A short visual overview of how SkillOpt treats natural-language skills
as trainable artifacts: roll out, reflect, edit, validate, and export.
Promotional video for the SkillOpt project page. The static paper teaser is shown below for high-resolution inspection.
Paper Teaser
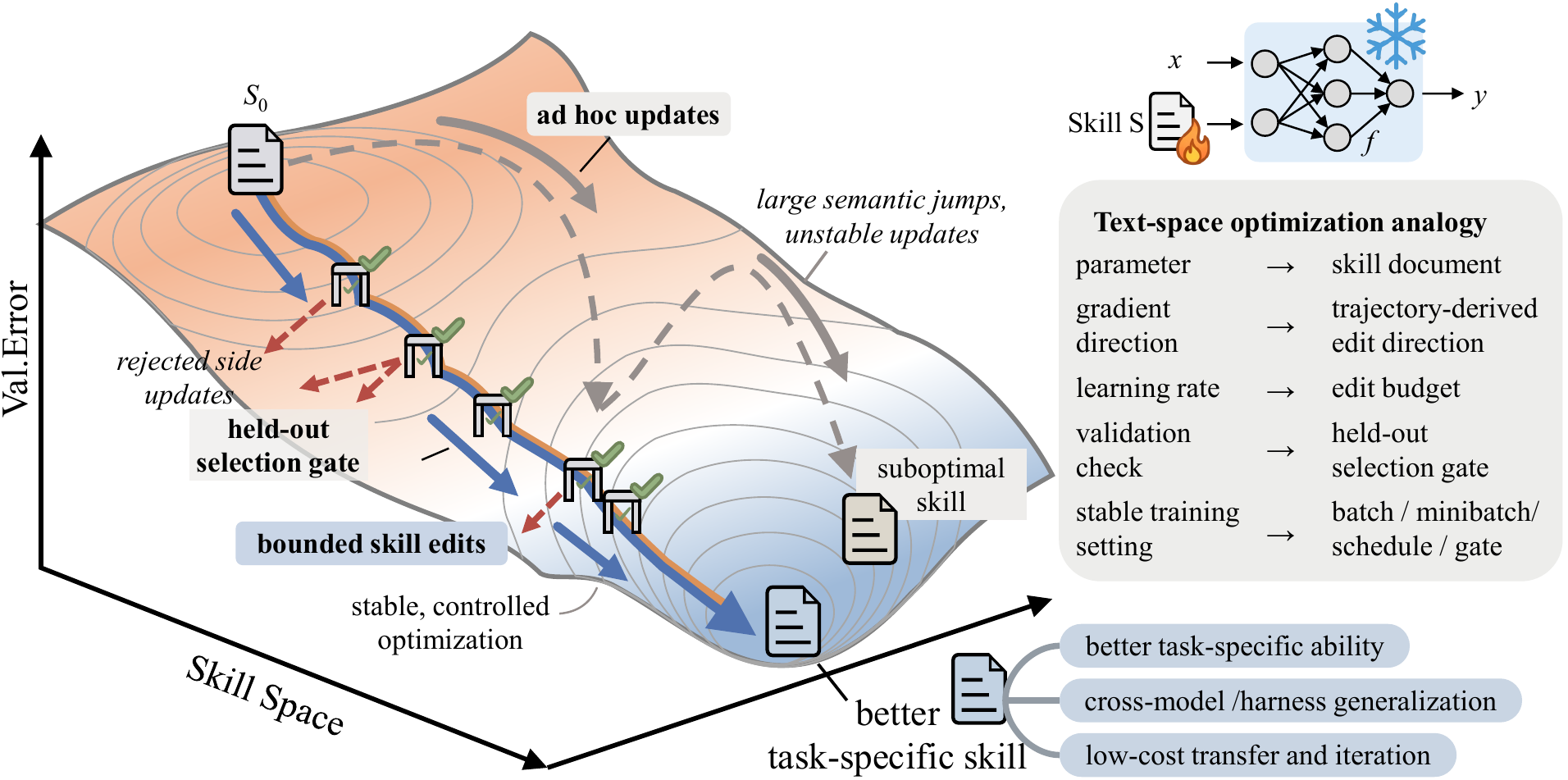
The core loop at a glance.
The teaser summarizes the SkillOpt training loop: rollout evidence,
optimizer-side reflection, bounded skill edits, validation gating,
and the exported reusable skill.
Figure from the SkillOpt paper. On small screens, the figure area scrolls horizontally to preserve the original details.
A skill is external state for an agent.
Instead of fine-tuning a model or hand-maintaining prompts, SkillOpt runs
the frozen agent on scored batches, asks a separate optimizer model to
propose structured edits, and accepts a candidate only when validation
performance improves.
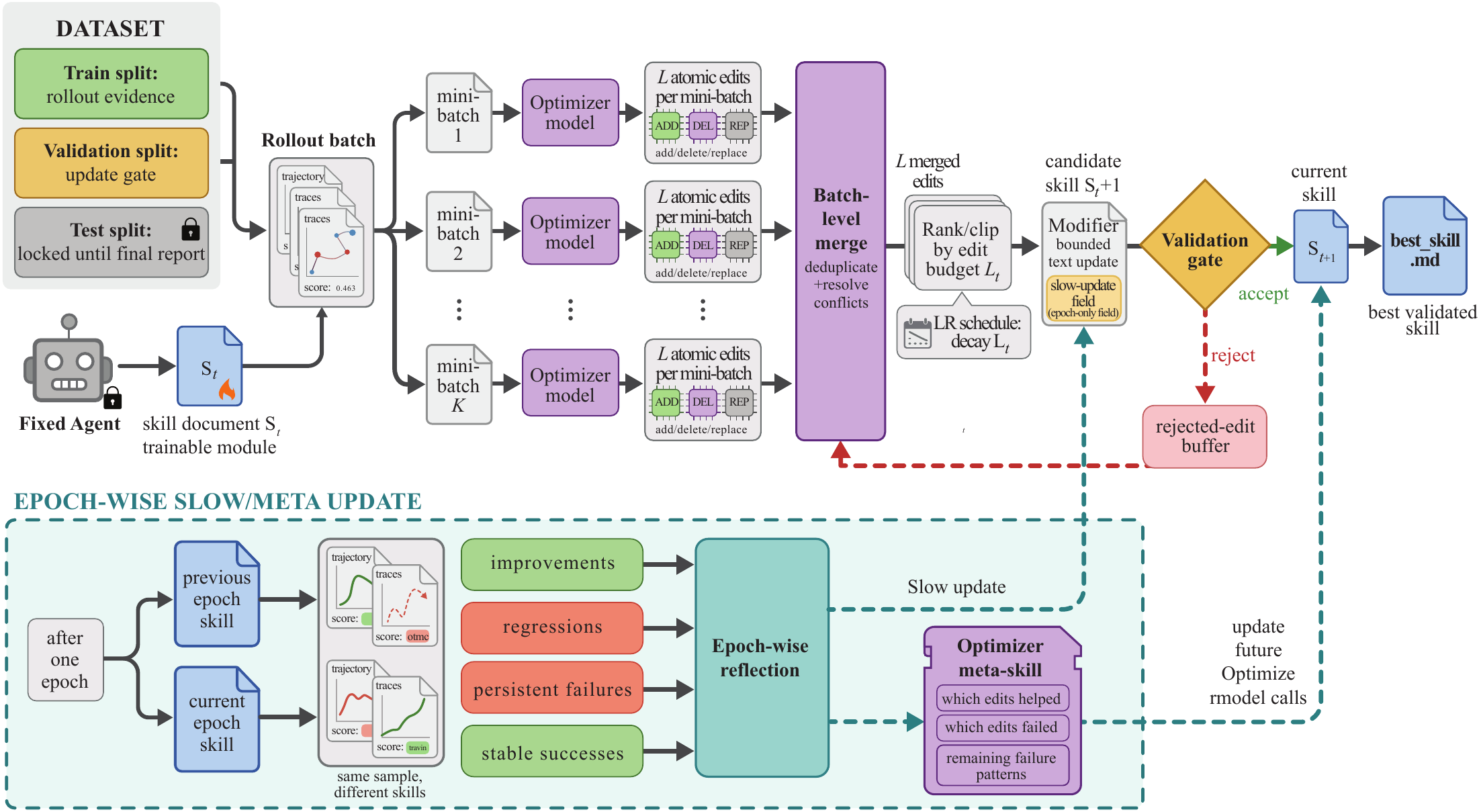
The target model executes tasks with the current skill and records scored trajectories.
Reflect
The optimizer analyzes success and failure minibatches to find reusable procedures.
Edit
Candidate add, delete, and replace operations are merged and ranked under a budget.
Gate
The candidate skill is kept only if it improves held-out selection performance.
Evidence
Rollout batches capture messages, tool calls, verifier feedback, task metadata, and final scores.
Minibatches
Failures and successes are reflected separately so edits correct recurring errors while preserving working behavior.
Bounded Edits
An edit budget functions as a textual learning rate, preventing useful rules from being overwritten by broad rewrites.
Memory
Rejected edits, slow update, and optimizer-side meta skill provide longer-horizon feedback without bloating deployment.
SkillOpt pipeline from the paper. The frozen target model executes with the current skill; the optimizer model proposes bounded edits; held-out validation decides whether the candidate becomes the new current skill.
Method comparison
SkillOpt clears the strongest baseline on every benchmark.
Component
Setting
SearchQA
Spreadsheet
LiveMath
Learning rate
lr=4 default
87.1
77.5
61.3
Learning rate
without lr
84.6
75.7
57.3
Rejected buffer
with buffer
87.1
77.5
61.3
Rejected buffer
without buffer
85.5
72.9
58.9
Update memory
meta skill + slow update
87.1
77.5
61.3
Update memory
without both
86.3
55.0
59.7
What the ablations say
BoundedTextual learning rates prevent destructive rewrites while keeping enough plasticity to learn new procedures.
GatedHeld-out selection turns reflection into propose-and-test optimization rather than unconditional self-editing.
BufferedRejected edits become negative feedback, helping the optimizer avoid repeating harmful directions.
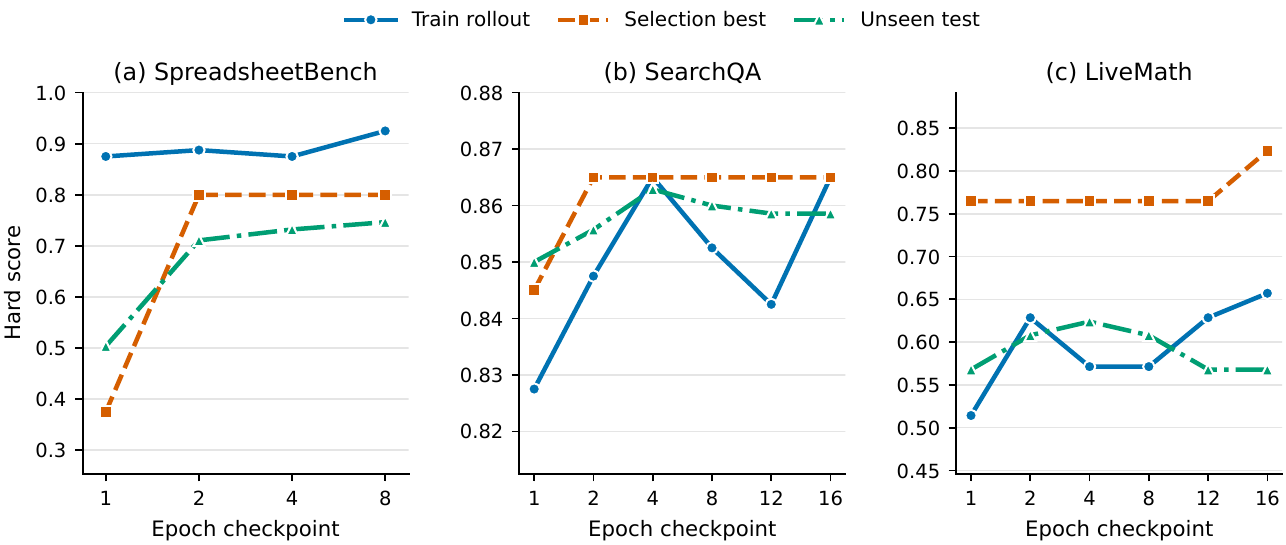
Epoch checkpoint trends from the paper. Selection-best checkpoints are compared with train rollout score and unseen test performance.
Accepted edits become the current skill only after held-out selection improves.Step 3 is rescued by a slow update; Step 4 trains higher but fails selection.
Cross-model+15.2
GPT-5.4 LiveMath skill transferred to GPT-5.4-nano on LiveMathBench.
Cross-harness+31.8
Codex-trained SpreadsheetBench skill transferred into Claude Code.
Self-optimizer+10.4
GPT-5.4-nano used as its own optimizer improved SpreadsheetBench over baseline.
Deployment1 file
The target model consumes only the final skill, not optimizer memory.
A stronger optimizer model gives the largest gains, but the loop is not merely
distillation from a stronger model. Even matched target-as-optimizer settings
can discover useful edits when the update is constrained, buffered, and
validated.
@misc{yang2026skilloptexecutivestrategyselfevolving,
title={SkillOpt: Executive Strategy for Self-Evolving Agent Skills},
author={Yifan Yang and Ziyang Gong and Weiquan Huang and Qihao Yang and Ziwei Zhou and Zisu Huang and Yan Li and Xuemei Gao and Qi Dai and Bei Liu and Kai Qiu and Yuqing Yang and Dongdong Chen and Xue Yang and Chong Luo},
year={2026},
eprint={2605.23904},
archivePrefix={arXiv},
primaryClass={cs.AI},
url={https://arxiv.org/abs/2605.23904},
}