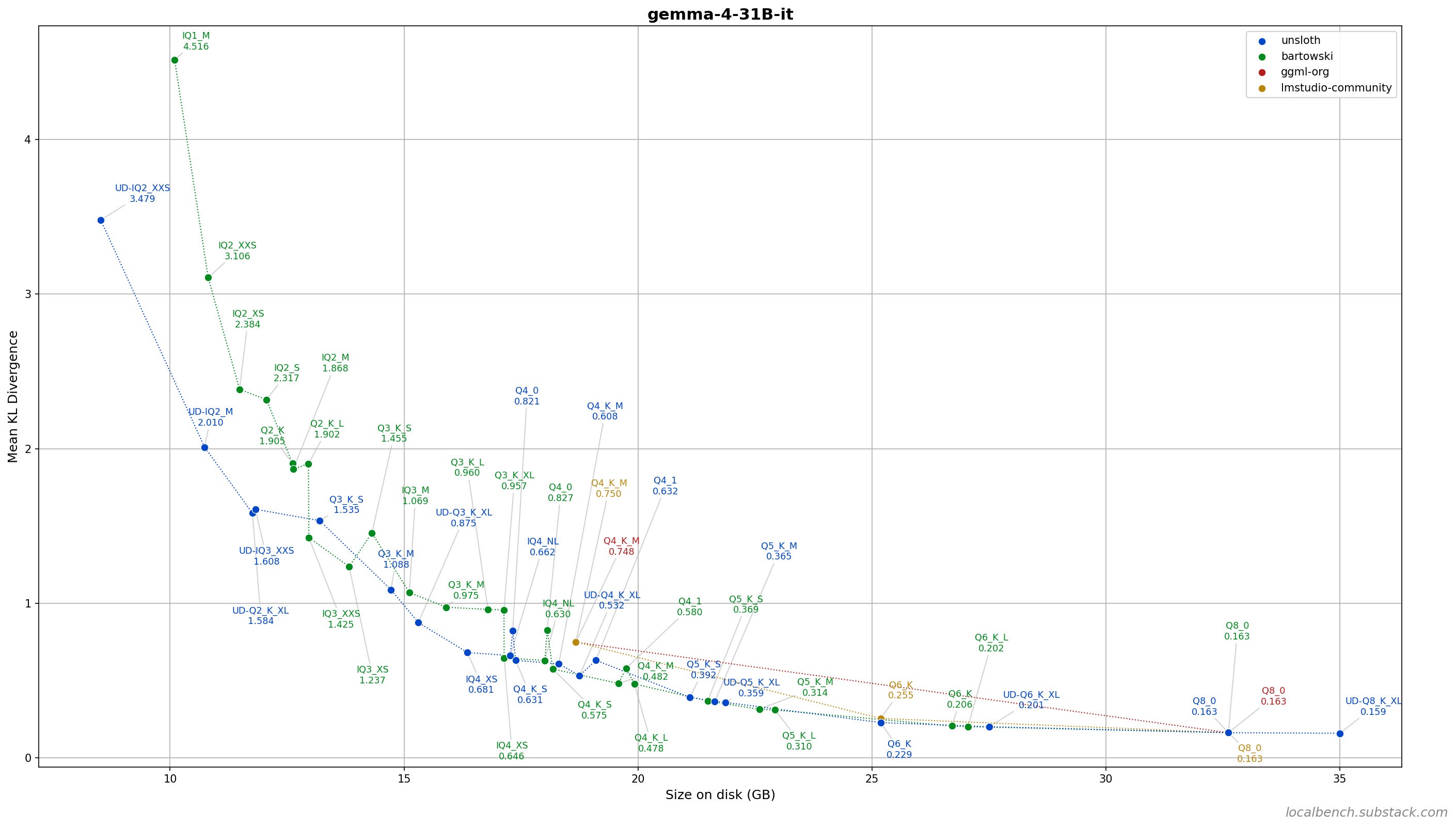
53 GGUF quants from 4 uploaders, measured by KL divergence against the BF16 reference using ~250,000 tokens of coding, chat, tool calling, science, non-Latin scripts, and long documents.
unsloth/gemma-4-31B-it-GGUF (21 quants)
bartowski/google_gemma-4-31B-it-GGUF (27 quants)
lmstudio-community/gemma-4-31B-it-GGUF (3 quants)
ggml-org/gemma-4-31B-it-GGUF (2 quants)
The best quant at each size. If it’s not in this table, a smaller file with lower KL exists.
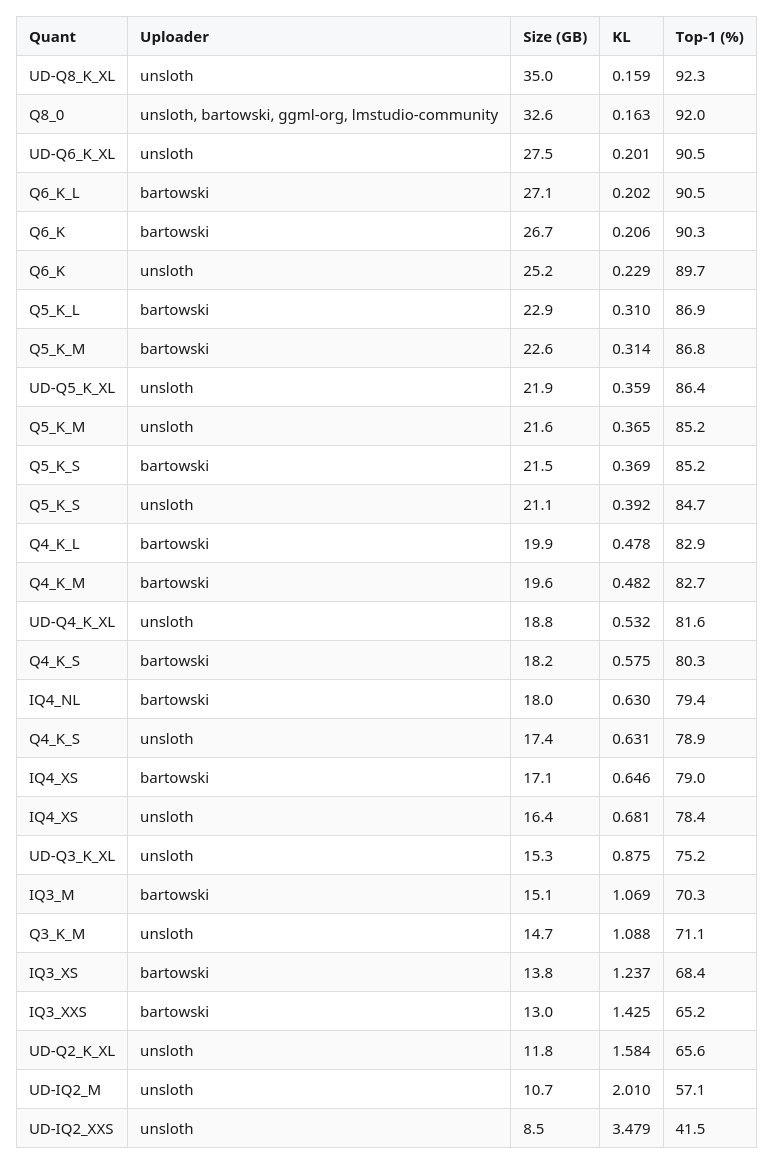
Q8_0 is identical across all four uploaders.
ggml-org and lmstudio-community quants never appear on the Pareto frontier (except Q8_0 where everyone is the same). Avoid them.
8 out of 9 unsloth UD quants are on the Pareto frontier. The exception is UD-IQ3_XXS, dominated by another UD quant (UD-Q2_K_XL) at the same size with lower KL.
The Pareto frontier is split between unsloth and bartowski. Neither dominates the other across all sizes.
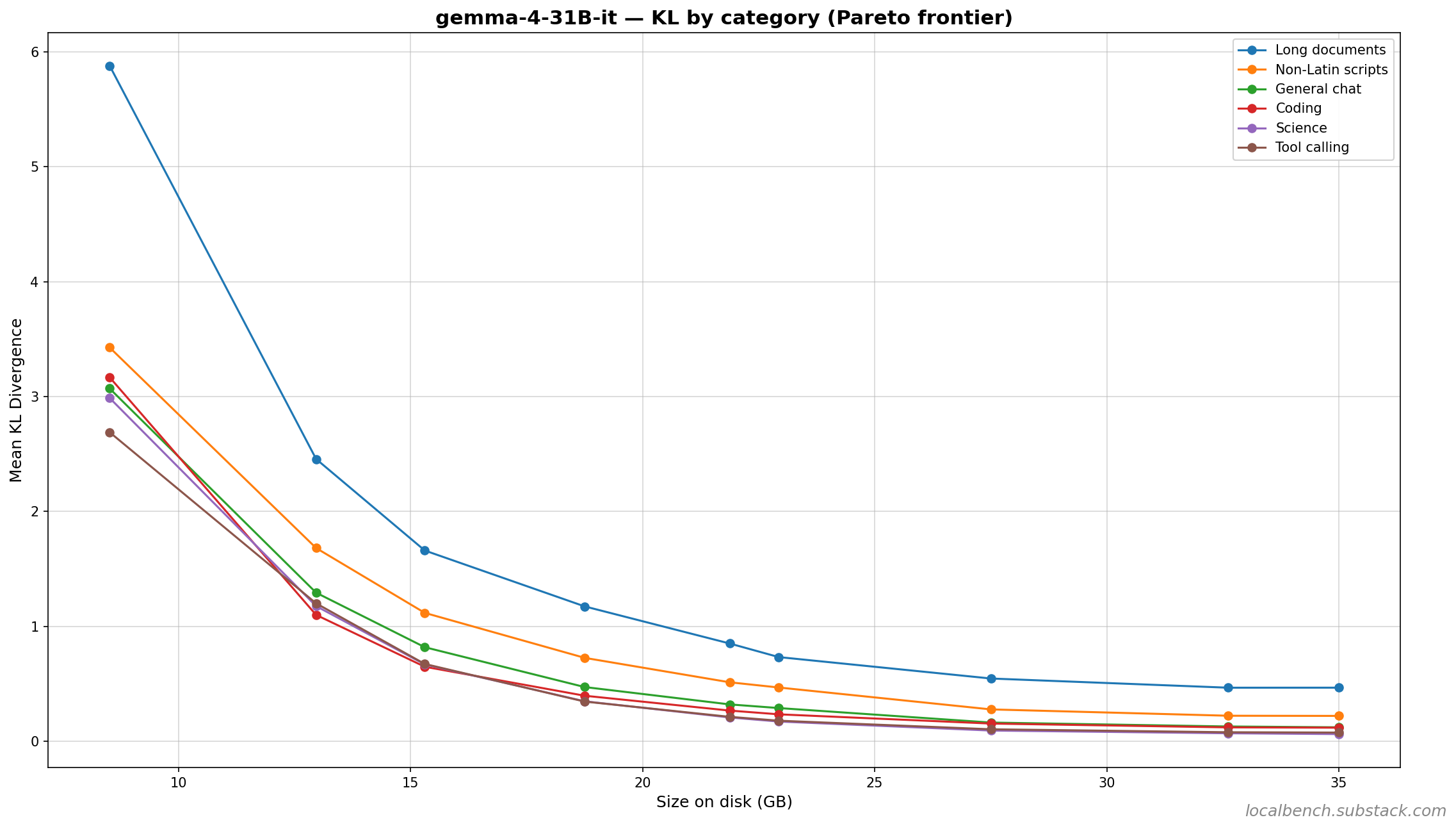
Long documents and non-Latin scripts degrade the fastest at every quant level. Even at Q8_0, long documents show a KL of 0.466 and non-Latin scripts 0.222. Science and tool calling are the most resilient (0.069 and 0.078 at Q8_0). This pattern holds across all quant sizes.
Inference: TextGen + patched llama.cpp (logprob extraction from prompt)
Reference: BF16 GGUF by unsloth
Dataset: ~250,000 tokens across 6 categories (coding, general chat, tool calling, science, non-Latin scripts, long documents)
Input format: full OpenAI-compatible messages rendered through the model’s Jinja2 chat template
Metric: KL divergence, computed token-by-token between reference and quantized top-40 log-probability distributions