Truth and Trust is lost in Internet Search
Internet Search, the most common search, is highly optimized to be incredibly broad, giving preferential to popular contents through keywords in web; ending up inconsistent in source quality and unreliable. Also, the search is a one-shot search for simple queries (keyword matching), same results for everyone.
We started Nouswise to be semantic and agentic search over curated knowledge (authoritative content-a portion of what Google might not have access to) resulting in consistent source quality and trustworthy. Also, the search is interactive (allowing follow up questions) for complex queries (natural language), personalized to the user.
In this post, I'll explain at a high level how we're building this end-to-end.
The requirements:
A perfect trustworthy search requires to:
- Understand arbitrarily complex queries ("The effect of US policies on climate change on other UN members' policies in years between 2008-2016 and what are the recent implications")
- Comprehend and return any response in any medium ("make a podcast about inflation from the ECB reports")
- Only answers across curated knowledge - refuse to hallucinate ("I'm sorry but I kindly decline to answer to your query about cooking pizza, however I can help you with the influence of pizza on Italy's economy")
- Personalize the response ("...this policy can influence companies like where you work in")
- Drive insights ("What are the central bank's policies about the inflation in 2010s and their social implications")
- Understand different mediums and answer in different mediums accordingly (text, image, video, …)
Traditional search engines like Google can't do these by only using 10 blue links and SEOs - even their state-of-the-art AI cannot manage it!! AI tools like ChatGPT are designed to answer all questions at all costs (for engagement), more often than not at the cost of hallucination.
Nouswise is a next-gen answer engine, built to power the trust and confidence in the responses by leveraging AI, addressing the world's ever increasingly trustworthy informational needs in the way we understand information. To build it, we're redesigning the whole system from the ground up.
The fundamental Infrastructure
Information search always involves three fundamental pieces: ingesting and digesting the curated knowledge (documents, notes, …) for retrieval, retrieving the right information, and serving queries.
The first step is gathering data. Not an easy task for any organization, even many of them are not digitized or are just scanned (OCR)- piling up to tens of thousands of documents if not hundreds of thousands or more! some related and some unrelated from each other.
To build Nouswise's document preprocessing system, we constantly look for new relationships between the documents. It's done within a few steps and stages: 1. Each document has an outline (table of content-TOC) and sometimes each section has its own subsections, we process (embed) and store the tiniest body of the structure that carries an independent body of information as an entity. The combination of these tiny entities creates a bigger entity and going from within to without (from inside to outside) leads us to an entity for each document.
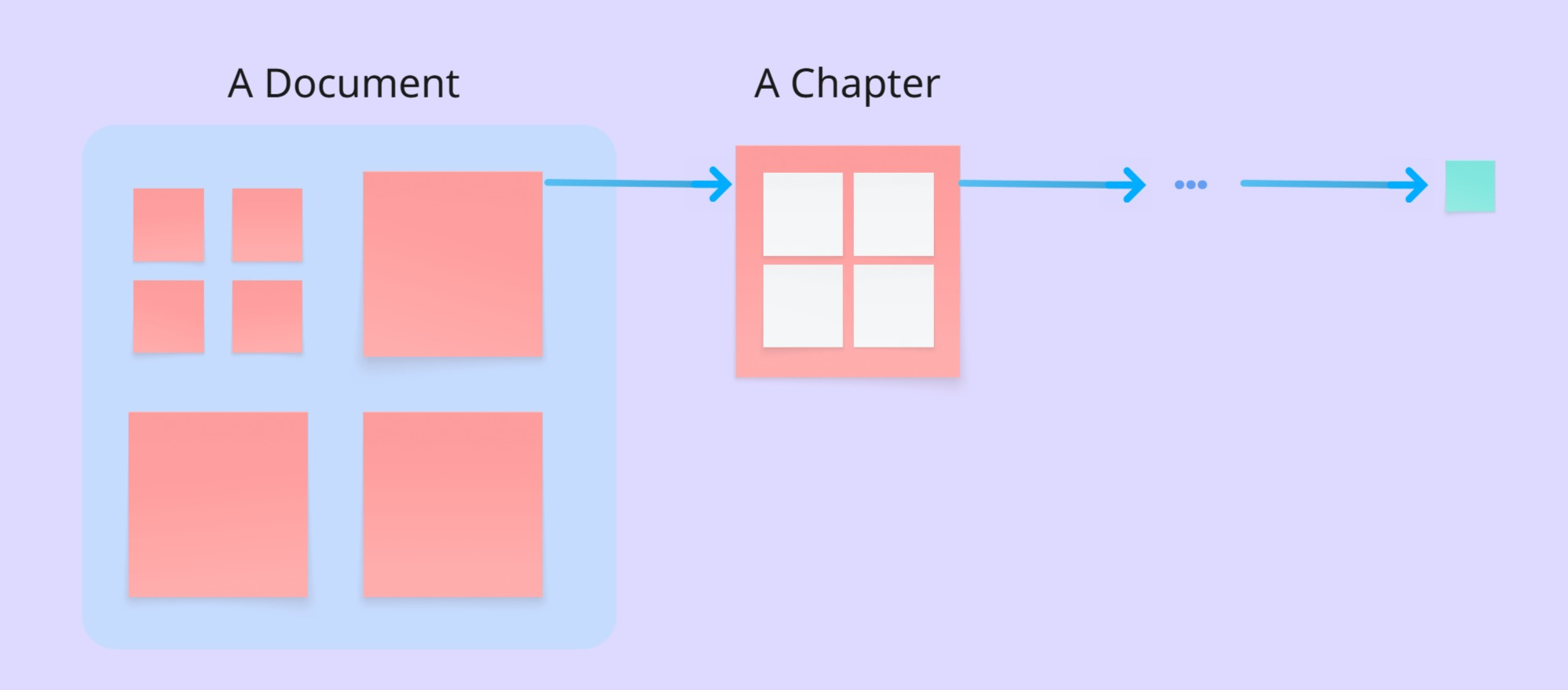
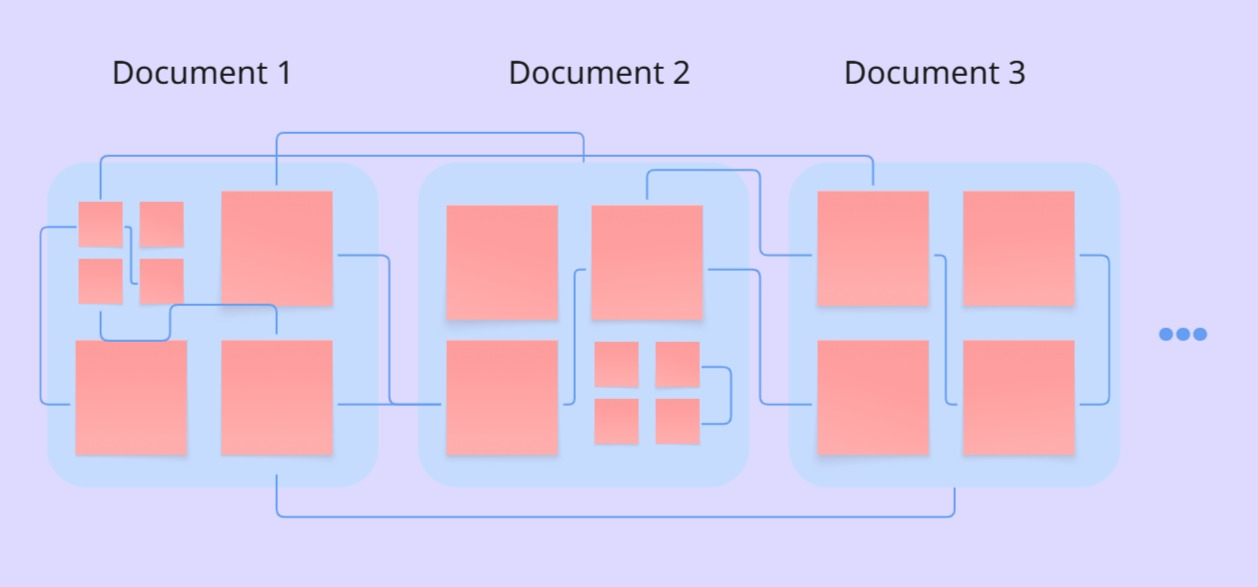
This is not where it ends, the next stage is correlating these entities with each other from the highest (big entities) to the lowest level (tiny sub-entities). This correlation making process is not done only once, anytime we have a new document, new correlations are built, constantly improving the knowledge graph. Here is where our secret sauce comes from. We train neural models to preprocess and connect documents into embeddings every time we have a new source.
This means the more data we have, the more connections are made, and consequently the better the retrieval becomes.
Now that we have our source(s) processed, we need a query from the user. The user writes a query in natural language in any language. Here we have an agentic process that starts with detecting the language, understanding the query, recognizing the intent, ... once we know what the user is looking for, we only need to retrieve the most relevant information and craft the answer.
As the set of data is processed, we have a structure that includes countless nodes (entities) and edges (connections), ready to be used for retrieving information. Once the user sends a query, after understanding it, we have multiple agents looking for relevant information simultaneously, looking into the nodes and their entities. Once these agents find the relevancy of the information, we distill the most relevant information, extracting the relevancy of the collected raw information, from the least relevant to the most relevant.
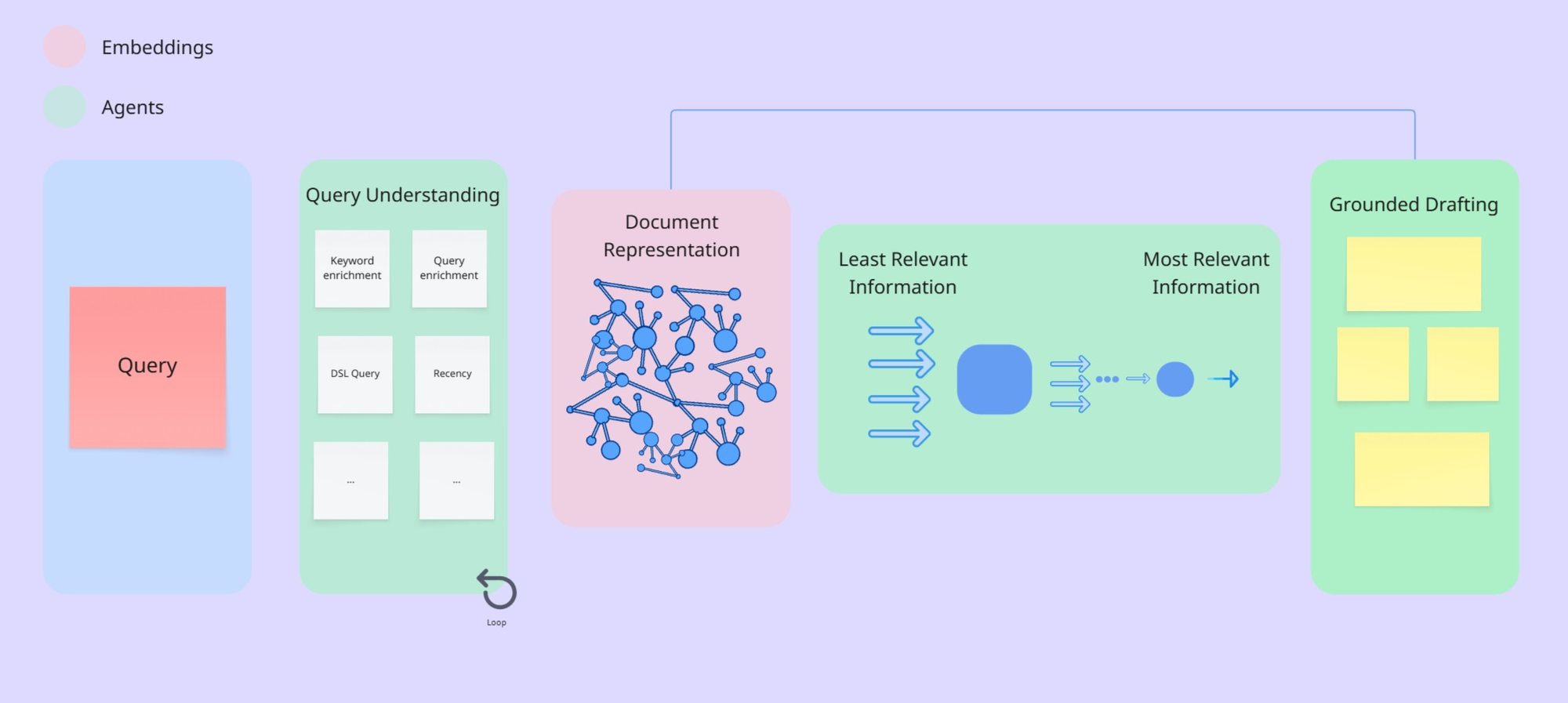
The last step is where magic happens, we combine the information we have about user ('user profile'), the memories (both "short term memory" and "long term memory"), most relevant information ("retrieved information") with the query ("user query"), drafting and feeding it to the final LLM to craft the answer.
Our agents do not only provide an answer from one source (document, ..), instead they do a quick reasoning process to generate not only an answer but an analysis with insights across different sources.
The answers are multi-modal, meaning we search through the diagrams, graphs, tables, paragraphs, .. of the documents and provide the answers both textually and visually, backed by both visual and textual fine-grained line-by-line citations, simplifying verification in a fraction of a second.
Our internal benchmarks resulted in outperforming the current existing AI search tools in the market.
Interfaces for Trustworthy Content
As a search product aiming to reach perfect answers, we need to provide our users reliable search from authoritative contents they trust the most, fulfilling all their particular information needs.

Unlike other search engines that have one search experience for all consumers (everyone gets the same Google result) we provide a unique and personalized experience to the user, discovering insights buried in the huge piles of data in a matter of seconds, paving the way to get deeper with follow-up questions and projects.
We avoid mixed quality information in our search interfaces, i.e. we only use curated knowledge to provide responses and when users are using an interface they know whose information is used.