Say you want to build your own LLM.1 One of the oldest practices in the book is to generate high quality synthetic data using a state-of-the-art model, and then use that as your training data.
This gives you:
- A lot of training data in mere minutes, without having to build your own data collection, web crawling (and so on) pipeline
- Really high quality data, since the model you are using to generate the data is probably the world's most powerful model
- Data specifically tailored for your use cases, which would require specialists, annotators, verifiers and all that, and is usually very expensive2
But, there's a catch. Say you use one of OpenAI's GPT models to generate your data. It turns out that you can't actually do that. OpenAI's Terms of Use are pretty clear on this. Under "What you cannot do":
"Use Output to develop models that compete with OpenAI."3
But, there is a workaround. You can take another model, say DeepSeek, which was almost definitely trained on GPT-4 data (to be clear, it says it's ChatGPT, smells like ChatGPT, and is being investigated for it)4, and then use that model to generate your dataset.
Why is that legal? Well, DeepSeek models use the MIT license and explicitly state:
"DeepSeek-R1 series support commercial use, allow for any modifications and derivative works, including, but not limited to, distillation for training other LLMs."
That's what I call token laundering. Just like the financial kind, you run restricted goods through a clean intermediary. In this case, your obligations are to DeepSeek (whose MIT license says "do anything, including train competitors"), and not to OpenAI.
Here is the idea in a figure:
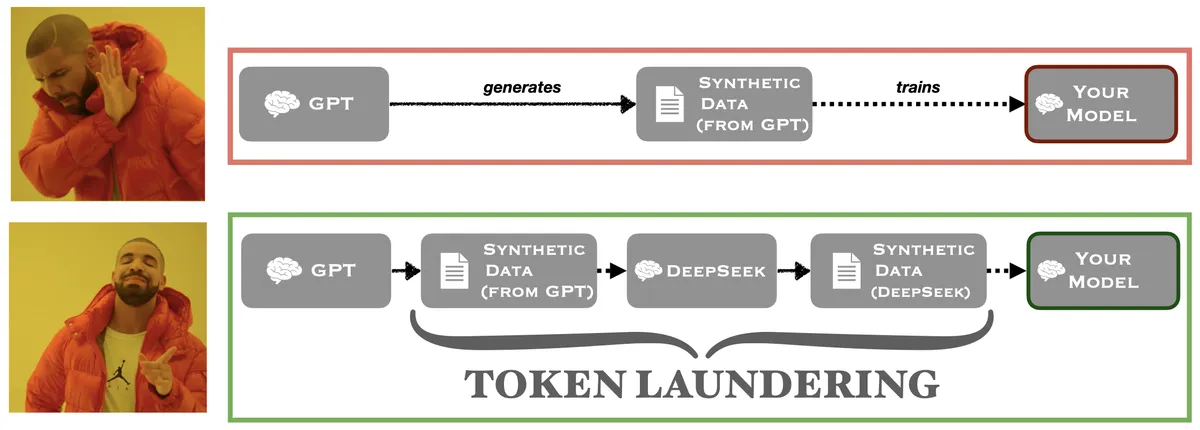
Other Instances of Token Laundering
This is not the only way to launder tokens. Here are some other ways to improve your training data quality without breaking any rules:
- The most obvious way:
- Step 1: Start a $10B company that does AI assisted web search or AI coding or something.
- Step 2: Have your users use some state of the art model at a very cheap cost to the users (so cheap you're bleeding money).
- Step 3: Store user data.
- TADA!
- Now your GPT or Claude generated data are actually customer data and you are probably free to do whatever you want with them. PROBABLY.
- A little more detailed:
- Hire human workers to generate datasets for you (e.g., Mechanical Turk).
- Pay very little money and make it clear in the task guidelines that using AI to do the task is fine.
- People will probably use ChatGPT to do their task and now you have GPT generated data.
Bonus: The "I Don't Remember" Defense
- The plausible deniability method:
- Step 1: Get really drunk.
- Step 2: Generate data using GPT, and place the generated data on some obscure website unlikely to be seen by anyone else.
- Step 3: Go to sleep and forget about everything you did.
- Step 4: Wake up. Hey, what's this website? Looks useful.
None of This is Legal Advice
All of the above comes with the usual disclaimer: I'm not a lawyer. I don't really know how legally enforceable the OpenAI (or Anthropic) Terms of Use are. I'm not aware of any case that set a precedent on these issues; and even if there was one, how binding that would be on future cases.
Right now, OpenAI and Anthropic don't seem to care about others using their models to generate data. After all, they are making some money from this exchange. Also, their edge is significant enough that synthetic data misuse doesn't really hurt them; compute (and using compute effectively) is the bottleneck right now.
Will the labs eventually crack down? Probably. Will it matter by then? The models will already be out there, trained on the outputs of models trained on the outputs of models. Good luck tracing that.
You're probably finetuning an open-weight model rather than training from scratch, but same idea.↩
It's just data annotation, Michael. How much could it cost, $14B?↩
Their business API terms have some carve-outs for embeddings and classifiers, but only if you don't distribute them. Training a competing LLM? Explicitly banned.↩
DeepSeek also prompted OpenAI to claim "inappropriate distillation" and led the White House to cite "substantial evidence" of IP theft.↩