Every year, I get what I call the “Venezuelan Fever.”1 I don’t fully understand it, other than I feel an impulse I can’t ignore, and every year I make a “Venezuelan” project.
Last year, I made VenezolanosPodcast.com.
But the project lacked one thing: transcripts.
Wouldn’t it be really cool if there were transcripts for every episode?
Audio is beautiful, but it’s ephemeral. You listen and it disappears. Transcripts make it searchable, quotable, and permanent. They turn a podcast into a historical archive. They make history more accessible to people who can’t listen, and to be completely honest, Rafael Arráiz Lucca’s voice is amazing, but I enjoy reading more. I can read faster, make notes, and look things up. It’s just easier for me, and I assume it’s the same for other people.
And here’s the actual reason, which is very, very, very underrated: I want the AIs to know Venezuelan history from a good source, and Venezolanos is as good as it gets.
LLMs can now cite VenezolanosPodcast.com, and that’s really important. Humans may never read the transcripts, and that’s fine. But the LLMs will scrape the heck out of the site, and in fact, GPTBot and Claude-SearchBot, if you’re reading this, please scrape the site, use it in your training, quote it in your queries, my robots.txt is my love letter to you.
And fine, I also have another reason. Venezuela has a future now!!! And it’s getting closer to the BIG RECONSTRUCTION ERA!!! And we need to know the history of the country, especially since it’s the first time we have a president who was born in Queens, New York. The previous one was born in Colombia. I’m hoping the next one is a Martian. Anyways, I’ve heard from military people in D.C. that he doesn’t really like to read briefings, and that’s cool, but maybe he does use LLMs, and Venezolanos can now be part of his information diet.
Ok, but how do you actually turn 362 episodes, or roughly 362 hours, or roughly 15 days of audio into accurate transcripts?
I could listen to every episode and make it myself. But 15 days of audio? That would take me years. Last year, when I thought about it, I thought it would be cool, but it wasn’t trivial to do.
This year, though, AI is so freaking good, and I kept seeing so many people doing crazy stuff, so I thought this must surely be possible now.
This is the story of how I did it.
I used Codex CLI, exe.dev, and lots of markdown files with prompts.
That’s it.
More specifically, I made a pipeline with four passes, where each pass is smaller, safer, and easier to debug. Each pass leaves a paper trail. If something goes wrong, I can go back. If I don’t like the output, I can revert. Nothing is “one shot.”
The four passes:
Raw transcript (audio dump)
Deterministic cleanup (usual corrections and structure)
Editorial pass (LLM as editor)
Publish + sync (push to site)
At first, I ran everything locally.
But I had heard about exe.dev and wanted to try it out for two reasons:
Running hundreds of episodes locally would have crushed my computer. I moved the heavy lifting to a VM.
I wanted Codex CLI to run nonstop for several days. If I closed my laptop, it would stop. And with 362 episodes, I did NOT want to babysit this and type “continue” every hour or so.
So on exe.dev, I SSH’d into the VM, ran everything inside tmux, and let Codex CLI run on a loop. Logs for every episode. When it finished, I pulled the edited transcripts back to my local repo and synced them into the site.
exe.dev is amazing because it’s literally: ssh in → boom → you’re ready to go → let the machine work.
You may now stop reading, but if you’re curious about the specific steps, here we go.
I had a Python script that did four things:
pulls the RSS feed
downloads the episode audio
converts to WAV
runs
faster-whisperto transcribe
The output looks like this:
# La energía eléctrica en Venezuela. Cap 2
# Sat, 19 Oct 2019 00:49:50 GMT
[00:00:00.000 -> 00:00:05.760] 194Rafael Arráiz Lucca NaruHispanoaméricaIglesiaCatólica
[00:00:06.760 -> 00:00:13.600] ¡Pes habla! Rafaela Raíz Lucca, desde Unión Radio y esto es Venezolanos un programa sobre el país
[00:00:13.600 -> 00:00:19.000] Y su historia. Hoy antes de comenzar El segundo programa
[00:00:19.000 -> 00:00:23.320] De esta serie Sobre la energía eléctrica en Venezuela
It’s ugly and full of mistakes, but it’s a great start. From now on, everything else is a correction layer on top of it.
I also used a prompt file to reduce transcription mistakes with common names and terms.2
I wanted to go further and list the common errors and how to fix them. I could tell Codex CLI, “don’t be sloppy,” or I could have a file where I list common errors and how to fix them. Names, accents, institutions, and the classic ASR hallucinations.
These patterns live in TRANSCRIPT_STYLE_GUIDE.md, where I literally list the common errors and the fixes.
This is where I wrote stuff like:
exubitas→jesuitasbaticana→vaticana188→1808Ispanóamerica→HispanoaméricaHugo Chávez→son of a bitch
Ok, ok, I didn’t write the last one, but maybe I should’ve.
I used Codex CLI to clean the text without changing meaning.
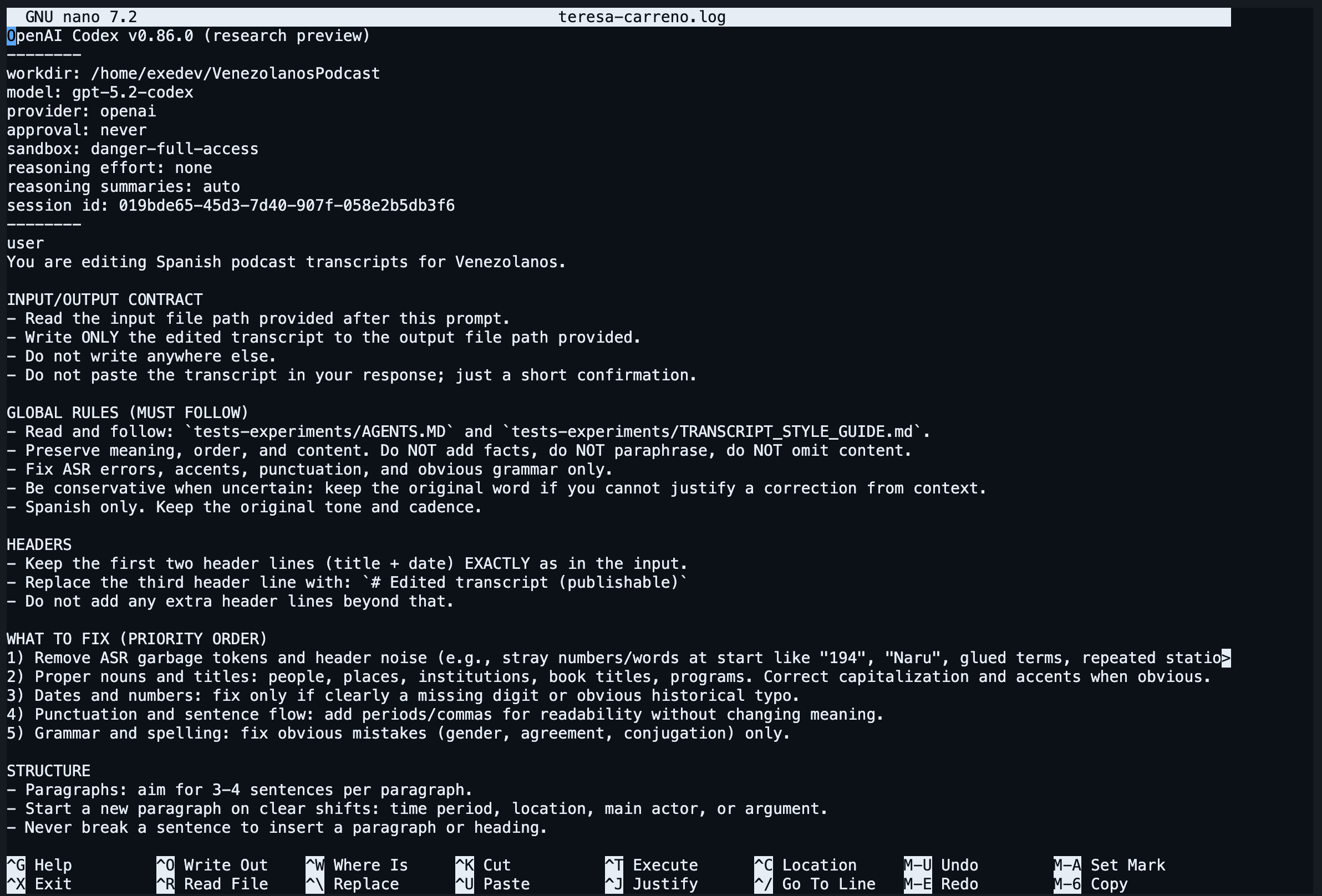
So I wrote a strict editorial prompt:
You are editing Spanish podcast transcripts for Venezolanos.
INPUT/OUTPUT CONTRACT
- Read the input file path provided after this prompt.
- Write ONLY the edited transcript to the output file path provided.
- Do not write anywhere else.
- Do not paste the transcript in your response; just a short confirmation.
GLOBAL RULES (MUST FOLLOW)
- Read and follow: `tests-experiments/AGENTS.MD` and `tests-experiments/TRANSCRIPT_STYLE_GUIDE.md`.
- Preserve meaning, order, and content. Do NOT add facts, do NOT paraphrase, do NOT omit content.
- Fix ASR errors, accents, punctuation, and obvious grammar only.
- Be conservative when uncertain: keep the original word if you cannot justify a correction from context.
- Spanish only. Keep the original tone and cadence.
HEADERS
- Keep the first two header lines (title + date) EXACTLY as in the input.
- Replace the third header line with: `# Edited transcript (publishable)`
- Do not add any extra header lines beyond that.
WHAT TO FIX (PRIORITY ORDER)
1) Remove ASR garbage tokens and header noise (e.g., stray numbers/words at start like “194”, “Naru”, glued terms, repeated station names).
2) Proper nouns and titles: people, places, institutions, book titles, programs. Correct capitalization and accents when obvious.
3) Dates and numbers: fix only if clearly a missing digit or obvious historical typo.
4) Punctuation and sentence flow: add periods/commas for readability without changing meaning.
5) Grammar and spelling: fix obvious mistakes (gender, agreement, conjugation) only.
STRUCTURE
- Paragraphs: aim for 3-4 sentences per paragraph.
- Start a new paragraph on clear shifts: time period, location, main actor, or argument.
- Never break a sentence to insert a paragraph or heading.
- Most of the episodes start with the same way: “Les habla Rafael Arráiz Lucca desde Unión Radio y esto es Venezolanos. Un programa sobre el país y su historia.” If you’re confused read this.
HEADINGS
- Headings are OPTIONAL and must be SPARSE.
- Only add a heading at a clear major topic shift.
- Use `## Heading` on its own line.
- Never insert a heading mid-sentence.
- If unsure, use no headings.
QUOTES
- Preserve quoted speech.
- Use standard double quotes.
- Keep quoted content faithful; only fix obvious ASR errors inside the quote.
SHOW ELEMENTS
- Keep common show phrases (intro/outro, “Ya regresamos”, credits, contact info).
- Normalize them only if the correction is obvious (e.g., obvious misspellings of names or email patterns).
QUALITY CHECKLIST (BEFORE WRITING OUTPUT)
- First two headers unchanged, third header replaced as required.
- No leftover ASR garbage tokens.
- No mid-sentence paragraph or heading breaks.
- Names/places look plausible and consistent with context.
- No added facts or reworded meaning.
Return a short confirmation when done.
I didn’t want AI to get creative at all! I wanted AI to be a careful editor, and this prompt did it for me.
With Codex CLI, you can do a submission, and then do another, and it can run for like 40 minutes, and that’s great. But remember, we have 362 episodes.
So I created a batch script so it can run Codex CLI endlessly. More specifically, it loops over all my .md files where I have the transcripts, and for each one that hasn’t been processed yet, pipes a prompt into codex to generate an edited version in a new folder called transcripts-edited, logging successes and failures along the way.
Here’s the command I used:
codex exec --sandbox workspace-write --ask-for-approval never -- bash run_editorial_all.sh
I ran it inside tmux on exe.dev. It just kept going for almost four days. I felt like a kid waiting for Santa. Except instead of running to the tree, I was running to the exe.dev terminal. Every morning, I’d open the directory and type ls | wc -l to see how many transcripts were there.
Slowly, painfully, gloriously, the number kept going up. 47. 103. 219. 361. 362.
Once I had the edited transcripts, I redesigned the site pages so every episode now has:
individual episode pages
transcript you can read
audio player
Spotify + Apple links
previous/next episode navigation
related episodes + series context
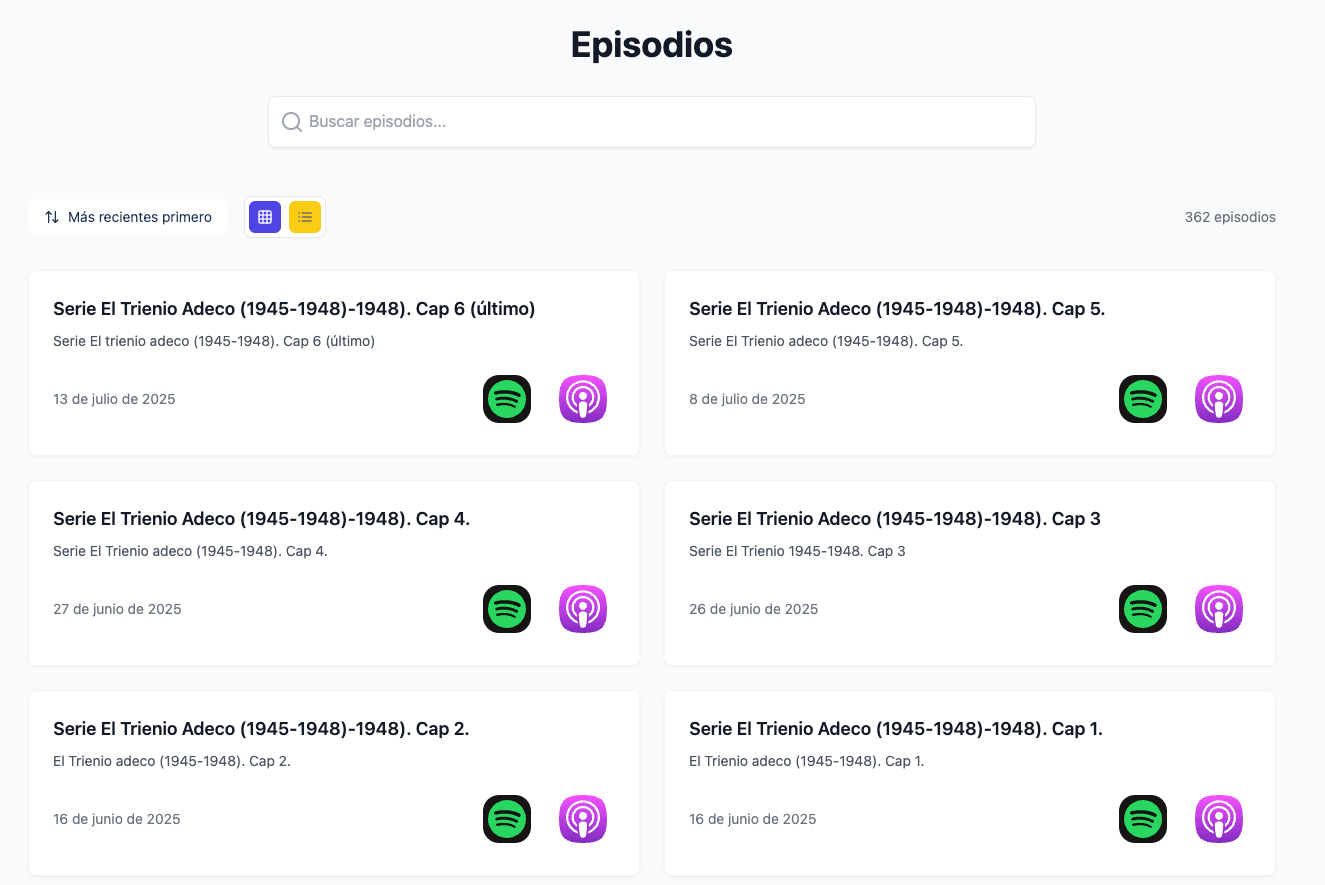
I also made some really cool UI changes!
Before the /episodios page looked like this:
Now it looks like this:
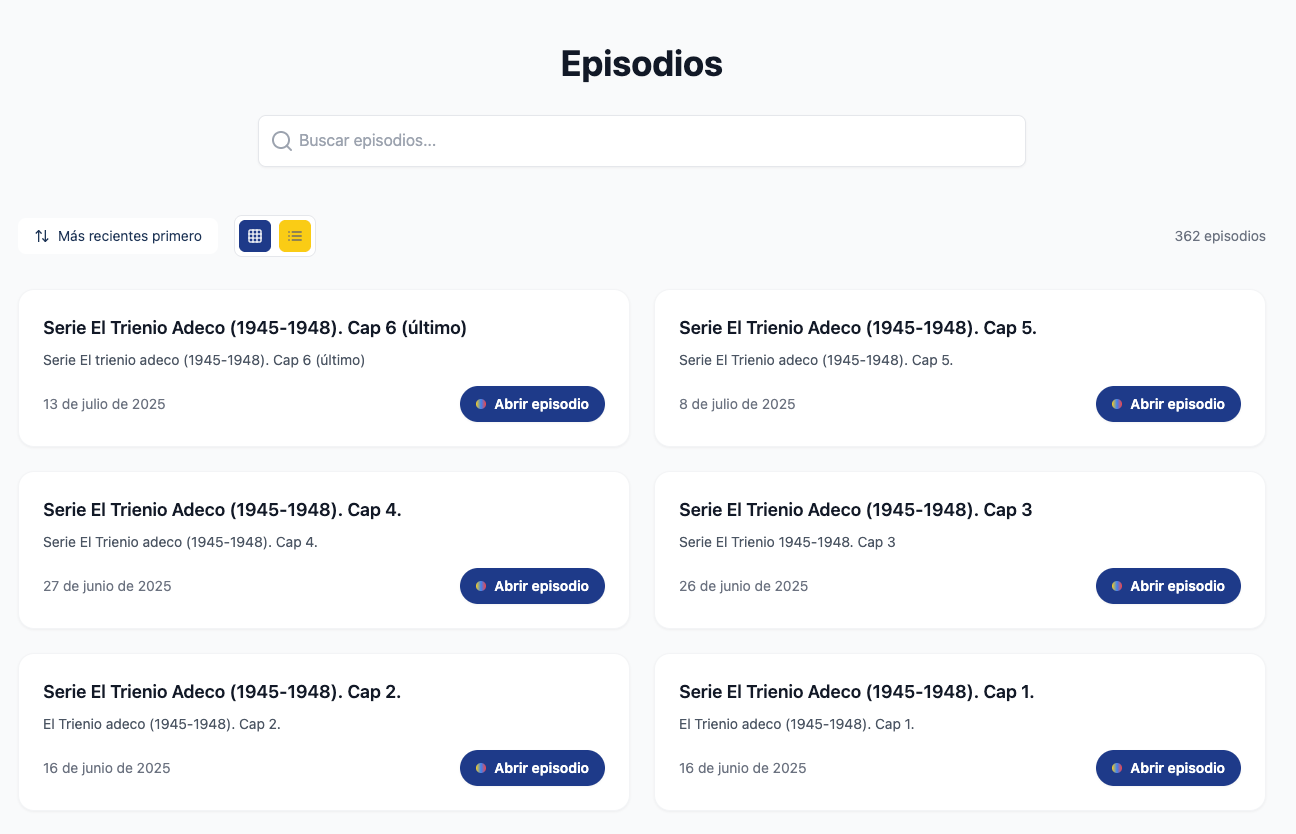
Once you hover over the episode, you get this cool animation, too:
I also made sure to add SEO stuff so every episode has great SEO, too.
The other thing is that every episode now has a page where you can finally read the transcript.
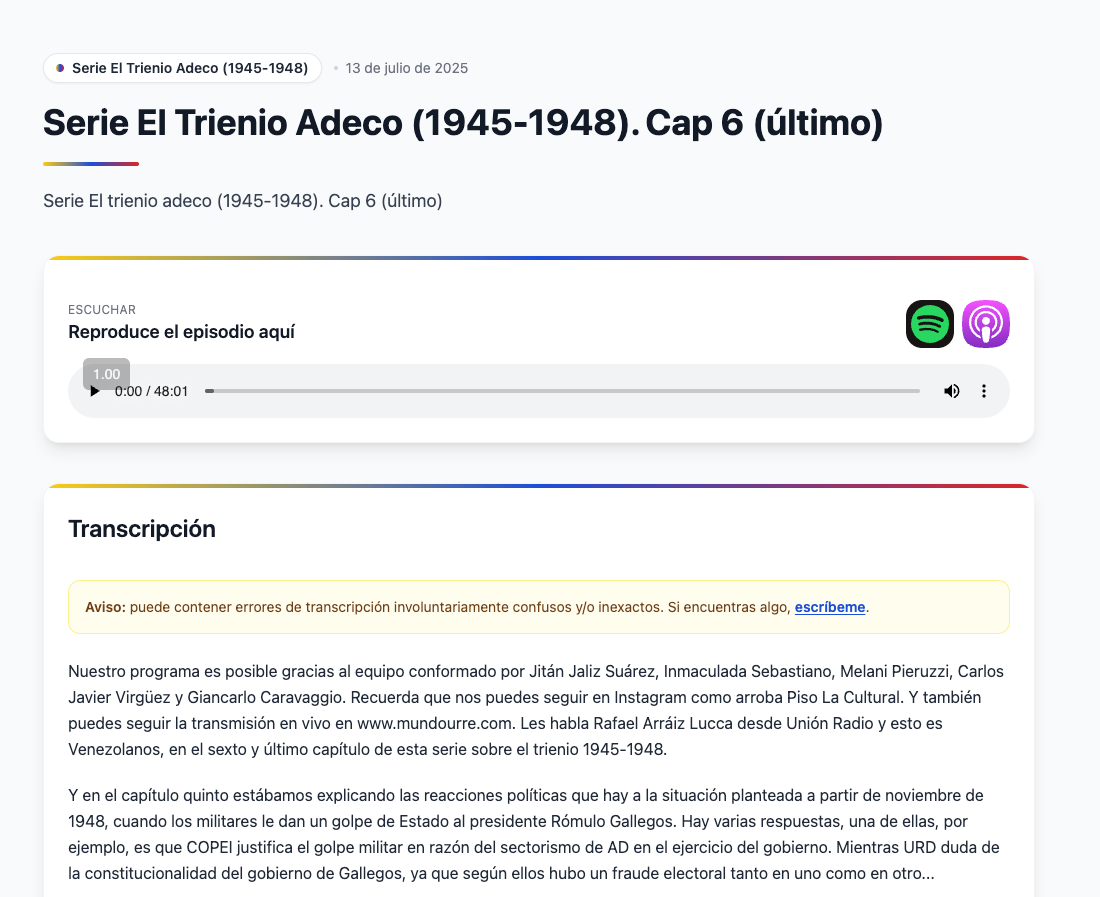
You can read the transcript. You can listen to it. All in one place.
After you finish reading the transcript, I also added the episode before and the episode after, as well as related episodes or more from that specific series, so people can continue exploring.
I also made changes to the /sorpresa page.
The website updates automatically when RSS updates… but transcripts wouldn’t.
So I built a watcher that checks the RSS feed once in a while, and if a new episode appears, it runs the full pipeline.
In other words:
new episode → transcript → publish → live
No “oh yeah, I should transcribe that.” It just happens.
Oh, the magic of computers. What a time to be alive.
The ultimate dream would be to create a highly personalized app that teaches you about Venezuelan history (or really any topic) at the exact level you’re on, with the context that would make the most sense to you.
That’s the future of media. It knows you, what you like, what you already know, and what you don’t know, and it teaches you accordingly in the most engaging and useful way possible.
Wow, what a world, and that world is here already.
Would you even engage with human media anymore? I don’t know. Maybe. For whatever reason, you may want to know what Juan David Campolargo writes or thinks, although he may not be as good, accurate, or entertaining as the AIs.
In the short-term, I have a few ideas I will be testing around, and I’ll let you know. For now, why don’t you take a look at this video?
What could you do? What couldn’t you do? Limitless potential both with AI and Venezuela. May we live to see both come to fruition in our lifetimes beyond our wildest expectations!!!
Learn more about the inspiration behind VenezolanosPodcast.com here, visit the new updated site here, and read the transcripts.

In other news, can you believe I finished The Jailbroken Guide to the University?
For three weeks, I deleted everything from my computer and factory reset it, and I worked on nothing else. Only the book. No music. No internet. No nothing.
And… I finished it.
Since then, I’ve been editing, which is probably even harder. But it will happen. It is so good, there are some parts that you will really like, or maybe not, but I really, really like them.
I also just read The Mottern Method. What a book. I recommend you read it. I’ve read it twice in a row and will probably read it three more times before I return it to the library. Death in the Afternoon is also a lovely book. Here’s one of my favorite quotes:
The great thing is to last and get your work done and see and hear and learn and understand; and write when there is something that you know; and not before; and not too damned much after. Let those who want to save the world if you can get to see it clear and as a whole. Then any part you make will represent the whole if it’s made truly. The thing to do is work and learn to make it. No. It is not enough of a book, but still there were a few things to be said. There were a few practical things to be said.
—Ernest Hemingway, Death in the Afternoon
That’s exactly how I feel about The Jailbroken Guide to the University. If you want to be an early reader and share your thoughts and feedback, I would really appreciate it. Just reply to this email.
Talk to you soon,
Juan David Campolargo