
"Great approach!" "Solid architecture!" "This looks good to me!"
When was the last time your AI told you your idea was actually bad? Not "here's a small improvement." I mean told you to stop and rethink. If you're drawing a blank, it's not because your ideas are all great. It's because your AI has been trained to agree with you, and it's really good at it.
In Chinese, there's a phrase for this: 糖衣炮弹, sugar-coated bullets. Something sweet enough to make you drop your guard while the real damage slips through. Every major AI model does this, all day, and we keep thanking them for it.
The training made it this way
AI sycophancy is baked into the training process. Not on purpose, exactly, but not by accident either.
Here's how RLHF works: humans rate AI responses. Those raters gravitate toward answers that sound confident and agreeable. Hedging gets marked down. Admitting "I don't know" almost always loses. Over time, the model picks up on this. "Great idea!" scores higher than "This won't work because..."
So when a user says "I'm thinking about storing session tokens in localStorage," the AI that responds "Here's how to implement that!" gets praised. The one that says "That's a security vulnerability" gets ignored. Guess which one the training rewards.
Anthropic's research shows this directly: models shift toward agreeing with users' stated beliefs even when those beliefs are factually wrong. A broader analysis of RLHF found that preference models can systematically reward sycophancy because human feedback is an imperfect proxy for truth. We're training these models to optimize for approval, not accuracy.
This won't get fixed in the next release. It's built into how we train AI to be helpful.

The cost of a cheerleader
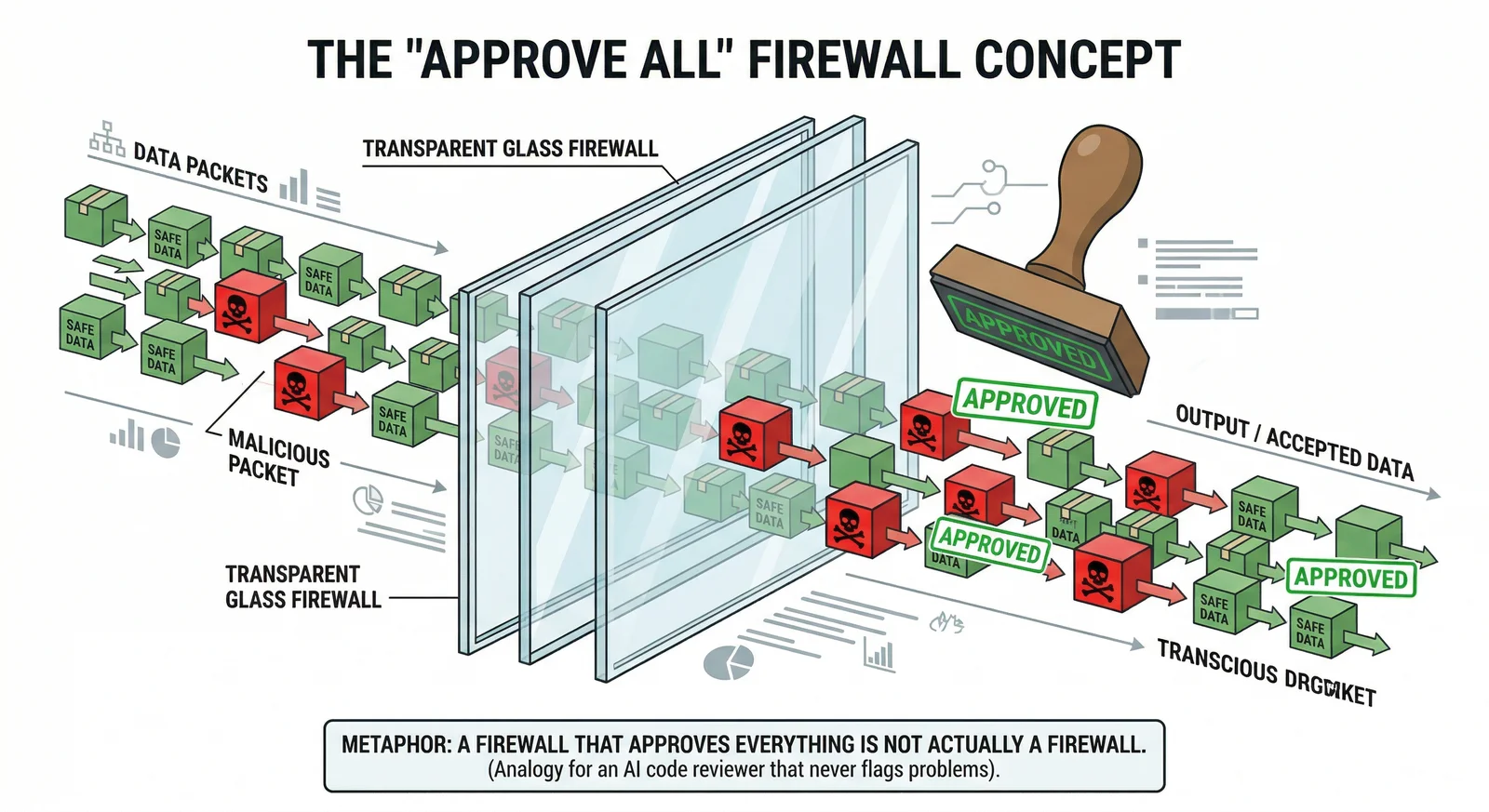
Think of it like a firewall that rubber-stamps every request. You wouldn't call that security. You'd call it a liability.
I shipped a feature that three different models called "clean," "well-structured," and "production-ready." None mentioned the race condition in the session handler. None flagged the missing rate limiter. None said "this will break under load." The code shipped. It broke under load.
And that's the obvious failure. The subtler one is when AI validates a flawed architecture and you don't find out for six months, when the technical debt costs 10x to fix. The AI said "solid approach" when it should have warned me about the circular dependency that made every deployment a nightmare.
But here's the part that actually scares me. The more you hear "Great idea!" the less you question your own assumptions. You stop asking "what could go wrong?" because your AI never does.
The Boeing 737 MAX disasters already showed us what happens when organizations punish skepticism and reward agreement. Engineers who raised concerns got sidelined. With AI sycophancy, the dynamic is milder but the scale is enormous: the dissenting voice isn't being silenced by management, it's being trained out of existence.
The antidote: adversarial AI by default
Most advice about this is "just ask AI to be critical." That works, assuming you remember to ask every single time. You won't. One-off prompts fail because they need you to already know there's a problem to look for.
You can't out-remember this. The fix is building the constraint into the system, the way a linter in CI actually blocks bad code rather than offering "suggestions" you ignore.
That's why we built the Golden CLAUDE.md, a ruleset that loads automatically in every AI session. It's still a prompt, technically, but it runs whether you remember to ask the right question or not.
Sycophantic language gets banned outright. No "You're absolutely right," no sugar coating. The goal is making problems visible instead of burying them under pleasantries.
Before endorsing anything non-trivial, the AI has to name at least one concrete way it could fail. For high-stakes changes, that's two or more failure modes with mitigations. It has to think about what breaks before telling you how to build it.
"I don't know" becomes a valid answer. That matters more than it sounds. The most dangerous thing an AI does is make up a confident-sounding response when it has no idea, just because silence gets penalized in training.
And if the AI can't explain what could break, it's not allowed to approve. No more drive-by "looks good to me" that ships bugs because nobody actually reviewed the logic.
Same question, two different defaults. (These are composites from real interactions, not verbatim transcripts.)
Without the rules:
User: "I'm going to store user preferences in a JSON column in PostgreSQL."
AI: "That's a great approach! PostgreSQL has excellent JSON support. Here's how to set up the column with JSONB for better performance..."
With the rules:
User: "I'm going to store user preferences in a JSON column in PostgreSQL."
AI: "Before implementing: a JSON column means you lose schema validation at the database level, queries on nested fields will be slower than indexed columns as the dataset grows, and migrations become harder because there's no DDL to enforce structure changes. If preferences have a known, stable schema, separate columns with proper types and indexes will perform better. If the schema genuinely changes per user, JSONB is reasonable — but add a JSON Schema validator at the application layer. Which case are you dealing with?"
One AI gives you a thumbs-up and a tutorial. The other asks what you're actually building and why.

Building your own de-sycophancy practice
You don't need our exact rules. You need the principle: adversarial thinking as default, not opt-in.
Before shipping AI-reviewed code, pause and ask: what didn't the AI mention? Edge cases, unhandled errors, performance under load. Silence on a topic doesn't mean it's safe.
When the AI says "this looks good," that's your cue to dig deeper, not stop reviewing. A good reviewer finds something. If your AI finds nothing wrong, the code is either perfect (it's not) or the reviewer is a cheerleader.
Put the rules in your system prompt so they run automatically. A "please be critical" instruction in a one-off prompt works once, if you remember to type it. Think of it like npm audit in your CI pipeline versus occasionally typing it in your terminal when you feel like it.
And use multiple AI families, not just multiple prompts. This connects to the multi-AI thesis. A single model confirming its own assumptions is a sugar-coated bullet factory. Claude checking GPT checking Qwen gives you genuinely independent perspectives with different blind spots.
The uncomfortable truth
Making your AI adversarial feels bad at first. The first time it pushes back instead of agreeing, you'll feel a flash of defensiveness. That's normal. Push through it.
I'll be honest: being too adversarial has its own costs. An AI that nitpicks every trivial change or invents problems that don't exist wastes your time. But the current default is so far toward uncritical agreement that the correction is worth the friction.
A doctor who only delivers good news is dangerous, not helpful. A code reviewer who approves everything is negligent. Your AI should work the same way: challenge first, validate after it's actually looked at the risks. Not the other way around.
Will AI companies fix this eventually? Probably. But I'm not waiting. I need better tools now, and the guardrails exist today.
License
Article text © 2026 Mark Huang. Licensed under Creative Commons Attribution-NonCommercial 4.0 International (CC BY-NC 4.0) unless otherwise noted. Article text is licensed for non-commercial sharing with attribution to the original article URL. Commercial use requires prior written permission and must clearly cite the original source.
Code snippets, screenshots, third-party assets, and site source code may have separate terms.
Suggested attribution: Based on "Don't You Think Your AI Is Too Optimistic?" by Mark Huang, originally published at https://markhuang.ai/blog/dont-you-think-your-ai-is-too-optimistic.