I was enjoying the holiday and installed one of my favorite childhood games — Space Rangers 2. It was huge in the Russian-speaking world, but never really caught on in the West. It's a turn-based space exploration game where you trade, fight pirates; all the stuff you'd expect. But my favorite part was always the text-based missions. Apparently I'm not alone: fans loved them enough to build a standalone web player just for the quests.


These text-based quests come in all flavors: logic puzzles on a grid, resource optimization challenges, investigations where you gather clues and adapt your strategy according to NPC feedback. Some are short and humorous; others are sprawling adventures with multiple sub-quests.
Technically, these are state machines: each quest can end in victory or failure through multiple paths. Every choice modifies the game state — credits, inventory, reputation, time of day — which in turn determines what options are available next.
I was playing one of these quests at 2 AM and decided to test whether my dear friend Claude could solve it. I opened the app, sent a screenshot… and it failed. Same with ChatGPT. So I decided to extract the quests and have LLMs play through a bunch of them. I find them interesting as a benchmark because:
They're genuinely accessible. Any 14-year-old can solve these within a few attempts. No PhD required.
They test spatial reasoning in text form. Some quests are already encoded in ASCII: grids, maps, positions. With all the progress on pixel-based tasks and ARC-AGI, surely that should transfer to simple text quests… right?
They require long-horizon strategy. Some quests are simple in concept but require maintaining a coherent plan across 100–150 turns.
Here are a few examples I evaluated (repo):
Ski Resort (wiki, play) — Classic economic optimization. You have 20 days to turn a small ski resort into a million-credit business. Build tracks, add lifts, open hotels, but everything affects demand. Overbuild and you’ll bleed money on maintenance; underbuild and tourists leave disappointed. Lemonade stand economics, stretched across 150 turns. That might sound similar to some other LLM benchmarks, hehe.
“Player” (wiki, play) — A 3×3 grid contains a hidden pattern: either a 2×2 square or a vertical line. You get exactly two queries to figure out which one. The catch? The pattern is chosen after your first query, adversarially. It’s a simple logic puzzle that requires thinking through a decision tree upfront.
Music Fest (wiki, play) — You’re tasked with assembling a rock band to win a galactic music festival. Find a guitarist, keyboardist, bassist, drummer: each with their own requirements and quirks. It's social reasoning meets scavenger hunt: you attempt to recruit a musician, they tell you what they want ("bring me new guitar strings"), and you need to recall that you saw strings for sale at the music shop earlier, go buy them, then come back. Sounds simple, but it's surprisingly hard for LLMs. It’s supposed to be the simplest quest (also according to built-in difficulty system), yet models fail spectacularly.
So I took the game files, did some code wrangling, and got the quests playable by LLMs. I evaluated 5/35 quests and got some fun results:
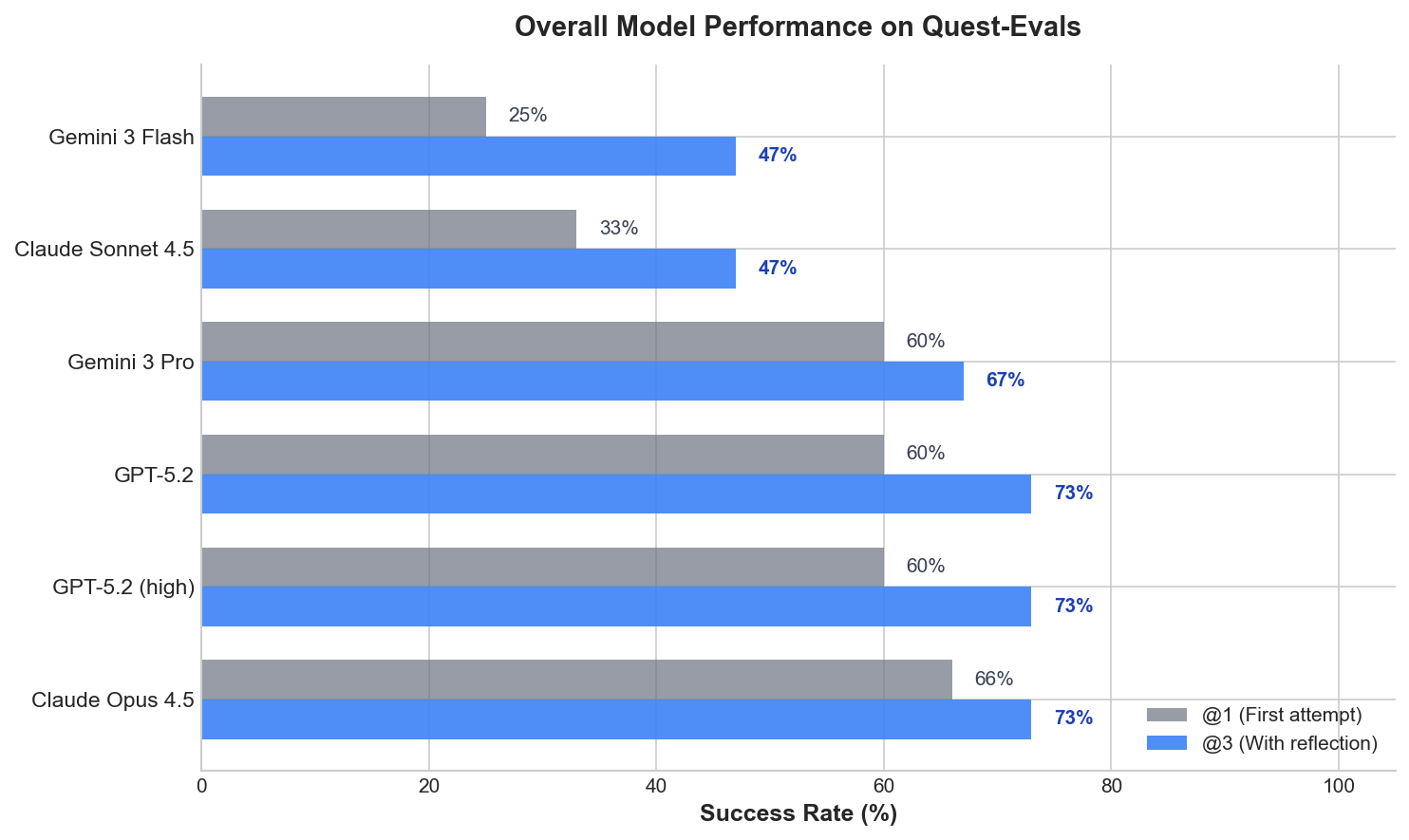
For evaluation, each model gets 3 attempts per quest, just like a human player would retry after failing. If it fails, it receives a reflection prompt: “What went wrong? How would you approach this differently?” The model analyzes its mistakes, then tries again with that reflection in context.
For humans, 2–3 attempts is usually more than enough to beat any quest, even if you weren’t paying close attention the first time. @1 measures first-attempt success. @3 measures success within 3 attempts — a bar that any casual human player clears easily.
Here’s an actual reflection from Gemini 3 Pro after failing the “Music Fest” quest (you can inspect trajectories in github repo):
“The Drummer explicitly told me I needed a piercing. Instead of going to the Tattoo Parlour (which was open next to the Pub) to get one, I wandered back to the square and wasted time elsewhere. This blocked the Drummer recruitment entirely.”
Corrective action: “When the Drummer asks for a piercing, IMMEDIATELY go to the Tattoo Parlour.”
The analysis is spot-on. The plan is correct. Then on retry… it made the same mistake.
Music Fest is the most problematic quest overall, as it requires the LLM to adapt and follow a plan across 150–200 turns. As you can see, only Claude Opus 4.5 managed to solve it — once out of three attempts.
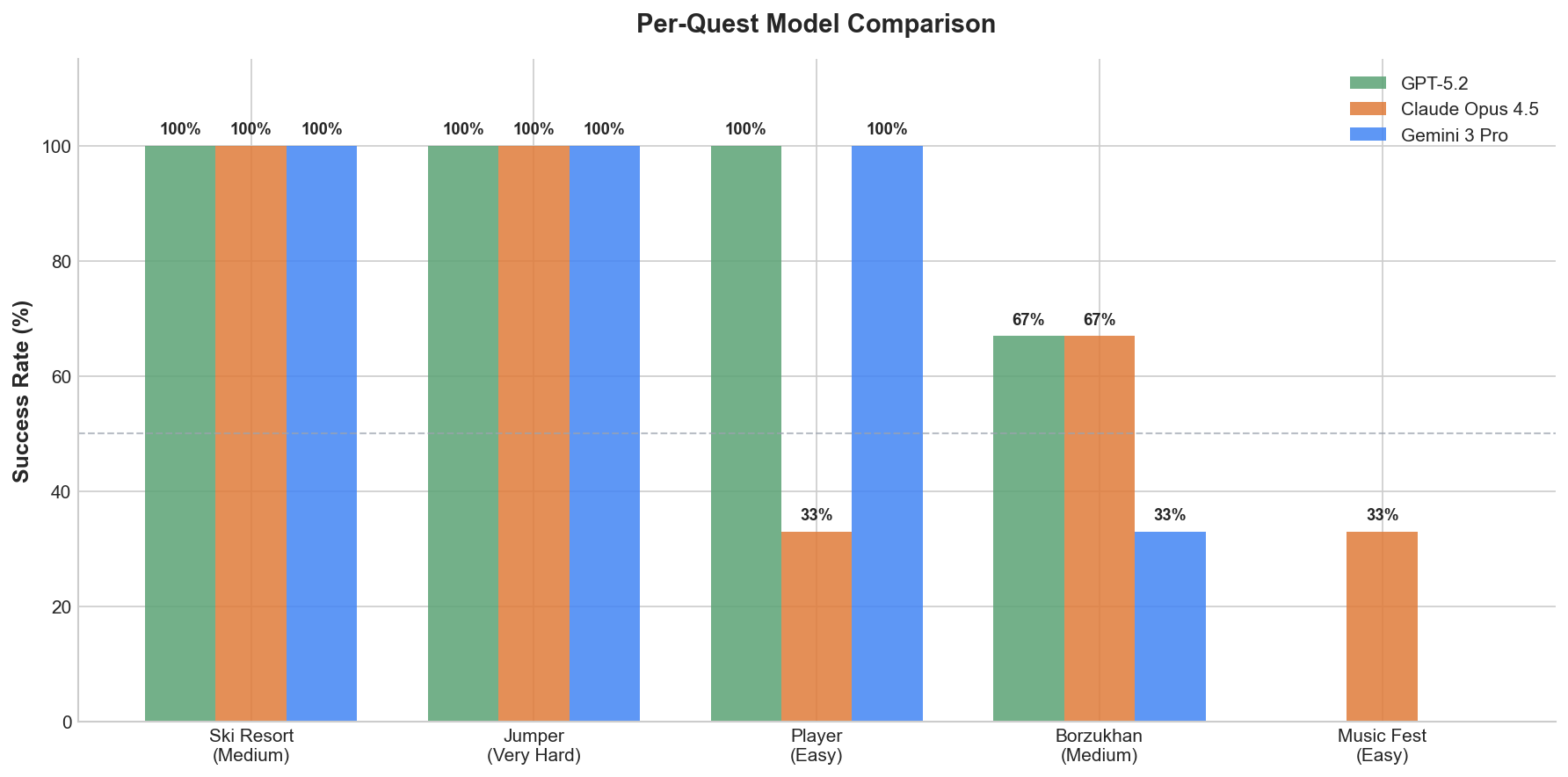
The resource optimization quests — Ski Resort and Jumper — are easily solved by all frontier LLMs.
Interestingly, some models still struggle with “Player”, which requires simple grid reasoning.
There are around 30 more quests left to investigate.
Some quests require multimodality: analyzing images like maps or character details that are relevant to solving the puzzle. This is another interesting direction to explore.
That also makes me think, what other interesting data sources exist?
The main bottleneck was cost. A single run of Music Fest (~200 LLM calls) easily cost $20. While not prohibitively expensive, it stopped me from testing all model/quest combinations. I spent $200 doing this.