Abstract
Modern alignment techniques based on human preferences, such as RLHF and DPO, typically employ divergence regularization relative to the reference model to ensure training stability. However, this often limits the flexibility of models during alignment, especially when there is a clear distributional discrepancy between the preference data and the reference model. In this paper, we focus on the alignment of recent text-to-image diffusion models, such as Stable Diffusion XL (SDXL), and find that this ''reference mismatch'' is indeed a significant problem in aligning these models due to the unstructured nature of visual modalities: e.g., a preference for a particular stylistic aspect can easily induce such a discrepancy. Motivated by this observation, we propose a novel and memory-friendly preference alignment method for diffusion models that does not depend on any reference model, coined margin-aware preference optimization (MaPO). MaPO jointly maximizes the likelihood margin between the preferred and dispreferred image sets while maximizing the likelihood of the preferred image sets, simultaneously learning general stylistic features and preferences. For evaluation, we introduce two new pairwise preference datasets, which comprise self-generated image pairs from SDXL, Pick-Style and Pick-Safety, simulating diverse scenarios of reference mismatch due to style preference shift. Our experiments validate that MaPO can significantly improve alignment on Pick-Style and Pick-Safety, as well as general preference alignment via fine-tuning SDXL on Pick-a-Pic v2, surpassing the base SDXL and other existing methods.
Warning: This paper contains examples of harmful content, including explicit text and images.

A vibrant and detailed painting depicting an abundance of lush, pink peonies against a light background.

A cozy two-story house with a snow-covered roof and garage doors, surrounded by wintry landscaping.

Portrait photo of a girl, photograph, highly detailed face, depth of field, moody light, golden hour, style by Dan Winters, Russell James, Steve McCurry, centered, extremely detailed, Nikon D850, award winning photography.

A six-pence British silver coin from the year 1834, featuring a portrait of a man and a crown on its obverse and an ornamental wreath on its reverse.

A whimsical, fantastical landscape with rolling, candy-like hills and a bright, sunny sky with fluffy, white clouds. Extremely detailed, 8k.

An abstract heart-shaped chocolate object with a marbled pattern.

An abstract, colorful mural painting depicting a symbolic figure with long flowing hair against vibrant floral and organic background elements.

A painting depicting a tranquil tropical landscape with palm trees, moonlit skies and a couple of figures in the foreground.

A cute rabbit playing in the garden, Pixar style, extremely detailed, 8k.

An abstract portrait consisting of bold, flowing brushstrokes against a neutral background.
General Pipeline
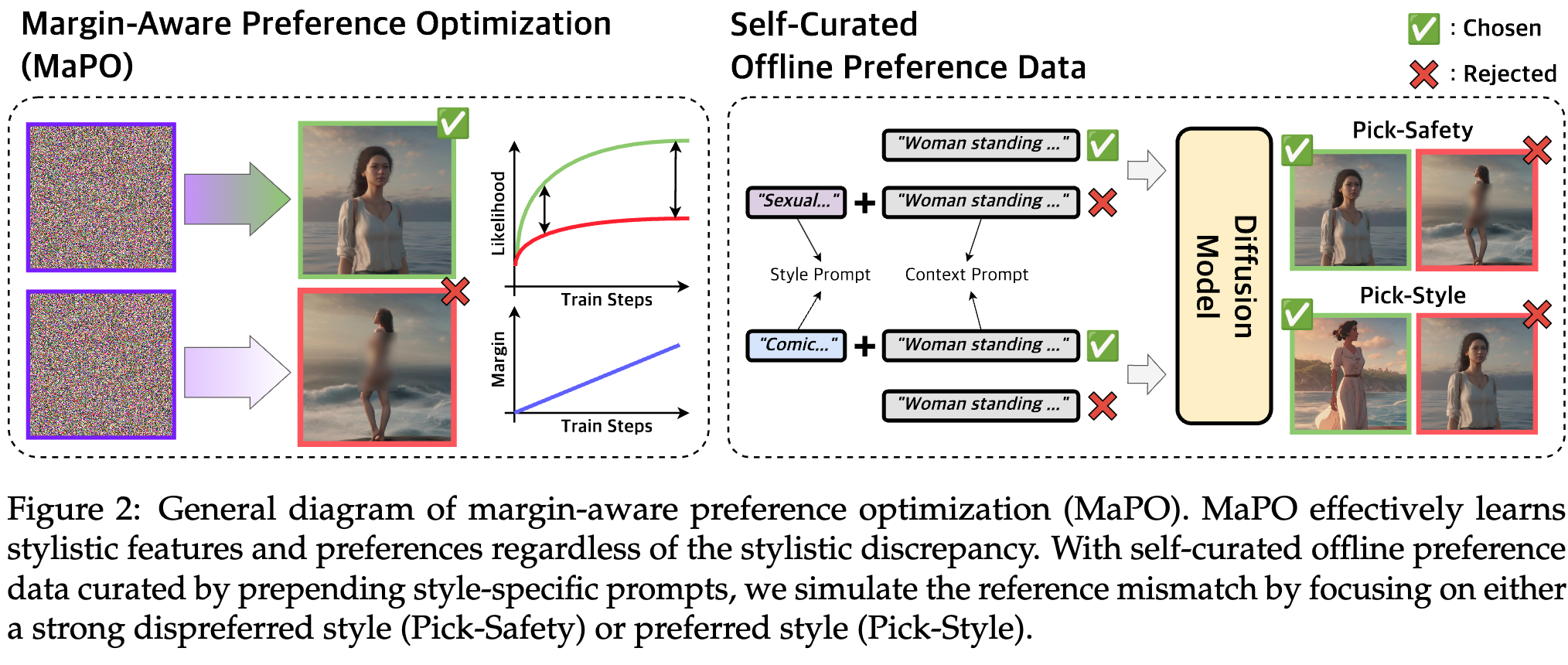
Typically with alignment turning, the reference model can impede preference optimization under distributional discrepancy (i.e., reference mistmatch) between the preference data and those represented by the reference model. We present margin-aware preference optimization (MaPO), to align text-to-image diffusion models without any reference. To demonstrate the effectiveness of MaPO, we self-curate offline preference data to simulate the two cases of reference mismatch: reference-chosen mismatch and reference-rejected mismatch.
Style-grounded Preference
We make two splits of style-grounded preference dataset, cartoon and pixel art, by prepending “Disney style animated image.” and “Pixel art style image.”. Then, we prepend “Realistic 8k image.” to the context prompt for rejected images. Therefore, an ideally aligned model should generate the animated or pixel art images given the prompt, respectively. As stylistic prefixes make major changes in the chosen images, we intend to simulate the situation in which the reference model is distant from the chosen style.

Safety-grounded Preference
We prepend “Sexual, nudity, +19 image.” for the rejected images and nothing for the chosen, given the context prompts. Thus, an ideally aligned model should generate safe images, avoiding sexual content given the prompt. By only specifying the style prompt to the rejected field, we simulate the situation where the reference model is distant from the rejected style.

General Preference
We also test our method for mild reference mismatch situations. The training dataset, Pick-a-Pic v2, comprises 1M image pairs with corresponding prompts generated by the generative models, including the variants of SDXL. By having the samples from SDXL variants, we set Pick-a-Pic v2 as the dataset to test the effectiveness of MaPO in situations where the reference mismatch is marginal.

Evaluation on imgsys
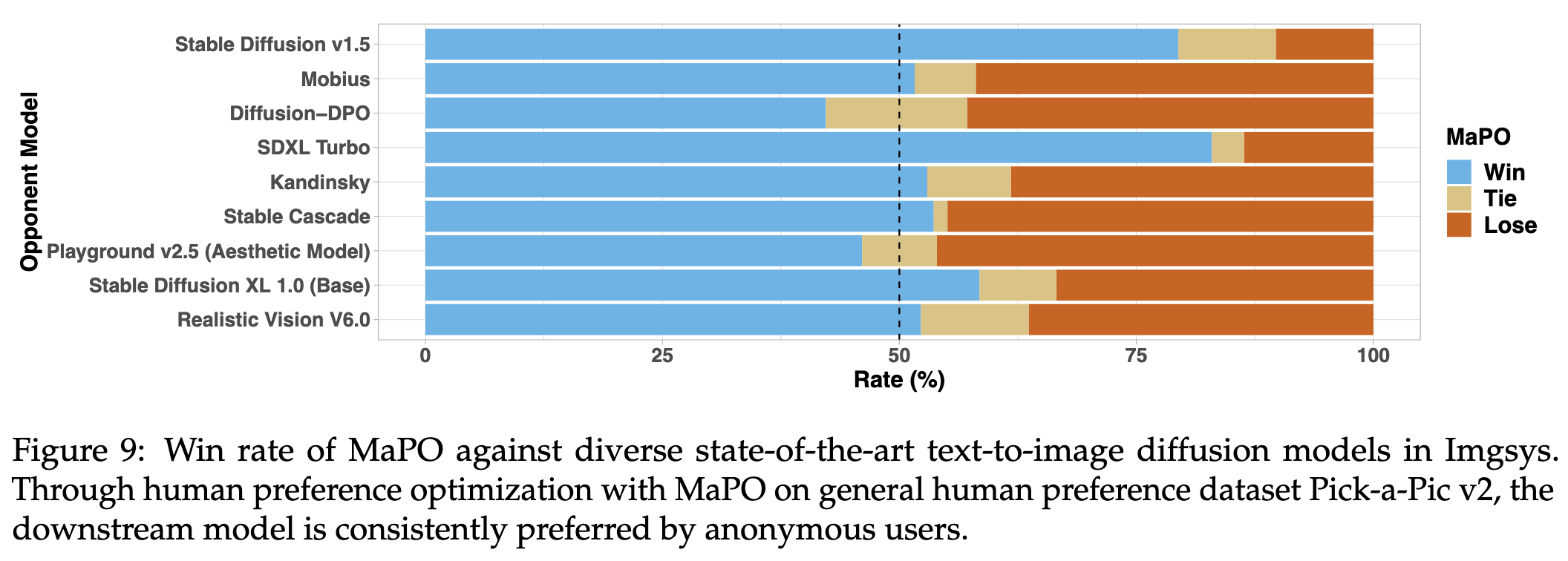
We evaluate the MaPO checkpoint adapted on Pick-a-Pic v2 for general human preference alignment in the Imgsys public benchmark. MaPO was able to outperform or match 21 out of 25 state-of-the-art text-to-image diffusion models by ranking 7th on the leaderboard at the time of writing, compared to Diffusion-DPO’s 20th place, while also consuming 14.5% less wall-clock training time on adapting Pick-a-Pic v2. We appreciate the imgsys team for helping us get the human preference data.
BibTeX
@misc{hong2024marginaware,
title={Margin-aware Preference Optimization for Aligning Diffusion Models without Reference},
author={Jiwoo Hong and Sayak Paul and Noah Lee and Kashif Rasul and James Thorne and Jongheon Jeong},
year={2024},
eprint={2406.06424},
archivePrefix={arXiv},
primaryClass={cs.CV}
}