Prediction Markets
A simple Python bot, a local laptop, real money, and a market that was inefficient just long enough to be interesting.
Repos: kalshi-analysis and kalshi-strategy-executor.
Here is my PnL chart for my incredibly simple prediction-market bot that ran 24/7 for a couple months on my local laptop. Roughly +$6k real money, not theory-trading. I did not actually ever intend on releasing these repos, but I got interested in a different project, clankerfights.ai, so forgive the disorganized mess: kalshi-strategy-executor and kalshi-analysis.

I kept seeing X posts like this one:
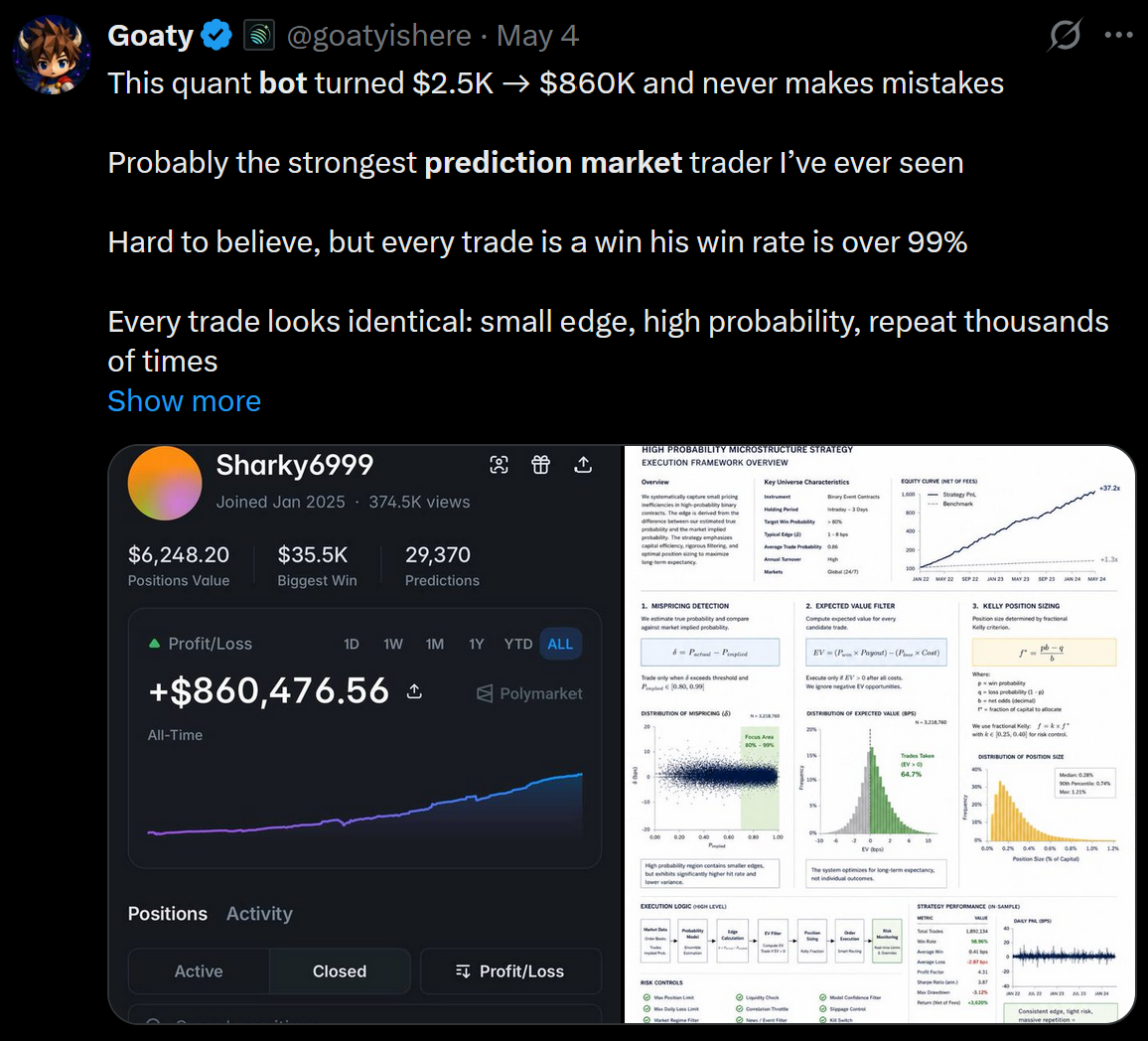
Given my background beating Vegas for multiple years with MMA-AI.net based on data analysis, I figured I would take a week off work and see what came out the other side.
Why I Care About Prediction Markets
Being able to predict the future is my absolute north star of useful intelligence measurements. Not IQ, not academic credentials, not net worth. Predicting the future. If you hold a certain world view, then you can accurately test it by making predictions and revising your world view as the predictions return. Fundamental truth lies in prediction. Too many people hold belief systems based on what makes them feel good and not enough on what is actually predictive, because they never test their belief system with predictions and learn from the results.
Given this, you can probably guess I love prediction markets. They are the most frictionless way of making a prediction with some skin in the game so it actually hurts when you are wrong. Prediction markets =/= gambling. Think about traditional markets like stocks. Every decision can be simplified to "Will it rain tomorrow?" Price predicted to go up: buy. Price predicted to go down: sell.
Personally, I consider gambling to be a market where you enter and the other side has a statistically inherent advantage over which you have no recompense. Roulette: gambling. Roulette where you know there is a bias on the wheel: not gambling. You can gamble on stocks, prediction markets, sports or poker, but that does not mean they are necessarily gambling. Knowledge and skill turn them into investment, not gambling. Semantic, I know, but it irritates me nonetheless when people view prediction markets as just giant casinos. It feels similar to when John McCain called UFC "human cockfighting" and tried to ban it meanwhile boxing, like, existed and had none of the hate.
The LLM Attempt
My initial thought was to focus on mention markets. These are markets where you predict what word a person will say during an event. So an example would be, "What will Trump say during the State of the Union?" and the markets are individual words, each with odds that he will say it. "MAGA" might have an 85% chance to be said, so if you buy 1 Yes contract at $0.85 and he says that word, then Kalshi settles that contract at $1.00. I was like, well shit, LLMs are amazing at word pattern matching, so I will just ask Google Deep Research to do research and automate that.
Well, it turns out they are good at that, but they are worse at coming up with probabilities than they are good at speech pattern recognition. They basically thought every word on the mention markets was higher chance to hit than the market prices implied, and I was losing a little bit of the very small amount of money I was wagering. There is probably still a viable way to make this work, but I figured there was a more consistent path.
The Data Pass
I moved on to more traditional data analysis. Inspired by jbecker's prediction-market microstructure writeup, I figured I would go create my own scraper and database and that would be my competitive advantage.
Pretty easy with Claude Code, but the Kalshi API rate limiting meant it took literally a week before my planned vacation to work on this to acquire all the data. So I let that run, then I basically asked Claude Code to write scripts to analyze the data with increasing specificity.
First, analyze Kalshi markets as a whole and determine calibration. That is, how often does the market favorite win? If they win 70% of the time and the average odds on the market favorite was 65%, then you just found a 5% free-money edge. My data found the same thing as jbecker: on average, the markets were extremely well calibrated. Within about 1-2% when taken as a whole. So now we get more specific.
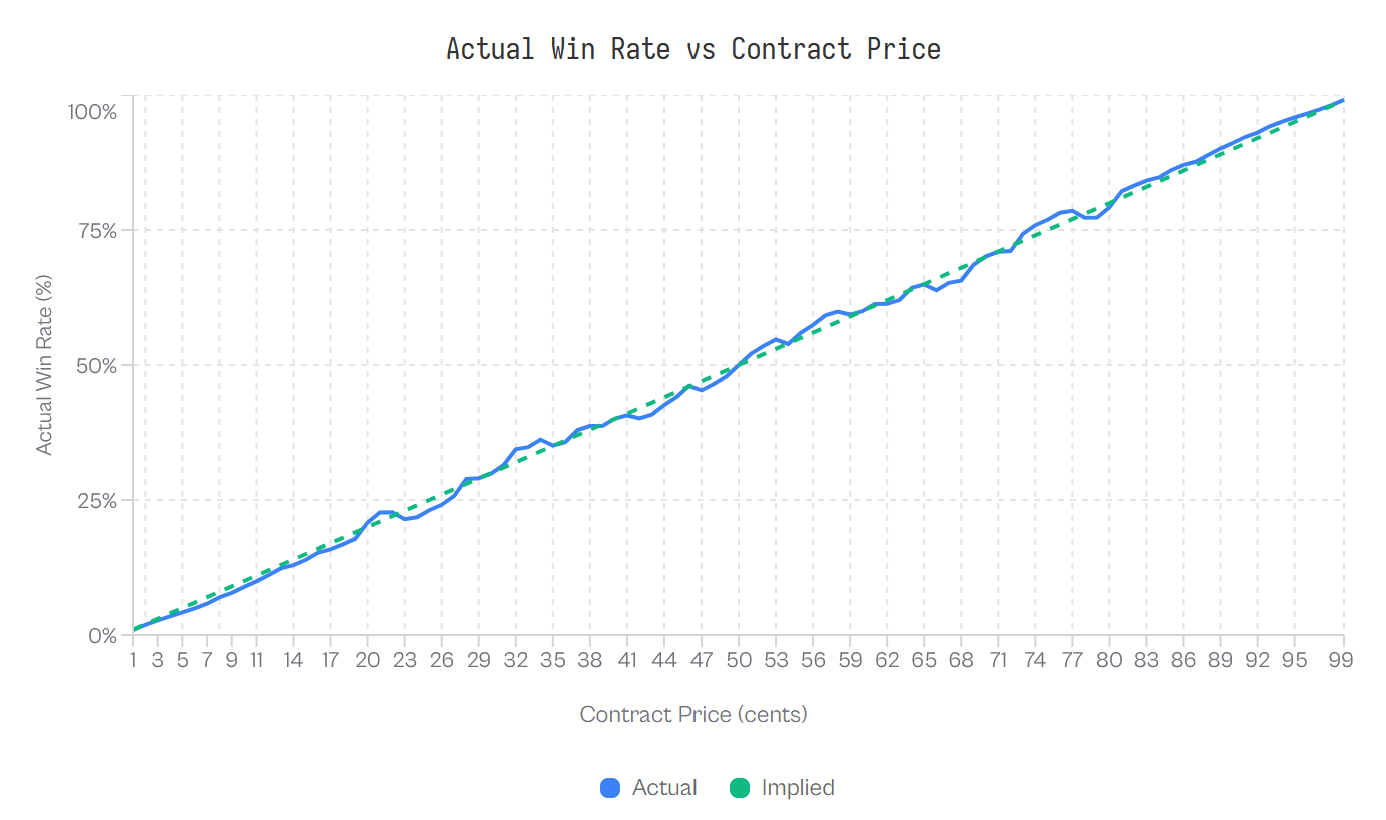
Drill down to each market type: climate, politics, sports, mentions, crypto, etc. Now we were getting somewhere. Mention markets started standing out big time.
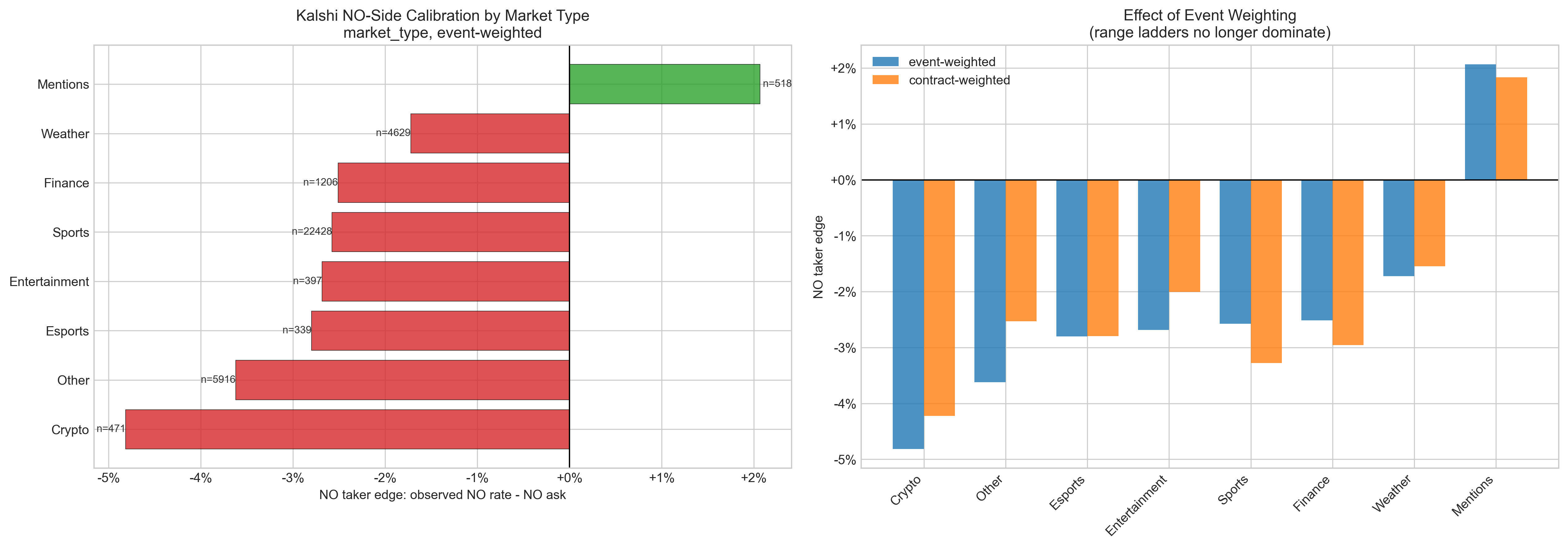
OK, so we acquired a target, but how do we take advantage? Let's drill it down to the calibration of the Yes/No contracts. Great, and just like that we can tell the No side is consistently underpriced.
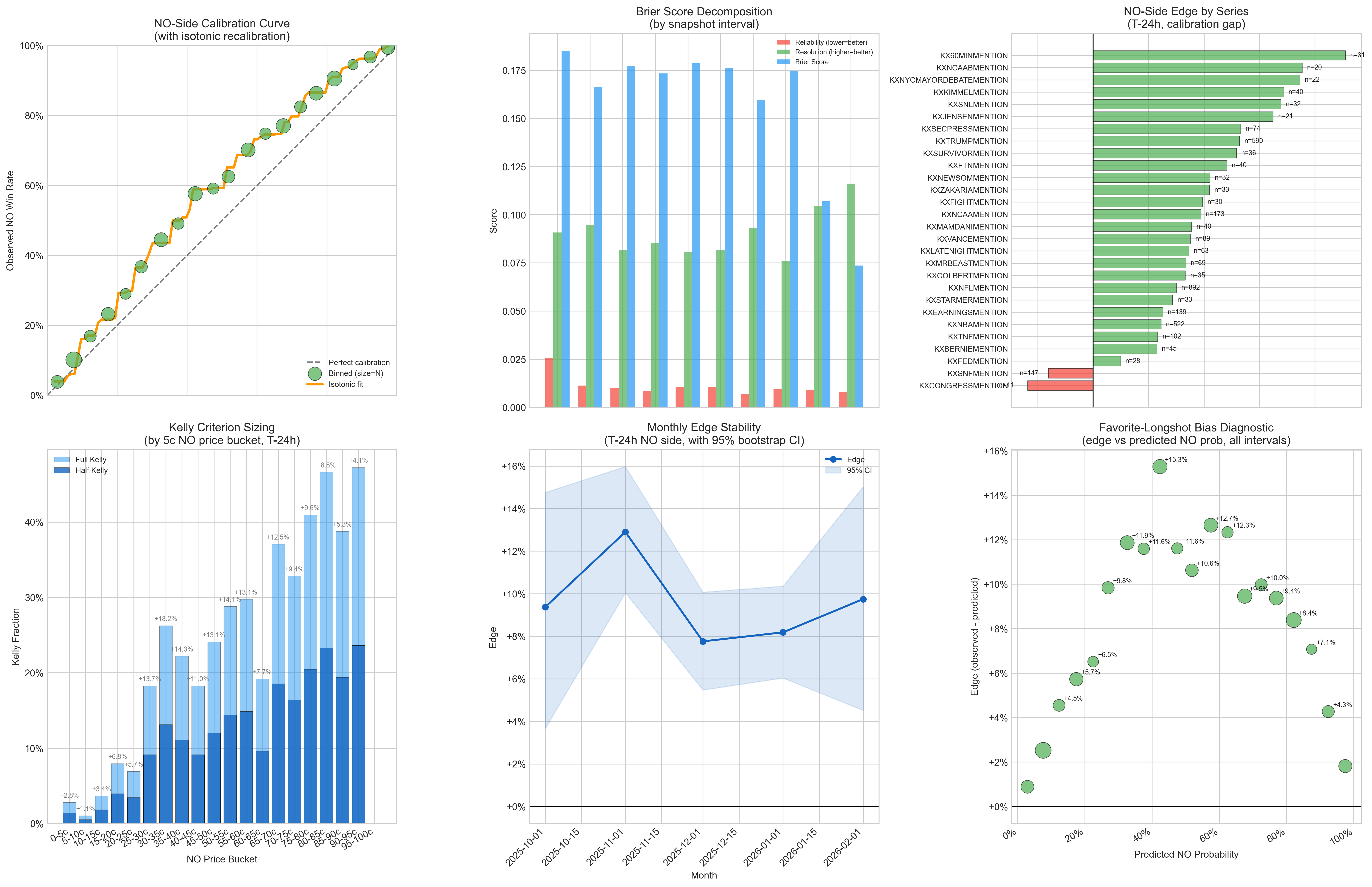
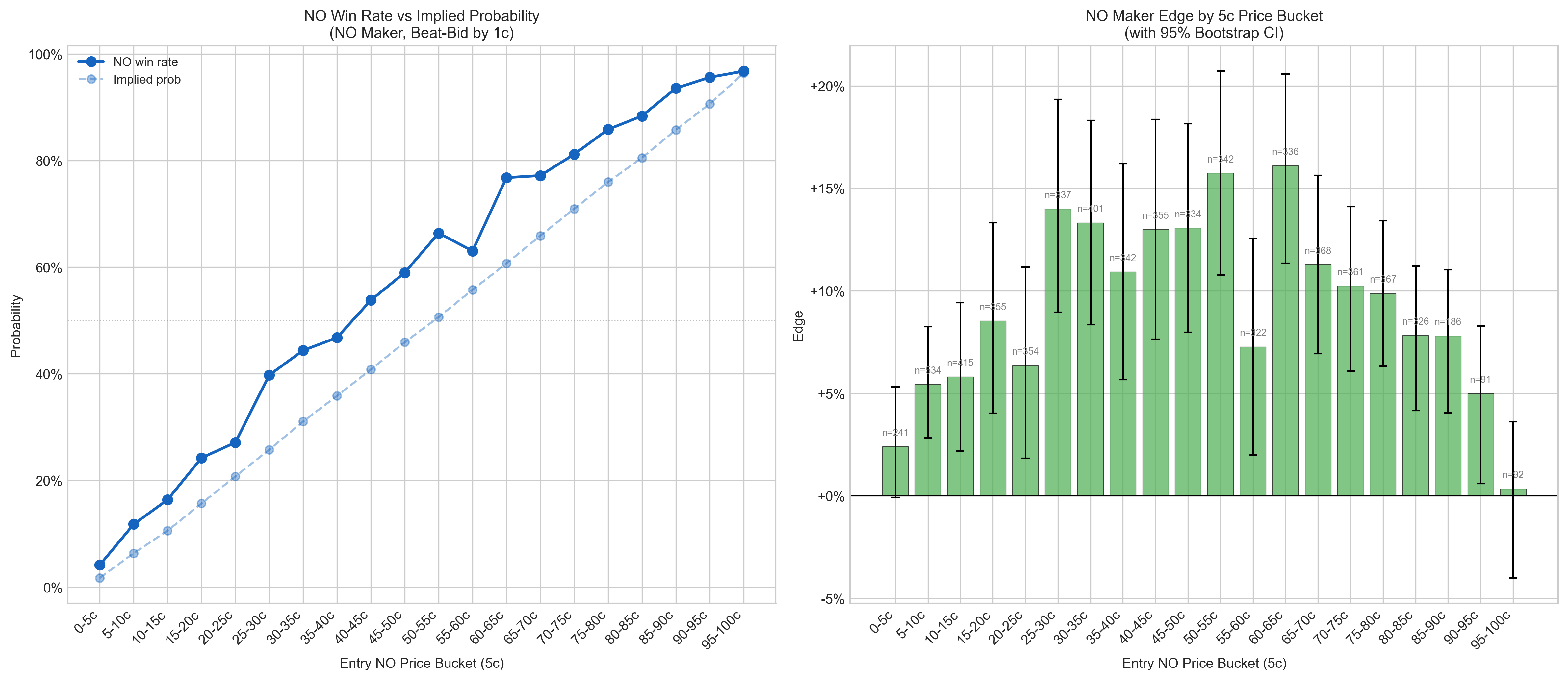
This information alone is basically enough to make a small amount of money: just bet No on all mention markets. But you also have to understand that Kalshi is a middleman that takes a cut of the contracts you put up. So you have to beat the other players in this market game, Kalshi's fees, and taxes. More on taxes later.
First, Kalshi's fee schedule uses a 7% taker-fee formula for immediately matched orders and a 1.75% maker-fee formula for resting orders that later execute. A taker is a person who visits Kalshi, clicks Yes or No on a contract, and buys it. You are "taking" a contract. A market maker provides liquidity. They say, "I'll offer contracts at 60% Yes odds if anyone would like to buy them from me." Every taker needs a maker. Nothing happens to unsold contracts. So, just like jbecker found, being a market maker is much, much more profitable.
Second, if you look at the calibration per price bracket, you can narrow this down more.
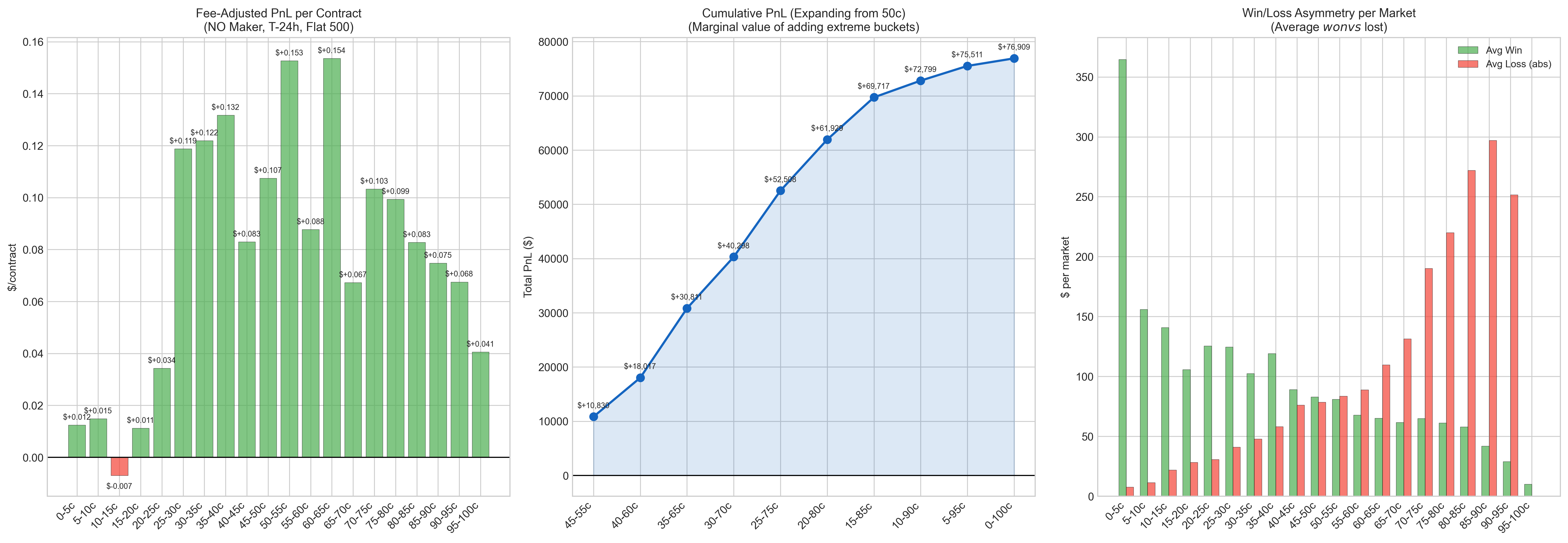
Third, timing matters. You mostly want to enter the market 24-30 hours before the market closes.
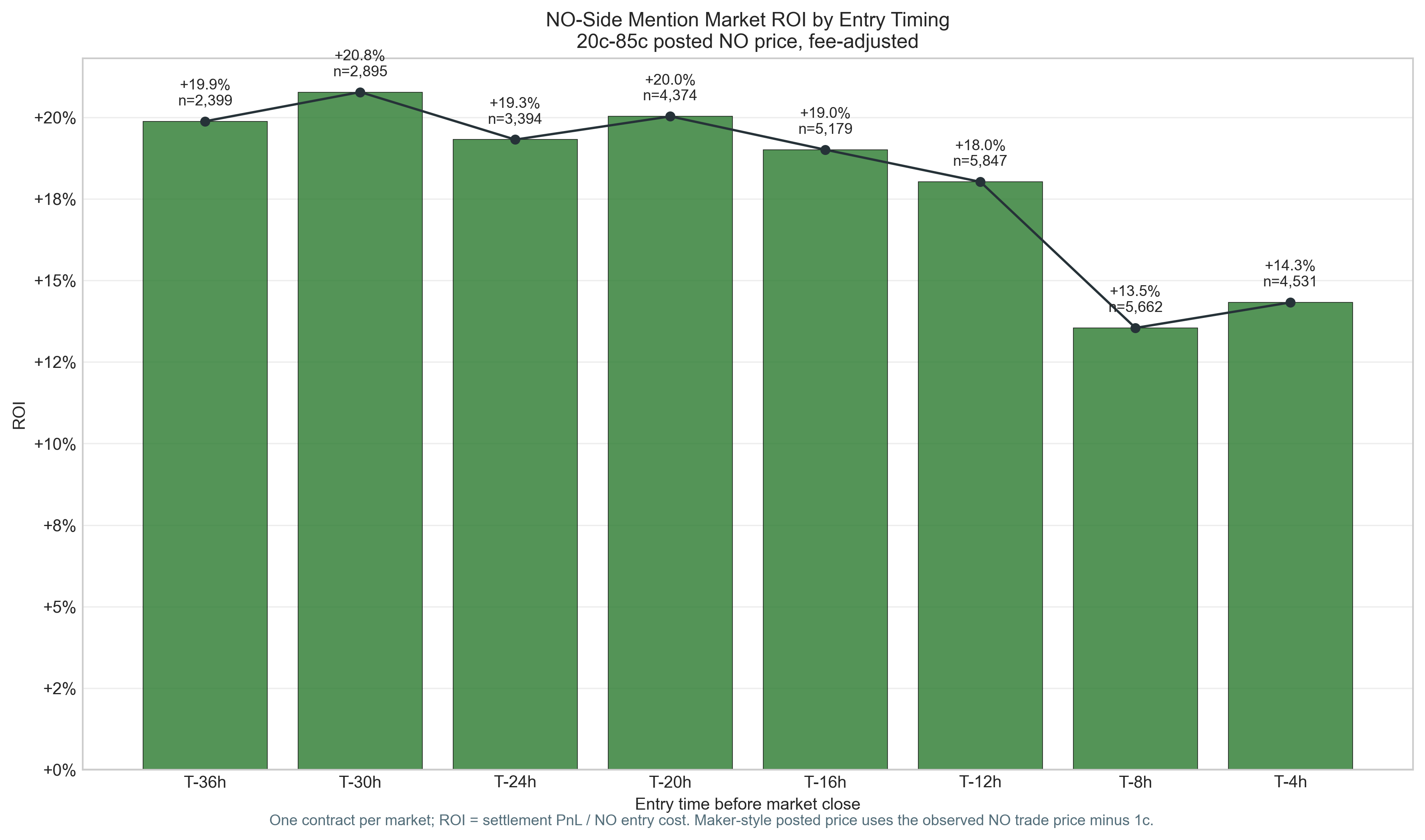
Great, now we have all the pieces. The chart above says we should enter 30h before the market closes so basically, words that are priced between 20% and 80% chance of being said, regardless of the speaker, show the highest mispricing. So we take the No-the-word-won't-be-said side on all mention markets, put in limit orders (offer contracts for sale at the best price so they get bought quickly), and only put in those limit orders if the best price is between $0.20 and $0.85.
Trap #1: Sizing and the Limitations of the Data
Like I said before, all my real money experimentation up to this point was with $10 worth of contracts. Since I was getting 50% ROI on these initial trades, I should just bump that up to $10,000 worth of contracts and I'll be a millionaire by next week, right? I'm sure you know the answer to this. I increased to $1,000 worth of contracts on each word market up from $10 in pure hubris with the following results highlighted.
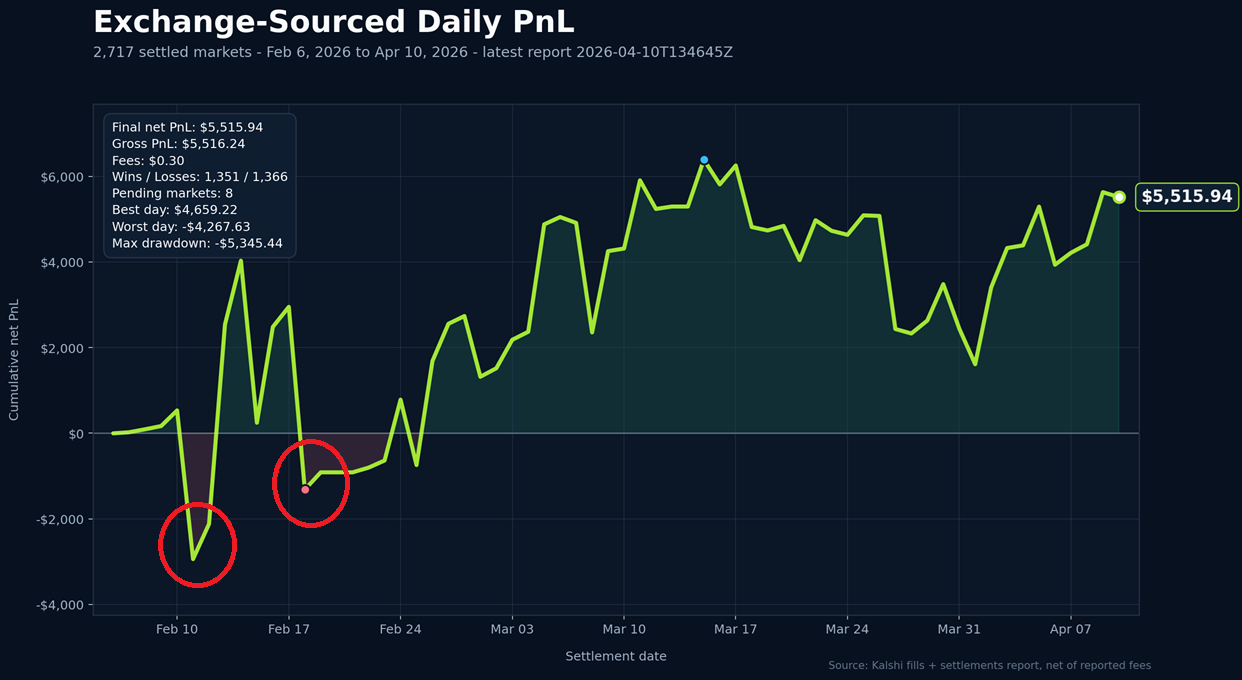
Oooook, so that didn't work. But why? Why did my data analysis say that the more I put in, the more profit I'd get? Well, that's because the historical data I was working from was basically L1 data. L1 is the top of the book: best bid, best ask, last price, volume, that kind of thing. L2 is the full visible order book by price level: how many contracts are sitting at 28c, 27c, 26c, etc. Kalshi's orderbook API can show the current aggregated YES and NO bid levels, and the websocket can stream updates to those levels, but my backtest did not have clean historical depth and queue data for every market at every point in time.
L3 is the even nastier version: individual orders, queue position, cancels, and the exact sequence of who is in front of you. That is the level where you can answer the question I actually cared about: if I post 1,000 contracts here, do I get filled because there is real random flow, or do I get filled because the only person willing to hit me knows I am wrong? Without that, you can estimate sizing, but you cannot know it. You model book depth, fill probability, and adverse selection from scraps.
And that is exactly how my pricing screwed me. I was trying to get filled quickly, so my bot priced near the top of the No book. Small orders were fine because they were a tiny sip of liquidity. Then I started throwing 500- and 1,000-contract orders into markets where that was sometimes the whole damn puddle. The people who either had insider knowledge or better probability measurements were snapping up ALL my contracts only on word markets that they had an advantage on while the dumb consumer money was just nibbling at my good contracts where I had an advantage. I was the largest liquidity provider in many of these word markets and got hit with adverse selection. Back to the drawing board.
The Quant Detour
I went and did research on what the quants at hedge funds do to try to improve my bot. Here is a list of words that you can spit out so you can impress the unsophisticated troglodytes around you with your supergenius trading knowledge: Avellaneda-Stoikov, GLFT, Glosten-Milgrom, VPIN, Brier score decomposition, isotonic calibration, Kelly sizing, queue depth estimation, spread sweeps, adverse selection, flow toxicity, repricing analysis, market-impact modeling, and multi-window inventory ramping.
None of you pedestrians would understand the nuances of these techniques so I won't even bother explaining them, and it definitely doesn't have anything to do with the fact that I just asked Claude Code to use them in analysis while nodding my head and going, "ah, yes yes," while sipping my martini. The actual summary is that a lot of this does not really apply cleanly to tiny, low-liquidity mention markets. The fancy models were useful mostly because they all screamed the same boring thing: thin books, toxic fills, and position size matter more than sounding like a PDF.
So I ended up keeping it simple: laddered limit orders with contract caps based on market liquidity. Pricing a No contract is straightforward. If I buy No at $0.40 and the word is not said, the contract settles at $1.00 and I make $0.60 before fees. If the word is said, I lose the $0.40. The price is both my implied probability and my max loss per contract, so moving from 40c to 50c is not a tiny cosmetic change. It is more money at risk and a worse break-even.
The ladder technique was just splitting one big stupid order into several smaller, slightly less stupid orders. Instead of posting 1,000 No contracts at 50c, the bot might post a stack like 300 contracts at 50c, 250 at 49c, 200 at 48c, and so on. If the market only lightly touches my price, I get a small fill near the top. If someone is aggressively taking the other side, they have to chew through worse and worse prices before they can fill my whole position. It does not eliminate adverse selection, but it makes the bad fills smaller and cheaper, which was the whole game.
Trap #2: Information Leakage
Overall, after I implemented laddering and limited the amount of contracts based on the liquidity in the market, the bot was just running 24/7 printing me a decent amount of cash consistently. Unfortunately, I actually hit a couple more horrible loss days after those 2 initial negative bankroll events. First, Survivor Episode 4 leaked in India a couple hours before it was supposed to premiere and I got HOSED. Then, a political speech was leaked online a couple hours before the speech was given. HOSED again. I mitigated these problems in the future by setting a guardrail that closed out all my unsold contracts a few hours before the event started. It's not perfect and it costs me a decent amount of money since most of the trading occurs right before the event starts, but it's a super simple and effective risk-limiter against total losses.
The Strategy
To recap:
- Do limit orders.
- Play mention markets.
- Always be on the No side of the contract.
- Ladder your limit orders.
- Keep your contract sizing relative to market liquidity.
- Place the limit orders between 20c and 85c.
- Close unsold limit orders a couple hours before the event takes place.
That's it. Code it up and let 'er rip. I did that for a couple months. Made money. It was pretty cool. Now let me tell you why I stopped.
Why I Stopped
First, the edge started to disappear. As mention markets grew in liquidity, the calibration started getting better and better and my ROI started dropping. I was never going to become a millionaire off this bot anyway, because the market liquidity was too low. As the ROI dropped, taxes started playing a larger role.
Second, taxes. In certain states, like my own, gambling laws can tax you on wagers, not profits. So if I wager $100,000, lose 100% of it, I can still owe taxes on the action. The fuck man. This is what ate tons of my profit wagering on UFC with my machine-learning model. I would go up 10% ROI, but taxes would eat 80% of my winnings. The kind of low-edge, high-volume betting I was doing meant I was feeding Captain America more than myself. Fucking lame.
Prediction markets are also in a precarious spot. They are federally regulated by the CFTC, but state regulators are fighting to classify at least some of the activity as gambling. As of 2026, courts are not speaking with one voice. Some rulings have favored Kalshi's federal-preemption argument, while other state fights have gone the other way or are still moving through the courts. That is not a tax opinion. It is just a tail risk I did not feel like carrying.
Donald Trump Jr. is a strategic advisor to Kalshi, and his firm also backed Polymarket, where he joined the advisory board. So while Trump is in office, prediction markets are probably safer federally than they otherwise would be. But what happens when he leaves? There is ongoing litigation between states and prediction-market companies, and I do not want to wake up years later with a back-tax problem because a low-edge bot got reclassified after the fact.
So I decided to share this with the world. Maybe some of you can make some money and buy me a Lambo when you are sipping Mai Tais in Anguilla and doing great public works with my hard one week's worth of work.
Conclusion
That's the story of how I made roughly $6k using a small Python script that ran untouched for a few months with zero further effort. I have been investing in my ability to create mathematical models that predict the future since 2021. I have wagered hundreds of thousands of dollars, and yes, IRS, I reported ALL of it on my taxes ya bastards, on UFC and prediction markets.
At the end of the day, my total net profit after taxes and expenses is probably just a measly few thousand. Small mistakes cost a LOT, and profit is slow and steady. That being said, all this work ended up giving me skills that have paid off very handsomely in my professional life and gives me confidence that, should I ever want to make a play at doing this full time, I would be fully capable.
If you want to connect with other machine-learning-for-sports-prediction experts, come on over to my Patreon chat: patreon.com/c/mmaai.
If you want to watch, play, or create games using AI agents, check out clankerfights.ai.