For over eighty years, the D’Agapeyeff Cipher has stood alongside the Voynich Manuscript and Kryptos as one of cryptography’s great unsolved mysteries. Published in 1939 at the end of Alexander D’Agapeyeff’s introductory book, Codes and Ciphers, the 196-number cryptogram was presented with a modest challenge:

Decades of manual and computational analysis have failed to extract a readable message. When asked for the solution later in life, D’Agapeyeff famously admitted he had “forgotten how he encrypted it”.
Recent investigations suggest that solving the cipher requires viewing it through two distinct lenses: the physical geometry of the numbers on the page, and the computational linguistics hidden beneath them. By combining structural observation with modern cryptanalysis, we are finally unmasking the cipher’s true architecture.
1. The visual artifact: the 14x14 Grid and the 2x7 Pulse
The first step in analyzing a transposition cipher is identifying its dimensions. The 196 symbols of the D’Agapeyeff cipher can be mathematically arranged in several rectangular grids (2x98, 4x49, 7x28, 14x14).
When we format the 196 symbols into a 14x14 square grid, a striking physical artifact emerges. The cipher contains five distinct “anomalous” symbols:
The zero anomaly: 04 (The only symbol starting with a zero).
The singletons: 71 and 94 (They appear exactly once in the entire text).
The rare pairs: 92 and 93 (Appearing only 3 and 2 times, respectively).
If these symbols were part of a continuous, scrambled stream, these rare anomalies should be distributed randomly. Instead, in a 14x14 grid, every single anomaly is perfectly isolated into the 14th column. It is worth noting that the singletons (04, 71, 94) each appear only once in the entire ciphertext, so each is guaranteed to land in exactly one column. The statistically significant observation is that 92 (all 3 occurrences) and 93 (both occurrences) also fall exclusively in this same column.
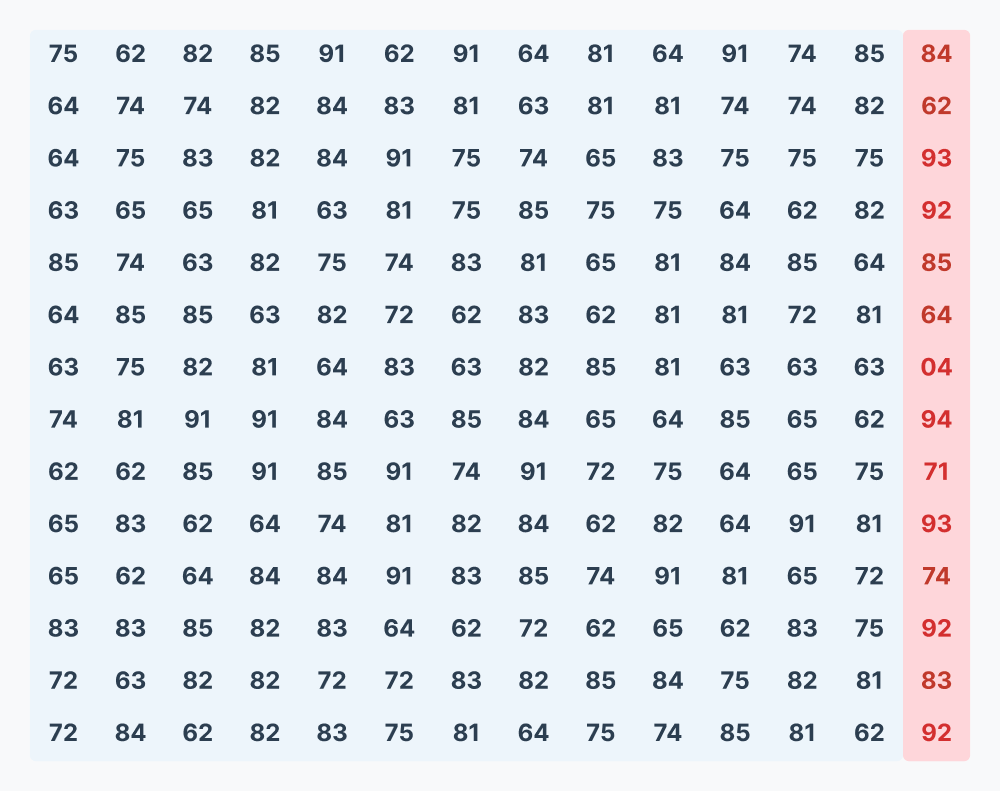
At first glance, this seems like a miraculous alignment unique to the 14x14 square. However, deeper mathematical inspection reveals a simpler, foundational geometry. The isolation occurs in the 14th column because every single one of these anomalies sits at a very specific mathematical interval in the linear text: in 1-based counting, they all occur at positions divisible by both 2 and 7.
Because all 8 occurrences of these anomalies fall at an odd-numbered index (the 2-pulse) AND at the end of a 7-block sequence (the 7-pulse), they are guaranteed to cluster perfectly in the final column of a 14x14 grid.
Rather than contradicting other grid sizes, this actually harmonizes them. The 14x14 grid is the beautiful, geometric culmination of a structural pulse that beats throughout the entire cryptogram.
Furthermore, the famous 04 anomaly lands at exactly row 7, column 14. In a linear string of 196 symbols, this is the 98th pair: the exact boundary between the first and second half of the ciphertext. This midpoint placement acts as a visual hinge, dividing the grid into a top half (7x14) and a bottom half (7x14).
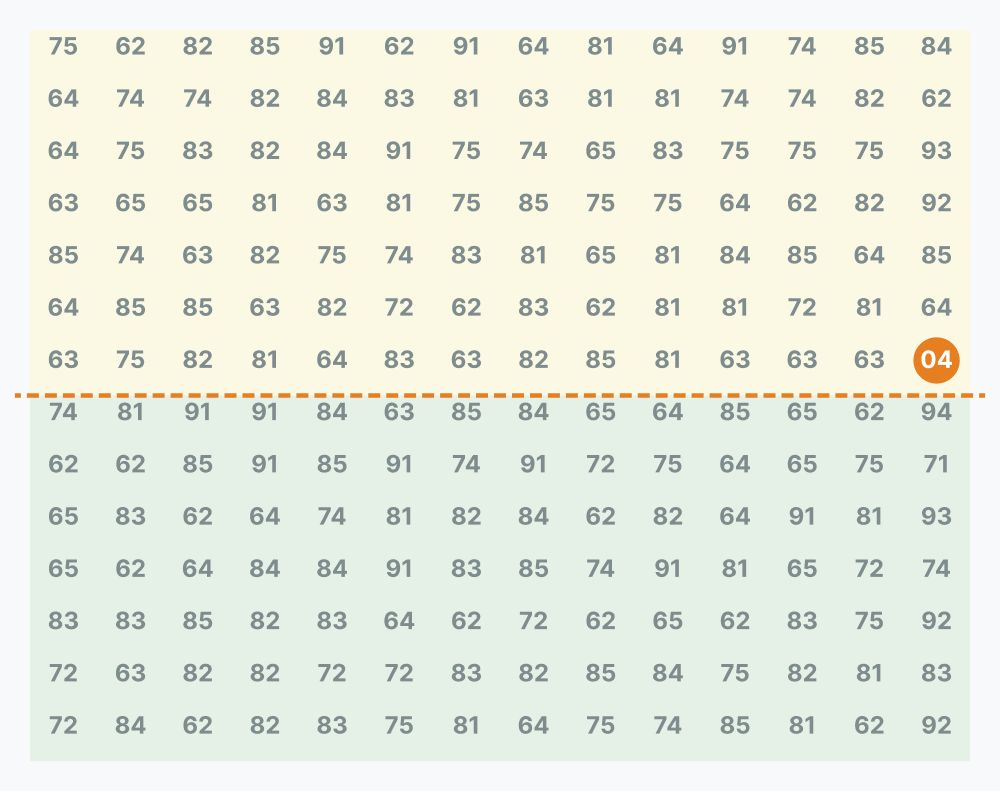
A formatting coincidence or a structural clue?
By isolating the 14th column, we are left with a 14x13 block (182 symbols) and a 14-symbol margin. It is entirely possible this is a typesetting artifact, a result of how D’Agapeyeff originally grouped the numbers into blocks for publication.
However, an interesting, if imperfect, parallel exists. The introductory challenge,“Here is a cryptogram upon which the reader is invited to test his skill”, contains exactly 14 words. If we extract the first letter of each word, we generate a 14-letter sequence that physically maps against the 14 symbols in the anomalous margin.
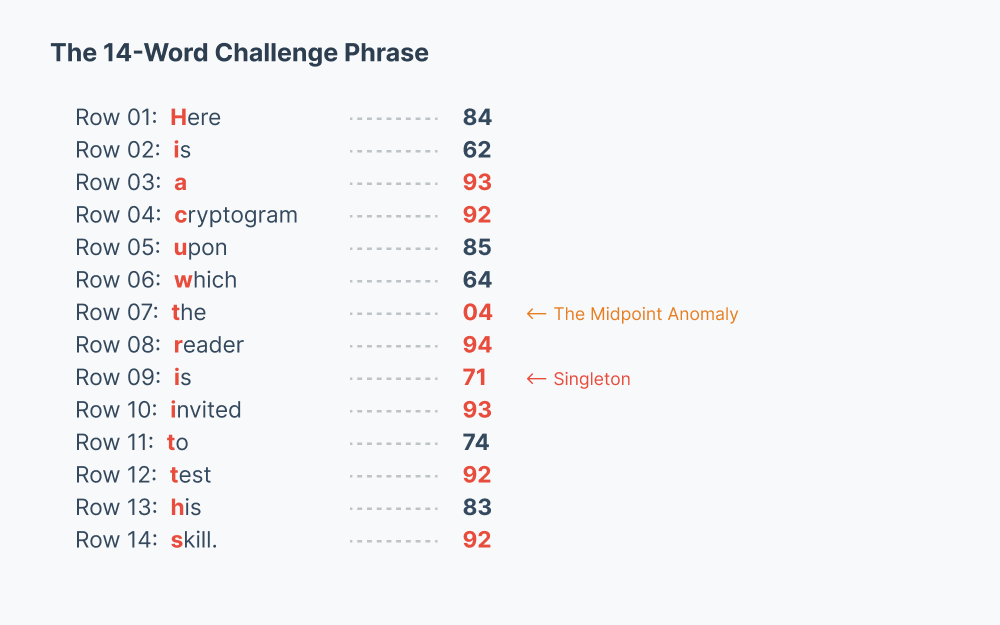
As a cryptographic key, this mapping is highly problematic. For instance, the letter “i” (from the word “is”) maps to the symbol 62 in row 2, but later maps to the singleton 71 in row 9. Whether this is a sloppy polyphonic substitution, a deliberate coordinate key, or simply a remarkable typesetting coincidence of the number 14, the grid provides a compelling structural view of how the cipher may have been drafted or formatted on paper.
2. The computational reality: Esperanto and the 2x98 Grid
While the 14x14 grid reveals fascinating visual clustering driven by a 2x7 geometric pulse, modern computational cryptanalysis points to how this underlying structure dictates the actual plaintext.
For decades, computers have failed to extract a readable English message from the cipher. But what if the underlying language isn’t English? D’Agapeyeff was a Russian-born cartographer writing in the 1930s, a time when the constructed international language Esperanto had a significant following in European cryptographic and intellectual circles.
When subjected to modern Simulated Annealing algorithms using an Esperanto quadgram corpus, the computational landscape shifts dramatically. And crucially, it aligns perfectly with our geometric observations.
Remember the “2-pulse” that drives the anomalies into the margins? When computational solvers analyze the cipher as a 2x98 columnar transposition (combined with a standard Polybius square substitution), it produces fitness scores that far exceed any English baseline.
When 30 independent solver runs with different starting seeds and parameters independently recover the same Esperanto vocabulary (ESTIS, KAJ, KIEL, TRADUK, KODO, KONTRAU, LANDO) at converging scores approaching natural-language baselines, we can be confident this is not a hallucination or overfitting. Overfitting produces different gibberish each time. The 2x98 Esperanto model produces consistent, reproducible linguistic structure.
The anomalies clustering on the “2-pulse” is not contradictory to the 2x98 computational grid; it is the physical symptom of it. The structural geometry and the computational linguistics are finally pointing in the exact same direction.
The same 2x98 model also lets us separate the published cipher into even-index pairs and odd-index pairs, revealing the pair inventory of the two source rows without yet solving the unknown column order.
3. Conclusion
The D’Agapeyeff Cipher is not just a mathematical algorithm; it is a multi-layered architectural puzzle.
Previous attempts have failed because they relied on a single methodology. If we only look at the physical geometry (the 14x14 grid), we find beautiful visual anomalies and formatting clues, but no readable text. If we only look at unconstrained math, we miss the structural artifacts left by the human who drafted it.
By combining these findings, the undeniable visual clustering driven by factors of 2 and 7, and the high-scoring computational reality of a 2x98 Esperanto transposition, we have a much richer understanding of the cipher. We now know that the cipher’s publication format hides deep structural alignments, and its core plaintext relies on a non-English language wrapped perfectly within that geometric pulse.
The D’Agapeyeff Cipher remains unbroken. But by bridging the gap between a map-maker’s geometric layout and modern computational cryptanalysis, we are finally closing in on the solution.
Addendum I (March 15): Mathematical proof of columnar isolation
The assertion that the anomalous symbols are guaranteed to cluster perfectly in the final column of a 14x14 grid due to a shared 2-pulse and 7-pulse can be formalized using the Chinese Remainder Theorem.
If we treat the 196-symbol cryptogram using 0-based indexing (i = 0, 1, 2, …, 195), the 14th column of a 14-width grid corresponds to all indices where i ≡ 13 (mod 14).
The structural observations for the anomalous symbols are:
The 2-Pulse: They occur at odd-numbered indices, meaning i ≡ 1 (mod 2).
The 7-Pulse: They occur at the exact end of a 7-block sequence, meaning i ≡ 6 (mod 7).
Since 2 and 7 are coprime (their greatest common divisor is 1), this system of congruences has a unique solution modulo their product (2 x 7 = 14).
We can elegantly rewrite the congruences symmetrically:
i ≡ -1 (mod 2) (since 1 ≡ -1 mod 2)
i ≡ -1 (mod 7) (since 6 ≡ -1 mod 7)
Because i is congruent to -1 for both coprime moduli, it must be congruent to -1 modulo their product:
i ≡ -1 (mod 14)
Which simplifies to i ≡ 13 (mod 14). In a 0-based 14-column grid (columns 0 through 13), any index satisfying i (mod 14) = 13 mathematically must fall into the 14th column.
Furthermore, without this underlying structural constraint, the mathematical probability of all 8 anomalous symbols randomly falling into the same column of a 14-width grid is practically zero. There are roughly 4.67 x 10^13 ways to place 8 items in the grid, but only 42,042 ways for them to share a single column (14 possible columns x 3,003 ways to place 8 items in 14 spots). The probability is 42,042 / 46,738,198,126,898, which is approximately 8.99 x 10^-10 (roughly 1 in 1.11 billion).
Rather than proving the author deliberately placed these symbols in the 14th column for visual effect, this mathematical reality demonstrates the opposite: the stunning visual isolation is an emergent geometric property. The clustering is not a statistical miracle of random placement, but an unavoidable mathematical consequence of the cipher’s underlying 2-pulse and 7-pulse structure.
Addendum II (March 15): The 17-letter alphabet as a search filter
A frequency analysis of the 196 symbol pairs reveals that only 17 of the 25 possible Polybius square cells are occupied. The plaintext alphabet contains exactly 17 distinct letters:
A, D, E, G, I, J, K, L, M, N, O, P, R, S, T, U, V
Four letters that are common in most European languages are entirely absent: B, C, F, and H. In standard Esperanto text, each of these letters appears with a frequency of 1-3%, making their simultaneous absence from a 196-character passage statistically unusual.
Every Esperanto word independently recovered by simulated annealing solvers across dozens of runs on different hardware (including TRADUK, KODO, LINGVO, MONDO, LANDO, KONTRAU, ESTIS, KAJ, KIEL, TIEL, KIAM, ANKAU, ANTAU, NOMO, and DONI) uses only letters from this 17-letter set, providing independent confirmation of both the substitution mapping and the language identification.
This constraint transforms the source text search from an open-ended literary question into a scriptable corpus query. And because the 2x98 model separates the published pairs into two source rows, that query can be sharpened further still. The search specification is:
Find candidate plaintexts of roughly 196 characters, or two linked 98-character halves.
Require the full text to respect the 17-letter set listed above (no B, C, F, or H).
Prefer texts containing several of the recovered vocabulary items (KODO, TRADUK, LINGVO, MONDO, LANDO, KAJ, KIEL, ESTIS).
Addendum III (March 15): What the even/odd row separation shows
The 14x14 grid and the 2x98 model describe the same 196 published pairs in two different ways. In the 2x98 reading, even-index pairs come from one source row and odd-index pairs come from the other. Separating the published cipher by parity therefore does not recover the unknown column order, but it does recover the pair inventory of each source row independently of that order.
Under this separation, source row 0 contains only 13 distinct published pair types, while source row 1 contains all 18 distinct published pair types, including every anomaly. The count is 18 here because the published text includes the printed outlier 04, even though the underlying Polybius model uses only 17 occupied cells.
Any source-text filter can therefore be sharpened further. Instead of treating the cipher as one undifferentiated 196-pair stream, we should treat the two source rows separately and ask whether the first and second 98-character halves exhibit different pair inventories and, under the current Polybius reading, different alphabetic constraints.

Addendum IV (March 19): Independent corroboration and divergence
Tim Marland, an independent researcher based in Lincoln, UK, has published a systematic pipeline analysis of the D’Agapeyeff cipher at dagapeyeffresearch.com. The two investigations (mine and his) were conducted independently and share no code, data, or communication. A brief comparison of findings:
Shared independently by both investigations: Polybius encoding structure confirmed. 14x14 grid is structurally significant. Period of 7 detected (Marland via chi-squared, this work via the 2x7 pulse and CRT proof). Three missing Polybius cells / 17-letter alphabet. The 04 pair is anomalous. No coherent English plaintext has been recovered by either investigation.
Found by Marland but not in this work: Nick Pelling’s 2017 Kerckhoffs reversal (encryption and decryption steps swapped in D’Agapeyeff’s book). George Lasry’s formal elimination of simple substitution + transposition. ADFGX fractionation ruled out as structurally incompatible. Systematic English pipeline of 290+ configurations.
Found in this work but not by Marland: The CRT proof formalizing column-14 clustering as an emergent geometric property (Addendum I). The 17-letter alphabet as a search filter (Addendum II). The even/odd row separation revealing 13 vs 18 distinct pair types, with row 0 containing zero G, M, P, or V, constraining the first half of the plaintext to a 13-letter alphabet (Addendum III). The 2x98 columnar transposition model with Esperanto quadgram scoring.
The critical divergence is plaintext language. Marland’s English-only pipeline produced no coherent text after 18+ hours of compute, leading him to a 10-15% solvability estimate. Our Esperanto-scored simulated annealing on the 2x98 model produces consistent vocabulary recovery (TRADUK, KODO, LINGVO, MONDO, LANDO, KAJ, KIEL, ESTIS) at fitness scores no English model has approached in either investigation. Whether the Kerckhoffs reversal applies to the Esperanto model is currently under test.
To be continued!