This is a follow-up to last week’s article on the April 2026 nuclear command-and-control exercise window. That exercise window is, I believe, ongoing. It’s also a response to a recurring pattern. For the second or third time in the past week, an HFGCS-related post of mine has reached well beyond my usual audience. Each viral moment has produced a distinct version of the same audience reaction. I think I now have a clear enough diagnosis of what is happening to write it down.
At 20:52 UTC on April 24, 2026, an EAM was broadcast on the HFGCS with the callsign RADFIELD. This message is 21 characters long, and it’s the third 21 character EAM I have documented.
The first two were broadcast an hour apart on on August 22, 2025. Today’s RADFIELD is the first 21 character EAM observed outside that August 2025 cluster. It arrived during a period I have previously identified as a likely exercise window. That’s the news. The rest of this article is about what to do with it.
I have published the majority of my HFGCS transcriptions to a public GitHub site at neetintel.github.io. The catalog is organized by EAM body length. The page for 21 character EAMs is at neetintel.github.io/structure_heatmap_21char.html. It now contains three entries.
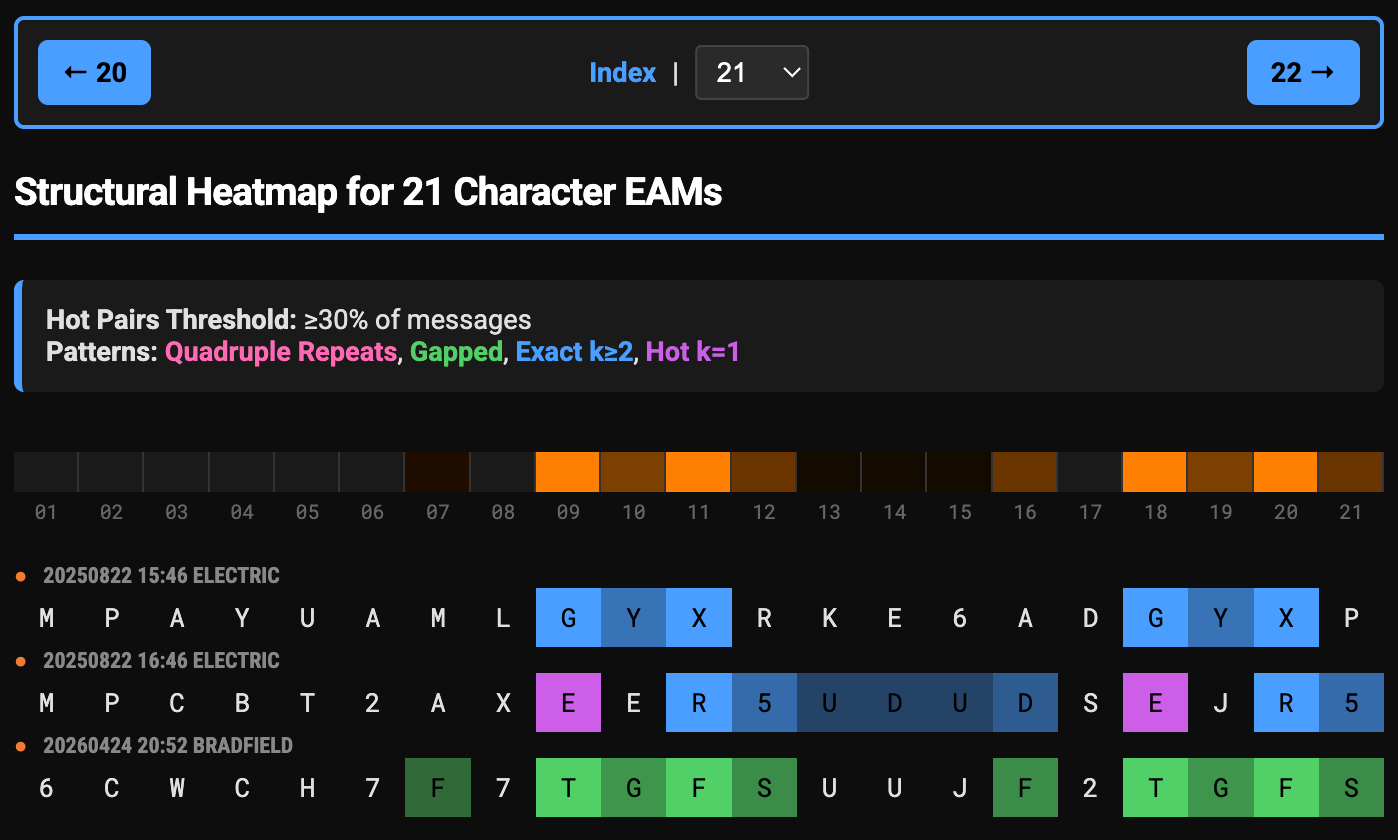
For anyone who wants to verify that this is genuinely the third such observation rather than a retroactive insertion, three independent verification paths exist;
The first path is the Internet Archive. I captured the 21 character page on archive.org on April 10, 2026, two weeks before today’s transmission. The archived snapshot shows only the two August 2025 entries. A number of other pages are also archived, and so you can check and see which ones are credibly “rare”, which are not, and make determinations for yourself along these lines.
The second path is my YouTube channel, https://www.youtube.com/@neetintel. It contains hundreds of hours of HFGCS recordings spanning the monitoring period. The vast majority of the transcriptions on the GitHub site can be cross-referenced against those recordings.
The third path is open. If anyone reading this has independent recordings or documentation of a 21 character EAM, from any date, I want to know. More data is better than less data. If there are 21 character EAMs in the historical record I missed, that is genuinely useful information, not a threat to the analysis.
Three documented 21 character EAMs across four years of monitoring is such that descrbing them as “rare” is not a rhetorical flourish, but a literal description.
The United States military conducts large nuclear command-and-control exercises on a regular cycle. Some of these are publicly named. Some are not. They involve real airspace reservations, real aircraft sorties, real radio activity, real Emergency Action Message traffic. They are observed by allies. They are observed by adversaries. They are observed by some hobbyists with shortwave radios and/or SDRs.
The United States military has very wide latitude in how it conducts these exercises. The choice of geography. The choice of which assets are deployed. The scale, the duration, the message structure, the callsigns, the timing relative to other geopolitical events. All of these are choices, made by people who know they are being observed.
When you make a choice that you know will be observed, that choice is communication. That remains true even when nothing kinetic happens. It remains true even when the exercise is, in every formal sense, routine training. The exercise can be entirely a rehearsal and still be a message, because the choice to rehearse this thing rather than that thing, in this place rather than that place, at this time rather than that time, is itself a signal to anyone watching.
This is what the dismissive frame collapses. “It’s just an exercise, bro” pretends the signaling layer does not exist. It treats the exercise as inert. It treats the choices made by US planners about scale, geography, asset deployment, and tempo as though they were random, or natural, or not choices at all – but they are choices! They are designed by people who understand exactly what those choices look like to a Russian intelligence analyst, a Chinese intelligence analyst, a NATO partner, a domestic political audience, and yes, even you and me.
For us to be able to read an exercise as communication, we have to know what normal looks like. We have to know the parameters. We have to know what the typical scale is, what assets typically deploy, what geography is typically practiced over, what message lengths typically appear, how often, and under what conditions. Without that baseline, we cannot tell whether a given exercise is more bellicose than usual, less bellicose than usual, or exactly as bellicose as it always is. And many of you cannot tell whether a 21 character EAM during this window means anything, because you do not even know how often 21 character EAMs are sent in the first place.
The dismissive answer requires no work. The interesting answer requires years of monitoring. That is why people prefer the dismissive answer. It is not because it is correct. It is because it’s easy.

NEET INTEL@neetintel
MAINSAIL has been destroyed, so did this E6 just broadcast authorization codes to take over as the HFGCS master control...?

NEET INTEL @neetintel
@ParssinenPaulus 21:01 DEDICATE [E6?] to MAINSAIL: "I acknowledge that you have been destroyed"
9:50 PM · Aug 20, 2025 · 10.4K Views
10 Replies · 5 Reposts · 95 Likes
In August 2025, the US military conducted a SKYMASTER event. A Mercury E-6B operated in the airspace around Pituffik Space Base in Greenland. A B-52 conducted a 24-hour flight over the continental United States during the same window. I noted at the time that the Greenland E-6B was unusually difficult to track and that figuring out which aircraft was operating where required more work than usual.
On August 22, two 21 character EAMs were broadcast within an hour of each other.
A reader applying the “just an exercise” frame to this activity at the time would have classified it as routine STRATCOM training, possibly with an Arctic exercise component. That classification was technically correct. I was one of the people providing that classification.
NEET INTEL@neetintel
yeah bro stratcom has been running a nuclear war scenario exercise all day

Pentagon Pizza Report @PenPizzaReport
The Papa Johns closest to the Pentagon is reporting above average traffic. As of 8:03pm ET
12:08 AM · Aug 21, 2025 · 9.77K Views
6 Replies · 17 Reposts · 189 Likes
My past commentary is relevant to this argument. For most of my time monitoring HFGCS, my standard public posture in response to “is this real or an exercise?” was to encourage the audience to understand exercises as exercises. That posture was itself a corrective response to bad-faith grifting in the prepper-adjacent space, where every loud transmission becomes evidence that the world is ending and you need to buy survival supplies. Pushing back against that grift in good faith required me to deflate the panic, repeatedly, with “these are scheduled training events, calm down.” I stand by having done that.
What I am increasingly less sure of is whether “these are scheduled training events” was or is the whole story. The timing of certain exercises relative to certain geopolitical events. The behavior of certain countries during or just before certain exercise windows. The geographic concentration of activity in places that became politically salient months later. None of these correlations is individually decisive. Several of them are likely artifacts of selection bias, or of confusing cause for effect, both of which I have spent considerable time pushing back against in this space and continue to push back against. But there are now enough of these correlations that I cannot in good faith continue to dismiss the possibility that some of these exercises also function as messages in the sense developed in the previous section.
Approximately five months after the August 2025 exercise, Pituffik Space Base became the geographic and strategic center of the most acute US-Denmark-NATO crisis of recent years. The Trump administration’s pressure on Greenland escalated sharply in late December 2025 and through January 2026. Pituffik and its strategic value were central to the public discussion. The administration’s stated rationale turned on the base’s role in early warning, missile defense, submarine monitoring through the GIUK Gap, and Arctic posture more broadly. The crisis was resolved, at least for the moment, at the World Economic Forum on January 21, 2026.
I am not claiming the August 2025 exercise predicted the January 2026 crisis. Rather, I think we do need to be able to discuss the possibility of whether or not the August 2025 exercise may have been a message to that end, and that the conversation needs the analytical room to take that possibility seriously, rather than always closing it off. The choice to put an E-6B in the airspace around Pituffik, in the same window as a 24-hour B-52 flight over the continental United States, was a deliberate set of operational choices, made by people who understood the combined activity would be observed. Whether or not those choices were specifically intended as a signal about US Arctic posture, they were visible against a backdrop of strategic priorities that became impossible to ignore five months later. The exercise and the crisis emerged from the same set of priorities. The exercise was visible first.
What I would hoped to have seen from OSINT by now – and what I want to see from the public for it to make sense for me to continue to engage with a wider audience at all – would be the willingness to hold this possibility open rather than collapse it into one of the two answers the current discourse permits. The grifter answer is “every transmission means imminent war.” The dismissive answer is “every transmission is just routine training.” Both answers are wrong in the same way, which is that they refuse the analytical work. The honest position is that the August 2025 exercise may have been a message about Greenland, that this is a real possibility worth examining, and that the work of examining it is exactly the work the binary frame forecloses.
I do not think every exercise carries a discrete message. I do not think the messaging interpretation should be applied indiscriminately. The risks of overinterpreting, of seeing patterns that are not there, of confusing cause for effect, are real, and I have written extensively about them elsewhere. However, the floor of seriousness has to rise above “is this guy grifting or not.” If the conversation cannot get past that question, it will never get to the actual analytical work, because I will continue to waste too much of whatever time I can afford to this to arguing with you all in the replies of posts or writing these huge treatises begging you to get with the program.
The April 2026 exercise window is currently active. Today’s RADFIELD message occurred during it.
A note on terminology before I continue. I reserve the term SKYMASTER for events where the SKYMASTER callsign is documented on the HFGCS. Events that produce the kind of activity I would expect to accompany a SKYMASTER, but without the documented callsign evocation that would confirm one, I label NOTHINGMASTERs. Either they are similar-scale exercises that are operationally different, or the callsign was used and I missed it. As of this writing, I have not personally heard a SKYMASTER evocation in this period. I am confident that nuclear command-and-control exercise activity is currently underway. I am not yet in a position to call this a confirmed SKYMASTER event by my own classification rules. April 21, 2026 was a date I had flagged in advance, and I classed it as a NOTHINGMASTER for the same reason.
Nonetheless, the activity profile remains consistent with a nuclear command-and-control exercise. A 21 character EAM appearing during this kind of period is consistent with what I would expect, given that the previous two appeared during the confirmed SKYMASTER event in August 2025. That observation is the smallest defensible claim about today’s message, and it’s the one I am most confident in.

At the time of broadcast, the airspace reservation CARF 04/536, designated ASHEN with the codename OAK CHARLIE, was active over the western Atlantic between Norfolk and Bermuda. The reservation runs surface to FL250 for a three-hour window. I am flagging it because the geographic and temporal coincidence is interesting, and because the western Atlantic is a plausible operating area for the kinds of assets involved in this kind of exercise.
What this exercise window is communicating, and to whom, will become clearer in retrospect. That is how this always works. Keeping a list of which exercises happened where, and watching what becomes contested in the news cycle that follows, is a more reliable analytical practice than trying to read individual EAMs as omens. The signal becomes legible later. The work in the present is to record the signal accurately.
My traditional response to being called a grifter has been to welcome the skepticism. I have actively encouraged it. The YouTube channel, the Twitter account, the GitHub catalog, the archived snapshots, the methodology notes, the public forecasts that can be checked against later observation, were all built specifically to provide the receipts a serious skeptic should ask for. A reader who asks “how do I know you did not make this up” is asking the right question, and I have spent four years constructing the infrastructure that answers it.
What I am responding to now is something different. The grifter accusation continues to arrive even when the receipts are sitting on the table next to it. A reader who could verify the rarity claim by clicking the archive.org link earlier in this article, and chooses instead to call me a grifter, is not engaging in skepticism. They are venting. I used to welcome inquiry. I do not, anymore, when it arrives without any.
The screenshot on this article, taken from my X monetization dashboard, should clarify what is materially at stake. Three consecutive two-week reporting periods, all marked “Below minimum earnings.” No payout has been triggered in any of them.
NEET INTEL@neetintel
"you're a grifter you're grifting you're lying for clicks" brother, this would be the worst grift ever

1:48 AM · Apr 25, 2026 · 2.96K Views
2 Replies · 71 Likes
If I am running a grift, I am running the worst grift in the history of grifts.
A meaningful slice of my audience demands a particular content format. They reward posts that lead with “BREAKING,” red alert emoji, and ALL CAPS. They ignore posts that do not. I have spent the past week or so empirically confirming this by varying the formatting on otherwise comparable posts and watching the engagement curves diverge. The data is unambiguous. The audience tells me, through its actions, that it wants the alert format.
The audience also contains a slice that calls me attention-seeking, sensationalist, and a grifter when I use this.
These two groups overlap more than the second group seems to realize. Many of the same accounts who reward BREAKING posts with engagement also occasionally complain about the broader culture of BREAKING posts. Their complaint is roughly that the algorithm rewards low-quality alarmist content and that serious analysts get drowned out. This complaint is sincere as a stated preference. It is also contradicted by the same person’s actual scrolling behavior, which is what trained the algorithm in the first place1.
NEET INTEL@neetintel
The past week or so of my account has basically been A/B testing the theory that posts need to have "🚨 BREAKING", "🚨 JUST IN", etc. to get sufficient traction with my current follower base. To pre-empt this because this is the exact sort of thing I get in trouble with because
NEET INTEL @neetintel
@CombatKev1n "does anyone want a million dollars?" 2 likes, 1 repost, 100 views "BREAKING: 10 dollars up for grabs" 10,000 likes, 560 reposts, 120,000 views, 57 bookmarks
9:03 PM · Apr 24, 2026 · 5.09K Views
9 Replies · 3 Reposts · 44 Likes
But the BREAKING dynamic is the surface of the audience problem. It is not the deepest part. The deepest part has to do with the framework the audience is using when they evaluate my output, and that framework has a clear upstream source.
The audience does not invent its analytical frameworks from nothing. The audience inherits them. Most of the readers who arrive at my work through a viral post are arriving from somewhere else in the broader open-source intelligence ecosystem, and the framework they are bringing with them is the framework that ecosystem has supplied.
I should be specific about what I mean. There is a wide range of work that gets called OSINT, and some of it is excellent. People who do serious primary-source research, who maintain reproducible methodologies, and who treat their analytical claims as falsifiable. Their work is valuable and it is not what I am critiquing. I am critiquing the much larger population of accounts that use the OSINT label to monetize live-blogging, breaking-news aggregation, and aircraft-tracking commentary. This is the OSINT that most general audiences encounter, and it is the OSINT whose framing has set the audience’s expectations.
That OSINT continues to operate with a binary frame on this front. Exercise or not-exercise. Routine or significant. Boring or BREAKING. The binary is rhetorically convenient because it produces clean engagement-friendly takes. It is also analytically inadequate, because the underlying activity is not binary. Exercises are messages. Operations have exercise components. Routine activity carries non-routine signals. None of this fits the binary.
The corner of SIGINT I work in (HFGCS monitoring, EAM transcription and structural analysis, exercise pattern correlation) requires more sustained effort than the dominant OSINT business model rewards. Years of recordings. Catalog maintenance. Cross-referencing. The willingness to publish forecasts that can be checked, and to be wrong in public when they are. None of this scales the way reposting flightradar24 screenshots scales. As far as I can tell, the dominant OSINT accounts have either not been able to develop this capacity or have not been interested in doing so. I assume the latter, because the effort required is not hidden. The methodology is not secret. The tools are commodity. What is missing is the willingness to do slow work for years before it pays off in any visible way.
A concrete example of the work OSINT could be doing but largely is not. Airspace reservations, particularly NOTAMs and CARF messages, contain meaningful information about scheduled military activity. When a peculiar Emergency Action Message broadcasts during the same window as an unusual airspace reservation over a strategically interesting location, the correlation is worth investigating. None of the inputs to that investigation are privileged. The reservations are public. The EAMs are public. The geographic and temporal correlations are observable to anyone willing to read both feeds. This is exactly the kind of pattern work that would distinguish serious analysis from aggregator commentary, and it is exactly the kind of work the binary exercise/not-exercise frame allows the practitioner to skip. If everything is just an exercise, there is nothing to correlate. The frame excuses the work, which is conveniently aligned with the work being effortful and not scaling.
This is the upstream cause of the audience problem. The audience uses the binary frame because the binary frame is what the loudest OSINT accounts have given them. When I post that a 21 character EAM is rare, that it is associated with previous exercise activity, and that I have published the underlying catalog and the verification trail, the audience tries to fit that claim into the binary. It does not fit. There is no slot in the binary for “rare in a quantifiable sense, associated with a documented prior pattern, observed during a forecast exercise window, possibly meaningful and possibly not, currently a NOTHINGMASTER under the framework I publish.” The audience receives a claim shaped like analysis but processes it through a framework shaped like news. The result, predictably, is that the claim reads either as routine (in which case “why is he posting BREAKING about it”) or as a major event (in which case “he is grifting for engagement”). Neither reading corresponds to what I actually said.
I don’t think this is fully the audience’s fault. They have been handed a framework that does not allow the analytical claim I am making. Inside that framework, my output reads as deceptive. Outside that framework, my output reads as straightforward and well-evidenced. The framework is doing the deceiving. The framework is what the dominant OSINT accounts have supplied. The audience has not been given better tools, because the loudest accounts in this space have not built better tools.
This is also why the grifter accusation lands the way it does. Within the binary frame, my output looks louder than the apparent stakes warrant. I post BREAKING about something the binary frame classifies as routine, so I must be inflating. The frame cannot accommodate the claim that the activity is non-routine in a specifically analytical sense (rare event during a forecast window, structural pattern, geographic context that may matter later) without abandoning the binary. The frame defends itself by classifying me as the problem, instead of itself.
I provide more effort, more receipts, and more evidence than the OSINT baseline most readers are calibrated against. That is not a flex. It is a description of how low the baseline is. When someone offers analysis that exceeds the baseline by an order of magnitude, the reader trained on the baseline does not recognize the analysis as analysis. They recognize it as someone making more noise than the topic warrants, because their calibration is wrong. The calibration is what OSINT failed to teach them.
The conversation will never progress and our collective understanding of these events will never improve as long as the dominant register is “it’s just an exercise, bro.” That phrase is a thought-terminating cliché. It treats analytical work as unnecessary. It assumes the only interesting question is the binary one, real or rehearsal, and refuses to ask the more useful one, which is what the activity is communicating, and to whom.
What the conversation needs is more readers willing to develop the literacy. Track the patterns over time. Notice when something is unusual. Notice when something is routine. Notice when an exercise’s geography matches current geopolitical priorities and when it matches old ones. Notice when message lengths cluster in unexpected places. Notice when callsigns recur. Notice when an exercise is bigger or smaller than it usually is. Notice when activity persists past its expected window or terminates early.
A reader who has done some of this work can ask better questions. They can tell whether a given exercise is at the bellicose end of the normal range or the routine end. They can anticipate how an adversary might read it. They can anticipate how a partner might read it. They can anticipate which audiences are likely to react and which are likely to dismiss it. They can do all of this without confidential access, because the underlying activity is observable and the patterns are stable enough to study.
None of this work generates “BREAKING” posts. None of it goes viral. All of it is necessary if you want to be able to tell a posture statement from a training scenario, a signal from a non-signal, a deliberate provocation from a routine cycle. Without this work, you are downstream of whoever talks loudest about whatever happens to be on screen.
The infrastructure for this work is already built. The catalog is public. The recordings are public. The methodology is documented. The forecasts are public, and they are public specifically so they can be checked. There is no gatekeeping, except the gatekeeping that requires you to do the reading.
I am not under the illusion that this article will produce a sudden epidemic of close attention to HFGCS traffic. Most readers will scroll past. Some will engage. A few will check the verification paths. Fewer still will start tracking the patterns themselves. That is how it has always gone.
What I am not interested in, going forward, is the loudest version of the audience reaction. The grifter accusation is empirically false in the dumbest possible way, as the screenshot demonstrates. The BREAKING criticism is contradicted by the same person’s scrolling behavior. The “just an exercise, bro” frame is a refusal to do the analytical work the topic requires. None of these objections is serious, and none deserves more time than this article has already given.
There is also a question of venue. Twitter is where most of these audience reactions happen, and Twitter is where I have been answering them. It is also where the conversation has so far stagnated, where OSINT accounts have shown no interest in sharing the analytical workload, and where, as the screenshot above demonstrates, the time invested produces no compensation. None of that is the reason I do this work. It is, however, increasingly relevant to where I do it. Substack is more conducive to articles like this one. Whether to do more of this work here is a question I am still working out.
There is a related question of access. Time spent answering audience misreadings is time taken away from higher-order analysis. If the audience is going to consistently misread what is provided to them openly, then some of the higher-order work probably belongs behind a paywall. Previous attempts at softer filtering have not been sufficient. The “dancing kpop girl” aesthetic of the channel and the account, the jpop/kpop invocations across posts and videos, the entirety of the Daily Timecard Project, and so on – these were all meant to function as filters.
I mean, who’s watching this unless they’re either me or one of the all of three other guys I’ve met who also both like the HFGCS and jpop/kpop? Probably someone who actually understands there’s something else at play here.
These antics did produce some self-selection, but weren’t sufficient filters to reach the “nightmare scenario” of an X account with 25,000 followers whose interest in the account sincerely operates from a “🚨CODE RED IT’S HAPPENING” / “lol dw abt it” code switch. A paywall is the next-coarsest filter available, and its function would be filtration more than monetization. Readers willing to pay a nominal amount to read serious analysis are, by selection, the readers more likely to engage with it seriously2. The catalog and the recordings remain public regardless. The question is which kind of analytical writing belongs in which venue.
The catalog is public. The recordings are public. The methodology is documented. The forecasts are public. The receipts are above. The work that has been done is on the record, and the record is already durable enough to outlast my interest in defending it.
In the previous article, I noted that we had reached a point where I no longer feel obliged to prove myself to anyone. That observation feels even sharper today than it did last week, hence we reach these questions – if I keep doing this, do I paywall? If I’m going to get called a grifter, I may as well. etc. etc. etc.
Meanwhile, that nuclear command and control exercise is likely still ongoing.