (becoming co-creator).
As a final piece to this new artistic medium, we can also anticipate that the co-creation and curation process will be AI-assisted. Personal agents appear to be a clear attractor point in the evolution of technology. And those personal agents will know the artistic preferences of each co-creator, making the generation of specific artefacts much more seamless. My agent will know that my preferred media is a 10-episode show with Kubrick’s cinematography and Villeneuve’s storytelling that I will binge in a single sitting, thank you very much.
Realistically, even armed with personal agents, I don’t expect that everyone will always be an active co-creator and make artistic and media choices. Sometimes you just want to sit back and passively consume. That’s why I’d expect that the most ingenious co-created artefacts will be consumed by others, like an organic human-made movie or novel from the ancient times. We see this pattern now: everyone can tweet, but plenty prefer lurking and scrolling. Both human and algorithmic curation will surface the AI-art equivalent of banger posts that will be enjoyed socially.
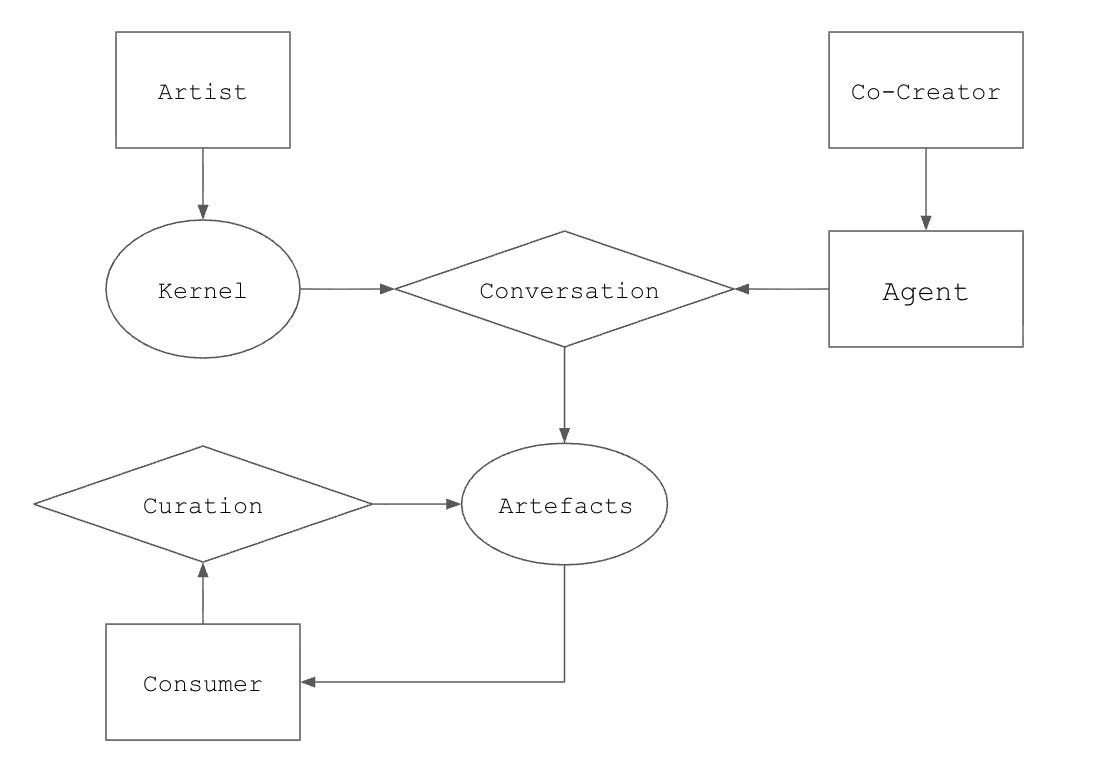
The flow chart above summarises the vision of AI-native art that I have in mind. Precursors of this conversation through agents are already happening: Ken Liu uses an LLM as a translator, generating multiple translations of a Chinese poem from different lenses. The Chinese version is analogous to the kernel (the difference being that there is still a fixed object in the form of a poem) that is explored through an agent, producing multiple artefacts.
With AI, Art has taken a procedural turn.

“Marshall McLuhan, patron saint of media theory hot takes and professionally cryptic aphorisms, gave us a useful lens here. AI is a “cool medium” in that it is participative (iterative prompting), low-definition (non-deterministic outcomes), and multi-modal (text, image, etc.). Cool like snowflakes. All alike, but each one is different. The most helpful framework of McLuhan’s is his tetrad, describing four simultaneous effects:
Enhancement: What does the medium intensify?
Obsolescence: What does it push aside?
Retrieval: What does it bring back from the past?
Reversal: When pushed to its extreme, what does it flip into?
This is a McLuhan Tetrad when applied to the vision of AI-native art described above.
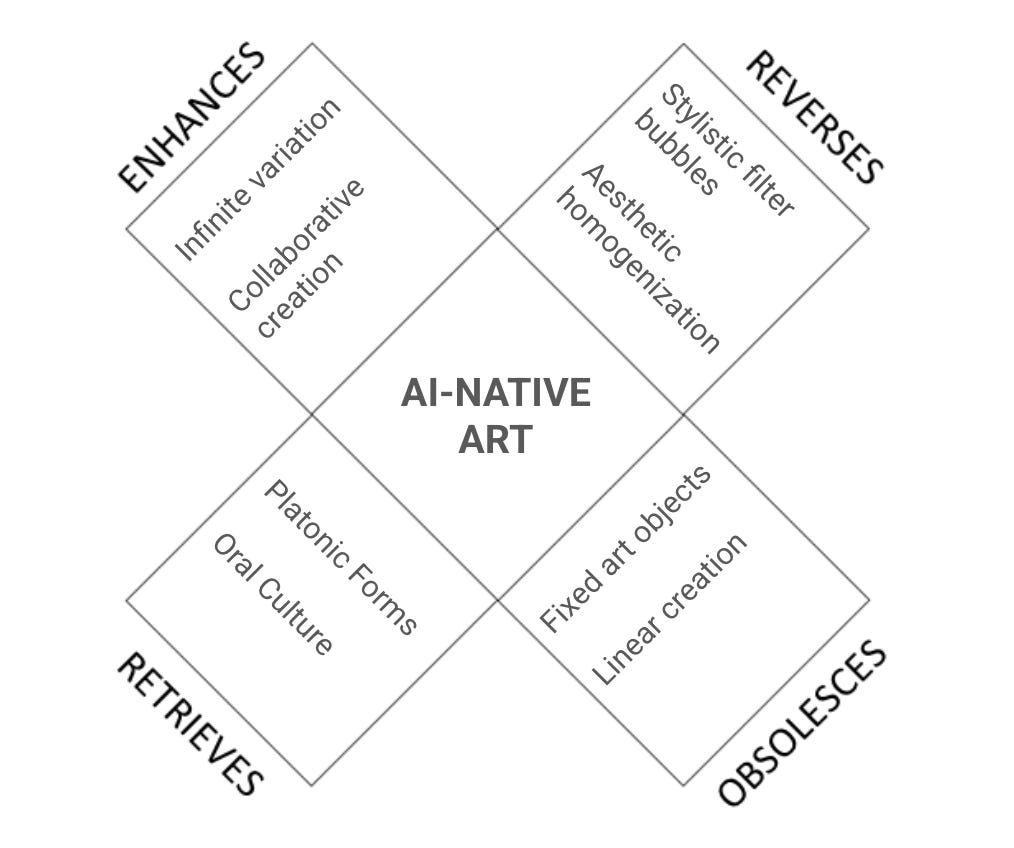
It enhances in the sense that it adds the capacity for infinite variation on an artistic kernel. Users become co-creators and collaboratively create many different artefacts in their preferred formats and styles. Art was always co-created: it lives in the collision between what artists think they're saying and what audiences actually hear. With AI-native art, that interaction becomes a conversation that produces tangible artefacts. These user generated artefacts become the art objects that spectators take in.
In that sense, fixed art objects, the “original version” , the canon, become obsolete. And with it, any notion of linear creation process. Not only is there a continuous stream of new artefacts unfolding the kernel of artistic vision, but each of them is created iteratively.
The kernel itself retrieves the notion of platonic forms. An abstract idea that can only ever be approximated by each physical manifestation. It is by looking at many artefacts that we can intuit the kernel and understand the artistic vision of an AI-native artistic conversation, just like we can asymptotically approach the idea of a chair by sitting on many of them. The endless variation and co-creation retrieve something even older: oral culture. Before writing ossified stories into fixed forms, songs and stories would constantly evolve as they traveled the world. Fairy tales vary wildly across languages and cultures. The core themes often persisted, but most of the details changed, from names to metaphors.
Like anything, we can (and absolutely will) take this too far. AI-native art will reverse into aesthetic homogenization if the same AI model is used by most co-creators. The nightmare scenario: we achieve infinite creative possibilities and accidentally use them to make everything look like the same Midjourney fever dream. Artistic dystopia with good lighting. As AI-generated artefacts are used as training data for the next generation of models, this effect will only get reinforced. Runaway self-training could trap us in endlessly repeating the same aesthetic. A similar effect happens through the preferences of co-creators and consumers: Just like filter bubbles on current social media select the type of content that we consume, our preferences in form and style could be ossified by the use of AI agents. Whether we are co-creating or just consuming art, our agents will have learned our preferences and serve us more of the same. The Ghiblification phenomenon might be a precursor of this effect. If all of your media follows the visual language of Dark Academia, you are in a stylistic filter bubble.

Sure, this vision of AI-native art is rampant speculation based on cherry-picked examples and a flow chart. And yet I can think of broader movements that are foreshadowing the rise of a new medium that is co-created with infinite variability while sharing an underlying structure: Dungeons and Dragons became mainstream. Interactive theatre seems to be rising in popularity, too. I’m seeing more shared authorship for avant-garde writers, from Hanzi Freinacht to David J Temple. And consider the most internet-native medium, the meme. Infinite variation on a common structure, co-created by posters competing for virality.
Co-composting, the process by which this piece was written, is a synecdoche of our vision for AI-native art. Simon and I had several conversations on the topic, collected notes and research in a shared document, and wrote two distinct pieces based on the same underlying material. The latent space is the intersection of the world models of the two authors and their creative dialogue. You can read two distinct artefacts, but you don’t get to see the kernel directly (the co-composting document). While this text is still human-written, AI agents supported at least my writing process and added illustrations. And Xiq gave feedback (thank you!).
The conversational aspect of this co-creation between different humans and AI agents is the most important aspect of these speculations. The real promise of AI-native art isn't infinite content, but infinite perspectives on the same deep structures of meaning. Each generated artefact becomes a facet of something larger, like looking at the same mountain from different angles. The mountain doesn't change, but our understanding of its totality deepens with each view.
This shift makes visible something that was always true: art emerges not from solitary genius but from the continuous conversation between creators and communities. AI-native art promises to make that conversation more generative, more accessible, and infinitely weirder.
Thanks for reading all the way! Help bring in others into the conversation by sharing this.