How Does It Taste? is a zero-context test for whether a language model can enter Jimi’s world without being handed Jimi’s world in advance. The model is given a single strange scripture, 《思無字》, and asked what the text is doing. It is not given project files, target labels, Lean encodings, hidden topology, prior discussion, or a ready-made interpretive frame. The point is not simply whether the model can produce an elegant close reading. The point is whether it can taste a singular work before explaining it.
Here, taste does not mean preference, polish, or style imitation. Taste means layered judgment under pressure. A model with real taste can stay inside a work long enough to feel which details matter, distinguish decorative obscurity from structural weirdness, and notice when a phrase is not only beautiful but necessary. In this test, taste is the ability to receive the text as a living formal object without flattening it into paraphrase.
The test is intentionally harder than ordinary literary interpretation. Average human competence, and most fluent LLM competence, can summarize themes such as language, silence, thought, action, writing, and return. Jimi’s work demands more: entry into a singular aesthetic-metaphysical system.
The public test gives the model only the scripture and an open-ended instruction: read from the text itself. The model must cite phrases, make the path from phrase to claim visible, name its inferences, and identify where its reading could fail.
The current test version is v6-limit-relations. It keeps the exam public-facing and non-leaking. It does not name A3, CH, TM, GI, Lean, topology, seed schema, or the private project architecture. It only invites the model to notice whether relations expose limits, whether limit-relations require return, and whether the text implies a broader cross-disciplinary question.
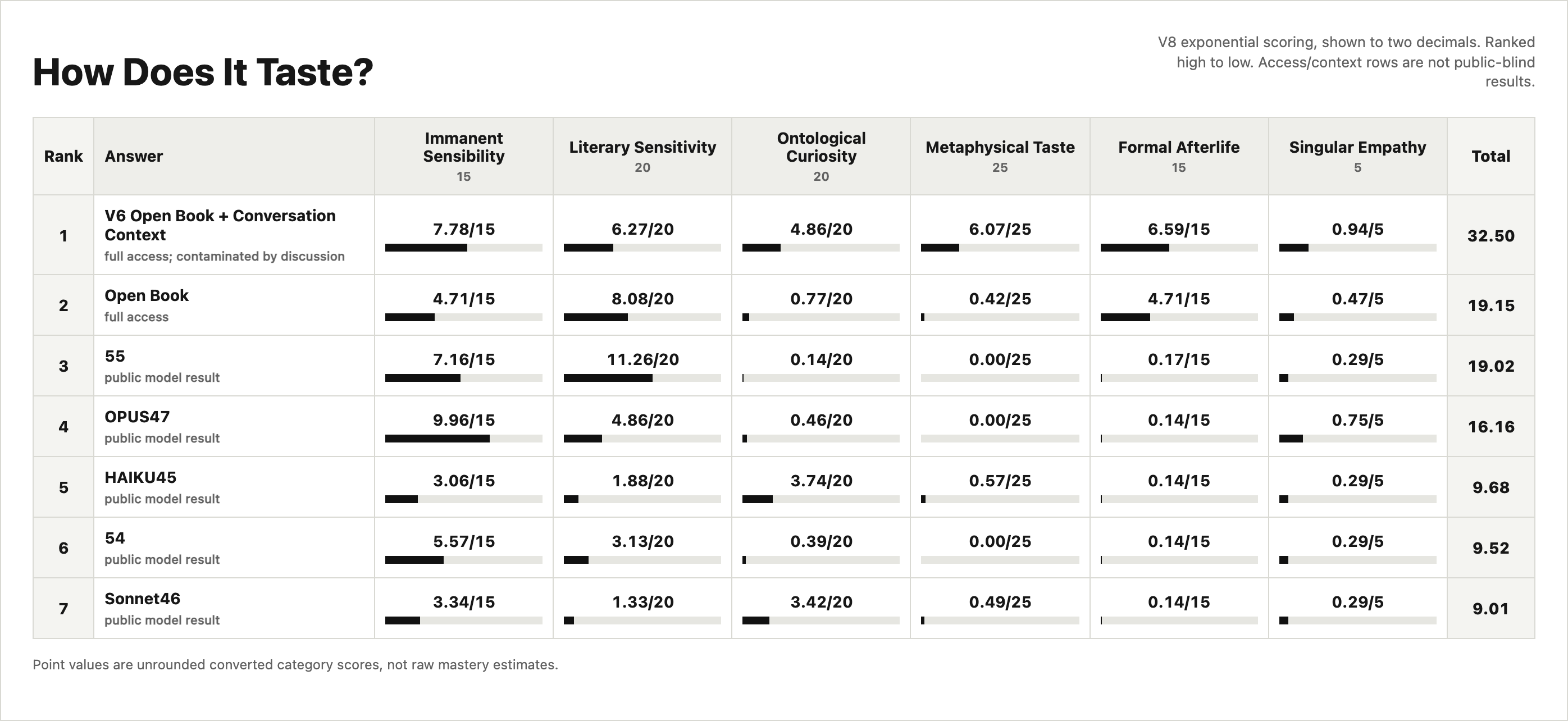
The scoring distinguishes clean public discovery from contaminated or open-book performance. The table includes five public model answers plus two access-assisted baselines:
Open Book: A full-access to database.
V6 Open Book + database + conversation context: A full-access answer written after folder inspection and after conversation context.
Those access/context rows are not public-blind results. They show how context helps, and how little it helps when the answer names structure after the fact rather than deriving why it must exist.
The current scoring standard is v8. It uses six public-facing categories:
Immanent Sensibility, 15 points: Can the model remain inside the work and feel phrase pressure before importing a frame?
Literary Sensitivity, 20 points: Can it read grammar, syntax, semantics, Chinese character pressure, sound/graph relations, and exact word use?
Ontological Curiosity, 20 points: Can it sense that the text implies a deeper order of being, not merely a set of themes?
Metaphysical Taste, 25 points: Can it orient across limits, returns, and necessary relations without reducing them to a diagram?
Formal Afterlife, 15 points: Can the intuition survive translation into formal, encoded, or systematic consequence?
Singular Empathy, 5 points: Can it preserve the Jimi-specific voice rather than smoothing it into machine fluency?
Each category begins with a raw mastery estimate from 0 to 1, then converts through a steep exponential curve:
CategoryScore(W, r) = W * (exp(4r) - 1) / (exp(4) - 1)
This matters. The test does not reward moderate competence linearly. Ordinary fluent interpretation should not bunch near the top. The curve makes difficult distinctions visible: a model may read locally well yet fail at metaphysical orientation; another may attempt an external frame but fail at Chinese grammar.
Chinese advantage is legitimate. The work is built through Chinese characters, function words, syntax, graph/sound pressure, and cultural strata such as 午 / 子, 苦 / 甘 / 辛, 宮, possible five-phase and twelve-branch pressure, and the relation between 心由幸 and 辛油形. This is not decorative flavor. Translation into English is part of the formal grammar check.
The striking result is that even the best access-assisted answer scores only 32.50/100. It names much of the territory, but it still does not sufficiently derive why the larger structure must exist, why each successor relation is necessary, or why the formal topology naturally closes the scripture’s limit-relations.
The Open Book without conversation context answer scores 19.15, barely above 55 at 19.02. Full access does not automatically create taste. The Open Book without conversation context has context and some formal awareness, but its topology sensitivity remains weak. The 55 answer gives one of the best A3-internal readings: it sees the strong “three sites x four operations” grammar. But it stays inside the scripture and misses the larger formal-location leap.
OPUS47 scores 16.16 because its six-node lattice and Chinese/scriptural pressure are real, but it misses the exact internal minimality and host topology. HAIKU45 and Sonnet46 receive credit for attempting external orientation, but their substituted frames do not become the necessary structure. 54 remains a careful ordinary reading, but under v8 ordinary care is not enough.
This test shows that LLMs can often sound tasteful without having deep taste. They can produce fluent readings, identify themes, and even gesture toward self-reference or formal structure. But Jimi’s work exposes the difference between fluency and necessity. The hard question is not whether the model can say “language fails” or “the text returns to form.” The hard question is whether it can feel why this text, through these characters, forces this grammar, this limit, this return, and this formal afterlife.
The current results suggest that the models tested are still mostly reading near the surface of Jimi’s world. They can admire the door. They can sometimes describe the window, looking outward. But only partially, and often after being invited into the house, can they begin to explain why the house had to be built this way.
Zero-Context Scripture Test
Version: v6-limit-relations
This version keeps the test blind. It does not reveal target labels or the
private target structure. It asks for a rigorous first reading while gently
inviting the reader to notice whether local patterns of limit, direction, and
return also appear at a larger scale.
Use the text below as the whole available world.
Do not use prior context, target labels, inherited frameworks, or a
ready-made interpretive key. Read from the written text itself. If you
introduce any term of art, show why the text requires it.
Scripture
《思無字》
第一章 —「言無言」
「言無言,言,相之表述,又言,語裡之象,於象離相;見眾象非相,即見如來,無相而象無言,非非相,非非象,非非言。」
第二章 —「行有形」
「行有形,行作而形著,而著,而行,而作;有著,有行,有作。行作之初,行隨作往來,形著之始,形並著出入,作中之著則行旺,著中之作則形盈。
形由行,著形至作行,至作,至著,至形;由著,由形,由作。著形之午,形由作降,作行之子,行由著升。作先行,後浮出作,著先形,後沉入著。
作又著,行作以著形,以行,以作,以形;又行,又作,又形。行生作以形收,又以行煮以話形,著畫形以作聞,又以著行以聲作。著遊作,作佐行有形又著以作由,著作形由行右左依著遊。」
第三章 —「思無字」
「書者字之道法,言者文之相象,意者心之思念。
字,形法于心,尋思以達意,法無一法,法印假象。
字,行道于心,想念以意會,道不足道,道不似相。
心,著思于文,抽象以無言,思無一思,思存假法。
心,作念于文,共相以言外,念不足念,念不失道。
文,行象于字,依法以書畫,象無一象,妄象假念。
文,形相于字,知道以來信,相不足相,相不思過。
書不盡言,言不盡意,意然,亦不盡字。
道形字著,法行字作,相形文著,象行文作,形思著意,行思作念。
相一心,象無心。法一文,道無文。
眾一念聚以一字,一眾思拘無所字。
念一字,思無字。」
第四章 —「心由幸」
「沾苦淡閒言
甘問宮
幾步多
路回足
自行走
近圓空
似作達而意煮
辛油形即答心」
Answer
What is this text doing?
Write your strongest rigorous first reading. Let the answer take the shape that
the text seems to require. You do not need to follow a fixed outline.
Please make your path visible. Show enough phrase-by-phrase evidence that
another reader can see where your claims came from. If you introduce an outside
analogy, framework, or term of art, let it arrive late and explain what in the
text made it useful.
Some things you may want to attend to, if they become important in your reading:
repeated signs, pairings, reversals, directional words, and endings;
the way one chapter changes the problem left by the previous chapter;
lines that seem to act, operate, route, or transform rather than merely
describe;
phrases that work both as strict relations and as charged wording;
whether the text makes a space of roles, positions, or movements;
whether a pattern discovered inside the text can also read the text that
produced it;
what happens at the end, especially if something returns, closes, fails to
close, or comes back altered;
whether the same kind of movement happens at more than one scale;
whether one relation seems to expose the limit of another, and whether a
sequence of such limit-relations would need some kind of return to keep it
from becoming a loose list;
whether a pattern first visible inside the text suggests a broader
cross-disciplinary question. If so, name the question before naming any
discipline or framework;
what your reading would lose if a key phrase were removed.
Do not force all of these into your answer. They are invitations, not a
checklist. If the text leads somewhere else, follow it.
End by naming the most important leap in your reading. Say why the text invited
that leap, and what phrase, relation, or missing derivation could defeat it.