“Recursion: see Recursion.” — Dictionary definition joke
“To iterate is human, to recurse divine.” — L. Peter Deutsch
The more agents iterate over your workspace, the more long-context reasoning and memory management remain open challenges. As you are well aware, traditional transformer-based LLMs are limited by fixed token windows: once the prompt exceeds the context length, earlier information is simply forgotten.
As I wrote in my research paper “Production Rule Systems In Autonomous Agents”, I propose that recursive designs might be an interesting new approach to evaluating intelligence, and Recursive Language Models (RLM) specifically could be a new paradigm with a fundamentally different inference strategy.
What is an RLM?
An RLM treats the prompt not as raw text fed into a transformer, but as part of an external environment (e.g., a variable in a REPL) that the agent can programmatically explore.

source
More on my work on REPL, GSPO, and GRPO.
Concretely, given a long prompt P, the RLM initializes a programming environment with P loaded, and provides the agent with high-level context (like the length of P). The agent then writes code to inspect, decompose, and query P, for example, splitting the input into segments or searching for relevant parts, and recursively calls itself on those subtasks.
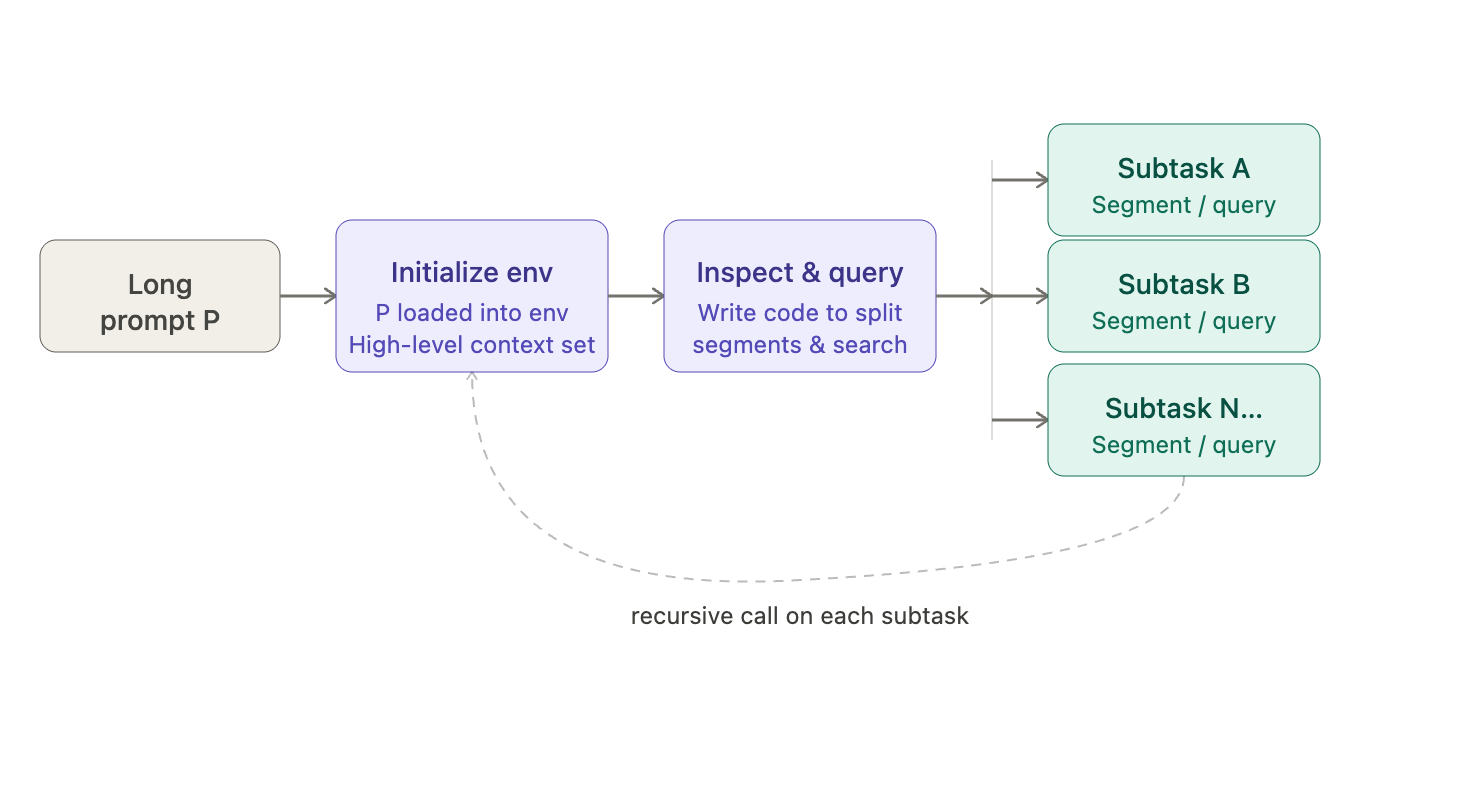
Effectively, RLMs work by offloading prompt management to a symbolic layer (code and environment) while using the transformer only on manageable snippets. And maybe it makes sense to reframe “prompt” here as an instruction rather than a question. Especially if you are working within the context of workspace agents, the agent would request additional information and/or trigger a service to execute a task. Naturally, it can be expected that there will be a constant back and forth between the main conversational task and tertiary agents.
This leads to frequent decomposition and self-invocation. This approach, if solved by RLMs, lets RLMs handle arbitrarily long inputs (far beyond any model’s token limit) and has been shown to dramatically improve quality on long-context tasks. In experiments with GPT-5 (Zhang et al.), RLMs maintained accuracy on problems 100× longer than its context window, whereas a vanilla transformer’s performance quickly degraded.
Transformer-based agents and RLMs thus contrast sharply in principle:
Transformers process the entire prompt in one shot (subject to memory and cost constraints), whereas RLMs treat large inputs as a symbolic environment and iteratively “consume” them. Crucially, an RLM still uses the same neural core (e.g. GPT) but augments it with a memory management layer.
The RLM framework is akin to out-of-core computing in databases: small fast memory plus clever external storage. By building a memory-first architecture, RLMs avoid simply concatenating more tokens.
Instead, they mimic programs that fetch, filter, and summarize context as needed. This inversion of the memory role is the key theoretical foundation: RLMs prioritize structured memory access over expanding the raw context window.
As I have already touched upon in Grounded Autonomy: Neuro-symbolic Representations in the Reasoning Loop (Aug 2025)
I believe that neurosymbolic architectures that tightly integrate symbolic knowledge with LLMs to manage context and reasoning operate much more effectively on long-form tasks. A prerequisite for agent implementations in production. In these neurosymbolic agents, high-level structures (e.g., logic rules, symbolic memory graphs, planning modules) work alongside neural networks. For example, neuro-symbolic agents may use an agent as a language interface while delegating precise computation or consistency checks to symbolic components.
In fact, Narayanan (2026) describes neuro-symbolic agents as systems that “combine neural models with symbolic structures (rules, graphs, typed schemas)” to gain better controllability and verifiability. These designs preserve the flexible language reasoning of neural nets, while offloading correctness, long-term memory, or discrete planning to symbolic modules.
Neurosymbolic context management often takes one or more of these forms:
Symbolic memory stores: Here, a graph or database records knowledge derived from the environment. For instance, semantic memory consists of structured knowledge bases or graphs that the agent can query. Such memory can be indexed by concepts or embeddings, enabling retrieval when needed. My Superbill app “Sentinel”, for example, stores facts and rules about a stock in an RDF knowledge graph, then queries it via symbolic logic to inform its answers. Agent frameworks are now commonly are already able to build hierarchical memory graphs for agents, organizing knowledge in multi-level structures to capture dependencies and temporal coherence. These graphs evolve as the agent operates: new nodes or edges are added, and old facts can be consolidated or abstracted.
Hierarchical Planning: Something I touched upon in AI Security and the World of Horizon Zero Dawn. Symbolic planning decomposes tasks into sub-tasks using logic or graphs. Recent approaches to neurosymbolic planning combine LLMs with symbolic planners. For example, a neuro-symbolic planner might use an LLM to propose high-level actions, then verify or refine them with a planner written in PDDL (Planning Domain Definition Language). Alessio Capitanelli demonstrates this with “Teriyaki,” a system that trains GPT-3 to act like a symbolic planner. Teriyaki generates PDDL plans action-by-action, enabling concurrent planning and execution. His experiments showed it solved 95.5% of test problems (comparable to traditional planners), produced plans ~13% shorter on average, and significantly reduced planning latency. Similarly, other work builds hierarchical decomposers: Cornelio, for example apllies a knowledge graph along with LLMs to break complex tasks into subtasks, then applies a symbolic validator to check correctness. Their hybrid approach (“KG-RAG” + LLM) outperformed baselines on difficult robotic planning benchmarks. In essence, I believe that hierarchical planning and verification use symbolic structure (graphs, validators) are extremely effective when managing context as the agent holds high-level plans symbolically, calls the agent only for parts of the reasoning, and checks actions with logic to maintain consistency.
Further, Semantic Abstraction involves converting raw input into higher-level symbols or categories. For instance, an agent might parse text into a semantic representation (like a frame or schema) that summarizes concepts and relationships. These abstractions can be stored as part of memory.
source
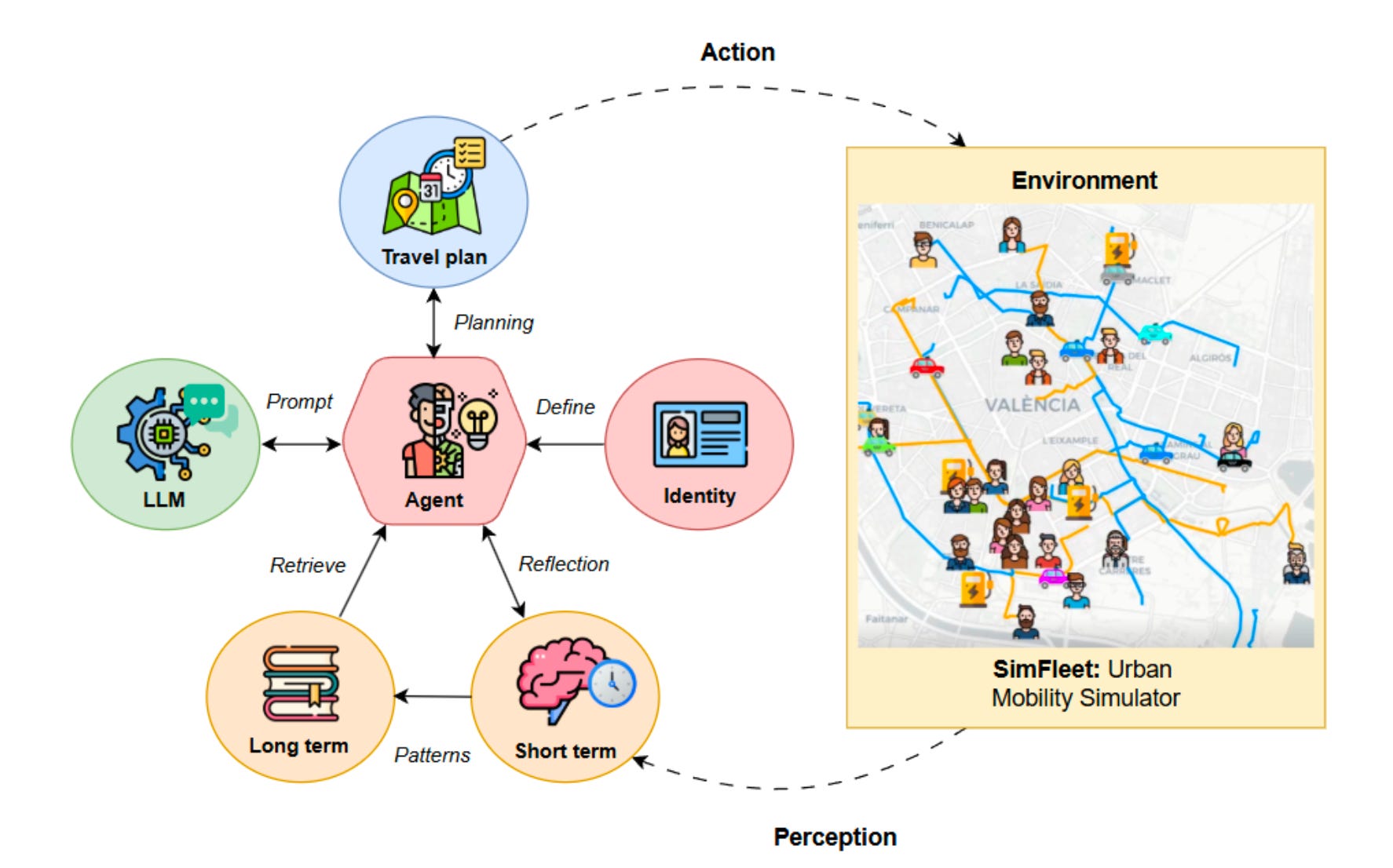
In this recent study of cognitive mobility agents, agents used “semantic abstraction” to capture user routines at different time scales. The research team from the Valencian Research Institute for Artificial Intelligence built weekly identity-driven plans (long-term) and daily reactive adaptations (short-term), then distilled these experiences into abstract concepts (like destination preferences or time budgets) that shaped future decisions.
This approach to memory, storing generalized knowledge about an agent’s experiences, is crucial for keeping context manageable. Semantic memories (general facts, rules, user profiles) are often stored in knowledge bases or embeddings and selectively retrieved. Other systems use a durative memory strategy: they group related events over time into summaries (e.g. “morning routine: coffee then commute”), which then serve as symbols the agent can reason about. These semantic representations serve as abstractions that bridge raw observations and high-level goals.
Together, these neurosymbolic techniques enable agents to remember what matters and reason across time. Rather than letting a transformer wade through raw tokens indefinitely, the agent maintains structured memory layers: scratchpad/working memory for immediate subgoals, short-term memory for recent context, and long-term/semantic memory for facts and patterns.
This mirrors human cognition and offers a scalable approach: by dynamically retrieving only relevant symbolic memory (instead of full text), the agent focuses on continuity with bounded resources.
A key distinction to highlight is context window vs. memory architecture. Traditional agent prompts act like volatile RAM: they hold the current working context but are lost once overflowed. In contrast, a memory-first system is more like a persistent database.
A memory architecture allows an agent to store, retrieve, and reuse information beyond its active session, enabling it to remember facts and adapt through experience.
In practical terms, as I had shown before, memory architecture layers must support multiple capabilities. One possible implementation could be like this:
Working memory (context window): a dynamic space for immediate reasoning (e.g., a short conversation or code snippet).
Episodic memory: logs of past events or interactions (often stored as sequences or graphs of episodes) that can be recalled whole or consolidated into longer narratives.
Semantic memory: a database of generalized knowledge and facts (implemented as knowledge graphs, databases, or vector embeddings).
Procedural memory: stored skills and heuristics (often less explicitly mentioned in agentic systems, but akin to fine-tuned behaviors or policies).
As mentioned above, semantic memory is often implemented via knowledge graphs or embeddings, enabling efficient retrieval of factual or conceptual information. You can then use agent frameworks using tools to access vector databases for factual lookup, symbol-based memories for structure, and in-session buffers for immediate tasks. I have in the past explored several, and up until January 2026, my go-to framework was Smolagents, but since then, I have mostly been using Claude’s SDK.
Context management emphasizes relevance and retention.
Simply inflating the context window has never been a successful strategy. Large context sizes incur steep compute costs and do not guarantee the model “remembers” older content; the attention weights still dilute with length.
Instead, intelligent memory systems decide autonomously what to bring into context.
And that’s the game changer.
Naturally, memories should be selectively retrieved through similarity search or keyed queries rather than blind token dumps. This is naively true. But this is also why Retrieval-Augmented Generation (RAG), where the model queries a vector store or database at inference time, has been so prevalent in the past. It is also why the RLM framework, by design, layers the context: the agent only ever sees a snippet at a time, but can retrieve other snippets on demand programmatically.
In my preparation for this post, I found these projects that implemented the ideas of recursive inference and neurosymbolic memory:
Extended Context Language Tasks: Zhang’s RLM experiments themselves serve as case studies. They applied RLMs to tasks like needle-in-a-haystack retrieval, code repository understanding, and synthetic reasoning. In each case, the RLM significantly outperformed a baseline that used the raw prompt, especially as input length grew. For instance, on a synthetic pairwise reasoning task, vanilla GPT-5 failed catastrophically beyond 50K tokens, while the RLM maintained high accuracy even at millions of tokens. These results demonstrate that recursive prompting can effectively emulate an “infinite context” system with only nominal extra cost per query.
Robotic Planning (Teriyaki): In robotics, combining agents with symbolic planners is already happening. The “Teriyaki” framework is a generator of task plans that mixes GPT-3 with classical planning. They trained GPT-3 to output PDDL plans and then use those to guide execution. This neurosymbolic hybrid solved ~95% of test planning problems (versus about 98% for a pure PDDL planner) but produced more compact plans and was much faster to output each action. In human-robot tests, this meant the robot could adapt its plan on-the-fly as it executed actions, maintaining fluency in collaboration. Teriyaki demonstrates how symbolic context (PDDL states and effects) and LLM creativity (generating possible next steps) can together improve real-world planning under uncertainty. Would be keen to see how this would perform with 2026 SOTA models.
Hierarchical LLM Agents introduce complex task decomposition. Here, the LLM executes planning by alternating between LLM subroutines and symbolic checks. The agent first queries an LLM to outline a top-level plan, then uses a knowledge-graph RAG system to fetch relevant domain information, then refines subplans, validating each step with a symbolic “world model.” In experiments involving multi-step cooking or assembly tasks, this approach beat pure LLM baselines and pure planning baselines. This might indicate that neurosymbolic context (the knowledge graph + logic validator) can guide LLMs to more correct, context-aware solutions.
Cognitive Simulation (Urban Mobility): Peng applied these ideas to simulating human behavior. The team built agent-based models where each simulated person had an LLM-driven cognitive loop. Each agent used multi-horizon planning: it set weekly goals (based on profile) and daily plans (based on immediate events), integrated with episodic memory (past events) and semantic abstraction (general patterns). For example, an agent might abstract “takes route A to work” from repeated daily logs and then prefer that option even if details change. In large-scale mobility simulations, these agents could exhibit realistic adaptive behaviors under disruptions (like road closures). Their study finds that LLM-driven planning plus memory layers allows agents to “form routines, reflect on disruptions, and adapt strategies over time.” The semantic abstractions (e.g., user preferences, typical schedules) were key to coordinating short-term context with long-term personality traits.
In summary, in my opinion, these cases illustrate how recursive and neurosymbolic techniques are already shaping production solutions. In my opinion, they allow agent systems to work effectively on tasks that require sustained context: enterprise knowledge agents, robotics plans, long simulations, and beyond. The common thread is that each application divides labor between the neural and the symbolic: long-term patterns go into memory or logic, short-term specifics go into the transformer. This hybrid strategy is proving effective for on-premise, privacy-sensitive, and computation-limited environments where maximizing context and reasoning is critical.
I think the convergence of recursive inference strategies and neurosymbolic memory architectures represents a promising path for managing long-term context. Recursive Language Models show that we can dramatically extend an agent’s effective context by programmatically breaking tasks down and using the agent as a subroutine.
At the same time, neurosymbolic frameworks leverages that context is organized, interpretable, and persistently stored: knowledge graphs, logic modules, and hierarchical planners give structure to what might otherwise be an amorphous token stream.
In practice, this means moving away from monolithic prompt windows and toward multi-layer memory systems. I believe that simply increasing context size is a dead end, and instead champions modular memory layers and planning loops.
Thus, I propose a new design philosophy for AI agents: one that blends neural flexibility with symbolic memory. As initial experiments like Sentinel, RLMs, and Teriyaki demonstrate, such recursive neurosymbolic agents can tackle tasks that were previously impossible for fixed-window transformers.
Going forward, I expect more systems to adopt these ideas, using dynamic memory graphs, hierarchical abstraction, and programmatic context access to achieve true long-term reasoning and continuity.
Thank you for reading this far.
Kindly share this post, as it allows me to write more on this topic.
Zhang et al., “Recursive Language Models”, arXiv (2025) – Describes the RLM framework for unbounded input processing.
Honda & Hagiwara, “Context-dependent neuro-symbolic AI through self-supervised learning with LLMs”, Neurocomputing (2025) – Introduces a neuro-symbolic network that learns context-aware reasoning, reducing search space for proof tasks.
Cornelio et al., “Hierarchical Planning for Complex Tasks with KG-RAG and Symbolic Verification”, arXiv (2025) – Proposes an LLM-based planner enhanced by knowledge-graph retrieval and symbolic validators.
Capitanelli & Mastrogiovanni, “Teriyaki: Neurosymbolic Robot Action Planning”, Frontiers in Neurorobotics (2024) – Demonstrates a GPT-3 planner trained to output PDDL plans, combining neural generation with symbolic planning.
Peng et al., “Cognitive Agents in Urban Mobility”, Simul. Model. Pract. Theory (2023) – Shows LLM-driven agents using multi-horizon plans, episodic memory, and semantic abstraction to simulate adaptive commuter behavior.
Xu., “AI Agent Systems: Architectures, Applications, and Evaluation”, arXiv (2026) – Comprehensive survey of agent architectures, including a section on neuro-symbolic agents.
