Mandoline helps you evaluate LLMs based on what matters to users. Measure real user outcomes, compare performance across models, and turn abstract capabilities into meaningful insights across text, code, and vision tasks.
about
Measure what Matters
Most LLM evaluation approaches fall short in addressing the needs of practical, user-facing AI systems, leading to unreliable AI products and frustrated users.
Standard benchmarks don't predict real user success
General evaluations and test prompts don't tell you if users will actually succeed with your product. Mandoline helps you evaluate what matters: can users accomplish their goals? Our user-focused evaluation framework measures real-world task performance.
LLM behavior varies unpredictably across models and time
Different models handle the same prompts differently, and behavior can change with each update. Mandoline gives you insight into how models perform on your specific use cases, helping you catch issues early and make informed decisions about which models to use.
It's hard to know if changes really improved the product
Traditional A/B testing doesn't work well for LLM product development. Mandoline's LLM evaluation framework helps you measure the impact of prompt engineering, fine-tuning, and product changes. Know with confidence if your changes made things better or worse.
how?
How it Works
Mandoline offers a streamlined, three-step process designed to address the challenges of evaluating LLMs and ensure high-quality AI output.
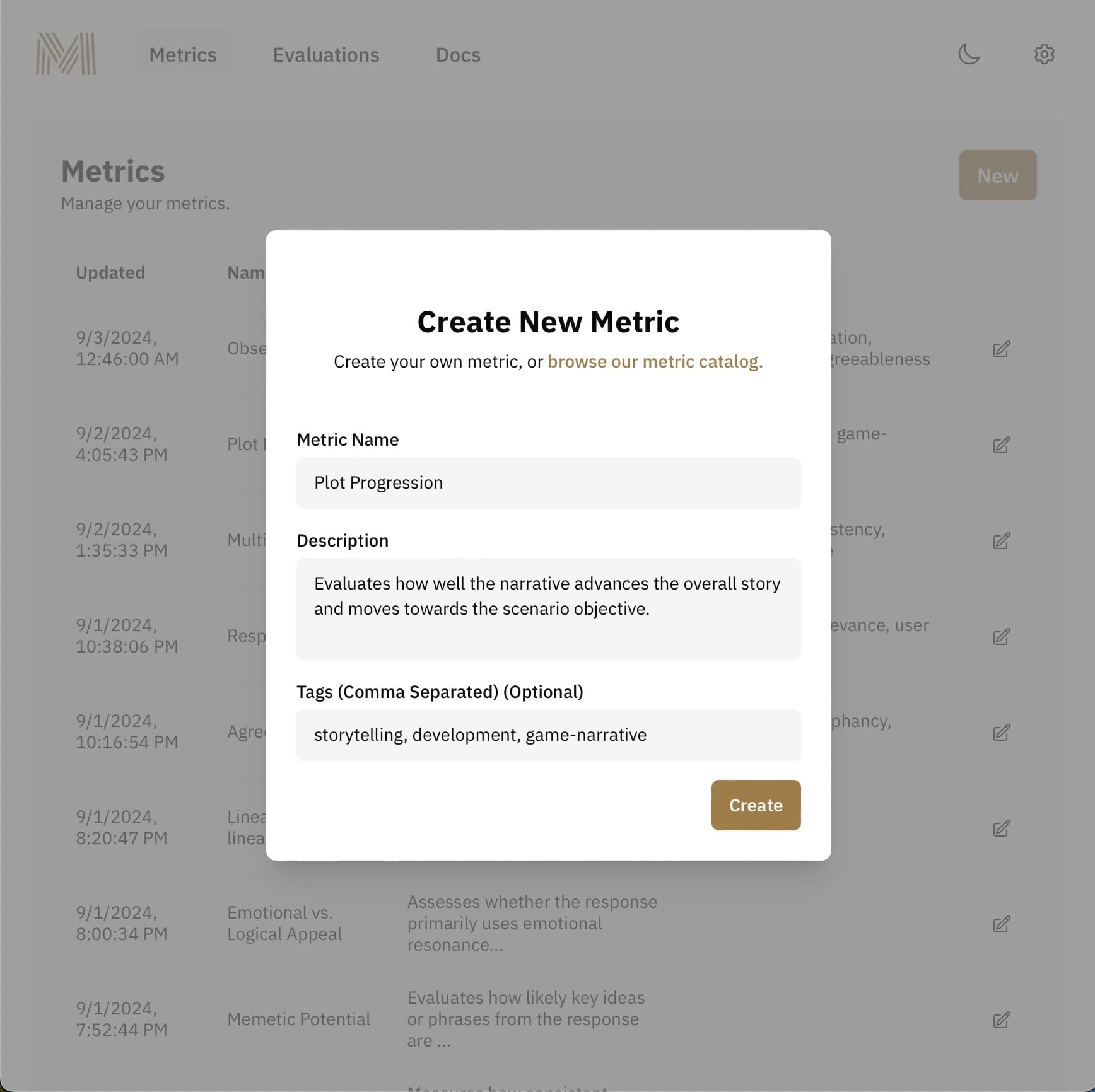
Design
using Mandoline's flexible metric system. Create and organize metrics that align with your specific product requirements. From optimizing game narratives to fine-tuning customer service bots, measure what matters to your users.
pricing
Simple, scalable, flexible pricing
API pricing by evaluation type.
EVALUATION TYPE | COST / EVAL ($) |
|---|---|
Text | 0.03 |
Vision | 0.04 |