The AI infrastructure buildout is $400B annually. Revenue across all AI companies is maybe $20B. Either we’re in a historic bubble, or we’re funding something we can’t yet articulate.
I think it’s the second. But not for the reasons most people cite.
I don’t have board seats at the labs or access to their internal roadmaps. What I do have is six months of running dual-source experiments in production, conversations with infrastructure teams at three fintechs and two enterprise SaaS companies, and a front-row seat to how the consensus narrative diverges from what practitioners actually ship. That’s the lens here.
The consensus view: models will commoditize, value will shift to applications. Every VC newsletter in my inbox makes this argument. And yet, those same VCs keep funding orchestration middleware, model routers, and evaluation platforms. LangChain just raised $125M at a $1.25B valuation in October 2025; Cursor hit $29B after five funding rounds in 18 months. Companies in the layer that, by their own thesis, should get squeezed.
The contradiction reveals something. Either the consensus is wrong, or the consensus believers don’t believe their own consensus. The barbell thesis is correct, but most misunderstand which barbells matter.
The AI economy operates in three distinct layers:

But the value doesn’t distribute evenly, it’s concentrated at the extremes.
“The AI stack is hardening. Economic power shifts to those who own the rails OR own the interface. Everything else gets squeezed.” — Lo Toney, Plexo Capital
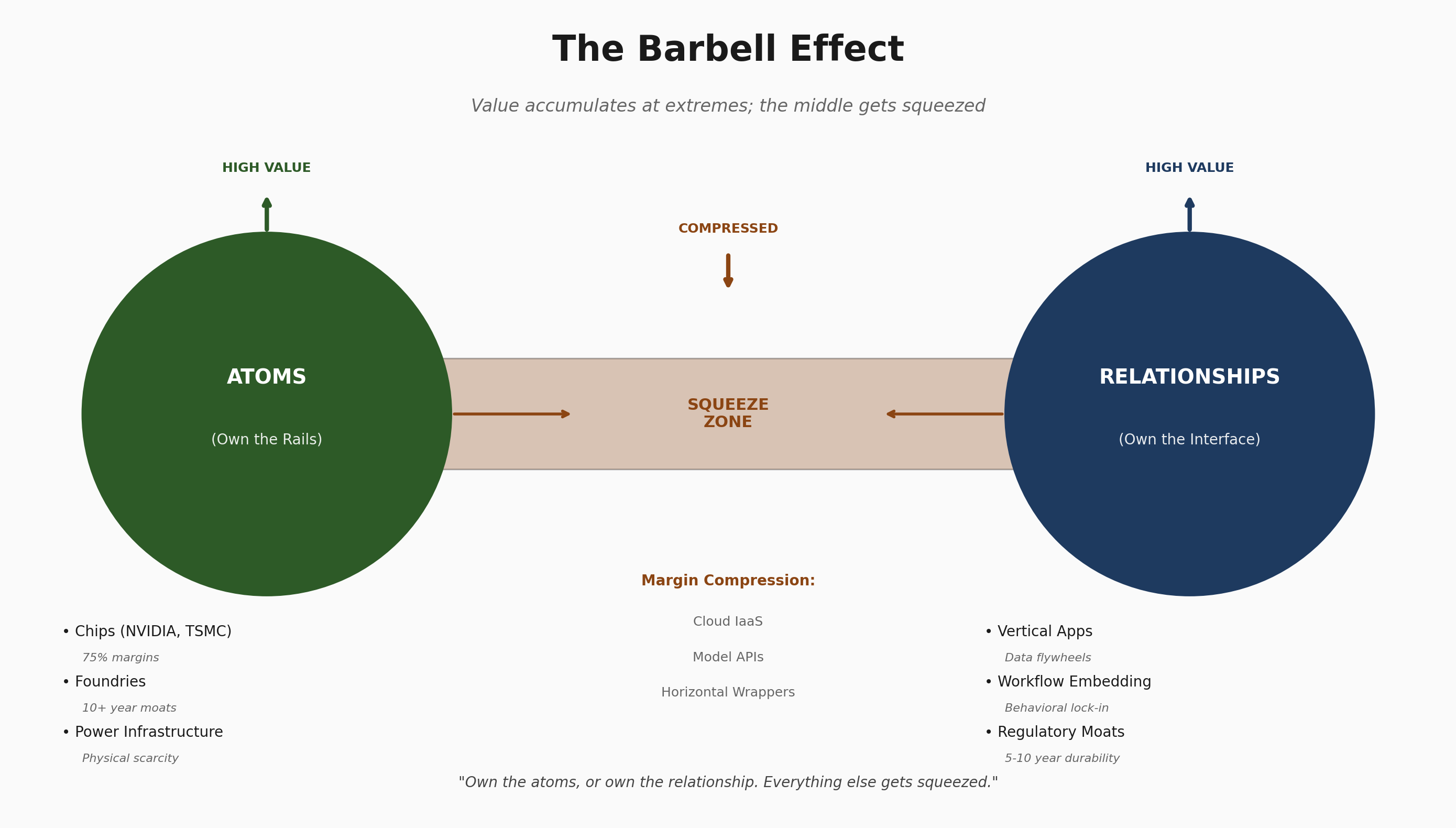
The barbell effect: Value accumulates at two poles:
Atoms (chips, power, silicon, physical infrastructure)
Relationships (user habits, workflow embedding, behavioral defaults)
The middle layers face margin compression from both directions. Cloud becomes a utility. Model APIs become commodities. The squeeze is structural.
Chip makers (NVIDIA, TSMC) maintain 73% gross margins through manufacturing complexity and ecosystem lock-in.
The January 2025 reality check: When DeepSeek released V3 on December 26, 2024, claiming $5.5M training cost using export-restricted H800s, NVIDIA shed $600B in market cap in a single day (the largest single-day loss in U.S. stock market history). The market briefly questioned whether the “expensive compute” thesis still held. A week later, NVIDIA recovered half those losses. The consensus recalibrated: cheap training doesn’t mean cheap inference at scale; the atoms still matter, but the margin story got more complicated.
Hyperscalers face erosion: a friend running ML at a large fintech told me they’re “actively planning our exit from single-cloud.” The Gartner data backs this up: 92% of large enterprises now run multi-cloud, up from 76% in 2022. Training stays sticky; inference commoditizes. Neoclouds chip away at the edges.
Defensible: Chips, foundries (5-10 year moats)
Eroding: Cloud IaaS (multi-cloud tooling, model convergence)
Orchestration is the emerging battleground, but margins get compressed from above (cloud bundling) and below (open source).
I’ve been running dual-source experiments for six months: the switching cost isn’t accuracy, it’s the 200 hours your team spent tuning prompts for one model’s specific quirks. The GPT-4 → GPT-5 transition in late 2025 broke half our production prompts; teams that had built model-agnostic abstractions recovered in days, single-model shops took weeks. Post-Llama 3.3 (December 2024) and post-Claude 3.5 Sonnet (June 2024), the capability gap narrowed enough that multi-model became viable. By Q4 2025, most teams I talk to run at least two frontier models in production.
The vector database correction: In 2023, dedicated vector DBs (Pinecone, Weaviate, Qdrant) looked like essential infrastructure. By late 2025, the story shifted. Pinecone lost Notion as a customer; pgvector and native Postgres extensions absorbed the simple use cases. The VentureBeat postmortem called it “the classic hype cycle followed by introspection and maturation.” Vector search became a checkbox feature in cloud platforms, not a standalone moat. Most teams I talk to run pgvector unless they’re past 50M vectors.
Emerging: Orchestration platforms, evaluation infrastructure
At risk: Standalone vector DBs (getting absorbed), single-model dependencies
Vertical specialists with data flywheels (Harvey’s legal precedent, medical AI’s diagnostic patterns) and regulatory moats build durable value.
The Harvey trajectory tells the story: $1.5B valuation in July 2024 → $3B in February 2025 → $5B in June 2025 → $8B in December 2025. Four funding rounds in 18 months, now serving majority of top 10 U.S. law firms. That’s what vertical embedding looks like when it works.
Horizontal wrappers face platform absorption: Cursor vs. Claude Code, Grammarly vs. Office Editor. A product lead at a leading coding assistant told me bluntly: “We’re not competing on capability anymore; we’re competing on addiction.”
The Cursor paradox: $400M valuation in August 2024 → $2.6B in December 2024 → $9.9B in April 2025 → $29.3B in November 2025. Fastest B2B scaling in SaaS history, $1B ARR in 24 months. And yet: Claude Code ships, Copilot improves, the labs keep getting better at appliances. Is Cursor building a defensible relationship layer, or riding a temporary capability gap? I genuinely don’t know. That uncertainty is the point.
Defensible: Vertical apps with workflow embedding (5-10 year moats)
At risk: Horizontal tools, “better prompt” plays
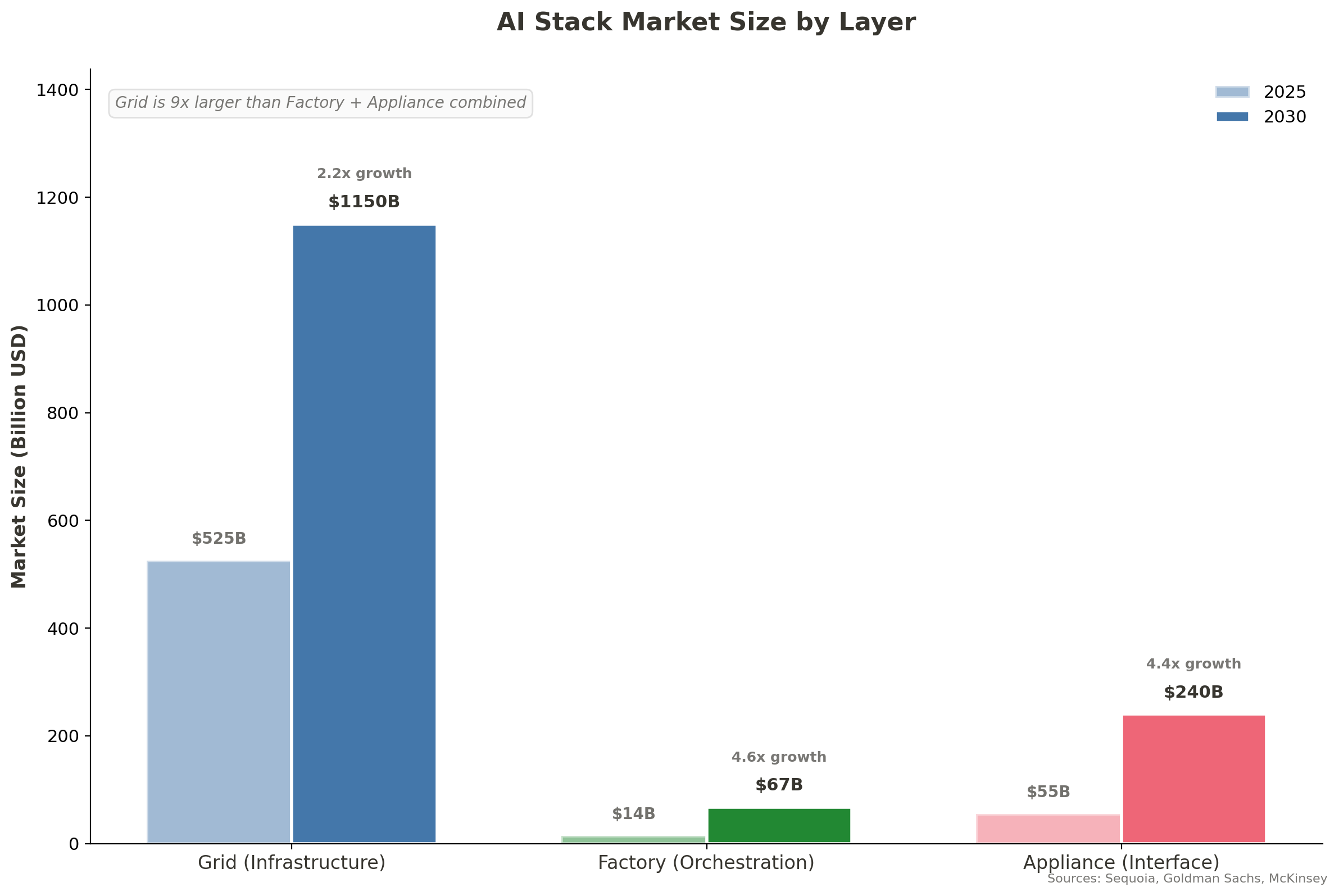
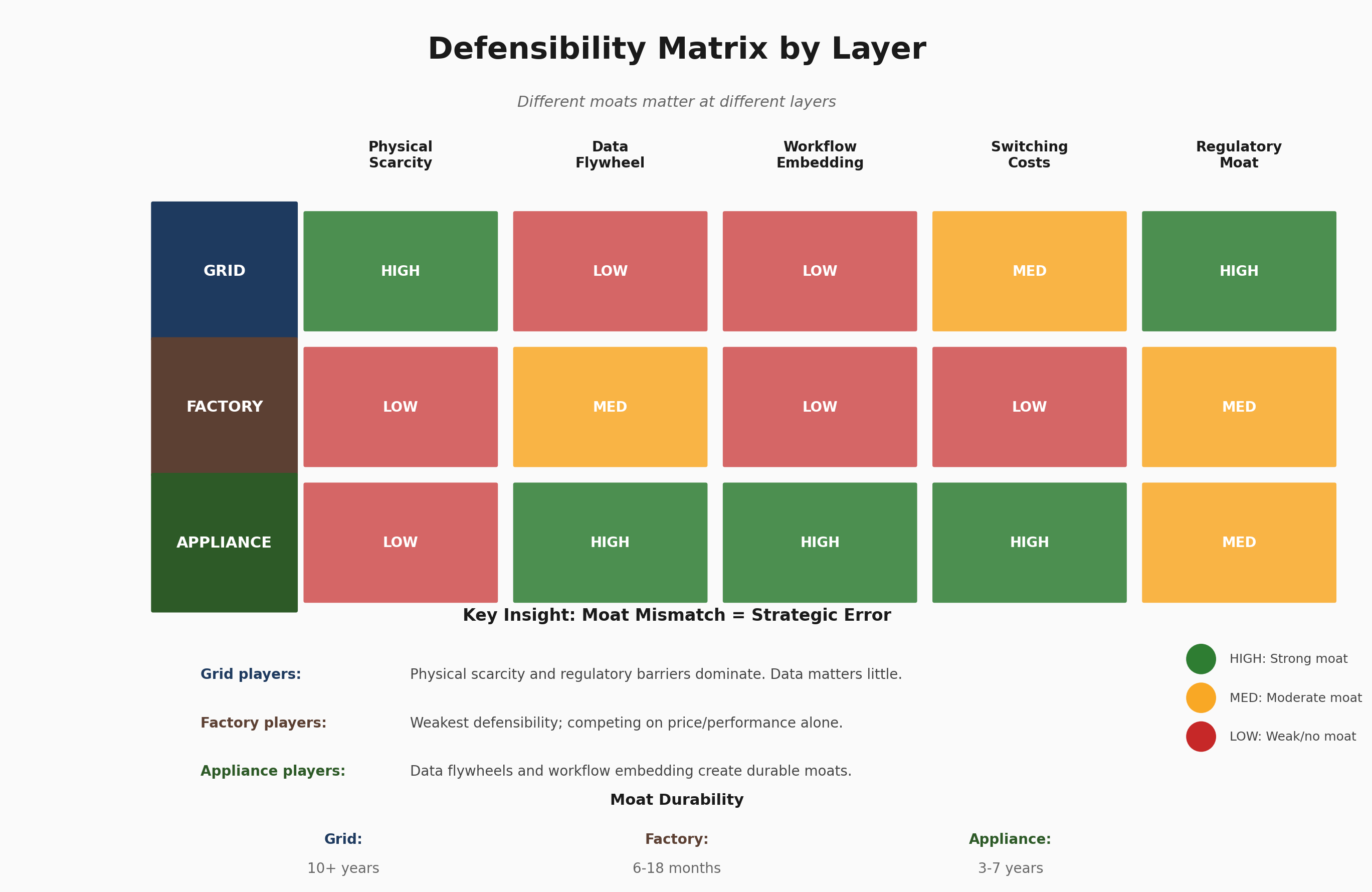
Forecast: Durable rents accrue to Atoms (chips) and Relationships (vertical apps). Cloud and model APIs face highest commoditization. Orchestration is the wildcard.
In 1900, electricity was astonishing. By 1950, it was invisible. The fortunes went to GE (appliances), Westinghouse (factories), and the utilities that became regulated monopolies with compressed margins.
In 2024, AI is astonishing. By 2035, it will be invisible. The fortunes will go to chip makers who control atoms, vertical appliances that become behavioral defaults, and orchestration platforms that become the enterprise control plane.
But here’s what keeps me uncertain: the labs are playing all three layers simultaneously. OpenAI, Anthropic, Google aren’t subject to the barbell squeeze because they own the whole stack. And they’re getting better at appliances faster than startups are getting better at factories.
The market may not bifurcate cleanly into atoms vs. relationships. It may consolidate around 3-4 vertically integrated giants, with everyone else fighting over scraps.
🤔 The tension I can’t resolve: If the barbell thesis is right, why are the barbell ends (chip makers and vertical apps) still lagging the giants in market cap growth? Partial answer: The giants aren’t subject to the barbell squeeze because they’re playing all three layers simultaneously. OpenAI’s $5B API forecast cut reveals the mechanism: their appliances are cannibalizing their own infrastructure revenue. The barbell is lopsided because one end is eating the other.
What changed my thinking: The pre-2024 consensus assumed inference costs would stay high, making compute-heavy operations a durable moat. DeepSeek V3’s efficiency claims and the subsequent NVIDIA correction suggest the inference cost curve is steeper than expected. The atoms still matter, but the which atoms question is more open than it was a year ago.
The barbell thesis is correct, but the weights aren’t balanced. Infrastructure is eating everything above it.
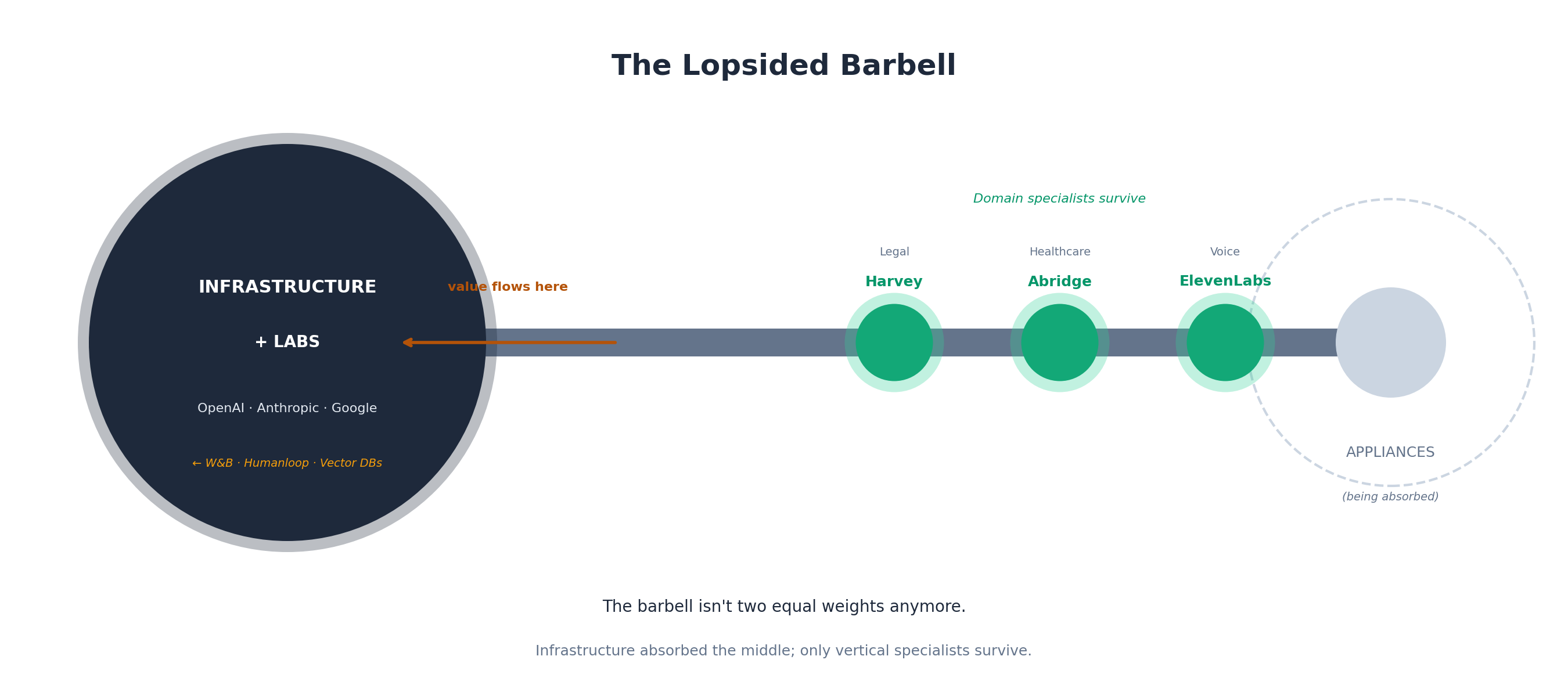
The API cannibalization problem: OpenAI cut its API revenue forecast by $5 billion over five years. ChatGPT Pro ($200/month) is losing money due to “higher than expected usage.” The pattern is clear: appliance success eats infrastructure revenue. Labs are competing with their own API customers. This isn’t an aberration - it’s the strategy now.

Anthropic builds Claude Code ($500M ARR in late 2025, 10x growth in three months) and competes directly with Cursor. OpenAI builds Canvas and competes with every Artifacts wrapper. Google embeds Gemini everywhere and competes with its own Vertex AI customers.
The middle layer absorption:
Company Fate Acquirer Signal Weights & Biases Acquired ($1.7B) CoreWeave Infrastructure absorbs factory Humanloop Acqui-hired Anthropic Labs absorb factory Pinecone CEO change (Sept 2025) TBD Struggling LangChain Independent N/A $16M revenue on $1.25B valuation (78x)
The Factory layer is bifurcating. Winners embed themselves as data platforms with gravity (Databricks at $62B, Observe with 180% NRR). Losers remain point solutions waiting to be absorbed or commoditized (vector DBs becoming pgvector features, single-purpose observability tools).
What survives the squeeze:
Embedded platforms with data gravity (Databricks model): Once your data lives there, switching costs compound
Vertical specialists with domain moats (Harvey, Cursor): Behavioral lock-in trumps infrastructure ownership
Infrastructure suppliers (NVIDIA, TSMC): The only ones with real pricing power
The consolidation trajectory: By 2028, the market consolidates around 3-4 vertically integrated giants (OpenAI, Anthropic, Google, possibly xAI), with everyone else fighting for scraps in the surviving niches.
The barbell isn’t two weights on opposite ends anymore. It’s one giant weight (infrastructure) with a long thin bar that occasionally bulges where domain specialists survive.