In discussions of contamination risk on Mars, it’s sometimes taken as a given that any microbes we accidentally introduced into a Martian ecosystem would be easy to distinguish from any relic life that existed there.
This claim touches on the very interesting question of what kinds of life we can identify on Earth.
As early as 1932, the Soviet microbiologist A.S. Razumov noticed that there were far more bacteria visible under a microscope in water samples than could be persuaded to grow in his laboratory. In a 1985 paper, the researchers Staley and Konopka christened the discrepancy ‘The Great Plate Count Anomaly’. By their estimate, something like 99% to 99.9% of bacteria in freshwater samples were happy, metabolically active microbes who could not be bullied or bribed into growing on a Petri dish or in a vial of liquid medium.
Back in an era when culturing microbes was the first step in trying to understand them, this was a problem. The only thing researchers could do was cross their fingers and hope that the few species we managed to grow in the lab were representative of the great unwashed masses of microbes living in the world around us.
In 1977 Carl Woese, using novel molecular techniques, announced the discovery of a third domain of life he called Archaebacteria. Later renamed Archaea, these one-celled organisms looked like bacteria under a microscope, but were no more related to them on the molecular level than they were to a rose bush or a hamster. It took until the 1990’s for Woese’s three-domain model of life to be accepted, but the methods he pioneered immediately transformed the field.
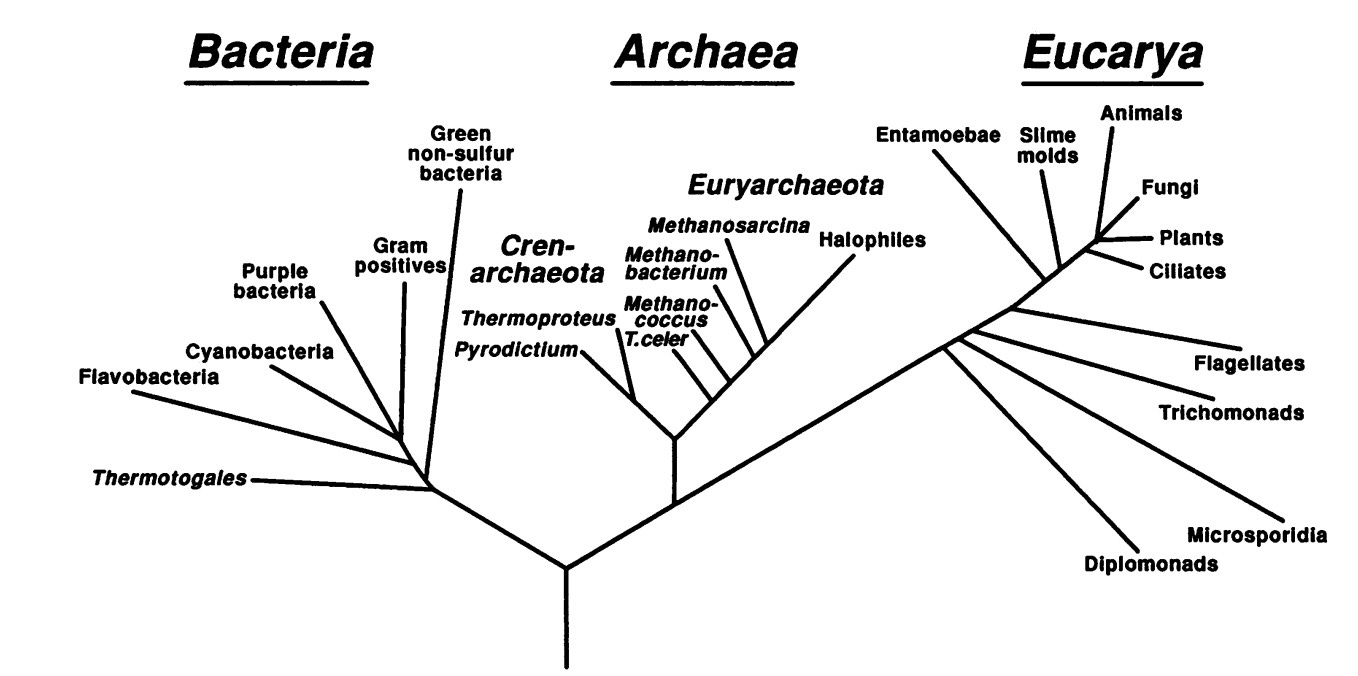
Woese reached his landmark conclusion by examining ribosomal RNA. Ribosomes are an ancient piece of cellular machinery, common to every form of life on Earth, and the DNA that codes for them was short enough to be tractable even by 1970’s standards. The ribosomal DNA had a useful property: some sections of the sequence are highly conserved, because key parts of the ribosome can’t function without them, while others are less constrained and can mutate freely over time. The existence of the conserved sections made it easy to pick out ribosomal DNA from a sea of fragments, while statistical analysis of the mutable areas gave a measure of evolutionary distance.1
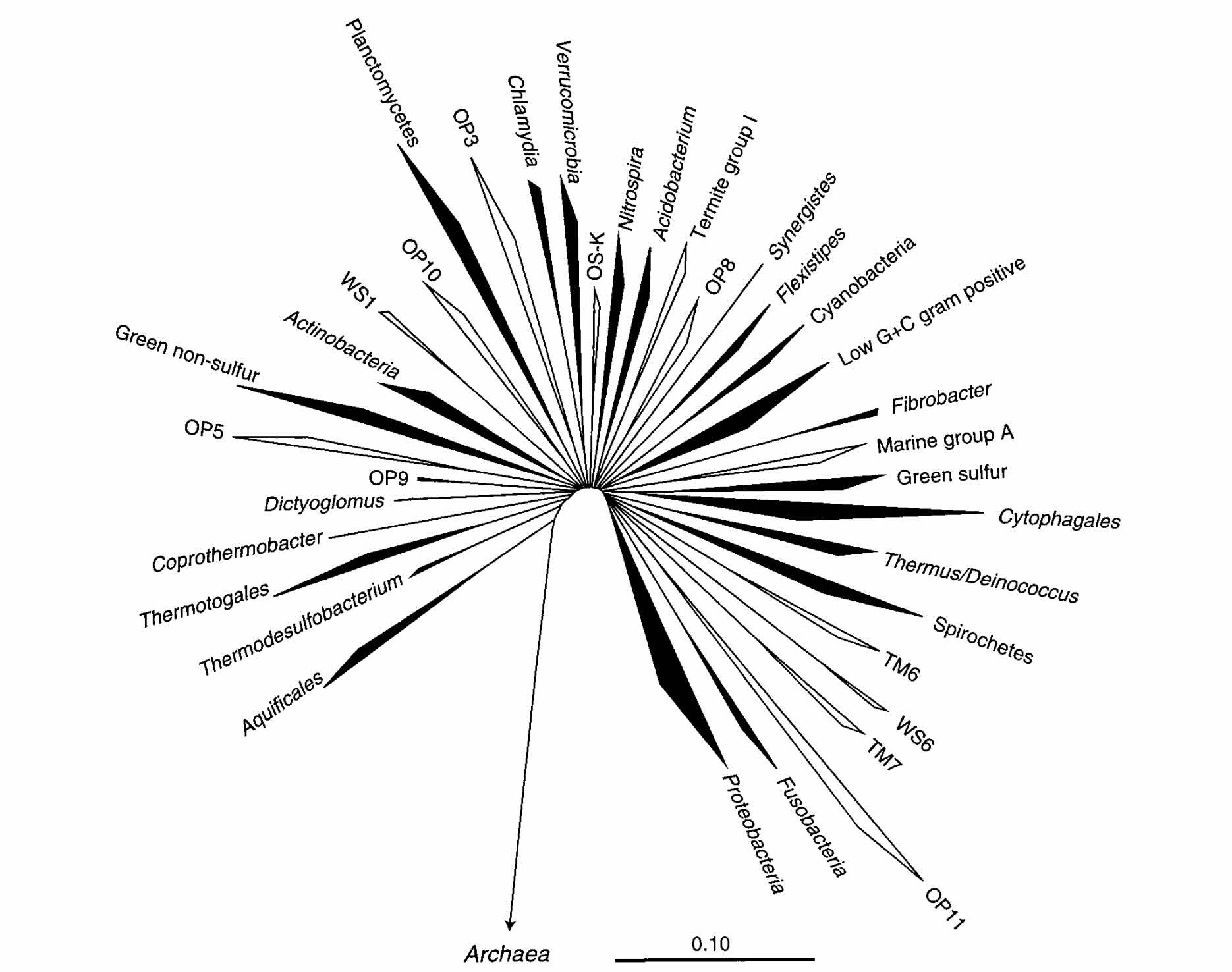
Woese had used ribosomal DNA to reveal relationships between microbes that could be grown in a lab. But a group led by Norman Pace quickly realized that the same technique would work on microbial populations in the wild, without having to culture anything. The line of research his group opened over the next ten years changed the face of microbiology, uncovering not just new species, but entire new divisions of life. Woese had grouped the known bacteria into about a dozen phyla, and now Pace’s group added twenty four major categories they called ‘candidate phyla’—new domains of life that we knew existed, but had no additional knowledge about. It was like opening a door in your studio apartment to discover that you’ve been living in the closet of a dark and unexplored palace.
At this point microbiologists faced a problem more familiar to mathematicians. Mathematics has the notion of a non-constructive proof, where you demonstrate the existence of a mathematical object without being able to produce an example of it. The ribosomal studies proved the existence of whole new categories of microbe, but didn’t offer clues about how to find such a creature in the wild. These new arrivals remained spectral entries in a growing database of ribosome sequences.
You can think of cataloging ribosomal DNA like being told someone’s name, date and place of birth. It’s a helpful way to build a family tree, but tells you nothing about a person’s appearance, hobbies, personality, or behavior. What was needed was a way to connect the new phylogenetic categories to actual organisms that could be collected and studied.
The next step was to try sequencing entire genomes directly from environmental samples. This technique, called shotgun sequencing, would have been ruinously expensive in the 1990’s. The Human Genome Project had needed thirteen years and nine-figure sums to assemble a rough draft of the 3 billion base pair human genome. But the cost of automated DNA sequencing was dropping at about the same pace as Moore’s Law, with the price per base pair cut in half every 18 months. In 2004, Jill Banfield’s team proved that environmental shotgun sequencing was viable by isolating multiple genomes from a sample taken in a California iron mine. That same year, Craig Venter collected samples from across the Sargasso Sea and assembled a list of 1800 candidate species. Their experimental techniques improved quickly; Banfield would go on to discover a bestiary called the Candidate Phyla Radiation, which for a while looked like it might constitute a fifth of all microbial species on Earth.
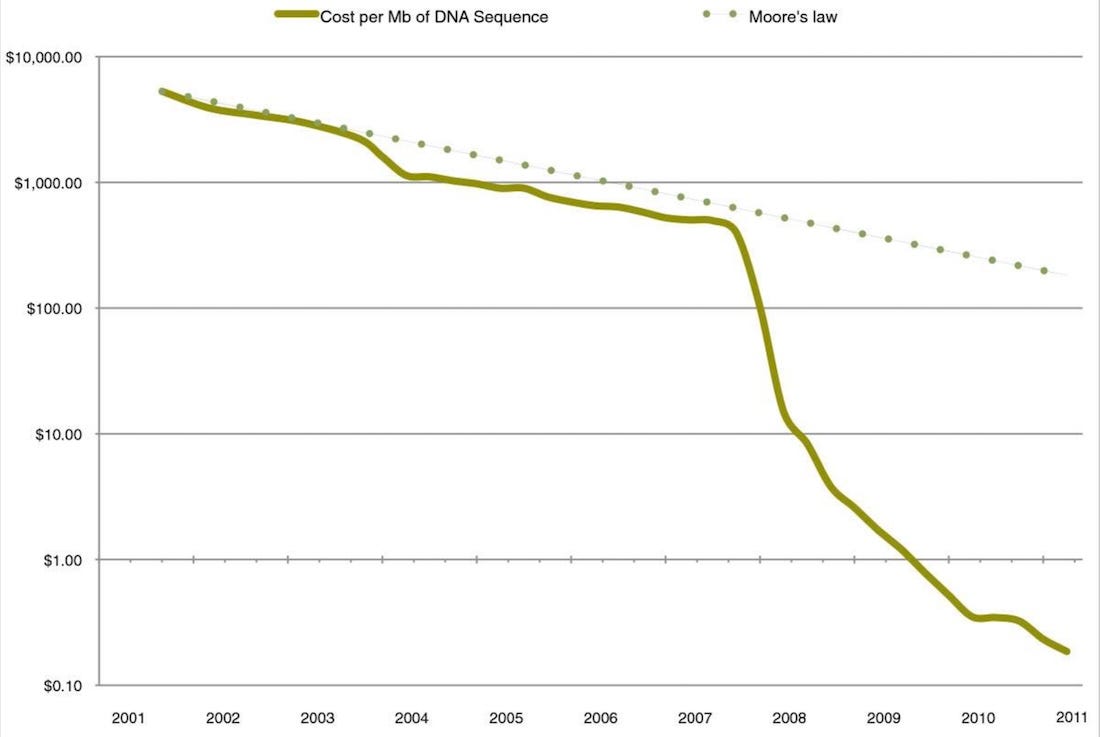
The floodgates really opened after 2005, when a new generation of commercial sequencing technology came online. The per-base cost of sequencing dropped by something like five orders of magnitude in just four years. You no longer needed a big lab and a million-dollar budget to try ‘shotgun sequencing’; all it took was a graduate student and a shovel. The field entered a sort of Wild West phase where you could put random pocket lint in a 454 pyrosequencer and reliably discover not just new species or genera, but entire phyla. Discoveries at this level were unheard of in multicellular biology—imagine if it had taken us until the year 2000 to discover insects or flowering plants. But in microbiology they were now expected.
A final breakthrough came with the adoption of multiple displacement amplification, a technique that could take DNA from a single cell and grow it into quantities big enough to be sequenced. Instead trying to tease out individual genomes from a gumbo of undifferentiated DNA, researchers could now pick out a single cell of interest in a microscope, isolate it, and sequence its entire genome.2 The process itself had been invented in 2002, and by 2012 it was fully automated. Sample water flowed through a thin capillary, sensors detected the presence of a cell, and some hapless microbe would then be shunted off for sequencing and then immortality in a genetic database.
But in some sense, these organisms were still digital ghosts. All we knew about them was their genetic code (sometimes just ribosomal sequences, sometimes whole genomes, more often fragments). But what were their hopes, dreams? What did they like to eat? Did they prefer methane to hydrogen? Would they rather swim towards the light or away from it? None of this leapt out of the gene data. And there were foundational questions to grapple with, too. If a scientist fully sequenced the genome of an organism she had never seen, could she be said to have discovered it? Was it okay to give it a name? Was microbiology even a laboratory science anymore, or would everyone end up sitting behind computers, looking for matches in a sequence database?
The mycologists took all this especially hard. Their domain of study, fungi, was confronted by the same crisis of overabundance as microbiology. Mushroom hunting had always been a genteel science where you were expected to produce a ‘type specimen’ that would then be the official embodiment of your discovery. You were supposed to discover fungi by walking around in tweed and lifting leaves with your cane. The new molecular techniques confronted the hunters with a flood of sequenced genomes for single-celled fungi. The four familiar, cherished phyla everyone had grown up with soon expanded to twelve. There were an awful lot of unsuspected mushrooms growing out there in the dark.
Virologists, more accustomed to being pantsed by Mother Nature, took the explosion of variety in their field more philosophically. But they struggled with definitional issues that were even trickier than the ones confronting microbiology. Viral DNA was everywhere in environmental samples, with no obvious way to organize it, or associate it with a host organism. Even the boundaries between virus and non-virus were getting murky. Many took to drink.
A big lesson of this era was that you only ever find what you’re looking for. A large branch of the tree of life called the ‘Candidate Phyla Radiation’ escaped detection until 2015 because researchers were using the wrong mesh size to filter samples (no one expected bacteria could be so small), and because CPR bacteria had ribosomal DNA that was invisible to so-called ‘universal’ primers, which turned out not to be so universal.3 In the same spirit, a novel category of virus discovered in a water tower in 1992 sat unrecognized for eleven years in an archive because it was so huge that everyone mistook it for a microbe.
A consistent pattern in the new era of discovery has been that some bizarre microbe is discovered living in a preposterous environment like a hydrothermal vent, and then a couple of years later we find out it also makes up 40% of our intestinal flora. For example, Saccharibacteria are ubiquitous in the oral cavity, but the branch of life they belong to was only discovered in 1996 (in a German peat bog), and it took until 2015 to culture the first representative of the phylum, an absolutely tiny fellow who lives on the back of bigger, tougher microbes that like to hang out near the gum line.
Surprises like this were everywhere. Equally surprising was the aggressive ubiquity of life. It became difficult to find places on Earth that were uninhabited. You could collect and sequence DNA from cloud tops, hypersaline lakes, or the coolant loop in nuclear reactor cores. Drill kilometers under the sea floor and you would find living bacteria that perked up when you fed them, after a 100-million year nap.
Another key lesson was that microbial communities formed a more natural unit of study than individual species. The reason many of those Candidate Phyla Radiation beasties were so small is because they were missing some basic machinery of life, and lived as obligate symbionts (or parasites) of larger hosts. The same was true for the tiny class of archaea called DPANN. Many of these microbes lived off of one another’s waste products and borrowed molecular machinery as needed, the way a neighbor might borrow a cup of sugar. Some organisms could swap out entire metabolic pathways depending on what food was available at the moment.
Microbes also never took high school biology class, and so were unaware that genetic inheritance can only be passed down the germ line. Instead, they traded genes between themselves like Pokémon cards, in a promiscuous process called horizontal gene transfer. The microbial tree of life had a lot of cross-links. And a bewildering menagerie of viruses, viroids, phages, and other entities complicated the matter further by smearing genetic material across species, phylum, and sometimes even kingdom barriers.
By 2016, we had a beautiful new tree of life. The red dots in the diagram below show lineages that are known from environmental DNA, but do not have an isolated representative species.

For biologists, this period was a little bit like what astronomers went through in 1923, after discovering that stellar nebulae were entire galaxies in their own right. Imagine going outside to find that the Louisiana Purchase has been added to your backyard. There was a vertiginous sense of horizons expanding, and a glimpse of the full scope of human ignorance, which is rarely granted to a scientific field.
It all prompted a natural question—just how much more of this stuff was out there to find? In 2016, Kenneth Locey and Jay Lennon argued from mathematical models that we should expect to find a trillion species of microbe. Their claim started a debate that ranges across six orders of magnitude, from skeptics who argue for millions, through a middle ground of hundreds of millions, up to the enormous original claim. Whatever the answer is, it dwarfs the 30,000 known microbes that have so far been cultured.
This leaves the field in a bind. There is both too much and too little data at the same time. On the one hand, microbiology is drowning in sequences; the challenge is to find organizing principles and concepts that might make the great wealth of genetic data more tractable to human understanding. At the same time, we barely know anything about the microbial world, and need to keep filling gaps in the data with systematic surveys of the human microbiome and every kind of terrestrial niche.
So the answer to the question I posed at the start of this essay is that it’s complicated.
We can reliably find life if we know exactly what we’re looking for. But it is not true that, given a microbe chosen at random, we could identify it even at the superphylum level. Most of the weird DNA we find in environmental surveys gets binned in a category called ‘other’ that remains opaque to our understanding. We can’t even compile a definitive list of the microbes that live in the human bloodstream, let alone the species that might journey with explorers on a spacecraft.
Nor is it true that microbes are little bags of genes that stay the same over time, and that these genes uniquely determine an organism’s position in the great tree of life. Microbes exchange genetic material at the drop of a hat, a process that makes categorizing them in the wild frustrating, and one that has dire implications for any contamination scenario where terrestrial organisms encounter distant living relatives on Venus or Mars.
Let me talk about these implications of all this for space exploration in a little more detail.
The biggest lesson of this new era in microbiology is that we’re not very good at finding life. Microbes that have been living not just under our noses, but physically inside our noses, remain unknown to science. The most prevalent organism on Earth, a free-swimming ocean microbe called Pelagibacter ubique, was only identified in 1990, and not successfully cultured until 2002. A class of bizarre microbes that make hydrazine (rocket fuel) as a metabolic intermediate turned out to be responsible for half the ocean’s nitrogen production, even though scientists until the 1990’s were skeptical that their brand of metabolism was even possible. These organisms, the annamox bacteria, were not identified until 1999. The list of these things is endless.
And this is just the state of things on Earth, a planet with known biochemistry, big comfy labs, and armies of grad students. You can imagine the difficulty of trying to distinguish native from Earth life with the kind of rudimentary equipment we would send to Mars or the cloud tops of Venus.