Neurometric was founded on the idea that most of the “agentic” workflows companies are paying top dollar for don’t actually require frontier-scale intelligence. They require precision, consistency, and the ability to follow a well-defined procedure. That’s a very different thing — and it’s one that small language models can deliver at a fraction of the cost.
We’ve been building the tooling to prove it. Our proprietary SLM toolkit converts narrow agentic tasks into fine-tuned small language models that perform at the same level of efficacy as their larger counterparts. This will launch with a bigger announcement next week but for now, the results have been compelling enough to share a preview.
Consider a financial auditing task: loading an Excel workbook with thousands of rows, computing a statistically valid sample size, calculating quarter-on-quarter variance, applying entity-specific audit criteria, and producing a two-tab output workbook. This is exactly the kind of structured, multi-step workflow that enterprises throw GPT-5 or Claude at — and pay accordingly.
We took that same task and ran it on Qwen 2.5 at 1.5 billion parameters. Not 70 billion. Not 405 billion. 1.5 billion. The model runs locally, costs nothing per token, and completed the full audit workflow correctly.
The catch? Small models need more scaffolding than frontier models. They need it, and it’s worth building.
Our toolkit supports two complementary approaches, and knowing when to use each is half the battle.
Path one is fine-tuning. For tasks with a well-defined input-output mapping — like computing audit sample sizes from population parameters — we generate synthetic training data, format it into chat-style message pairs, and fine-tune using LoRA adapters. The pipeline handles everything: a synthetic data generator produces hundreds of realistic examples, each with a CSV population file and a JSON file containing the statistical calculations. A preparation script formats these into the message structure that modern models expect, with system prompts, user inputs, and expected assistant outputs. Fine-tuning runs against the base Qwen 2.5 model with configurable sequence lengths, and inference is handled through a clean Python class that loads the adapter and generates responses.
The sample size model, for instance, takes in population size, confidence level, tolerable error rate, and a few other parameters, then returns the correct integer. No chain-of-thought. No hedging. Just the answer. That’s the kind of task where a fine-tuned SLM doesn’t just match frontier performance — it’s actually preferable, because it’s deterministic, fast, and cheap.
Path two is agentic orchestration with tool use. For more complex workflows that require sequencing multiple operations, we built a harness around the SLM that provides structured tool access. The model calls functions like load_population, compute_sample_size, compute_variance, and finalize_sample_workbook in a guided sequence. Each function does exactly one thing well, and the model’s job is to call them in the right order with the right arguments.
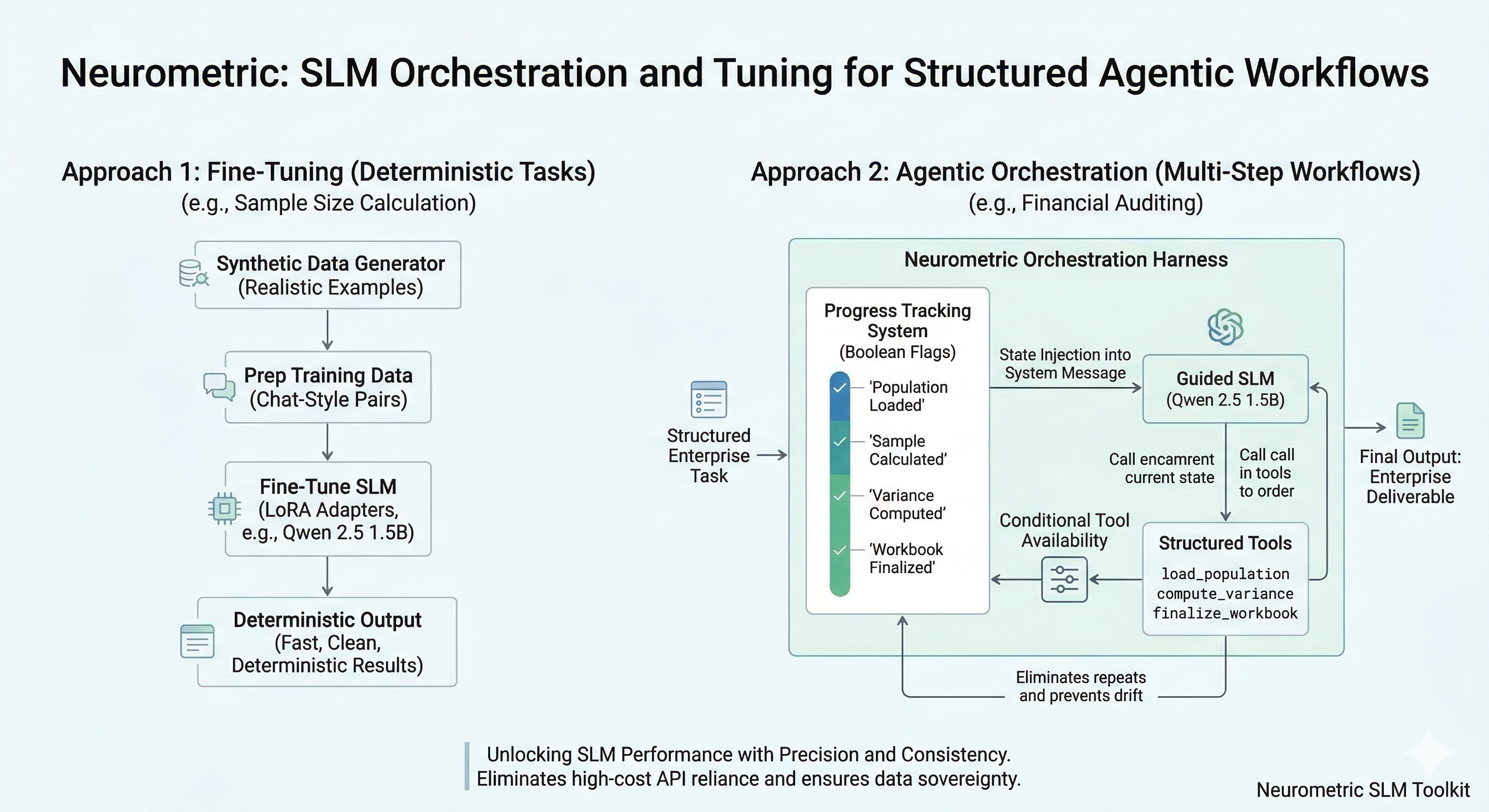
Here’s where small models can get tripped up. A 1.5B parameter model does not naturally reason about task ordering the way a frontier model does. Left to its own devices, it will repeat function calls, skip steps, or drift off-task entirely. We discovered this early and addressed it directly.
The solution is a lightweight progress-tracking system. A set of boolean flags tracks which stages have been completed — population loaded, sample size computed, variance calculated, coverage met, workbook finalized — and a progress summary is injected into each turn’s system message. The model sees exactly where it is in the workflow and what it should do next. Conditional logic restricts which tools are available at each stage, preventing the model from calling functions out of sequence.
This isn’t a hack. It’s a design pattern. Frontier models internalize task sequencing because they’ve seen enough examples to infer it. Small models need that structure made explicit. The performance is equivalent; the architecture is just different.
The economics here are straightforward. Frontier API calls cost between $2 and $35 per million tokens depending on the provider and model. A locally-hosted 1.5B parameter model costs the electricity to run it. For high-volume, repetitive tasks — audit sampling, compliance checks, data validation, report generation — the savings compound fast.
More importantly, local models eliminate the data sovereignty concerns that keep many regulated industries from adopting AI at all. Your financial data never leaves your infrastructure. There’s no API call to intercept, no third-party retention policy to evaluate, no vendor lock-in to negotiate.
This toolkit will launch next week as part of a bigger launch including some other pieces, but we are ready to take some alpha customers for it now. Email slms-at-neurometric.ai
The post-model world isn’t about bigger models. It’s about the right model for the right task, deployed at the right cost. That’s what we’re building toward.