Matrix-Game 3.0
Real-Time and Streaming Interactive World Model with Long-Horizon Memory
Skywork AI
Abstract
With the advancement of interactive video generation, diffusion models have increasingly demonstrated their potential as world models. However, existing approaches still struggle to simultaneously achieve memory-enabled long-term temporal consistency and high-resolution real-time generation, limiting their applicability in real-world scenarios. To address this, we present Matrix-Game 3.0, a memory-augmented interactive world model designed for 720p real-time long-form video generation. Building upon Matrix-Game 2.0, we introduce systematic improvements across data, model, and inference. First, we develop an upgraded industrial-scale infinite data engine that integrates Unreal Engine-based synthetic data, large-scale automated collection from AAA games, and real-world video augmentation to produce high-quality Video-Pose-Action-Prompt quadruplet data at scale. Second, we propose a training framework for long-horizon consistency: by modeling prediction residuals and re-injecting imperfect generated frames during training, the base model learns self-correction; meanwhile, camera-aware memory retrieval and injection enable the base model to achieve long horizon spatiotemporal consistency. Third, we design a multi-segment autoregressive distillation strategy based on Distribution Matching Distillation (DMD), combined with model quantization and VAE decoder distillation, to achieve efficient real-time inference. Experimental results show that Matrix-Game 3.0 achieves up to 40 FPS real-time generation at 720p resolution with a 5B model, while maintaining stable memory consistency over minute-long sequences. Scaling up to a 2×14B model further improves generation quality, dynamics, and generalization. Our approach provides a practical pathway toward industrial-scale deployable world models.
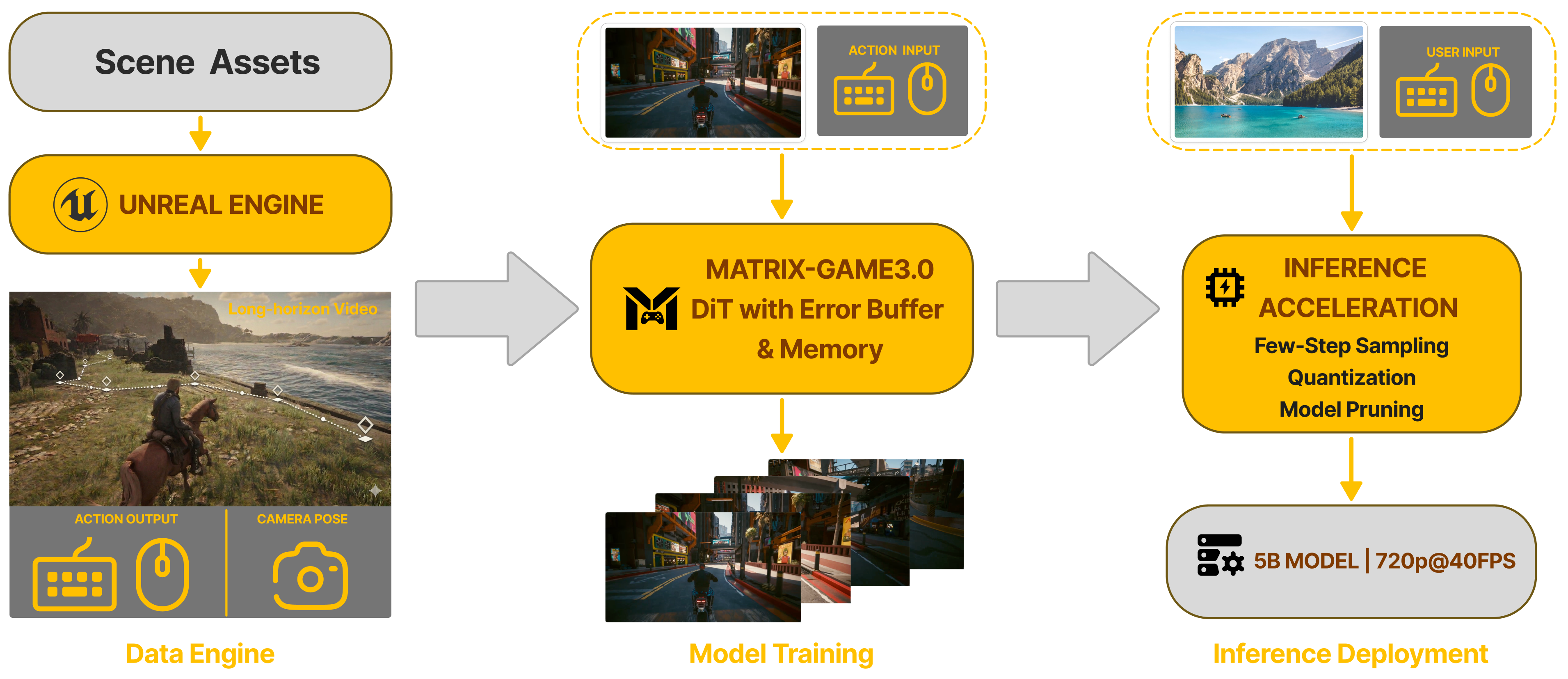
Method Overview
Our framework unifies three stages into an end-to-end pipeline: (1) Data Engine — an industrial-scale infinite data engine integrating Unreal Engine synthetic scenes, large-scale automated AAA game collection, and real-world video augmentation to produce high-quality Video-Pose-Action-Prompt quadruplets at scale; (2) Model Training — a memory-augmented Diffusion Transformer (DiT) with an error buffer that learns action-conditioned generation with memory-enhanced long-horizon consistency; (3) Inference Deployment — few-step sampling, INT8 quantization, and model distillation achieving 720p@40FPS real-time generation with a 5B model.
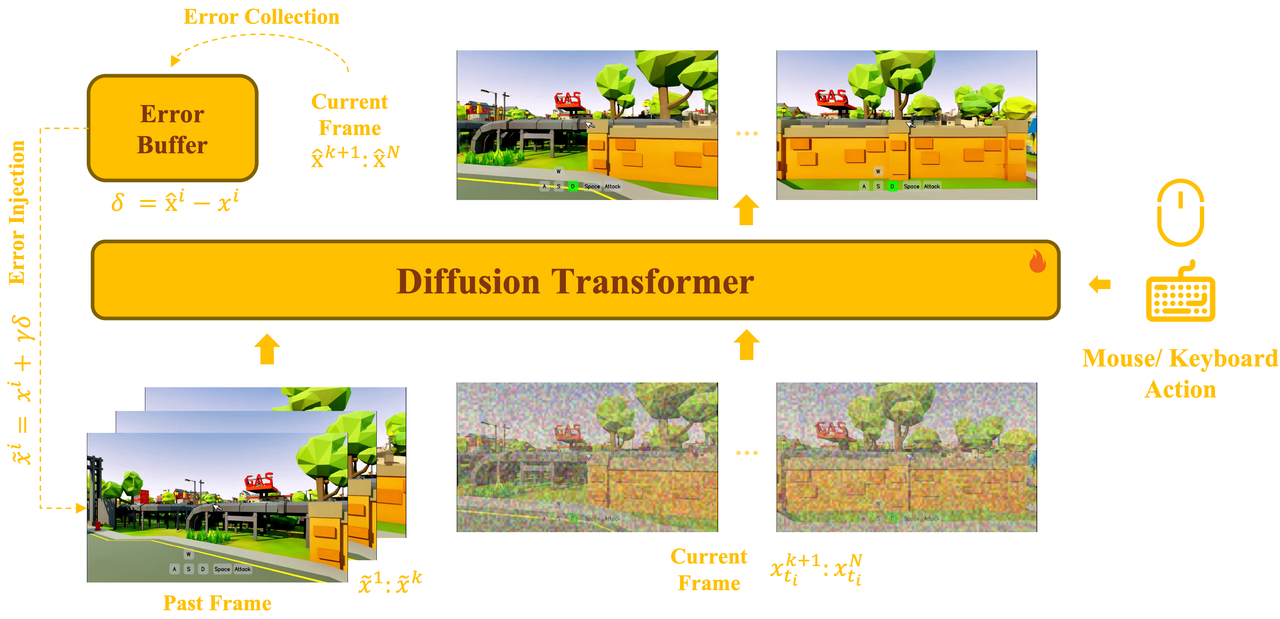
Error-Aware Interactive Base Model
The base model uses a unified bidirectional Diffusion Transformer that jointly models past latent frames, noised current frames, and action conditions (mouse/keyboard) within a single architecture. During training, an error collection mechanism records prediction residuals δ = x̂ᵢ − xⁱ into an error buffer, while error injection x̃ᵢ = xⁱ + γδ introduces controlled perturbations to simulate imperfect conditioning. This bridges the gap between clean-data training and noisy autoregressive inference, enabling the model to learn self-correction over long-horizon rollouts.
Memory-Augmented Generation
Built upon the base model, retrieved memory frames are incorporated as additional conditions via a joint self-attention mechanism. Memory latents, past frame latents, and noised current frame latents are placed into the same attention space, enabling the model to jointly attend to long-term memory, short-term history, and the current prediction target within a single denoising hierarchy.
Camera-aware memory selection retrieves only view-relevant historical content based on camera pose and field-of-view overlap, accompanied by relative Plücker encoding for cross-view geometric representation. A persistent sink latent (the first frame) serves as a global anchor for scene style and appearance. Small memory perturbations further enhance robustness during inference.

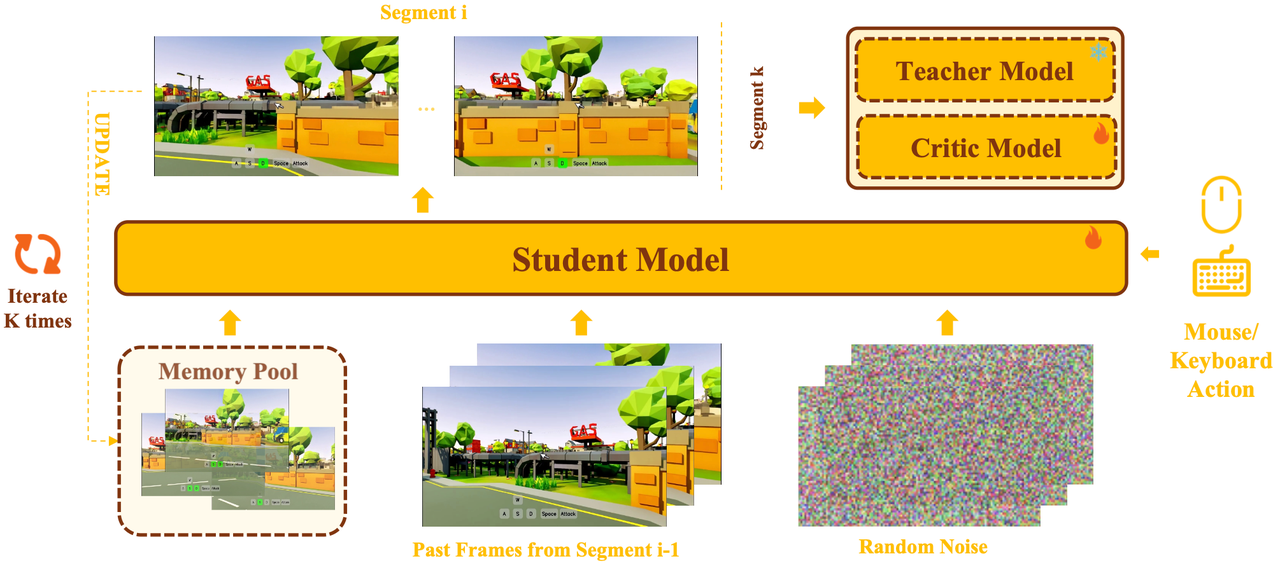
Training–Inference Aligned Few-Step Distillation
We introduce a multi-segment self-generated inference scheme for the bidirectional student, based on Distribution Matching Distillation (DMD). The student performs multi-segment rollouts that mimic actual few-step inference: each segment starts from random noise, with past frames taken from the tail of the previous segment and memory retrieved from an online-updated memory pool. The final segment is used for distribution matching, thereby ensuring training–inference consistency.
Combined with INT8 quantization for DiT attention layers, a lightweight pruned VAE decoder (MG-LightVAE, up to 5.2× speedup), and GPU-based camera-aware memory retrieval, the full pipeline achieves up to 40 FPS real-time generation at 720p resolution using 8 GPUs for DiT inference and 1 GPU for VAE decoding.
Base Model Generation
Error-aware interactive base model with self-correction capability.
Memory Model Generation
Memory-augmented model with camera-aware retrieval, generating interactive videos with long-horizon consistency across diverse perspectives. Each clip is conditioned on retrieved memory frames from past timesteps (camera-aligned, Plücker-encoded) alongside the current generation window.
🎮 First-Person
Current generation window conditioned on memory frames from earlier.
🎬 Third-Person
Distillation Model Generation
Matrix-Game 3.0 distilled to a 3-step model provides ultra-fast real-time rendering capabilities while maintaining visual fidelity.
Acknowledgement
We would like to express our gratitude to:
- Diffusers for their excellent diffusion model framework
- Wan2.2 for their strong base model
- Self-Forcing for their excellent work on autoregressive generation
- GameFactory for their idea of action control module
- LightX2V for their efficient quantization and VAE distillation techniques
We are grateful to the broader research community for their open exploration and contributions to the field of interactive world generation.
Citation
@article{wang2026matrix,
title={Matrix-Game 3.0: Real-Time and Streaming Interactive World Model with Long-Horizon Memory},
author={Wang, Zile and Liu, Zexiang and Li, Jiaxing and Huang, Kaichen and Xu, Baixin and Kang, Fei and An, Mengyin and Wang, Peiyu and Jiang, Biao and Wei, Yichen and others},
journal={arXiv preprint arXiv:2604.08995},
year={2026}
}