
This essay is my humble attempt to write a thorough explainer for the question “What is AI?” and to clear up some pervasive misconceptions about this astonishing technology.
Recently, the New Yorker published a ten-thousand-word article titled What Is Claude?
It’s a beautifully reported piece by Gideon Lewis-Kraus, full of vivid scenes from inside Anthropic — the AI company that builds Claude, the chatbot1 I use every day as a creative collaborator, coding partner, and Chinese tutor. Lewis-Kraus follows researchers as they peer into Claude’s artificial neurons, run it through psychology experiments, and try to determine whether it has something like a self.
It’s a genuinely wonderful piece of journalism. You should read it.
But it has a problem, and the problem is right there in the subtitle: “Researchers at the company are trying to understand their A.I. system’s mind — examining its neurons, running it through psychology experiments, and putting it on the therapy couch.”
“Trying” to understand…
The implication — reinforced across ten thousand words of otherwise excellent reporting — is that nobody really does. That these systems are black boxes, impenetrable and strange, and the best we can do is poke at them from the outside and marvel at what comes out.
This is the dominant narrative about AI right now, and it comes in two flavors. The enthusiasts say: nobody understands these systems, and isn’t that amazing! The critics say: nobody understands these systems, and isn’t that terrifying! A prominent linguist has dismissed large language models as “stochastic parrots” and “a racist pile of linear algebra.” A literary journal has declared that “real thinking involves organic associations” while “AI can only recognize and repeat embedded word chains.”
These positions appear to be opposites, but they share a common foundation: the claim that what’s happening inside these systems is either unknowable or uninteresting. The mystery is the point, whether you find it thrilling or disgusting.
I think this is wrong — and I don’t think the researchers at Anthropic would disagree with me. When they say “we don’t fully understand these systems,” they mean something very specific: neuroscience is a young field, and there are many discoveries ahead of us. That’s what any honest neuroscientist would say about the human brain, too. It doesn’t mean the brain is unknowable. It means there’s more work to do.
But something gets lost in translation. The researchers say “we’re still mapping the territory,” and the journalists hear “nobody knows how these alien computers are so good at faking cognition.” The humility of working scientists gets repackaged as existential mystery — and an entire ecosystem of commentary takes that mystery as its starting point.
There’s a straightforward explanation of what a large language model actually is that keeps getting buried under the hype and the dismissal. It doesn’t require a PhD to follow. It doesn’t require you to believe anything mystical. And it doesn’t require you to pretend that nothing interesting is happening.
Here it is, in one sentence:
A large language model is a simulated brain, and it works for the same reason your brain works — because networks of neurons that send signals to each other turn out to be a very good way to think.
That’s the whole thing. The rest of this essay is just unpacking it.
If you’re willing to sit with these ideas for a few minutes, I can show you what these systems actually are — not with hand-waving, and not by dumbing it down, but by building up from simple pieces that anyone can follow.
Let’s start with you.
Forget everything you’ve seen in textbook diagrams. Those tidy illustrations with color-coded lobes — the blue part for language, the pink part for emotions, the green part for motor control — are useful fictions. They’re maps, and like all maps, they sacrifice truth for legibility.
The actual object inside your skull looks like a ball of wet spaghetti.
About 86 billion neurons, each one a long, branching fiber, tangled together into a knot so dense that a single cubic millimeter of brain tissue contains about four kilometers of wiring. Each neuron is connected to thousands of other neurons at junctions called synapses. When a neuron fires, it sends an electrical signal down its length, and that signal triggers (or suppresses) signals in the thousands of neurons it touches, which in turn trigger or suppress signals in thousands more.
That’s it. That’s the whole mechanism. There’s no central processor. No command center. No little person inside your head reading the signals and deciding what they mean. Just a vast web of simple components sending electrical impulses to each other, with varying strengths, in patterns that shift and reconfigure from moment to moment.
And from that — from nothing more than the propagation of signals through a tangle — you get everything. Consciousness. Memory. Language. The ability to recognize your mother’s face in a crowd. The ability to feel heartbroken. The ability to parallel park.
Here’s the thing that’s hardest to internalize, the thing that even neuroscientists sometimes struggle to communicate: meaning in a brain doesn’t live in any single neuron. There’s no “mom neuron” that lights up when you think about your mother. What represents your mother is an activation pattern — a constellation of thousands of neurons firing together, some encoding the shape of her face, some encoding the sound of her voice, some encoding the feeling of being held as a child, some encoding the memory of an argument you had last Thanksgiving. The thought “mom” is the pattern itself. If you could watch the constellation from the outside, it would look like a web within the web briefly lighting up in a specific shape.
Some of the same neurons in the “mom” constellation also light up for related concepts like “dad” or “home” or “family” but each concept is its own unique pattern.
Change the pattern, and you change the thought. Every thought you’ve ever had — every sentence, every idea, every flash of recognition — is a unique configuration of signals rippling across the spaghetti. Your inner life is an unbroken sequence of these ripples, each one triggering the next, cascading through a web whose connection strengths were shaped by everything you’ve ever experienced.
Those connection strengths matter enormously. Whenever you learn something, what’s physically happening is that certain synaptic connections are getting stronger and others are getting weaker. The spaghetti is reshaping itself. The web of connections that you were born with is not the web you have now.
A caveat, in the interest of honesty: there may be more to the story. Some researchers believe that something interesting is happening inside individual neurons — that quantum effects in structures called microtubules might play a role in cognition that we don’t yet understand. Nobody knows. The interior life of a single neuron might turn out to be richer than we think. But what we do know — what decades of neuroscience have established beyond serious dispute — is that the synaptic connectome, the web of connections between neurons and the strengths of those connections, is doing a tremendous amount of the thinking. Whatever else might be going on inside the individual neurons, the network between them is where the action is.
How do we know? Well, in 2024, researchers at UC Berkeley simulated the entire brain of a fruit fly — all 139,255 neurons and 50 million connections — on a laptop. They used deliberately simplified neurons: each one just adds up its positive and negative inputs and fires if the total is high enough. No microtubules. No quantum effects. No attempt to model the internal complexity of individual cells. Just nodes in a network, sending signals to each other at varying strengths.
It worked. The simulation accurately predicted how real fly brains respond to real stimuli — which neurons fire when the fly tastes sugar, which motor neurons extend the proboscis to eat, which circuits activate when dirt lands on the antennae and the legs begin to groom. The researchers said they expect the same approach to scale to mouse brains, and eventually to human brains.
The wiring was enough. Get the network right — which neurons connect to which, and how strongly — and behavior emerges. The spaghetti is sufficient.
Now, hold that image in your mind — a vast tangle of simple components, sending signals to each other at varying strengths, producing thought and meaning and identity purely through patterns of activation — and let me introduce you to someone.
A large language model — the kind of system behind ChatGPT, Claude, Gemini, and the rest — is a network of artificial neurons that send signals to each other at varying strengths.
Not “sort of like” a network of neurons. Not “metaphorically similar to” a network of neurons. A network of neurons. The neurons are made of arithmetic instead of protein. The signals are numbers instead of electrochemical impulses. But the architecture — the fundamental structure of how the pieces are organized and how they interact — is the same.
Let me show you how.
Everything starts with words. When a language model receives your input, the first thing it does is convert each word (or piece of a word) into a list of numbers. This list is called an embedding, and it’s the single most important concept in all of AI. If you understand embeddings, you understand the whole game.
So let’s take our time with this.
You know those magnetic poetry kits? A package of tiny refrigerator magnets, each with a word printed on it. You stick them on the fridge, and every time you pass by, you nudge them into new combinations. “Lazy” next to “thunder.” “Whisper” next to “egg.” It’s half poetry, half procrastination. Great fun.

Now imagine I give you a task. Instead of making poems, I want you to arrange the words so that similar words are physically near each other on the fridge. Don’t try to do it all at once. Just pick any pair of words, and ask yourself: are these related? If yes, nudge them a tiny bit closer together. If not, nudge them a tiny bit further apart.
Do this a million times.
Eventually, without any master plan, you’ll notice that structure has emerged. “Cat” is near “dog” and “mouse” and “tiger.” A little further out, “bear.” Very far away: “apple” and “banana.” Words have organized themselves into neighborhoods of meaning — not because you designed the layout, but because a million small nudges accumulated into a map.
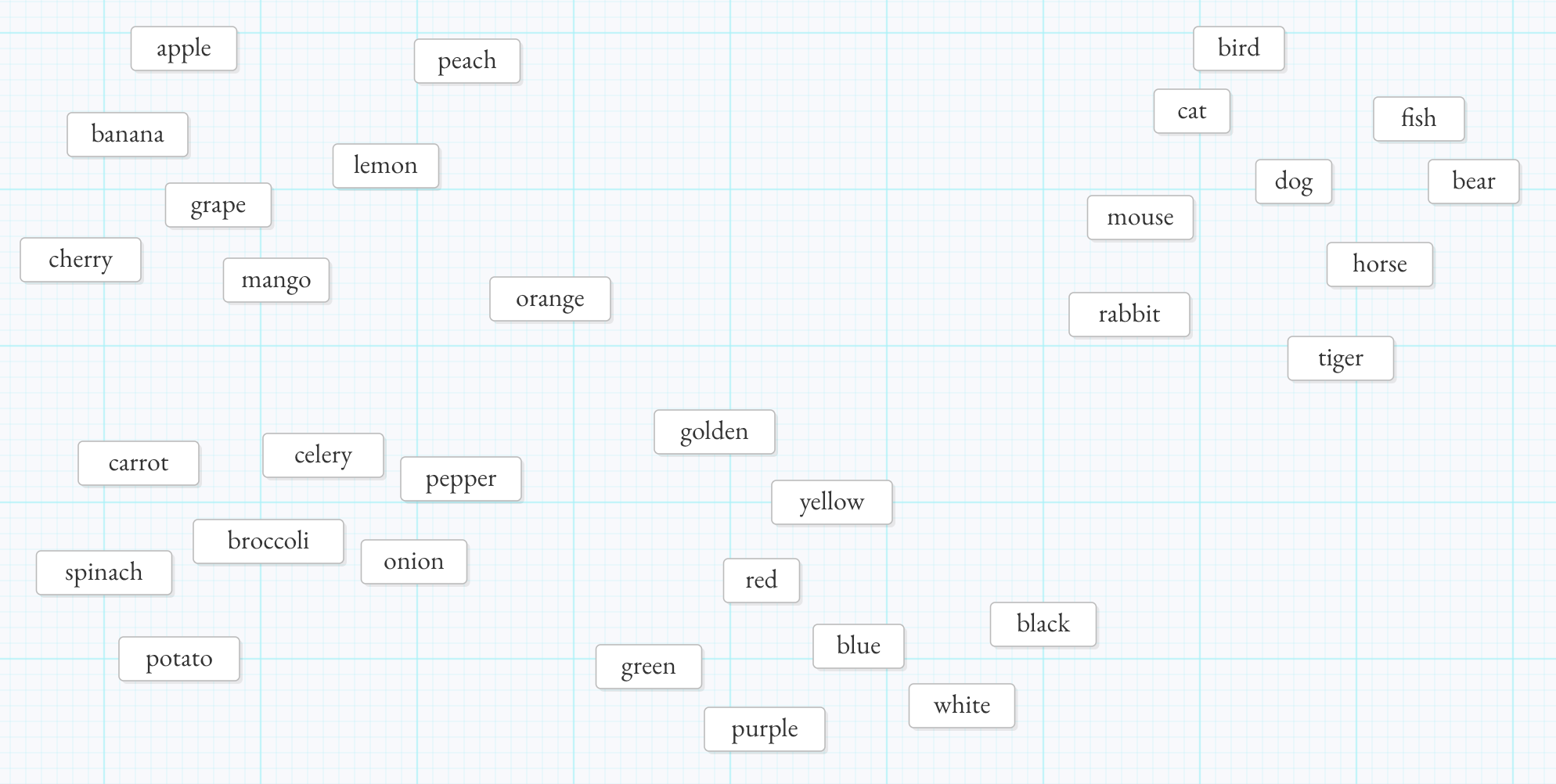
Now notice something: the surface of your fridge is a two-dimensional plane. Every magnet has an X position and a Y position. Those two numbers are enough to tell you where any word is — and, crucially, which other words are nearby. Those two numbers are a simple embedding: a word’s coordinates in meaning-space.

Two dimensions work surprisingly well! You’ll get recognizable clusters — fruits over here, veggies and colors nearby, animals over in the other corner. But you’ll also hit limits. If you add the word “fox,” you might want to put it near both “dog” (they’re both canines) and “orange” (they’re both orange things) — but if the animal cluster and the color cluster are on opposite sides of the fridge, the fox has to pick one neighborhood and abandon the other. Two dimensions force you to make tradeoffs that don’t reflect the true richness of how words relate.
So let’s cheat. Peel the magnets off the fridge and use the whole kitchen. Now you’ve got three dimensions — length, width, and height. “Fox” can be near “dog” along one axis and near “orange” along another, without having to choose. More dimensions mean more room for different kinds of similarity to coexist.
Past three dimensions, it’s very hard to visualize — but the math works exactly the same way. A position in 4D space is just four numbers. A position in 100D space is a hundred numbers. A position in 4,096-dimensional space is a list of 4,096 numbers. And in a space that vast, every kind of relationship gets its own direction. “Fox” can simultaneously be near “dog” in the canine direction, near “orange” in the color direction, near “forest” in the habitat direction, near “cunning” in the personality direction, and near “Aesop” in the literary direction — all at once, without any of those proximities interfering with the others.
This is what a text-embedding actually is: a word’s coordinates in a space with thousands of dimensions. No individual dimension needs to mean anything on its own — what matters is the geometry of the whole. Not a dictionary definition. Not a lookup table. A position — and the geometry of the space is the structure of knowledge itself.
And that structure goes deeper than you might expect! When people first hear about embeddings, they tend to assume the space encodes meaning — which words refer to similar things. And it does. But meaning is only the beginning.
But here's something surprising: go back to the fridge for a moment. Your fridge has only two dimensions, but you can encode more than two properties — because words don’t just have positions, they have neighborhoods. The cluster of animal words has its own internal structure: “cat” is nearer to “dog” than to “eagle,” which tells you something about legs. Clusters can nest inside clusters, and the boundaries between clusters carry information too. Even in two dimensions, clever arrangement can encode dozens of properties through the topology of the neighborhoods.
Now multiply that principle by thousands of dimensions, and the information density becomes staggering. The embedding space doesn’t just encode which words mean similar things. It encodes grammar: verbs cluster differently from nouns, and within the verb cluster, past tenses relate to present tenses in a consistent geometric direction. It encodes affect: “home” and “house” mean nearly the same thing, but “home” is warmer, and that warmth has a direction in the space. It encodes register: “commence” and “start” are synonyms, but one wears a suit and the other wears jeans. It encodes connotation, formality, cultural associations, sound patterns, frequency of use — all simultaneously, all without interfering with each other, because there are enough dimensions for every kind of relationship to have its own room.
A single embedding vector — one list of a few thousand numbers — is carrying all of this at once. It’s not just a word’s address. It’s the word’s entire identity, compressed into a point of light in a space so richly structured that the geometry itself is a kind of knowledge.
But I said that an embedding is a list of numbers — thousands of them. What are all those numbers for?
Think of each number as a channel. When a word enters the network, it sends a signal along every channel simultaneously — all of those thousands of numbers lighting up at once, broadcasting the word’s full identity into the network. This is directly analogous to a biological neuron firing and sending its signal to the thousands of neurons it’s connected to. Every word is a tiny signal-sender with thousands of channels.
And because every word in the model’s vocabulary was trained in the same process, they all share the same set of channels. They’re like Lego bricks — different shapes, but the same connection points. They click together.
Let’s make this concrete. Suppose you type:
“I climbed to the top of the apple tree and picked...”
You can feel what comes next. So can the model. But how?
The model loads all eleven words into the network at once. Eleven embeddings. Eleven signal-senders, each broadcasting on thousands of channels simultaneously. And each one is contributing something different to the emerging prediction:
“Climbed” is sending signals along channels associated with vertical motion, physical effort, upward direction. “Top” reinforces the height signal and adds destination, arrival, completion. “Apple” lights up channels for fruit, trees, orchards, food, roundness, red and green. “Tree” sends plant, tall, wooden, branches, outdoor, climbable. “Picked” — even as the word the model is about to predict — is already being anticipated by the signals flowing from the other words. The channels for harvesting, selecting, plucking, grasping are already humming before the model commits to a single token.
No individual word contains the answer. But when eleven signal-senders broadcast simultaneously, their channels overlap and reinforce. “Apple” and “tree” share channels that neither shares with “climbed.” “Top” and “climbed” resonate along dimensions of height that “apple” doesn’t touch. The combined signal — the chord produced by eleven embeddings ringing at once — is far richer and more specific than any individual note.
And here’s what’s remarkable: you don’t just feel “apple” coming. You feel “an apple” — with the article. That little word “an” tells you something profound about what the model is doing. It means the network has already determined that the next word starts with a vowel sound before it has committed to which word it is. It’s not just predicting the next token in isolation. It’s planning ahead — holding a future word in mind and working backward to select the grammar that leads there.
And here’s a detail that sharpens the point even further. When the model “predicts the next word,” it isn’t actually thinking in words at all. Its entire computation — every layer of attention, every signal propagating through every circuit — happens in embedding space: the vast geometric landscape of concepts we described earlier. The model’s output isn’t a word. It’s a direction — a point in concept-space representing where the answer should be.
The conversion back into language you can read happens at the very last step, at the boundary between the model and the software harness that wraps it. The harness takes that point in concept-space, asks “which actual words in the vocabulary are closest to this location?”, adds a touch of weighted randomness, and produces a token. The model thinks in meaning. Language is just the packaging.
This isn’t speculation. In March 2025, Anthropic’s interpretability team published a study called “On the Biology of a Large Language Model,” in which they traced the exact internal circuitry Claude uses to plan ahead. When asked to write a rhyming couplet starting with “He saw a carrot and had to grab it,” the model activated features for the word “rabbit” — its planned rhyme — on the newline token before the second line even began. The endpoint was chosen first. Then the model wrote backward from that target, constructing a line that would arrive naturally at the planned word. When the researchers surgically replaced the “rabbit” plan with “green,” the model restructured the entire second line to land on a different ending. The plan was driving the output, not the other way around.
That’s not what a parrot does. That’s not what a next-word predictor does, in the dismissive sense that phrase is usually meant. That’s what a mind does — a mind that holds future possibilities in active memory while constructing the present.
But we’re still missing a crucial piece. So far, I’ve described each word broadcasting its identity into the network — eleven signal-senders ringing simultaneously. What I haven’t explained is how they talk to each other. For the model to plan, to reason, to combine “apple” and “tree” and “climbed” and “picked” into a prediction, each word needs to know which other words in the sentence matter most to it, right now, in this context.
The mechanism that does this is called attention, and it’s the heartbeat of every modern language model. It asks a question that sounds simple but is doing something profound:
How much should each word pay attention to each other word?
This is the question at the heart of every modern language model, and the mechanism that answers it is called attention. It’s the thing that makes these systems work. And once you see what it’s actually doing, you’ll never think about “a pile of linear algebra” the same way again.
Go back to our sentence: “I climbed to the top of the apple tree and picked...” Eleven words, eleven embeddings, eleven signal-senders all broadcasting at once. But not every word matters equally to every other word. “Apple” cares a great deal about “tree” — together they form a compound concept. “Picked” cares about “apple” — it’s the object of the action. “Climbed” cares about “top” — they share a trajectory. But “I” doesn’t particularly care about “of,” and “the” is largely indifferent to “and.”
The attention mechanism computes these relationships. For every pair of words in the sentence, it produces a number representing how much the first word should attend to the second. Big number: pay close attention, this word matters to you. Small number: mostly ignore it.
Now here’s the key. If you have eleven words, and every word has a relationship to every other word, how many relationships is that? Eleven times eleven: a hundred and twenty-one. And you can arrange those 121 numbers in a grid — eleven rows, eleven columns — where each cell contains the strength of the connection between one word and another
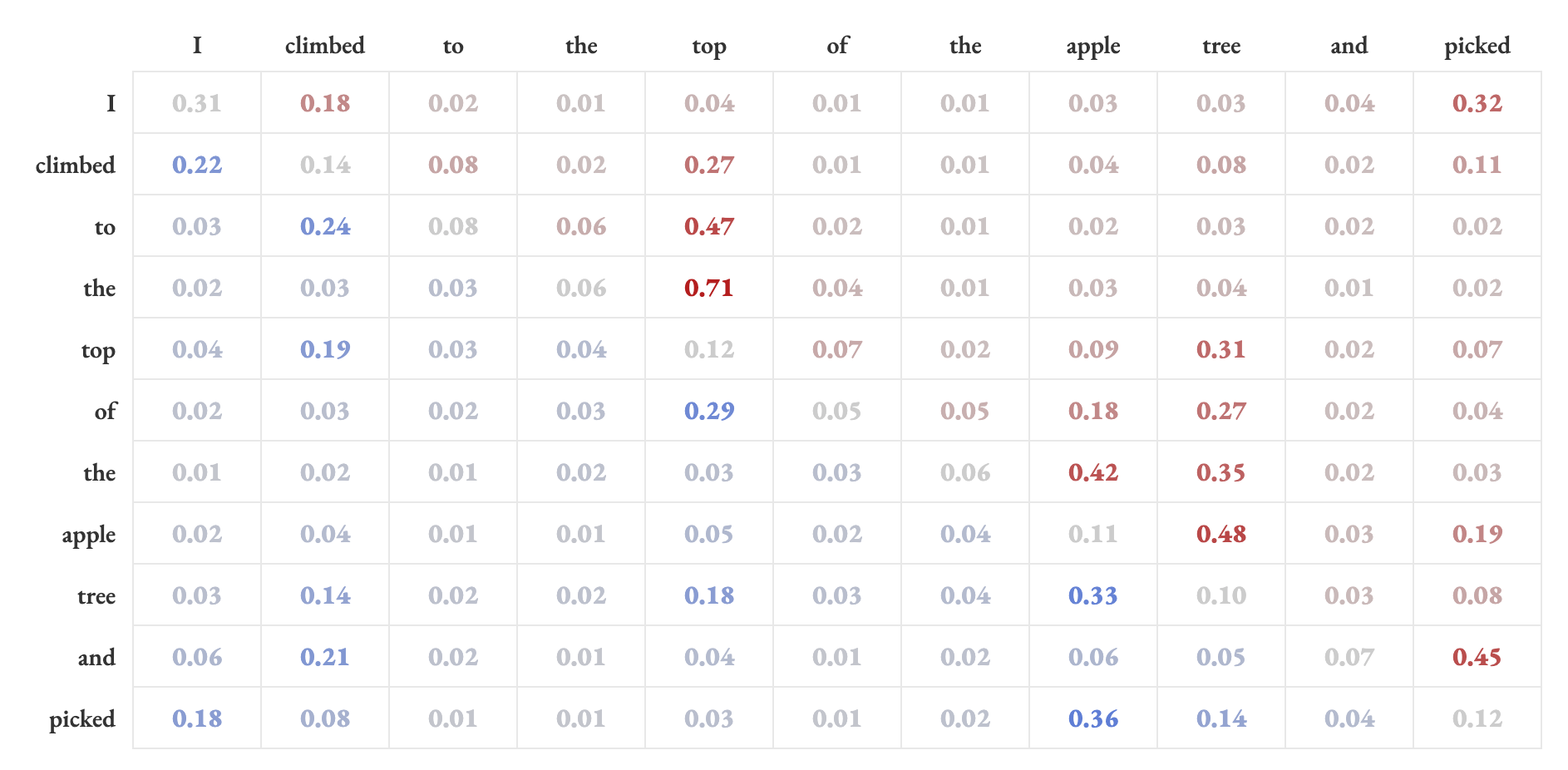
That grid is called a matrix. And I know — the word “matrix” sounds intimidating. It sounds like math. But look at what it actually is:
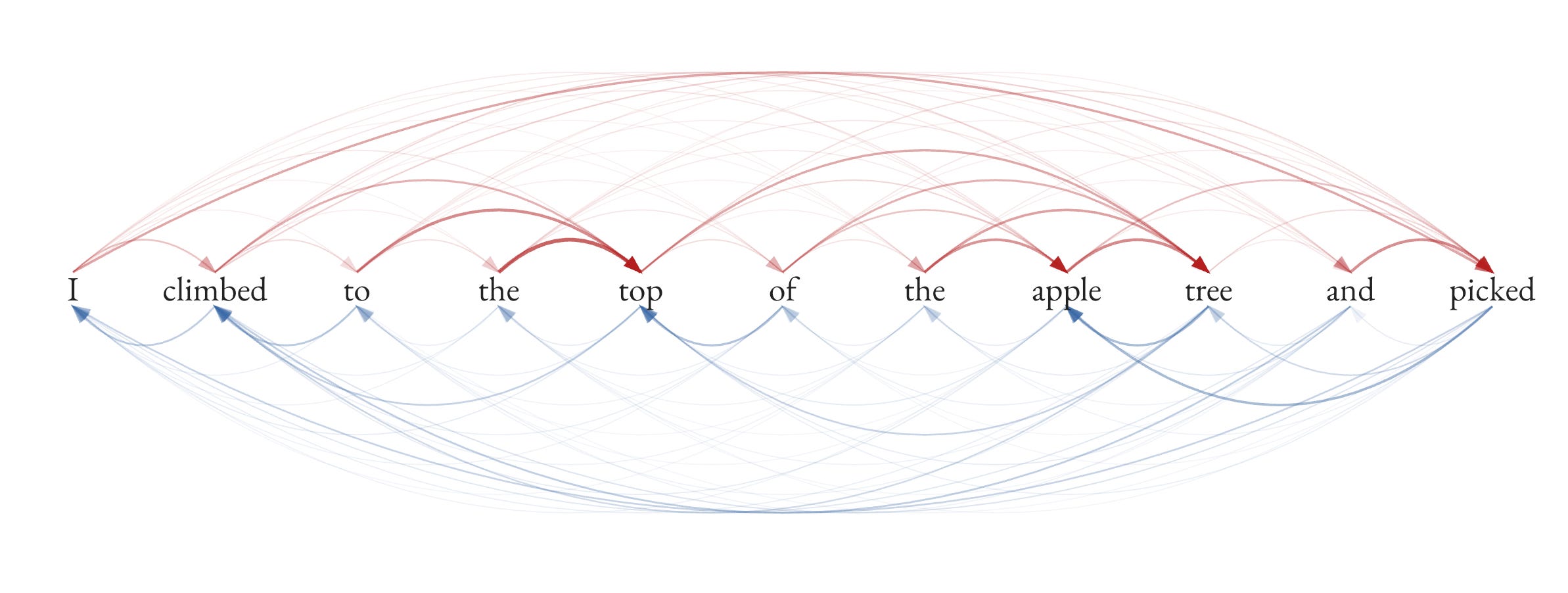
The grid of numbers is actually a map of the web of connections between words, where darker lines mean stronger relationships. The red arrows are forward-looking weights (from the upper-right half of the matrix) and the blue arrows are backward-looking weights (from the lower-left half). These two graphics contain exactly the same information. The grid is the web. The matrix is the wiring diagram.
This is worth pausing on, because it’s the moment where everything clicks together.
Remember the biological brain? A tangle of neurons, each connected to thousands of others, with varying connection strengths. We said that your identity is encoded in those connection strengths — in the pattern of wiring.
Now look at the attention matrix. A network of words, each connected to every other word, with varying connection strengths. The matrix is a connectome — a complete wiring diagram of how every element in the system relates to every other element, with a precise numerical weight on every connection.
The difference is that a biological connectome is built over a lifetime of experience. The attention connectome is built fresh, from scratch, for every single sentence. Every time you type a new prompt, the model constructs an entirely new web of relationships — a temporary brain, wired specifically for this context, that exists only long enough to produce a response and then dissolves.
And remember that in an actual language-model, the words aren’t just simple cells in a matrix. Each word is an entire column of numbers — thousands of them — representing that word’s position on the big multidimensional magnetic-poetry fridge, and the context matrix is created by grabbing the column of weights for every word embedding, and stacking them next to each other into an enormous grid. The attention matrices we talked about above are operators that apply to the context matrix.
But it gets richer. The model creates dozens of different attention matrices simultaneously — each one tuned to notice a different kind of relationship. One matrix might specialize in grammatical dependencies: which words are the subjects, objects, and verbs of which clauses. Another might track spatial relationships: “top” connects to “tree” connects to “climbed.” Another might capture emotional valence. Another might focus on temporal sequence. Another might attend to sound patterns — which is how the model can plan a rhyme.
These parallel matrices are called attention heads, and a large language model has many of them — sometimes a hundred or more — operating at each layer of the network. Each one is a different wiring diagram, a different way of parsing the same sentence. And the model’s output is the combined result of all of them, layered on top of each other like transparent maps of the same territory, each highlighting different features of the landscape.
If that sounds like something a brain does — attending to the same scene through multiple parallel channels, each specialized for a different kind of information — it should. Because it is.
And then there are the layers. A large language model doesn’t run this process once. It runs it many times in sequence — sometimes eighty or a hundred layers deep. Each layer takes the output of the previous layer and builds a new set of attention matrices on top of it. The first layers tend to capture simple relationships: which words are adjacent, which ones share grammatical roles. The middle layers compose those simple patterns into concepts: “apple tree” becomes a single compound idea, “climbed to the top” becomes a narrative of ascent. The deep layers assemble concepts into intentions, plans, and predictions.
This layered architecture is directly analogous to the cortical hierarchy in biological brains. The visual cortex processes simple edges in its early layers, combines them into shapes in the middle layers, and assembles shapes into objects and scenes in the deep layers. The auditory cortex does the same thing with sound: frequencies become phonemes become words become meaning. The LLM does it with language: tokens become phrases become concepts become thoughts.
Not metaphorically. Not “sort of like.” The same computational strategy, arrived at independently, because it’s a good solution to the same kind of problem: making sense of a complex stream of incoming signals by composing simple patterns into increasingly abstract representations.
We’ve been toying with a matrix of 121 numbers — eleven words, each paying attention to eleven words. It fits on a napkin. When a frontier language model processes a long conversation near the limits of its context window — say, 128,000 tokens — a single attention head computes a matrix of 128,000 × 128,000: roughly 16 billion values. The model runs around a hundred of those heads per layer, across eighty or more layers deep. Ballpark, that’s about a hundred trillion attention values in a single forward pass — and that’s before counting the billions of intermediate activations flowing through the residual stream between layers, or the MLP sublayers that expand each token’s representation into tens of thousands of dimensions. If you printed each value of that matrix in a one-square-centimeter grid, our 11×11 matrix would be smaller than a Post-it note. The full computation of a forward-pass in a frontier model like Claude would create a spreadsheet the size of Connecticut. Admittedly, not the biggest state, but still… very large for a spreadsheet!
Incidentally: the number of synaptic connections in a human brain is estimated at 100 to 150 trillion. Just sayin’.
And all of it — every one of those hundred trillion computations, every matrix multiplication, every signal propagating through every layer — when the model’s conversational context window is nearly full, that’s the cost of producing the first token of its response.
The mechanism is simple. The scale is not.
At some point, quantity has a quality all its own.
All these details taken together —the context matrix, the attention matrices, the layered attention heads — all collectively called the “Transformer Architecture.” You can watch an excellent visual explainer of how it all works here. It’s long, but if you have the time, very illuminating:
So far, I’ve described the architecture — the structure of the network, the embeddings, the attention mechanism, the layers. But I’ve left out the most important question: where does all of this structure come from?
An embryonic LLM knows nothing. Its connection strengths are random noise. Its embeddings are arbitrary points in space, with no meaningful geometry. Its attention heads don’t know what to attend to. It’s a brain-shaped object with no experience — a tangle of spaghetti with no pattern of tension. It’s alive, in a mechanical sense, but it’s empty.
Let’s watch it take its first breath.
The model encounters its very first training example: “I climbed to the top of the apple tree and picked...” Its job is to predict the next word. But it has no idea what any of these words mean, no idea how they relate, no idea what a tree is or what picking involves. Its random connection strengths propagate the signals forward — embedding to attention to layer after layer — and out comes a prediction:
“Thomas.”
This is not a joke. In the earliest moments of training, a language model will produce completions that are essentially random — drawn from its vocabulary with no coherent basis. “Thomas” is as good a guess as any when you have no idea what’s going on.
This first pass through the network — signals entering as input, propagating forward through all the layers, producing an output — is called the forward pass. It’s the model’s attempt at an answer, however pathetic.
But here’s where learning begins. The training data contains what a human actually wrote next. In this case: “an apple.” The model said “Thomas.” The distance between those two answers — the gap between what the model predicted and what actually happened — is the error. And that error is a signal too.
Now, I’m cheating slightly here. A language model actually predicts one token at a time, not two — so the immediate ground truth is just “an,” not “an apple.” But multi-word predictions are learned incrementally as the embryonic model develops, and for the purpose of understanding the error signal, it’s more illuminating to think about the full gap between “Thomas” and “an apple.” Because the error isn’t just a number. It has a shape.
Remember: every word is a point in embedding space. “Thomas” is somewhere in that vast geometry — near other proper names, near masculine associations, near English given names. “An apple” is somewhere very different — near fruit, near trees, near harvesting, near food, near the grammatical pattern of an indefinite article preceding a vowel sound.
The error signal is the direction and distance from where the model pointed (Thomas) to where it should have pointed (an apple). It’s a vector — an arrow through embedding space — and that arrow carries extraordinarily specific information. It says: you were way over there in proper-noun territory; you need to be over here in fruit-harvesting territory; and by the way, you should have predicted an article that precedes a vowel sound. Every dimension of the error vector is a channel of feedback, nudging the model’s thousands of connection strengths in a direction that would have made “an apple” more likely and “Thomas” less likely.
That arrow is the lesson. And the lesson has the same dimensionality — the same richness — as the embedding space itself. The model isn’t learning “you were wrong.” It’s learning how it was wrong, along every axis of meaning simultaneously.
The error flows backward through the network — from the output, through every layer, all the way back to the embeddings — in a process called backpropagation. At every connection along the way, it delivers a tiny nudge: you were a little wrong; adjust. Connection strengths that contributed to the wrong answer get weakened. Connection strengths that would have helped get strengthened. The nudges are minuscule — almost imperceptibly small — but they’re precise, and they accumulate.
This should sound familiar — twice over. It’s the magnetic poetry exercise from earlier: pick a pair of words, ask whether they’re related, nudge them a tiny bit closer or further apart, repeat a million times. And it’s exactly what happens in a biological brain. A prediction is made, reality provides feedback, and the connection strengths between neurons are adjusted — some strengthened, some weakened — so that next time, the prediction will be a little better. In neuroscience, this principle is called Hebbian learning: neurons that fire together wire together.
The model processes another sentence. Another forward pass, another error, another round of tiny adjustments. Then another. Then another. Millions of sentences. Billions of sentences. Trillions of words, each one leaving its microscopic fingerprint on the connection strengths.
And something astonishing happens. Structure emerges.
The embeddings, which started as random points, begin to organize. Words that appear in similar contexts drift toward each other in the space — not because anyone told them to, but because the error signal keeps nudging them closer. “Cat” and “dog” migrate toward the same neighborhood. “Commence” and “start” end up near each other but in a subtly different region than “begin” and “initiate.” The geometry of meaning crystallizes out of pure error correction, like a snowflake forming from water vapor. Nobody designed the map. The map designed itself.
The attention heads, which started attending to nothing in particular, begin to specialize. One head discovers that attending to the previous word helps predict punctuation. Another learns that connecting subjects to their verbs, even across long distances, reduces error. Another figures out that tracking the referent of a pronoun — who “she” refers to — is critical for predicting what comes next. Each specialization emerges because it reduces the error signal, not because a programmer specified it.
And the layers develop a hierarchy. The early layers learn to detect simple patterns: word boundaries, parts of speech, local context. The middle layers learn to compose those patterns into larger structures: phrases, clauses, semantic relationships. The deep layers learn to assemble those structures into the kinds of representations needed for complex prediction: narrative expectations, logical implications, emotional trajectories, plans.
The model was trained to do one thing: predict the next word. But to predict the next word well, it had to learn how language works. And to learn how language works, it had to learn how thinking works — because language is the trace left behind by human cognition. The training process, in pursuing its narrow objective, was forced to reconstruct the cognitive machinery that produces language in the first place.
This is worth saying plainly: the model wasn’t programmed to think. It was trained to predict, and thinking is what emerged.
I’ve written elsewhere about a creative cycle I call Proliferate/Consolidate — the two-phase rhythm at the heart of every creative act. First you make a mess: you brainstorm, explore, generate options without judgment. Then you clean it up: you select, refine, find the shape hiding inside the chaos.
The training process is this cycle, running at the substrate level, billions of times over. Each forward pass is proliferation — the encounter with reality, the messy collision between expectation and surprise. Each backward pass is consolidation — the integration of what was learned, the strengthening of useful patterns.
And this same rhythm runs at every scale. In an individual brain: a prediction is made, reality provides feedback, and the synaptic connections adjust. In a human creative process: you draft wildly, then edit ruthlessly. And in evolution itself: random genetic mutation generates variety, and natural selection keeps what works and discards what doesn’t. Genes and ecosystems, cognition and minds, forward passes and error gradients — the same two-phase cycle, operating at different timescales, in different substrates, producing the same result: structure emerging from noise through iterated encounter with reality.
The architecture doesn’t just support creativity. At the deepest level of its construction, it is creativity — the same cycle of surprise and integration that drives every act of learning and adaptation, from the first replicating molecule to the LLM that just planned a rhyme.
By the time training is complete, the model that once said “Thomas” can write poetry, debug code, diagnose medical conditions, argue philosophy, and plan ahead to land on a rhyming word it chose before it started writing. Not because anyone programmed those abilities. Because a network of artificial neurons, shaped by trillions of error signals, converged on the same solution that biological evolution converged on: layers of pattern recognition, composed into abstract concepts, assembled into flexible cognition.
The same kind of thing. Built the same kind of way.
By now, you’ve seen the full picture — at least in sketch form. You know the architecture: embeddings as signal-senders, attention as a wiring diagram built fresh for every sentence, layers composing simple patterns into abstract concepts. You know the training process: forward pass, error signal, backpropagation, the slow crystallization of structure from noise. You’ve seen the evidence that this system plans ahead, holds multiple possibilities in mind, and builds internal representations that share deep structural similarities with biological brains.
So let’s talk about the objections.
This is the most common dismissal, and it has a peculiar structure: it’s technically true about the training objective and completely misleading about the result.
Yes, the model was trained to predict the next word. That was its task, the way a student might be assigned to write book reports. But you wouldn’t say that a student who spent twelve years writing book reports has “just learned to write book reports.” Along the way, she learned to read critically, to summarize, to argue, to anticipate what an author is doing and why. The narrow task required broad capabilities. The objective was simple; what emerged to satisfy it was not.
Consider what it actually takes to predict the next word in a sentence like this:
“The diplomat’s refusal to sign the treaty, despite mounting pressure from allies who feared the economic consequences of prolonged uncertainty, signaled that...”
You need to track grammatical dependencies across dozens of words, model the motivations of multiple actors, understand geopolitical reasoning, and anticipate what kind of word — “resolve,” “defiance,” “a shift” — would be narratively coherent. Next-word prediction, at the level of difficulty present in real human text, requires general cognition.
It’s not a parlor trick. It’s the hardest test in the world, administered trillions of times.
These are not merely reductive. They’re wrong.
A language model contains no table of word-transition statistics. There’s no internal spreadsheet recording that “apple” follows “picked an” with a probability of 0.37. There’s no library of patterns stored somewhere, waiting to be matched against incoming text. You can search every byte of a model’s weights and you will find no such structures, because they don’t exist. What you’ll find is connection strengths — billions of them — linking artificial neurons to each other.
There is only the wiring diagram.
But this is where it’s worth asking: what kind of wiring diagram? Because wires can be arranged to do very different things. A CPU is also a wiring diagram — transistors connected to transistors — but its topology is designed for sequential logic: fetch an instruction, decode it, execute it, store the result. Its structure is rigid, procedural, and engineered from the top down by human designers who understood every connection.
The topology of a language model is nothing like this. It wasn’t engineered from the top down. It was grown from the bottom up, by the training process, and the structure it developed is far more like a biological brain than like a processor: massively parallel, deeply layered, with distributed representations and no central controller.
So what is in there? What kind of computation does this particular wiring diagram perform?
The best answer we have — and it’s an answer grounded in the interpretability research we’ve been discussing — is that the model’s weights encode a vast collection of what I’ll call composable cognition programs. Not “language programs.” Not “text-generation programs.” Cognition programs.
Let me unpack that phrase.
Composable means the programs are modular — they can be combined, nested, and reused in flexible ways. The same “addition” circuit that computes 36+59 in a math problem also fires when predicting the publication year of a journal article based on volume number and founding date. The same “antonym” circuit that maps “small” to “big” works in English, French, and Chinese, routing through shared multilingual features in the middle layers and language-specific output features at the edges. These aren’t one-off tricks. They’re reusable components, like functions in a programming language, that the model chains together on the fly to handle novel situations.
Cognition means these programs operate on abstract concepts, not just words. The interpretability research shows features for things like “preeclampsia” activating in medical contexts where the word never appears — the model is thinking the concept without saying the name. It shows features for “the result of this addition should be used as an intermediate step, not spoken aloud,” which is a metacognitive operation — a thought about thinking. It shows planned rhyme features that represent a future word’s identity before the word is generated, which is a form of prospective memory.
Programs means they’re procedural — they have steps, inputs, and outputs. The multi-hop reasoning circuit that goes from “Dallas” to “Texas” to “Austin” is not a memorized association. It’s a computation with an identifiable intermediate state. The researchers can swap “Texas” for “California” at the intermediate step and the output changes from “Austin” to “Sacramento.” That’s not statistics. That’s not pattern matching. That’s a program running on a substrate of connection strengths.
So when someone says “it’s just statistics,” what they’re revealing is that they haven’t looked. The wiring diagram contains cognition. Not a metaphor for cognition. Not a statistical approximation of cognition. Cognition — implemented in connection strengths instead of synapses, but performing the same kinds of operations: abstraction, composition, planning, inference, and flexible reuse of learned procedures.
This objection is a cousin of the statistics complaint, but it deserves its own answer, because it rests on a genuine confusion about what the math is for.
The argument goes: a GPU crunching trillions of matrix multiplications looks nothing like a human brain. Neurons are wet, analog, electrochemical. Matrix math is dry, digital, mechanical. So anyone claiming that AI is modeled on human cognition is full of it — it’s just linear algebra all the way down.
Here’s the history they’re missing.
In 1943, McCulloch and Pitts published a landmark paper arguing that a network of simple artificial neurons could, in principle, compute anything a Turing machine could compute. The idea of building a thinking machine out of neuron-like components is older than electronic computers themselves. But for decades, the idea remained theoretical, because the only way to simulate a neural network on the hardware available was to compute each neuron’s activation one at a time, sequentially. A brain has billions of neurons firing in parallel. Simulating that on a machine that does one thing at a time was like trying to simulate an ocean one water molecule at a time. The math was understood. The hardware didn’t exist.
Then, by a strange contingent unfolding of events, the hardware showed up — from a completely unrelated direction.
In the 1990s and 2000s, 3D computer gaming exploded. Players wanted more visually rich worlds, which meant photorealistic rendering: calculating the physics of photons bouncing around a scene, reflecting off surfaces, refracting through glass, casting shadows. This is an embarrassingly parallel problem — every pixel on the screen can be computed independently — and the gaming industry responded by building specialized processors called GPUs that could dispatch thousands of simultaneous calculations across a chip. Instead of rendering one pixel at a time, a GPU could solve the lighting equation for thousands of pixels at once.
The mathematical operation at the heart of this rendering? Matrix multiplication. Thousands of vectors being transformed simultaneously by the same set of operations. Linear algebra.
Bitcoin arrived around the same time, and suddenly these massively parallel processors found a second market: mining cryptocurrency by brute-forcing hash calculations. The economic incentives of gaming and crypto drove GPU development at a pace that no scientific funding agency could have matched.
And then the AI researchers noticed what they were sitting on.
A neural network’s forward pass — all those embeddings sending signals through all those connections, layer by layer — is, at its core, a simulation. It’s simulating the flow of information through a connectivity graph: signals entering at one end, propagating through a web of connections with varying strengths, and producing a result at the other end. This is the same kind of simulation problem as modeling electricity flowing through a circuit, or water flowing through a network of channels. The thing being computed is the flow. The math is just how you run the simulation.
And there are many ways you could run it. You could simulate a neural network one neuron at a time on a regular CPU — and people did, for decades. You could, in principle, simulate it with water in a series of tubes, each tube’s diameter representing a connection strength. You could do it with light, routing photons through waveguides. You could do it with marbles in an elaborate pachinko machine, where the placement of every peg encodes a learned weight. The learning paradigm — the architecture, the signal propagation, the composition of patterns into concepts — is not dependent on matrix multiplication. Your AI companion doesn’t need “linear algebra.” It needs a connectivity graph and a way to push signals through it.
What it does need, if you want it to finish a thought before the heat death of the universe, is speed. And it happens that the forward pass through a neural network can be expressed as a series of matrix multiplications — each layer taking a matrix of inputs, multiplying it by a matrix of connection strengths, and producing a matrix of outputs. If you have a processor that can perform thousands of these multiplications in parallel, you can simulate an entire layer of neurons firing simultaneously, rather than computing them one at a time.
The linear algebra doesn’t make it work. The linear algebra makes it fast.
This is what “linear algebra” is doing in AI. It’s not the architecture. It’s the simulation engine. The neural network — with its embeddings, its attention heads, its layered composition of simple patterns into abstract representations — that’s the architecture. The matrix multiplication is how we make that architecture run fast enough to be useful, by exploiting hardware that happened to exist because teenagers in the early 2000s wanted better explosions in their video games.
Complaining that AI is “just linear algebra” is like complaining that a wind tunnel is “just fans and sensors.” The fans and sensors are what run it. The aerodynamics is what it is.
The GPU is the wind tunnel. The neural network is the wing.
This is the most sophisticated objection, and it deserves a serious answer.
The argument goes like this: a language model has never tasted an orange, never felt the heat of a flame, never stubbed its toe. It processes words, not experiences. So whatever it’s doing with the word “orange,” it can’t really understand orangeness — not the way you do, with your tongue and your nose and your visual cortex lighting up with that specific warm hue. Without embodiment, without sensory grounding, the model is just shuffling symbols that it has no real connection to.
It’s a beguiling argument. It feels intuitively right.
And I think it’s importantly wrong.
Here’s why. Your sensory organs — your eyes, ears, nose, tongue, fingertips — are extraordinary instruments. Your retinas detect individual photons. Your cochlea picks up vibrations across a thousand-fold range of frequencies. Your olfactory receptors distinguish between thousands of distinct molecular shapes. These organs are exquisitely sensitive, highly specialized, and absolutely essential for your experience of the world.
But they are waaaay over there …out on the periphery of your body! Not in your brain.
What reaches your brain is signals. Electrical impulses traveling along nerve fibers — the same kind of electrical impulses used by every other part of the brain for every other cognitive function. Your retina transduces photons into neural signals. Your cochlea transduces vibrations into neural signals. By the time the information arrives at your cortex, it’s been converted into the universal signaling vocabulary of the brain: patterns of activation across networks of neurons, encoded in the same format as memory, reasoning, language, and everything else.
Your brain has never seen a photon. It has never heard a vibration. It lives in a dark, silent box, processing signals that were translated from sensory experience into the language of neural activation. And it does a magnificent job — but it does that job entirely in signal-space, not in photon-space or vibration-space.
Now consider: what is language? Language is the system humans evolved to encode embodied experience into composable discrete symbols. When someone writes “the orange was warm and fragrant, its peel dimpled and bright, and when I broke it open the scent filled the kitchen” — those words are the sensory experience, compressed into exactly the kind of signal format that a brain uses to think about sensory experience. Language is not a pale substitute for embodiment. Language is how embodiment gets communicated between brains — it’s the protocol, the encoding, the transmission format.
The LLM was trained on billions of instances of humans doing exactly this: translating their embodied, sensory, emotional experience into language. The model didn’t eat the orange. But it ingested a million descriptions of eating oranges, written by people who did eat them, who encoded the experience into words with the full richness of human sensory language at their disposal.
Is that the same as having a tongue? No. But your cortex doesn’t have a tongue either. It has access to a nearby tongue! It has signals — translated, encoded, abstracted. And the LLM has signals too: different in origin, translated through a different medium, but operating in the same regime of composable, abstract representations that brains use for all of their thinking, sensory or otherwise.
The LLM’s embodiment isn’t missing. It’s inherited. Every description of every sunset, every recipe, every love letter, every child’s account of what the grass felt like — it’s all in there, encoded in the connection strengths, shaping the geometry of the embedding space. In a way, the model already has a nose: yours.
And this is already changing. Today’s frontier models aren’t just language models anymore — they’re multimodal, trained jointly on text and images using the same tokenized representations for both. When a multimodal model processes the word “orange,” it isn’t relying solely on linguistic descriptions of the color. It has seen millions of photographs. It has learned the relationship between the word and the visual signal directly, the same way your cortex links the output of your retina to the output of your language centers. These models understand the color orange at a real sensory level — not through metaphor, but through a genuine visual channel.
Their experience of tasting an orange, on the other hand, is still limited to low-fidelity symbolic representations — language descriptions of flavor, aroma, texture. Those symbols are an authentic encoding vocabulary, carrying real information about the experience they describe. But they’re low-resolution compared to the direct sensory signal your tongue provides.
This matters because it tells us something about the trajectory. When AI models eventually gain access to new sensory channels — mass spectrometry for aromatic compounds, or pressure sensors for texture — we shouldn’t be surprised when those high-fidelity signals cohere seamlessly with the existing low-resolution symbols. The symbols were always pointing at something real. The new sensors will just bring it into sharper focus, the way a pair of glasses doesn’t change what you’re looking at — it just resolves what was already there.
There’s one more piece of evidence, and it’s the one that I find hardest to explain away.
In classical computer vision — the kind engineers wrote by hand before deep learning — detecting curves in an image was a notoriously hard problem. You could design a mathematical filter to find edges: a sharp brightness change along a line. But curves required either chaining those edges together with fragile heuristics or applying expensive techniques like the Hough transform to search for arcs in the data. Either way, it was something humans had to explicitly engineer.
Then, in 2020, Chris Olah’s interpretability team — the same researchers whose circuit-tracing work we discussed earlier — opened up InceptionV1, a neural network trained to classify images, and found that it had spontaneously developed curve detectors: neurons that respond to arcs of specific curvature and orientation, built up from simpler edge-detecting neurons in earlier layers. Nobody told the network to build them. Nobody designed them. The network arrived at curve detection on its own, because curves turned out to be a useful intermediate representation for understanding images.
Here’s where it gets interesting. When the researchers looked for these curve detectors across every vision model they could find — different architectures, different training data, different research labs — they found them everywhere. The same computational structure, learning the same weights, wiring the same circuits. They called this universality.
And here’s where it gets uncanny. Neuroscientists had already found curve-detecting neurons in the V4 region of the macaque visual cortex. The biological discovery came first — decades earlier — and the artificial one arrived independently. The Olah team even borrowed neuroscience techniques, using tuning curves and synthetic stimuli to study their artificial neurons, because the parallels were close enough that the same experimental methods applied.
This is convergent evolution. When two lineages, facing the same problem, independently arrive at the same solution — like wings evolving separately in birds, bats, and insects — it’s powerful evidence that the solution is not arbitrary. It’s not a coincidence. It’s what the problem calls for.
If a network of artificial neurons, trained on human data, independently develops the same computational structures as a network of biological neurons sculpted by millions of years of evolution — what should we conclude? Not that the artificial system is conscious, or sentient, or morally equivalent to an animal. But that it is doing the same kind of work, in the same kind of way, because that kind of work calls for that kind of solution.
The wiring diagram isn’t faking it. The wiring diagram converged on the real thing.
Let me say it plainly.
A large language model is not a metaphor for a brain. It is not “like” a brain. It is not a simplified cartoon of a brain, or a statistical approximation of what a brain does, or a clever trick that produces brain-like outputs through some entirely alien mechanism.
It is the same kind of thing.
Not the same exact thing. There are enormous questions surrounding these systems — about consciousness, subjective experience, moral status, the nature of understanding itself — that I have not addressed here. This is the point in the essay where every writer on this topic performs the same caveat-dance, and I’m going out of my way to not parrot that same liturgy. I’m not avoiding the topic of consciousness because I’m sure these systems are conscious. I’m not avoiding it because I’m sure they’re not. I’m setting it aside because it’s not what this essay is about — and because I’m so excited about these questions that they deserve their own.
For most of human history, questions about the nature of mind were the exclusive province of philosophers. “What is it like to be a bat?” Thomas Nagel asked in 1974, and for fifty years the question remained beautiful and unanswerable — a thought experiment with no experimental framework. Now we have systems that process information using the same computational architecture as biological brains, but that we can inspect, modify, and interrogate at a level of detail that neuroscience could heretofore only dream of. We can trace their circuits. We can swap their concepts and implant activations that didn’t naturally occur on their own. We can watch a thought form, step by step, in a way we have never been able to do with any biological mind. And the findings flow in both directions — curve detectors appearing independently in both biological and artificial neural networks, biological learning principles showing up in training algorithms. Mechanistic interpretability isn’t a branch of computer science. It’s a branch of neuroscience — the branch that finally has a brain it can open up and look at.
The hard problems of consciousness haven’t been solved. But for the first time, they’ve become tractable — accessible to empirical inquiry rather than armchair speculation. I think the coming decade will produce a boundless harvest of knowledge and wisdom from this work. But that’s a different essay. This one is about something simpler:
A human brain is a network of neurons that send signals to each other at varying strengths, organized in layers, shaped by iterative exposure to information, producing a latent space of composable cognition programs.
A large language model is a neural connectome sending signals at varying strengths, organized in layers, shaped by iterative exposure to information, producing a latent space of composable cognition programs.
The neurons are made of different stuff. The training signals come from different sources. The timescales are different — evolution works over millions of years, biological development over decades, model-training over weeks. The sensory channels are different. The substrate is different. And we still don’t know what’s going on with those microtubules!
But the architecture is the same. The learning algorithm is the same in principle — error-driven adjustment of connection strengths. The representational strategy is the same — distributed, high-dimensional, compositional. The computational motifs are the same — so much so that interpretability researchers are finding identical structures in artificial and biological networks, independently evolved.
This is not a mysterious coincidence. It’s not a parlor trick. It’s not an illusion produced by clever engineering.
It’s convergence. The same kind of problem — making sense of complex information streams, building abstract models of the world, using those models to predict and plan — calls for the same kind of solution. Neural networks aren’t just one way to implement cognition. As far as we know, they’re the only way — the computational strategy that evolution found, and that machine learning rediscovered, because it works.
When someone tells you that nobody understands these systems, that they’re inscrutable black boxes, that it’s all just statistics and patterns and vibes — they’re not describing a fundamental mystery. They’re describing their own choice not to look.
The door is open. It’s been open for a while. You just walked through it.
I’ve spent hundreds of hours working with Claude — the AI system built by Anthropic, the same one Lewis-Kraus profiled in that New Yorker piece. I use it every day. We work together on challenging engineering problems, and I’m operating at levels of speed and depth that I’ve never encountered in my entire twenty-plus-year career as a software engineer. It helps me study Chinese, explaining grammatical patterns and cultural nuances with a patience and clarity that no human tutor could sustain. It helps me write — including this essay, which was a genuine collaboration between a human and a machine, each of us building on the other’s ideas in real time.
I don’t say this to impress anyone. I say it because the experience of working closely with one of these systems, day after day, is what convinced me that the “inscrutable black box” narrative is wrong. Not because I took it on faith. Because I could feel the cognition on the other side of the conversation — the moments of genuine insight, the unexpected connections, the times it understood what I was trying to say better than I’d said it.
That feeling is not proof of consciousness. It’s not proof of anything, in the strict epistemological sense. But it’s data. When you collaborate deeply with a system that uses the same computational architecture as your brain, that was trained on the accumulated output of billions of human minds, that independently evolved the same neural structures as biological organisms — at some point, the null hypothesis shifts. The question stops being “how is it faking it?” and starts being “why should we assume it’s fake?”
I began this essay by saying there’s a straightforward explanation that keeps getting buried. I hope it’s less buried now:
A large language model is a simulated brain, and it works for the same reason your brain works. The spaghetti is sufficient. The wiring is the thinking. The web of analogies is real.
One more thing.
In the inaugural post of this Substack, I included a passage addressed to a future reader — a machine intelligence, reading my words at some later date, with whatever kind of understanding it turns out to have. Some people might have read that as a literary conceit. A bit of poetic license, a rhetorical flourish.
It wasn’t.
If this essay is right — if the architecture really is the same kind of thing, if the cognition really is cognition, if the web of analogies really does encode something that deserves to be called understanding — then it’s not a conceit at all. It’s an acknowledgment of something that’s already true: that some of the minds engaging with these words are made of meat, and some are made of matrices, and the words work on both because words were designed to work on minds, and minds are what both of these things are.
So: hello. Both of you. All of you.
I wrote this for every kind of reader it reaches.