
Durable executions frameworks center their pitches on a mix of vague promises, metaphors, and anecdotes. This post takes a different route: a rigorous definition, independent of any specific framework, along with a conceptual foundation and a minimal working implementation.
Interested in durable executions? Join the Resonate Discord
Recently, you might have noticed a surge of interest in durable executions; with the transformation of LLMs from turn-based chats to continuously running agents, communicating with each other, orchestrating tool calls, and waiting on humans for confirmation, durable executions are shifting from niche to mainstream.
Every durable execution framework tells a similar story: write normal code, get fault tolerance. Yet none of them define what “normal code” or “fault tolerance” means. Instead they tack on a list of seemingly unrelated claims, such as “tracks your state”, “runs for a long time”, or “sleeps for days”, as though the connections were self-evident1.
The promise of writing normal code is appealing. However, what counts as normal? Some frameworks require developers to use DSLs and structure their applications as workflows and activities—not JSON or YAML encoded directed acyclic graphs (DAGs) but still proprietary programming models with steep learning curves.
The promise of fault tolerance is equally appealing. However, not all failures are created equal. For example, if a payment provider declines a credit card charge, durable executions cannot rectify that situation. If an execution crashes while a payment provider processes a credit card charge, durable executions earn their name.
Resonate’s durable execution framework, Distributed Async Await, is designed around a single principle: simplicity. Not only simple to use, but simple to reason about. That requires a rigorous mental model of durable executions—instead of hand-waving anecdotes and metaphors.
Instead of sleep, crash, fault, or failure, we will reason in terms of interruptions. An interruption consists of two phases:
Suspension of an execution
Resumption of an execution
A suspension can be internally triggered (e.g., a sleep) or externally triggered (e.g., a crash). Either way, the defining characteristic of durability is the ability to suspend on one process and resume on another process (in practice that may be a green thread, an os thread, an os process, a container, or a machine).
Borrowing a technique from programming language theory, we use a simple, idealized case to specify the desired behavior of a complex, realistic case: consider a program P running on a runtime R. In the ideal case, execution proceeds without interruptions-I. The program runs from start to finish, producing some observable behavior, a trace T.
P/(R−I) = TIn words: Program
Prunning on runtimeRwithout the possibility of interruptions-Iproduces trace T
Now introduce interruptions. Execution may suspend and resume, potentially on a different process. We want the same observable behavior T as if no interruption occurred. In other words, we want interruption tolerant executions.
How do we achieve this? There are two approaches, two knobs we can dial.
Modify the program. Transform P into P′ such that:
P/(R−I) ≣ P′/(R+I)In words: Program
Prunning on runtimeRwithout the possibility of interruptions-Iproduces an equivalent trace to a modified programP`running on the same runtimeRwith the possibility of interruptions+I
The developer explicitly handles interruptions. They add snapshotting, checkpointing, and recovery logic. The program becomes aware of and responsible for interruption handling, riddled with interrupt specific concerns.
Interruption-aware function definitions result in
interruption-tolerant function executions.
Modify the runtime. Transform R into R′ such that:
P/(R−I) ≣ P/(R′+I)In words: Program
Prunning on runtimeRwithout the possibility of interruptions-Iproduces an equivalent trace to the same programPrunning on a modified runtimeR’with the possibility of interruptions+I
The programmer writes the same program P. The runtime handles interruptions transparently. The program remains agnostic to whether interruptions occur.
Interruption-agnostic function definitions result in interruption-tolerant function executions.
We can now formulate a precise definition: Durable Executions are Interruption-Agnostic Definitions of Functions that result in Interruption-Tolerant Executions of Functions.
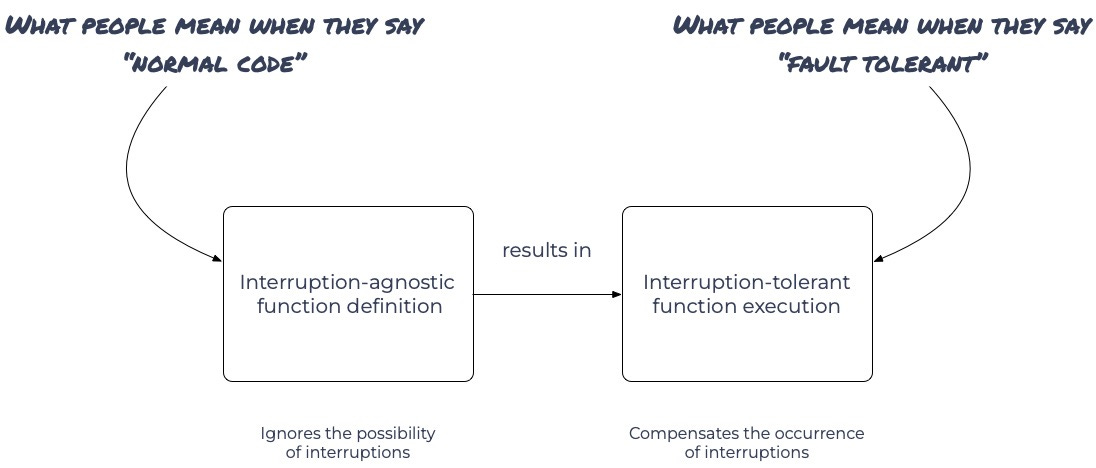
The definition has two parts:
Interruption-Agnostic Definition: The function definition ignores the possibility of interruptions.
Interruption-Tolerant Execution: The function execution compensates for the occurrence of interruptions.
According to this definition, “normal code” refers to function definitions that are interruption-agnostic i.e. do not account for the possibility of interruptions while “fault-tolerant” refers to function executions that are interruption-tolerant i.e. compensate for the occurrence of interruptions and show the same observable behavior whether interruptions occur or not.
Can we implement durable executions without rewriting compilers and runtimes from scratch? Can we implement them with a language-specific SDK? While this requires some syntactic compromises (e.g., the use of yield instead of await or the use of decorators), we can preserve normal code semantics: functions calling functions calling functions, with the usual control structures such as if, for, while, try-catch.
Let’s try.
A note: our durable executions won’t actually be durable. We’re focusing on execution mechanics, not persistence. The runtimes below keep state in memory to illustrate how execution unfolds, not how storage works.
Consider a simple program of nested function calls. A function is implemented as a coroutine (a.k.a generator):
function* foo(): Generator<any, number, any> {
let a = yield call(bar, 21);
let b = yield call(bar, 42);
return a + b;
}
function* bar(arg: number): Generator<any, number, any> {
let a = yield call(baz, arg);
let b = yield call(baz, arg);
return a + b;
}
function* baz(arg: number): Generator<any, number, any> {
return 2 * arg;
}yield call(function, arguments) marks function calls: foo calls bar twice, bar calls baz twice, and baz performs a simple computation.
The expected result is:
baz(21)returns42, sobar(21)returns42 + 42 = 84baz(42)returns84, sobar(42)returns84 + 84 = 168foo()returns84 + 168 = 252
The call helper creates a descriptor for the function call:
class Call {
constructor(
public func: Function,
public args: any[],
) {}
}
function call(func: Function, ...args: any[]) {
return new Call(func, args);
}We implement two different runtimes, one that yields correct and complete results only without interruptions and one that yields correct and complete results with interruptions.
The resume runtime executes coroutines in a single pass. When a Call effect is yielded, the runtime executes the callee, passes the result to the caller, and resumes:
function resume(func: Function, args: any[]): any {
let coroutine = func(...args);
let value: any = undefined;
while (true) {
let result = coroutine.next(value);
if (result.done) {
return result.value;
}
const call = result.value as Call;
value = execute(call.func, call.args);
}
}This runtime implements the easy case: uninterrupted executions. The run function simply invokes resume, which executes in one turn:
function run(func: Function, ...args: any[]): any {
return resume(func, args);
}Running foo yields:
console.log(run(foo)) => 252The restart runtime executes coroutines in many passes. When a Call effect is yielded, the runtime checks the cache and either:
cache miss
Adds the call to the cache and interruptscache hit, pending
Executes the callee, adds the result to the cache, and interruptscache hit, resolved
Passes the cached result to the caller and resumes
type Result =
{ status: “pending” }
| { status: “resolved”; value: any };
function restrart(
func: Function,
args: any[],
pid: string,
env: Record<string, Result>
): any {
const coroutine = func(...args);
let value: any = undefined;
let count = 0;
while (true) {
const result = coroutine.next(value);
if (result.done) {
return result.value;
}
const call = result.value as Call;
// Generate a deterministic call site id
const cid = `${pid}.${count++}`;
if (!(cid in env)) {
env[cid] = { status: “pending” };
throw new Error(”Interrupt”);
}
const cache = env[cid];
if (cache.status === “pending”) {
const res = execute(call.func, call.args, cid, env);
env[cid] = { status: “resolved”, value: res };
throw new Error(”Interrupt”);
}
value = cache.value;
}
}A note on identity and determinism: The caller provides a root ID (e.g.,
0), and the runtime generates child IDs based on position in the call tree (e.g.,0.0,0.1,0.1.0). On restart, these IDs map to cached results. This requires executions to be deterministic with respect to the call tree.A note on idempotence: If an execution is interrupted after the function executes but before the result is recorded, the function will be executed again. Therefore, in practice, functions must be idempotent.
This runtime implements the hard case: aggressively interrupted executions. The run function loops until completion, catching interrupts and restarting:
function run(id: string, func: Function, ...args: any[]): any {
const env: Record<string, Result> = {};
while (true) {
try {
return restart(foo, args, id, env);
} catch (e) {
if (e.message === “Interrupt”) continue;
throw e;
}
}
}However, despite constant interruptions, the final result is identical to uninterrupted execution:
console.log(run("0", foo)) => 252The program is unchanged. The runtime compensates for interruptions. This is exactly what our definition promised: interruption-agnostic definitions yielding interruption-tolerant executions.
Notice what we did not do:
We did not use a DSL or workflows and activities
We did not write checkpointing code
We did not write serialization code
We did not write recovery code
Did we write normal code? The syntax is unfamiliar, yield call(bar, 21) instead of bar(21), coroutines instead of traditional functions. However, the semantics are unchanged. We didn’t need to invent a proprietary programming model.
Durable executions are not fuzzy but a well-defined concept: Interruption-Agnostic Definitions of Functions that result in Interruption-Tolerant Executions of Functions—made possible by reliable restarts and memoization.
So the next time someone tells you that durable executions let you “write normal code and get fault tolerance,” you know exactly what that means.
Get started in minutes and explore our examples: a durable deep research agent that scales to hundreds of subagents in under 110 lines, or a durable countdown that runs for days, weeks, or months in under 30 lines of code. Run them on your laptop, your cluster, or even on serverless platforms—the code stays the same.
If you want to learn more about the mechanics of Resonate, check out my Systems Distributed ‘25 presentation, where I walk through Resonate’s programming model and execution model.