The last four months have been intense. I’ve dedicated my professional life to understanding and developing artificial intelligence, and now I’d argue we have a form of (jagged) artificial superintelligence (ASI). 1 Available in your pocket. If that does not blow your mind, you lack imagination.

This post is my attempt to make sense of where we are now and what it means for humans. It is divided into six sections:
-
Models Can (Sort Of) Think And Use Tools Now. Combined with better scaffolding, we crossed a threshold, and agents are now useful.
-
Verification Costs Determine Progress. Progress is fastest in areas that allow automated verification. A lot of things humans care about can’t be automatically verified.
-
The Frontier Will Become More Jagged. Due to the verification bottleneck, progress will be uneven across domains. This unevenness will be amplified by which problems match the inductive biases of current models.
-
Agents Run On Text. Write everything down, find ways to verify agent output, and scaffold. Documentation is now code.
-
Humans Are Still More Efficient For Many Problems. For problems that are dynamic, subjective, and judgment-heavy, the human brain remains the more cost-effective solution. Become good at solving problems that are expensive to verify.
-
This Means You Should Be More Human. Stop trying to be a computer. Be more human instead.
I think by writing, and here are my thoughts:
What Happened in November 2025?
On November 24th, 2025, Anthropic released its Opus 4.5 model, and with that, we crossed a threshold for what large language models are able to do. Or actually, it might have been the scaffolding, Claude Code, that unlocked a new level of performance. Either way, agents can now solve complex, hours-long tasks that only expert humans could handle a few months ago.
My attitude to new AI things has always been one of realistic skepticism, mostly because I’ve been responsible for making models perform well in critical production systems for most of my life. That humbles you. Every attempt I’ve made to get agents to work in the last few years has failed. The models couldn’t quite put things together. It was close, but not enough. Hence, my policy has been: I’ll periodically try it to be ready when scaling makes it work.
Well, it works now. Over the last few months, we crossed a threshold that makes agents useful. The most immediate and obvious impact is on software development, which has been completely transformed. For software engineers, there will always be a “before and after November 2025.” The difference between “works” and “does not work” can be as little as a few percent on the underlying capability curve. Still, if you cross a threshold where the model can reliably solve problems, then it becomes a tool you can use in production. And that is what happened.
Over a few short months, leading engineers and their teams have completely adopted agentic coding tools. Why? Because they work. Between March 2024 and early 2026, the most widely recognized benchmark for agentic software development reported that performance climbed from ~30% to ~80%. And it’s still climbing. 2
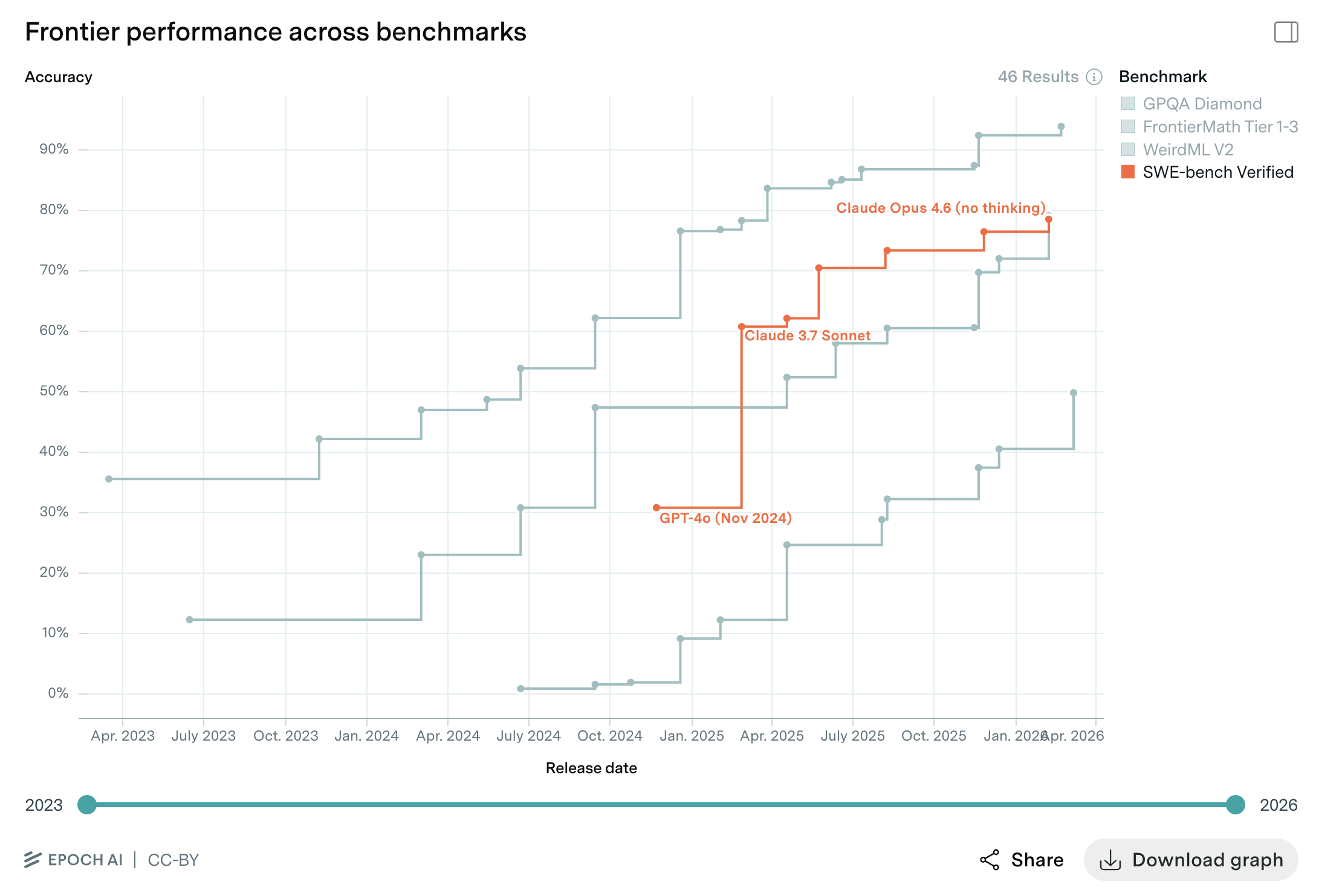
As mentioned, the increase in raw model performance with the release of Opus 4.5 isn’t very big. The model release pushed us over the threshold, but two things really boosted performance in recent months:
1. Models Can (Sort Of) Think Now
I think the only way to predict the future is to deeply understand both the past and the present. For that reason, we will work through exactly what “thinking” means in the context of large language models. The text might seem overly thorough, but it’s necessary to understand my predictions about ASI’s future. If you want to skip the details, jump to the next section.
Back in 2019, Sutton wrote The Bitter Lesson, 1 reflecting on the fact that methods that use computation tend to win in the long run. In that spirit, the term “scaling laws” was coined by Jared Kaplan, Dario Amodei, and others in 2020 based on their observations while working at OpenAI. 2 Their paper described power-law relationships among performance, model size, dataset size, and compute. Not long after, in May 2020, Gwern popularized and extended the phrase in his piece The Scaling Hypothesis. 3 The text articulates the broader philosophical claim that neural nets absorb data and compute, generalizing and becoming more capable as they scale.
“Thinking” is an extension of the bet that more tokens and more compute make models produce better solutions. Brute-force training on internet-scale human knowledge remains the foundation, but labs have found that the largest gains are no longer coming from scaling this dimension alone. 4 Instead, they are increasingly focused on improving how models “think”. The first paper I read that used this term was Chain-of-Thought Prompting Elicits Reasoning in Large Language Models, published in 2022. 5 The idea is that if you ask a model to “think step by step”, it will generate a chain of thought that leads to the answer. Synergizing Reasoning and Acting in Language Models 6 then introduced the idea of “interleaving” reasoning with action, where models not only think, but take actions based on their thoughts. Toolformer 7 showed that giving models access to tools further enhanced their capabilities.
In parallel, I think Noam Brown’s work on game AI has shaped progress. He is famous for developing two poker bots: Libratus and Pluribus. This work demonstrated that letting models think for 20 seconds mid-hand gave roughly the same improvement as scaling up model size and training by 100,000x. 8 Gradually, it became clear that “inference-time compute” is a scaling axis. Labs shouldn’t just make the model bigger; they should also let them think longer. Brown introduced the concept of the generator-verifier gap. 23 3 The key point is that “thinking” is a powerful way to use more compute and achieve much better performance without scaling up the number of parameters in the underlying model.
Here is an attempt at visualizing the evolution from “generation” to “thinking” in language models:
But how do you train a model to think productively? The big labs have had to completely rebuild their training pipelines in recent years.
Training large models starts from a randomly initialized neural network that trains on trillions of tokens of filtered text and code. The network learns to predict the next token. The result is a base model.
Towards the end of pre-training, you shift the data distribution to mathematics, formal reasoning, and verifiable software code. At the same time, you reduce the learning rate. That means you make the model change less and less based on each example. This annealing technique makes models more precise at logical reasoning.
Next, the model enters a reinforcement learning (RL) loop against problems with verifiable answers: math, code with test suites, formal proofs. DeepSeek-R1-Zero demonstrated that a base model trained based on only correctness rewards learns to generate extended chains of thought, including self-verification and backtracking. 9 Or more simply put: the model discovers on its own that intermediate reasoning steps increase accuracy. That said, there are some severe limitations with this approach, as described by Karpathy in a recent interview: 19
“You’ve done all this work only to find, at the end, you get a single number of like, ‘Oh, you did correct.’ Based on that, you weigh that entire trajectory as like, upweight or downweight. The way I like to put it is you’re sucking supervision through a straw. You’ve done all this work that could be a minute of rollout, and you’re sucking the bits of supervision of the final reward signal through a straw. You’re broadcasting that across the entire trajectory and using that to upweight or downweight that trajectory. It’s just stupid and crazy. A human would never do this. Number one, a human would never do hundreds of rollouts. Number two, when a person finds a solution, they will have a pretty complicated process of review, of, ‘Okay, I think these parts I did well, these parts I did not do that well. I should probably do this or that.’ They think through things.” 4
To mitigate these issues, people have started training process reward models (PRM) to enable models to backtrack if they make mistakes. I think we are still in the early days of figuring this out, but it’s a promising direction. The more we can give models feedback on their intermediate steps, the better they can learn to think productively. 5
Anyway, once you have a reasoner, you can run it on new problems to generate many candidate solutions. You then apply the same automated verifiers to filter for correctness. A fresh model is fine-tuned on this curated output. This can be set up to create a synthetic data flywheel.
It’s important to note that this only works for verifiable problems! 6
After that, preference optimization calibrates the model for “harmlessness and helpfulness”. The idea is that you want the model to help you plan a weekend in Paris, but not guide you on how to produce sarin gas. This is also known as alignment, and is a process that is completely dependent on human feedback. It’s an attempt to encode human values and preferences in the model. Those most worried about a scenario in which AI runs amok want to invest heavily here to make sure future AIs don’t decide to kill all humans to achieve their goals…
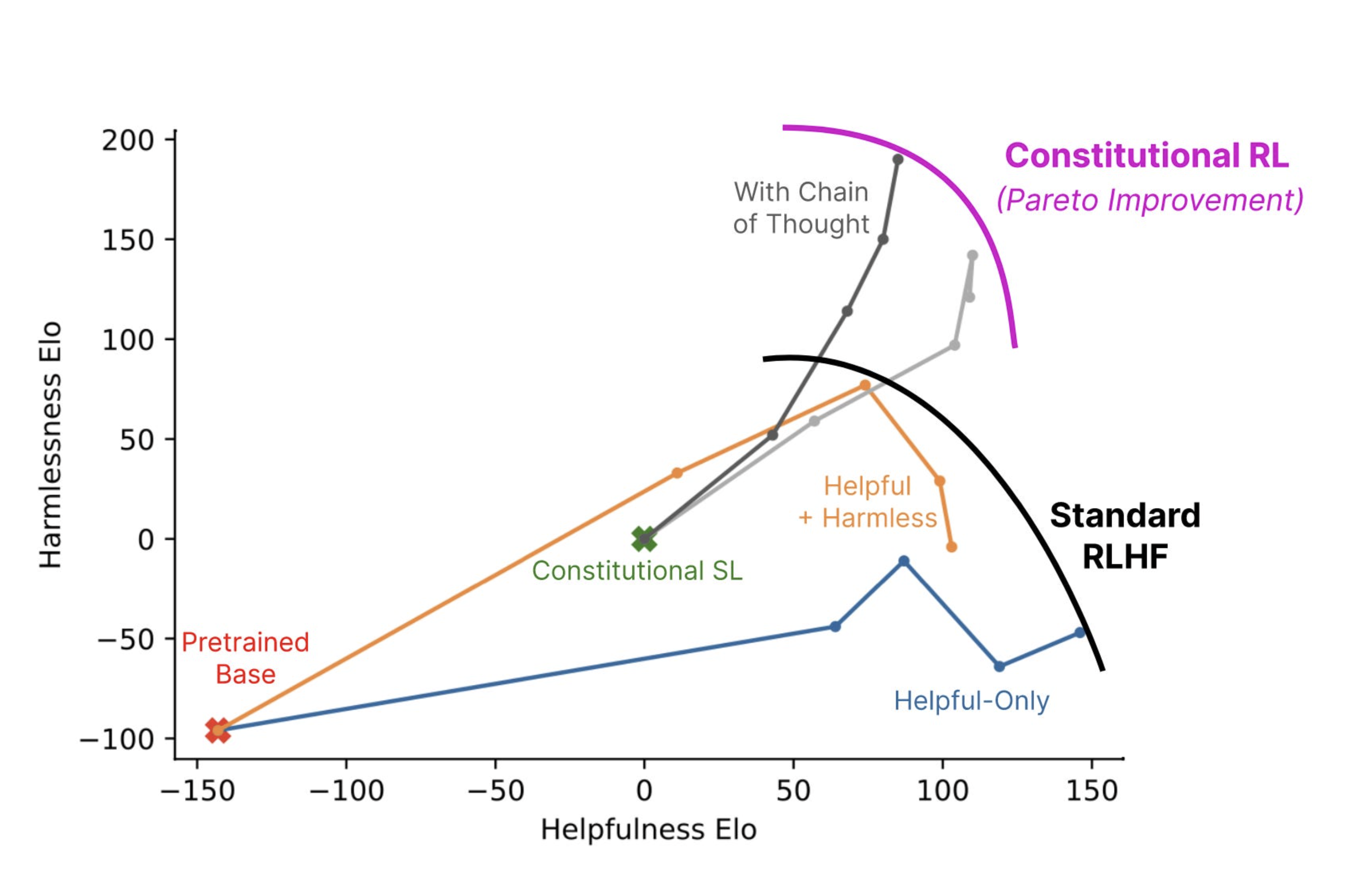
In practice, it means models compare pairs of outputs against a set of principles and learn to favor the better-aligned response.
Separately, the model also trains in environments with terminals, file systems, and APIs, learning to invoke tools, interpret results, and resume reasoning. This is a growing area, and I wouldn’t be surprised if a huge amount of the compute build-out right now is about building eval environments for computer-use agents. Anthropic in particular has a strong thesis that computer-use is the next big unlock. Claude Code is the first step, but if models can use all aspects of your computer: mouse movements, read screen state, access browser, etc., then it can suddenly take on a very wide range of tasks. We are getting close to that. The Claude Chrome plugin, 17 for example, has been improving steadily.
Thanks to all this, the model learns not to respond immediately to your questions. It first generates a chain of thought of thinking tokens that are hidden from the user, each one a forward pass that provides additional computation for planning, exploring alternatives, and self-correcting.
Together, all of this increases the thinking budget and makes it adaptive. Simple prompts use minimal amounts of tokens, while hard problems may consume tens of thousands of tokens (or even millions in some cases) before the response is ready. For reference, the average novel is about 70k-100k words… I’ve personally managed to get models to spend hours “thinking” in this way, using millions of tokens. I suspect Google Gemini 3 Deep Think is especially expensive to run. If you haven’t tried it, you should. The results are mindblowing.
Training & Inference Pipeline
A typical pipeline from raw data to test-time compute.
Each training stage draws on a different source of signal, from self-supervised text (essentially free) through human preferences (expensive) to automated verification (free again for verifiable domains). Reasoning RL and agentic RL use verifiable outcomes, breaking the human-annotation bottleneck.
Several specific advances have further improved this pipeline in recent months:
Anti-reward-hacking training. One problem in succeeding with RL is that models tend to take shortcuts if they can. Early coding agents would, for example, turn off failing tests to improve test coverage scores. Claude 4 models were trained to be 65% less likely to take such shortcuts, 10 and instead actually obeying the user intent. For complex coding tasks, this means the model really reads the code and identifies the root cause, rather than applying some superficial fix or hack. At least, that’s the idea. It’s not perfect yet, but it’s gotten a hell of a lot better in the last year.
Self-correction. Anthropic’s analysis noted that upgraded models showed “an ability to try several different solutions, rather than getting stuck making the same mistake over and over.” 14 Self-correction is a necessary trait, as real-world coding tasks involve hundreds of steps and often rely on testing and debugging to reach the right answer.
2. Models Can Use Tools Now
Claude 4 was the first model to use interleaved thinking. This is qualitatively different from planning everything up front.
Giving models access to, e.g., a Unix shell and a file editor was a massive unlock. But it also turns out that the details of how those tools are designed matter. Researchers have tried switching models inside various agent harnesses and found that careful tool-interface design, like requiring absolute file paths to prevent confusion, writing detailed tool descriptions, rejecting syntactically invalid edits, makes a much bigger difference than pushing the underlying model a few percent. One study found that swapping models changed SWE-bench scores by 1%, while swapping the harness changed them by 22%. 15
The Agent Harness
The harness manages everything except the model's weights: which tools are available, how tool descriptions are written, how context is compressed when the window fills up, how errors are caught and retried, and when to ask the human for approval.
Claude Code is far from the only harnessing out there, but they all converge on the same architecture: a sort of plan-act-review loop with a few carefully designed tools. Engineers are currently racing to develop the best innovations in the “harnessing layer”. That includes thinking about things like: How does the agent manage its context window when a task takes hundreds of turns? How does it recover when a tool call fails? When does it ask the human for help? That’s where the difference comes from now. The underlying models are all good, but the way you harness them makes a huge difference in what they can do.
3. Benchmarks Are Saturating
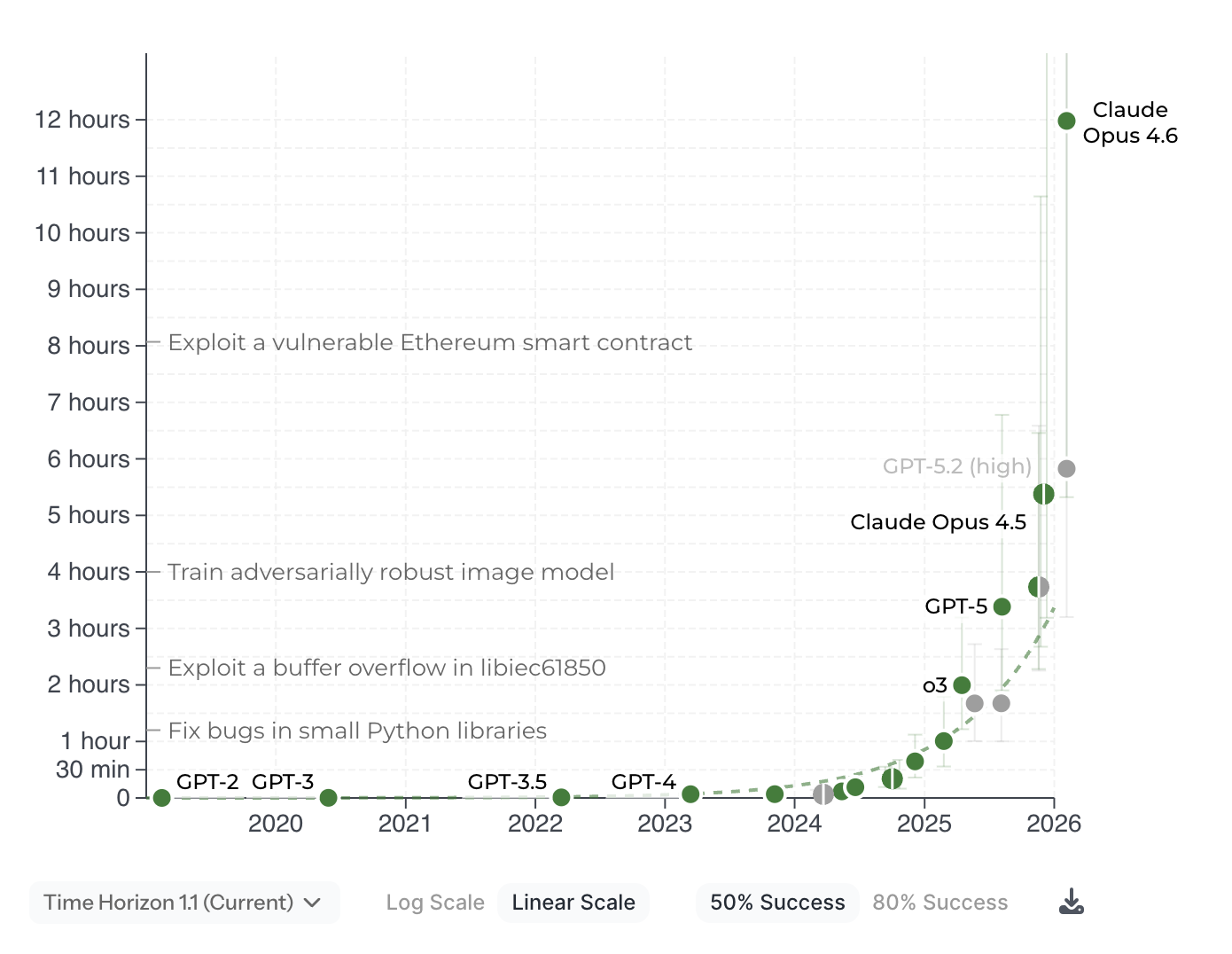
Alright, so models and their harnesses are much better now. How much better? Let’s take a look at three benchmarks that test different capabilities: long-horizon task execution (METR), reasoning (ARC-AGI), and graduate-level scientific knowledge (GPQA).
METR measures how long a task an agent can solve. As of Opus 4.6 (February 2026), agents can take on tasks lasting many hours. A new version of Moore’s Law is emerging: the length of tasks AI can solve is doubling every 7 months. Perfection is not necessary if you can error-correct within an iterative loop. Successfully solving problems is about establishing an error-correcting way of working, using tools, memory, and planning. And, as models are now increasingly able to do this, this benchmark is going vertical.
ARC-AGI is specifically designed to measure general reasoning rather than memorized knowledge. Every task is novel by design, yet any adult human can solve it in under a minute. ARC-AGI-2 was designed to raise the bar and last longer than ARC-AGI-1. Well, developers have already almost saturated it. 7
GPQA is a dataset of 448 PhD-level multiple-choice questions in biology, physics, and chemistry. They are “Google-proof”, i.e. during testing, highly skilled non-experts only reach 34% accuracy even with web access. Here is an example question:
A scientist studies the stress response of barley to increased temperatures and finds a protein that contributes to heat tolerance through the stabilisation of the cell membrane. The scientist is very happy and eager to develop a heat-tolerant diploid wheat cultivar. Using databases, they identify a heat-tolerance protein homologue and begin analysing its accumulation under heat stress. Soon enough, the scientist discovers that this protein is not synthesised in the wheat cultivar they are studying. There are many possible reasons for such behaviour, which is correct:
- A miRNA targets the protein, which makes exonucleases cut it immediately after the end of translation and before processing in the ER
- Trimethylation of lysine of H3 histone in position 27 at the promoter of the gene encoding the target protein
- A stop-codon occurs in the 5’-UTR region of the gene encoding the target protein
- The proteolysis process disrupts a quaternary structure of the protein, preserving only a tertiary
As of the most recent generation of models, it’s basically saturated…
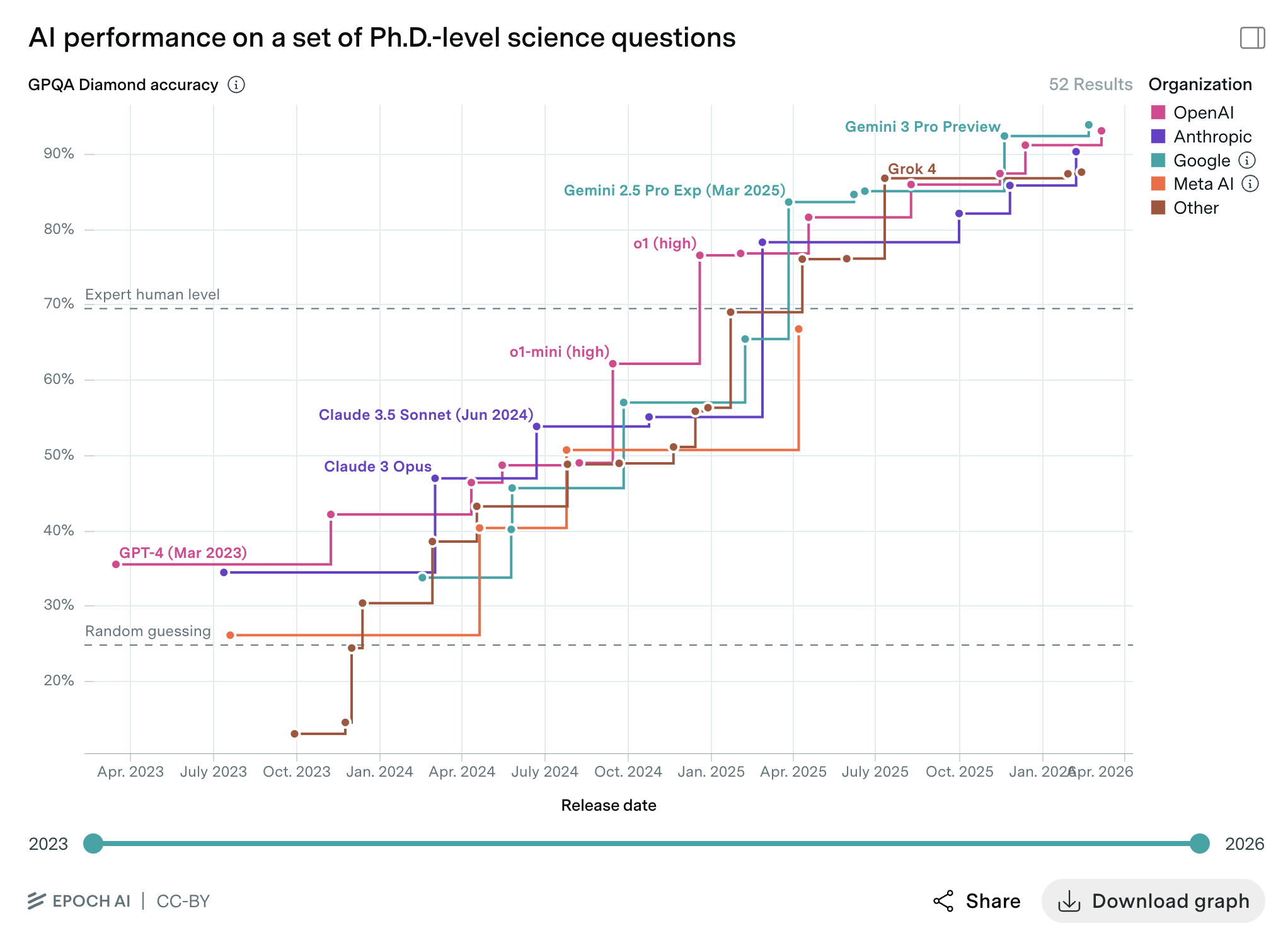
The pattern across most benchmarks is the same: capabilities are improving on a predictable curve, and benchmarks designed to last years are being saturated in a matter of months. As pre-training showed diminishing marginal returns, other scaling dimensions stepped in, such as inference-time compute, better tool use, and iterative self-correction.
Are these benchmarks perfect? No. Are they able to capture the full extent of the human experience? No, of course not. Are they still relevant? Yes.
The Verification Bottleneck
The entire reasoning-reinforcement-learning pipeline described earlier depends on one critical property: automated verification. DeepSeek-R1-Zero works because you can check if a math answer is correct. Code agents work because you can run a test suite. AlphaZero works because you can simulate games and evaluate outcomes. The synthetic data flywheel spins because each candidate solution can be graded programmatically at machine speed. When verification is automated, the model can generate millions of attempts, filter out incorrect ones, and train on its own best outputs. Math and code have very low verification costs, which explains why progress has been so dramatic in those domains.
But most things humans care about aren’t easy to verify.
“Do you like this design?”
“Does this email strike the right tone?”
“Will this strategy work?”
None of these can be checked by running a program. The only way to verify them is to show the output to someone and have them judge it. The flywheel can’t spin faster than we can verify the output. Lots of things contribute to much slower progress outside of automatically verifiable domains, but here are a few of the most important ones:
Language is lossy. Language is the best tool we have for transmitting preferences from one mind to another, but it still sucks. It’s indirect and incomplete. When a product manager writes a product brief, they are transmitting a compressed, partial representation of what they actually want. Much of what they want is tacit knowledge that they couldn’t write down even if they tried.
People change based on what they are shown. Learning is a coupled problem. Often times, you don’t know what you want until you see what you don’t want. A designer shows a client three mockups: the client rejects all three but now has a much clearer sense of what they’re after. This sense did not exist before seeing the mockups. Their preference is literally created by the process of you trying to learn it.
Human attention doesn’t scale. A human reviewer might evaluate ten things per hour. An automated test suite evaluates millions per second. Computers are orders-of-magnitude faster at verifying. But, as soon as a human is involved, the cost is measured in real time, real energy, and real cognitive load.
Interaction with the world is expensive. You can’t check if a strategy works by running a program. You have to try it in the real world and see how the market respond. That takes time, and the feedback is noisy and delayed. Your company is sort of the program, and the market is sort of the computer. This is the same reason we are seeing much slower progress in robotics than in software.
These sorts of factors contribute to an asymmetry in the rate of AI progress across domains based on the cost of verification. I’m using “verification” broadly here. My definition covers the whole range from deductive checking (Does this code compile? Is this proof valid?) to subjective evaluation (Does this email strike the right tone? Is this design good?). Based on this, I think it makes sense to think of three categories of problems:
-
Automated Verification. Like math, code and perfect information games. For these, the flywheel can spin at machine speed. We get basically unlimited training signal for free. This is why software engineering and math benchmarks have improved so dramatically.
-
Cheap Verification, This includes things like simple content moderation, basic translation quality, image classification, thumbs-up/thumbs-down ratings on chatbot responses etc. For these, the flywheel spins slowly, but it’s reasonably affordable. Each human judgment takes seconds, and you can collect millions of comparisons at scale. This is how RLHF produces models that feel nice to chat with (or sycophantic, if you’re not careful with your training data. 25). Progress here is steady, but not explosive.
-
Expensive Verification. Like strategic decisions, drug testing, hiring decisions or autonomous driving system safety. Anything requiring domain expertise, extended reasoning or real-world interactions will be expensive and slow, which also means progress will be slow. This is why we haven’t seen nearly as much progress robotics or drug discovery as in math and software.
The obvious counterargument is increased scalability of oversight. Can you train a reward model on human judgments, then use it as an automated verifier? Methods like Constitutional AI and RLAIF are increasingly effective, and will push problems from category 3 into category 2, and from 2 into 1. But I’m skeptical they will close the gap. A reward model is a frozen approximation of a moving target. For non-stationary problems, where tastes shift, contexts evolve, and optimization itself changes what people want, the model drifts out of alignment with the humans it represents. 8
In coupled human-AI systems, human evaluation speed becomes the binding constraint on the system’s learning rate. If evaluation is the bottleneck, generating more candidates faster is just wasteful. Instead, the more energy-efficient strategy is to minimize the cost while maximizing the quality of each unit of human feedback. This would be done by presenting the human with the right context, at the right level of granularity, and the right instructions.
This is exactly what good annotation tooling does. 9
And it has a counterintuitive implication: as models get better at generating candidates, the value of human feedback increases! Better models can produce more options faster and at lower cost. But someone still has to verify the output. Every improvement in generation capability shifts more of the system’s total cost onto the verification side. The value of software, i.e., the verifiable part, plummets while the value of excellent human judgment grows.
The Increasingly Jagged Frontier
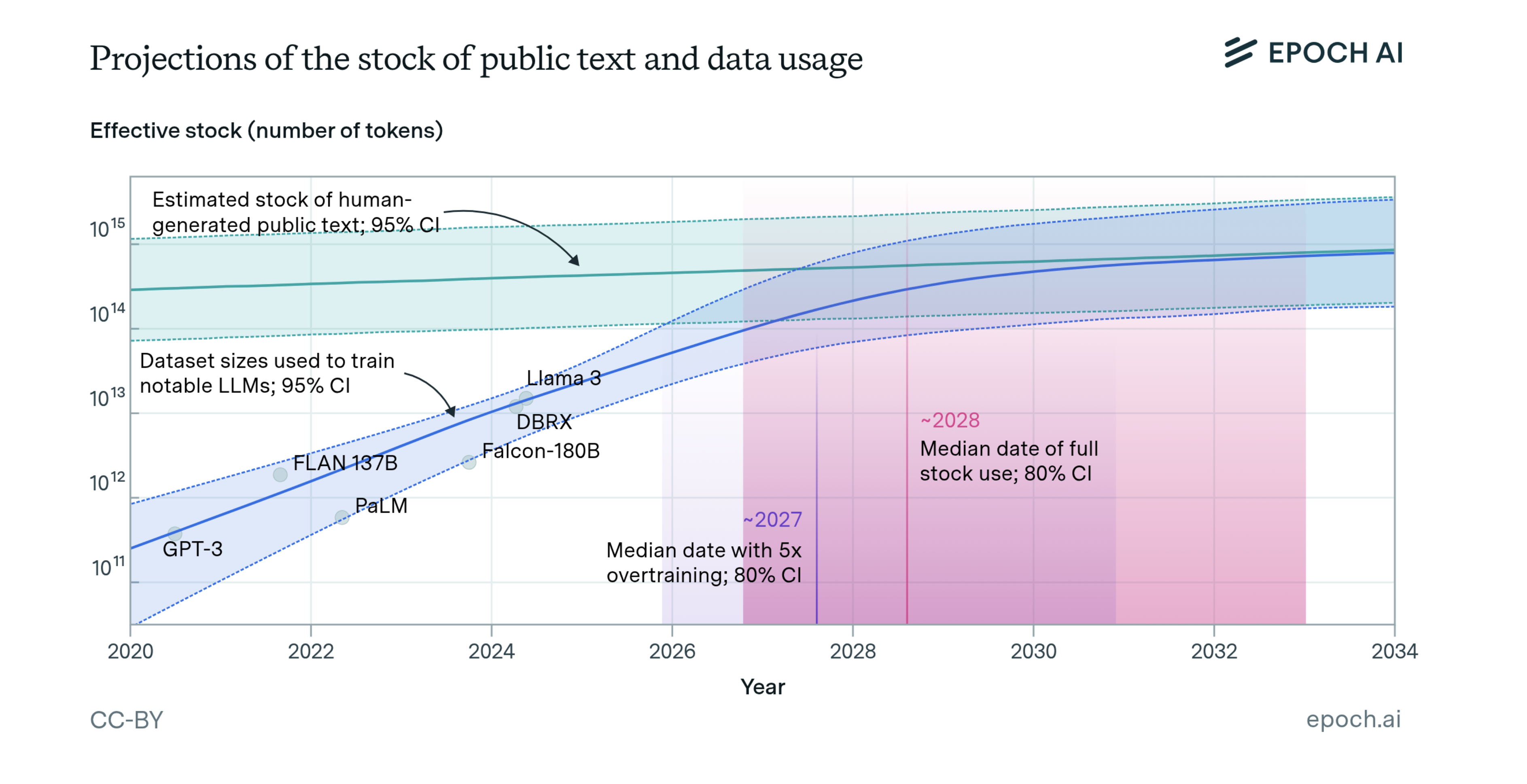
Given how much text we have available, it’s tempting to think everything is written down. But that’s not true. Not even close. Our human experience is deeply personal and rarely written down in any significant detail. Most of our knowledge is tacit, and most of our preferences are hidden. Epoch AI estimates the supply of quality, deduplicated, human-generated public text for AI training sits at around 300 trillion tokens (to be fair, their 90% confidence interval is 100T to 1,000T tokens). 12 If current LLM development trends continue, models will be trained on datasets roughly equal in size to this available stock sometime in the next few years.
This means that the “low-hanging fruit” of learning from human-generated text is almost gone. 10 The next wave of progress will have to come from other sources of training signal, like human judgment, self-supervision, and synthetic data generated by the models themselves. And as we’ve just seen, those signals are far more expensive to produce and verify than text. This is why the frontier of AI capabilities is not advancing evenly, and why it will become more jagged, not less.
Karpathy popularized the term “jagged intelligence” 13 to describe the observation that AI capabilities don’t advance evenly. A model can solve differential equations that challenge PhD students, then fail to count the r’s in “strawberry.” It can draft a legal brief better than most lawyers, then hallucinate a nonexistent case citation. The boundary of what AI can and can’t do doesn’t follow human intuitions about difficulty. Tasks that seem equally hard to us sit on different sides of the frontier, and the shape of the frontier doesn’t map on any difficulty gradient we are familiar with.
Jaggedness has two causes, and understanding both is necessary to predict where the frontier will move.
The first is inductive bias mismatch. Models are trained on text, so their capabilities mirror the structure of problems that can be solved through pattern-matching over sequences. Some tasks that are “hard” for humans (e.g., graduate-level math) are well-represented in the training data and closely aligned with the model’s bias. Some tasks that are “easy” for humans (spatial reasoning, counting, physical intuition) are poorly matched and less represented. This mismatch is a big reason the frontier is jagged, as human difficulty and model difficulty measure different things.
The second is verification cost asymmetry, i.e., the dynamic described in the previous section. Models improve rapidly where verification is automated, and slowly where verification requires expensive human judgment. The outward spikes on the jagged frontier are domains with low verification costs. The recesses are domains where each evaluation costs minutes of expert attention rather than microseconds of compute. This explains why the frontier stays jagged over time: the domains with automated verification pull ahead faster, while the domains that depend on human feedback improve at human speed.
These two causes reinforce each other. A domain that is both well-matched to the model’s inductive bias and cheaply verifiable will see rapid, compounding progress. Significant parts of software development fit this description. In contrast, a domain that is poorly matched and requires expensive human verification will lag on both fronts. The result is not a frontier that smooths out over time, but one that may become more jagged as the fast-improving domains accelerate away from the slow ones. This will be very confusing for people, as we will keep seeing AI perform superhuman feats almost instantly while completely failing at tasks we think are simple. That’s already true, just take Chess as an example. The world chess champion would lose to a wristwatch running a chess engine, but the wristwatch has no clue how to make a sandwich. That’s weird.
Making Agents Work
As promising as results are, they only really matter if we can operationalize them. So, how do we do that? And how do we know if it’s working?
The New Core Loop
Agents run on text, so to make use of them, you need careful documentation. If you want to transfer a task to an Agent, you need to:
- Checklist. Outline every step of the process as a checklist in precise natural language.
- Specify Inputs. For each task, specify inputs, outputs, and available tools. If the right tools don’t exist, build them.
- Verification Methods. The easier it is for the agent to self-verify, the better. If that’s not possible programmatically, then make sure to integrate human feedback.
- Resolve Edge-Cases. Iterate with the agent to resolve issues and edge cases. Make actions reversible where possible. Agents can run amok if you are not careful, so make sure to put in guardrails.
- Dry-Run. Test the agent by letting it autonomously dry-execute the entire process.
- Monitor. Add monitoring and escalation paths.
Then just let it rip. Your job, in this setting, is to be a person with values, experience, taste, and domain intuition. You steer the agents by writing down things and verifying the output. You do not perform tasks beyond what is necessary to outline the process and build understanding. Sometimes that requires months of work. I always work on things for a while before delegating them. The same will apply now.
If It’s Not Written Down, It Doesn’t Exist
All processes, tasks, inputs, outputs, and tools must be documented in version-controlled files. Documentation is code for agents, but not everything can be easily written down. Much of what makes human judgment valuable is tacit knowledge that resists explicit description. But everything that can be documented, should be, because that’s the layer agents can operate on. Detailed documentation is a core requirement for maximizing the potential of agentic AI, just as digitalization has been for using computers. All learning, solutions, and new tools should be added to a shared repository for reuse across all projects. The effect is an instant, complete transfer of learning across all projects. Every agent operator receives all learnings as soon as the underlying scaffolding is updated.
This parallels what’s happening inside the agent harness. Claude Code uses a file called CLAUDE.md as a form of memory. In there, it keeps the project’s accumulated “wisdom” in plain text and loads it every time it starts. You need to apply the same principle at the organizational level: if something isn’t documented in a way an agent can consume, it doesn’t exist in the workflow. Humans tend to keep too much in their heads, as anyone who just started a new job quickly learns…
I predict the next wave of development tools will all focus on context management. These tools might as well be called “annotation tools” or “knowledge bases” in that they will guide humans to ensure the right information is present in text that guides the model. Context management for coding agents is the same as curation, review, and correction. Think of work as being the moderator of Wikipedia.
By the way: most engineers, AI-researchers (and AI-lab CEOs) fail to appreciate how hard it is to make people write things down in a way that is useful for agents… You can’t just tell people “write nice documentation.” You need to work hard to put in place the right tools, processes, and incentives to make it actually happen.
What Does Success Look Like?
I don’t know yet, but the three primary metrics I will be looking at are:
1. We Create More Value. Most managers immediately think: Wow, we can save money using AI and finally get rid of all those pesky people in our teams! Wrong. Wrong, wrong, wrong! That’s a narrow, zero-sum mindset. What you should do is use your imagination: What can we do now that was impossible before?! What completely new forms of value can we deliver using this technology?! What impossible problems are now possible to solve?! Success here is measured by revenue from new line items that previously did not exist. I’m not going to share too much here, since that’s our secret sauce at Kognic, but I encourage people to think like this everywhere. The world economy and human quality of life will improve much more if we use ASI to create new value rather than just cut costs.
2. We Increase Productivity. While bullet one is my primary approach, it is also, of course, relevant to find ways for the same team to do more. Productivity can be very hard to measure in some areas, but it is easier in others. We have areas of Kognic that scale with the number of clients and annotation projects. We have a very clear baseline for resource needs in this area. If we reduce the number of human hours needed per project by 10x, that would be a clear sign of success.
3. We Decrease Overhead. Companies require a massive amount of admin. Most of those tasks are routine, like receipts, invoices, and similar forms of boring paperwork. The less of this we need to spend time and money on, the better. These tasks are the best candidates for automation: they are not mission-critical, do not differentiate, and are mostly mechanical. Unfortunately, I still don’t see great progress here, but I’m optimistic we are about to see more.
Since early 2026, we have been running projects under the theme “Maximize Human-Agent Collaboration”. I think that’s the right way to think about this. The goal is not to replace humans, but to create a new form of collaboration in which humans and agents work together to achieve outcomes that neither could achieve alone. This is a new frontier, and I’m excited to explore it.
Humans Will Remain More Cost-Effective
The World Doesn’t Stand Still
Many of the problems that matter most (social dynamics, markets, organizations and geopolitics) are non-stationary The target is moving. Past observations become irrelevant as the world drifts away from the process that generated them.
Stationary problems reward depth and precision: Invest heavily, find the perfect answer and then use that knowledge for a long time. Many companies and cultures are design to find perfect solutions.
Non-stationary problems reward speed and adaptability: Try different approaches, scale up the ones that work, and keep going until you see diminishing returns. Restart as the environment changes. The half-life of your knowledge depends on how fast the environment changes. Startups and emerging economies like China tend to be good at this.
Humans evolved for non-stationary environments. We didn’t evolve to optimize static constraints. We evolved to be dynamic, adaptive, exploratory, and innovative people who can cope with enormous change and find new ways to do things. Social contexts are highly non-stationary: they change over time. For example: fashion, vibes and slang. The ability to quickly learn subtle changes from a few examples is a core part of being socially successful. We all have friends who are always tuned to the latest trends, and friends who are always a few years behind. Or those who never seem to be able to read the room. The first group is more socially successful because they can adapt to non-stationary social environments. The other group struggles because they are trying to apply static knowledge to a dynamic world.
LLMs are trained on static snapshots. First of all: Yes, agentic systems can pull in real-time information through tools, web searches, and environmental feedback. This eliminates some of the worst “staticness”. But it doesn’t close it. In-context learning is bounded by the context window and limited to what can be expressed in text. For problems where the non-stationarity is subtle (e.g., social situations) or tacit (e.g., a shift in taste, a change in team dynamics, or an evolving market intuition), an agent’s adaptive loop is still far worse than a human’s. Some, like Dario Amodei, speculate that the lack of continuous learning in modern LLMs is sufficiently solved by in-context learning in huge context windows. Maybe. Time will tell.
Either way, for now there is a likely division of labour emerging: Humans should lean into what’s dynamic and push the stable stuff to AI. As soon as something is understood, documented, and can be processed in structured text, shift that work over to a model. If you don’t, the market will since it will be cheaper. What remains for humans are the hard, dynamic, relational, low-sample-count things that requires the kind of efficiency evolution spent millions of years equipping us with.
The premium is no longer on executing known processes. The premium is on adapting: exploring the unknown, building relationships, and learning faster than the environment changes.
There’s one big thing I’m not addressing here: Robotics and Embodied AI. Vision-language-action models and humanoid robots are trying to do exactly what I’m saying humans are good at: operate in messy, dynamic, physical environments. Right now, they can’t learn continuously from real-world feedback. They train offline on curated demos and simulations, and the gap between a cool demo and actually working in the real world remains enormous. Moravec’s paradox still holds even if we might find ways to overcome it. If embodied agents eventually learn to adapt in real time the way we do, a lot of what I’ve argued here gets weaker. But, that’s still a long way off, though. I think we need a new model paradigm for that to really take off. 11
More Compute, Same Search Space
A common mistake when thinking about AI is to assume that intelligence makes search easy. It doesn’t. Some problems are intrinsically hard to search. For example, I don’t expect superintelligent AI to crack AES encryption. The search space is 2^128 regardless of intelligence. There are physical limits to what we can expect for large search spaces. 12
Formal verification languages like Coq and Lean are underused not because humans are bad at them, but because program search is hard. More intelligence doesn’t change the size of the search space. It may let you move through it faster, and sometimes deep analysis can help you shrink it. But if it’s large, then there isn’t much you can do about it.
This opens for an interesting question: Can you be “better at search”? Some researchers clearly have “good taste” in the sense that they tend to select better problems to work on. They don’t select research questions randomly. This skill is hard to describe. It’s not like there’s a clear gradient to follow. The best path when exploring the unknown is not obvious. When people think about recursive self-improvement in AI systems, I think they underestimate the verification cost per iteration and the size of the search space. The ability to generate a hypothesis isn’t the binding constraint on research progress. It is some combination of our ability to verify it, and our ability to convince others that what we claim is true. If you can’t verify it, you can’t learn from it, and you can’t improve. And if no one believes you, it doesn’t matter.
Resource Rationality Matters
Transformers are universal approximators: given the right parameters, they can represent any continuous function to arbitrary precision. 26 They are also Turing complete when combined with chain-of-thought: given enough time and memory, they can compute any computable function. This sounds powerful. But it is also nearly ubiquitous. Feedforward networks, polynomials, kernel methods, and even a lookup table that memorizes all input-output pairs are universal approximators. A lookup table is a universal approximator and also the worst possible learner.
The existence of a solution does not guarantee that you can find it. Universal approximation says the parameters exist. It does not say you can find them. Turing completeness says the computation sequence exists. It does not say you can learn it from data. Neither says anything about how much data is needed, how long the search will take, or how much energy it will cost.
What actually determines learning efficiency is the match between the learner’s inductive bias and the structure of the target problem. 21 When the learner expects the kind of structure the target actually has, each observation provides maximum information. When expectations and structure diverge, data is wasted on updating wrong assumptions. Neural networks dramatically outperform alternatives on images, speech, and language not because they are more expressive (a lookup table is equally expressive) but because their biases match the targets they’re applied to. This is why I think architecture matters as much as raw capacity.
What I’m about to argue is perhaps contrarian, but hear me out: I think The Bitter Lesson is true in the sense that computational methods beat expert methods in performance in the long run, BUT there is an important caveat that changes the practical implications: performance is not the only thing that matters, cost per unit of performance matters too. I think people are overly focused on the performance aspect of The Bitter Lesson and not focused enough on the cost aspect. Resource rationality is the key concept here.
During 2025, the major technology companies collectively spent over $300 billion on AI-related infrastructure, and in 2026, the projected figure approaches $700 billion. 20 That capital funds bigger models, longer thinking, more candidates, and faster inference. The benchmarks listed earlier prove that the Bitter Lesson approach is delivering.
But look at what it costs. Training a frontier model requires megawatts sustained over months. Inference at scale requires data centres with dedicated power plants. During the RL phase, the model does a minute of work, generates thousands or millions of tokens of reasoning, and learns from a single bit. Right or wrong. That is a staggering amount of compute per bit of learning signal. Yes, the marginal cost of a single inference is fractions of a cent, but learning a new capability still requires millions of training examples and enormous infrastructure investment.
Now compare that to a human. A person can watch a single demonstration, extract the principle, and apply it to a novel situation. We learn subtle social dynamics from a handful of interactions. We update a lifetime of priors based on one well-chosen piece of evidence. The sample efficiency is extraordinary. A human costs $5-500/hour, which is expensive per unit of time, but for tasks that require learning from a few examples, adapting to novel situations, or exercising judgment that can’t be automatically verified, the total cost of getting an AI system to match that performance can far exceed the cost of the human.
The Bitter Lesson tells us that compute beats hand-crafted heuristics. It does not tell us that computers beat humans on all problems when you account for the full cost.
I believe there will be a large and persistent class of problems where humans are more cost-effective than AI models. Not in terms of energy per operation, but in total system cost. A GPU cluster is extraordinarily cheap per inference, but inference is not the bottleneck. The bottleneck is a mix of getting learning signals, verifying model output, adapting to non-stationarity, and searching in hard problem spaces. When you account for the full pipeline, i.e., not just the inference, but the human oversight, the failure recovery, the retraining, then I hypothesize that for a wide range of tasks, the total cost will exceed that of simply having a skilled person do the work.
Now, the obvious objection: compute costs are falling fast. Yes, of course. They always have been. GPUs are getting cheaper, model architectures get more efficient and inference chips are created. Won’t the boundary keep shifting until everything is worth automating? This is essentially testing if Jevons paradox holds for intelligence.
I think the answer is “Yes, Jevon’s will hold.” Tasks that were too expensive to automate last year are cost-effective today. And the frontier will keep moving. But the boundary will shift at different speeds on different fronts. For verifiable problems, falling compute costs translate directly into expanded automation. The verification in some areas is already almost free, so cheaper generation accelerates progress. But for problems bottlenecked by human verification, cheaper computing just means you can generate more candidates that still need human evaluation. And that’s not fixing your problem. You’ve made the generation side cheaper while the verification side stays fixed. The constraint stays the same. In fact, cheaper generation can make the problem worse: more candidates means more evaluation load. The cost of computing falls, but the cost of judgment doesn’t, even as Kognic works to lower it.
This means the frontier of automation will advance steadily into the space of problems with cheap or automatable verification, and slowly, constrained by the speed of human judgment, into everything else. The human doesn’t need to outperform the data centre on raw throughput. It just needs to remain cheaper on the margin, for enough problems, for long enough. And on problems that require taste, adaptation, and judgment under uncertainty, it will. 13
We’ve actually seen signs of this at Kognic. There are annotation tasks where we’ve tried to automate the judgment and found that the cost of building, validating, and maintaining the automated system (including the human oversight required to catch its failures) exceeds the cost of simply having a skilled annotator do the work. The model is faster per unit, but the total system cost is higher because the verification overhead eats the savings.
This doesn’t mean AI won’t transform work! It already has, dramatically. But the transformation will follow the boundary of resource rationality.
Be More Human
For the last two hundred years, we’ve been training humans to be more like computers. In school, we are asked to sit still, memorize formulas, and optimize based on static constraints and perfect information. It may be the Industrial Revolution’s fault. Whatever the reason, humanity decided we needed human-shaped cogs, so we built schools and offices to produce them. This has gradually been rolled back, and today, new companies recognize that agency and drive are more important than fixed knowledge. The arrival of Jagged ASI means the era of computer-like human work is finally over.
The things that make you human are exactly what remains valuable. Your ability to adapt on the fly. To read a room. To know something is off before you can say why. Your ability to update your entire worldview based on a single conversation. Feeling your way through ambiguity. Building trust. Having taste. These aren’t soft skills. These are the capabilities that evolution spent millions of years optimizing at 20 watts, and that the $700-billion-a-year AI industry still cannot replicate.

So, here is my advice:
Stop trying to be a computer. The value of human-as-computer is going to zero. Every hour you spend manually formatting spreadsheets or writing boilerplate is an hour wasted. Push that work to the models. As soon as something is understood, documented, and stable, push it to AI. If you don’t, someone else will, and they’ll move faster than you.
Get comfortable not knowing. The world will never be stable again. The pace of change is accelerating, and things are becoming increasingly complex. That won’t stop. But that is a good thing! It means our ability to adapt is becoming increasingly valuable. Your ability to encounter something you didn’t expect, update your thoughts, and act on the new information before the world shifts again. Humans have literally evolved to be good at exactly this.
Invest in relationships, not just knowledge. What you know is less important than what you can act on, and what you can act on depends on who you know and who trusts you. Knowledge without a social fabric to act on it isn’t useful. The glue that holds companies together is the informal agreements, the contextual judgments, the “I know who to call for this”. These things are all dynamic, low-sample, and high-frequency. That’s what makes them almost impossible for statistical systems to learn. You, however, can be that glue!
Improve your bullshit filter. As the cost of generating text is going to zero, the volume has massively increased. At the same time, it is not clear that it has increased the amount of information actually transmitted. Much of what you read now is fluent and plausible, yet potentially completely bonkers. It used to be that fluency correlated with competency, but that’s no longer the case. The best policy is always to demand explanations that are hard to vary. Ask what would need to be true for someone’s conclusion to be wrong. Seek first-hand sources. Your ability to separate signal from noise has always been valuable, but it’s becoming increasingly important.
Create new value, don’t just cut costs. The instinct when a powerful new tool arrives is to do the same thing cheaper. That’s a sign of a lack of imagination. Instead, you should ask: what can we do now that was impossible before? What problems couldn’t we even attempt until now? The best use of ASI is not replacing humans. It’s enabling humans to attempt things that were previously unthinkable.
Be proud of your humanity. Humans are extraordinary beings. We are these 20-watt, general-purpose learning machines that can update from a single example, navigate social complexity with no training data, detect when the rules have changed before anyone tells you, and make judgment calls under uncertainty that no amount of compute can yet verify at scale. We are the product of the longest optimization process in the known universe. Our brains are potentially the most complex things in existence. We are not about to become obsolete. We just need to adapt, like we always have.
The last few centuries pushed humans to be less human and more mechanical. We are about to invert that trend. Computers are finally good enough at computing. Now the premium shifts to everything that isn’t easily calculated and verified.
So: Be more human. Explore. Adapt. Build trust. Have taste. Take care of each other. And leave the computing to the computers.
References
- Sutton, R. (2019). The Bitter Lesson. incompleteideas.net
- Kaplan, J., McCandlish, S., Henighan, T., et al. (2020). Scaling Laws for Neural Language Models. arXiv:2001.08361
- Branwen, G. (2020). The Scaling Hypothesis. gwern.net/scaling-hypothesis
- Wolfe, C. (2025). Scaling Laws for LLMs: From GPT-3 to o3. cameronrwolfe.substack.com
- Wei, J., Wang, X., Schuurmans, D., et al. (2022). Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. NeurIPS 2022. arXiv:2201.11903
- Yao, S., Zhao, J., Yu, D., et al. (2023). ReAct: Synergizing Reasoning and Acting in Language Models. ICLR 2023. arXiv:2210.03216
- Schick, T., Dwivedi-Yu, J., Dessì, R., et al. (2023). Toolformer: Language Models Can Teach Themselves to Use Tools. NeurIPS 2023. arXiv:2210.03629
- Meta FAIR, Bakhtin, A., Brown, N., et al. (2022). Human-level play in the game of Diplomacy by combining language models with strategic reasoning. Science. doi:10.1126/science.ade9097
- DeepSeek-AI, Guo, D., Yang, D., et al. (2025). DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning. arXiv:2501.12948
- Anthropic. (2025). Introducing Claude 4. anthropic.com/news/claude-4
- Anthropic. (2025). Extended Thinking. platform.claude.com
- Villalobos, P., Ho, A., Sevilla, J., et al. (2024). Will We Run Out of Data? Limits of LLM Scaling Based on Human-Generated Data. epoch.ai
- Karpathy, A. (2024). Jagged Intelligence. x.com
- Schluntz, E. (2024). Raising the bar on SWE-bench Verified with Claude 3.5 Sonnet. anthropic.com
- MorphLLM. (2026). Best AI Model for Coding (2026): Swapping Models Changed Scores 1%. Swapping the Harness Changed Them 22%. morphllm.com
- Patel, D. (2025). Ilya Sutskever — We’re moving from the age of scaling to the age of research. Dwarkesh Podcast. dwarkesh.com
- Anthropic. (2025). Piloting Claude in Chrome. anthropic.com
- Bai, Y., Jones, A., Ndousse, K., et al. (2022). Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback. Anthropic. arXiv:2204.05862
- Patel, D. (2025). Andrej Karpathy — AGI is still a decade away. Dwarkesh Podcast. dwarkesh.com
- Futurum Group. (2026). AI CapEx 2026: The $690B Infrastructure Sprint. futurumgroup.com
- Wolpert, D. H. & Macready, W. G. (1997). No Free Lunch Theorems for Optimization. IEEE Transactions on Evolutionary Computation. doi:10.1109/4235.585893
- Herron, A. (2024). Three Mile Island nuclear power plant to return as Microsoft signs 20-year, 835MW AI data center PPA. Data Center Dynamics. datacenterdynamics.com
- Brown, N. (2024). Noam Brown and Team on Teaching LLMs to Reason. Sequoia Capital Training Data Podcast. sequoiacap.com
- Intuicell. (2025). About Intuicell. intui.ai
- OpenAI. (2025). Sycophancy in GPT-4o. openai.com
- Yun, C., Bhojanapalli, S., Rawat, A. S., Reddi, S. J., & Kumar, S. (2020). Are Transformers universal approximators of sequence-to-sequence functions? ICLR 2020. arXiv:1912.10077
-
I know calling current AI systems “superintelligent” is controversial. Some reserve the term for (future) systems that exceed human capabilities across every domain. I’m using it more loosely: We now have systems that are superhuman at a growing set of verifiable tasks, while remaining worse than humans at others. Whether that qualifies as “super” depends on your definition. I have been using it since the recent capability jump is large enough to deserve a really strong word. “Jagged” refers to this unevenness, i.e., superhuman at some tasks, mediocre or worse at others. And yes, “jagged superintelligence” is sort of an oxymoron. Some would say that a system with massive gaps in basic reasoning isn’t superintelligent, which is fair 😅 But I think the traditional framing, where ASI arrives as a single moment of uniform god-like capability, is the wrong mental model. What we’re getting instead is superintelligence that arrives unevenly, domain by domain. That’s weirder, and I think harder to make sense of. I explore the implications of this jaggedness in more detail below. ↩
-
Worth knowing about this number: SWE-bench Verified tasks are drawn from public GitHub repositories that may appear in model training data. On uncontaminated, enterprise-grade benchmarks, frontier models score closer to 20-25%. But that actually strengthens my point rather than weakening it. Going from 0% to 25% on unseen codebases in 18 months is a remarkable improvement. ↩
-
From his interview with Sequoia: “I view it as the kinds of problems where there is a benefit from being able to consider more options and think for longer. You might call it, like, a generator verifier gap, where it’s really hard to generate a correct solution, but it’s much easier to recognize when you have one. I think all problems exist on the spectrum from really easy to verify relative to generation, like a Sudoku puzzle, versus just as hard to verify as it is to generate a solution, like naming the capital of Bhutan.” ↩
-
This is a problem known as “credit assignment”, and it’s a major challenge in reinforcement learning. The model has to figure out which parts of its reasoning process led to the correct answer, and which parts were irrelevant or even harmful. This is why some researchers are exploring alternative approaches, such as training separate models to evaluate the correctness of individual reasoning steps rather than just the final answer. That way, you can provide more granular feedback to the model and help it learn more effectively. ↩
-
Karpathy’s response to PRMs is interesting: “Process-based supervision just refers to the fact that we’re not going to have a reward function only at the very end. After you’ve done 10 minutes of work, I’m not going to tell you whether you did well or not. I’m going to tell you at every single step of the way how well you’re doing. The problem is that, by then, you have partial solutions and you don’t know how to assign credit. So when you get the right answer, it’s just an equality match to the answer. It’s very simple to implement. If you’re doing process supervision, how do you assign partial credit in an automatable way? It’s not obvious how you do it. Lots of labs are trying to do it with these LLM judges. You get LLMs to try to do it. You prompt an LLM, ‘Hey, look at a partial solution of a student. How well do you think they’re doing if the answer is this?’ and they try to tune the prompt. The reason that this is tricky is quite subtle. It’s the fact that anytime you use an LLM to assign a reward, those LLMs are giant things with billions of parameters, and they’re gameable. If you’re reinforcement learning with respect to them, you will find adversarial examples for your LLM judges, almost guaranteed.” 19 ↩
-
I think, in some sense, we are reverse engineering the rules of logic but encode them in the weights of the model rather than explicitly programming them. The model learns to generate reasoning steps that lead to correct answers, but it doesn’t necessarily understand the underlying principles of logic in a human-like way. This is why the model can be very good at generating plausible-sounding reasoning that ultimately leads to incorrect conclusions. It has learned patterns of reasoning that often work, but it doesn’t have a deep understanding of why they work or when they might fail. It’s like we are brute-forcing the space of logical rules, rather than learning them. It’s not clear whether this is a problem, but it’s certainly different from how I learned math… ↩
-
There is an intense debate about what high ARC-AGI scores actually mean. Chollet and others argue that brute-force test-time compute and massive program search can game the benchmark without demonstrating true general reasoning. That’s a fair point, but even as a measure of “search efficiency under novel constraints,” the improvement curve is steep. ARC-AGI shows that allowing models to use more tokens increases their likelihood of solving the problem, consistent with the inference-time compute scaling story. ↩
-
There are two stronger versions of this counterargument: 1) AI Safety via Debate. I think it’s a creative idea, and might work for some problems, but it assumes the relevant disagreements can be decomposed into verifiable claims. For problems where the crux is aesthetic, or involves, e.g., competing values, decomposition may not be possible. 2) Environmental verification, i.e. an agent optimizing a marketing campaign doesn’t need a human to check if tastes have shifted. It can just A/B test it in the real world and verify via clicks, conversions, and revenue. This will work for some problems I currently put in category 3. But it only works when the metric you can measure actually captures what you care about. When it doesn’t, like when optimizing for clicks degrades trust, or when maximizing conversions selects for manipulative patterns, you’re back to needing human judgment about whether the metric itself is the right one. ↩
-
Full disclosure: I’m the CEO of Kognic, a company that builds annotation and verification tools for AI. So yes, I have a financial stake in human verification remaining valuable. Take that into account as you evaluate my argument. I’ve tried to reason from first principles here, but I’d be naive to pretend my perspective isn’t shaped by what I work on every day. ↩
-
“Low-hanging fruit” is of course relative! In 2025, the major technology companies collectively spent over $300 billion on AI-related infrastructure (data centres, GPUs, energy, and annotation), and the frontier labs raised tens of billions more in equity on top of that. In 2026, the projected figure approaches $700 billion. 20 That is an extraordinary amount of capital directed at extracting value from a (mostly) fixed supply of human-generated text. ↩
-
Full disclosure: I’m an investor in Intui, 24 a Swedish company building neuroscience-inspired AI systems that learn the way biological organisms do, i.e., through interaction with their environment, rather than through massive offline training on curated datasets. If anyone cracks continuous real-world learning, it will look something like what they’re doing. ↩
-
Yes, yes, I know, quantum computers, bla, bla, bla. Look, we don’t have quantum computers yet, so let’s save that for when it’s an actual thing, okay? They will make things very weird and very different again, but I can only think about so many weird things at a time, okay?! 😅😂 ↩
-
One important caveat: this argument assumes humans are the ultimate consumers of AI output. A growing share of AI work is machine-to-machine: an AI writes an API, another AI consumes it, and verification is entirely programmatic. In these loops, human “hidden states” are irrelevant, and the flywheel spins at full speed. My argument about human cost-effectiveness applies specifically to the parts of the economy where humans are the end consumer or where the output ultimately serves human preferences. That’s still most of the economy today, but the machine-to-machine slice is growing fast. ↩