As Large Language Models (LLMs) move toward million-token context windows, we are hitting a physical limit: the KV Cache. Storing the Keys and Values for every single token in a sequence causes VRAM usage to scale linearly.
In the standard Transformer architecture, each new token requires access to the keys and values of all preceding tokens. As a result, the KV cache grows linearly with sequence length:$[\mathcal{O}(N)]$. For long-context models, this quickly exceeds the VRAM capacity of a single GPU (e.g., an H100), necessitating either distributed sharding or aggressive pruning strategies.
Existing Heavy Hitter or Top-K eviction strategies rely on a simple premise: if a token isn’t being looked at now, it won’t be looked at later. However, information in natural language is inherently context-dependent and non-stationary. A token that is irrelevant in one segment may become the primary anchor in another.
In this post, I’ll walk through another paradigm: The SRC (Selection-Reconstruction-Compression) Pipeline. Instead of deleting tokens, we mathematically summarize them using Information Theory and Linear Algebra.
To understand why this assumption fails, we first need to examine the structure of attention itself.
Why Pruning Fails: Attention is Structured
The attention mechanism does not operate on tokens independently. Instead, it produces a dense interaction pattern between queries and keys, where each token participates in a global computation.
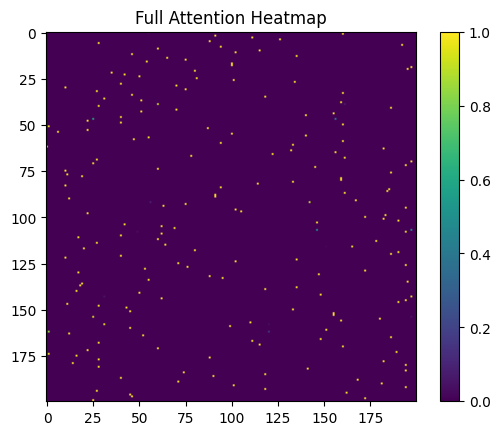
Each row corresponds to a query token, and each column corresponds to a key token.
The intensity reflects how strongly a query attends to a given key.
Several observations emerge:
- Attention is highly structured, not sparse
- Multiple tokens contribute jointly to outputs
- Dependencies are distributed across the sequence
Token-wise Error Under Pruning
While pruning appears effective on average, a finer-grained analysis reveals a critical failure mode.
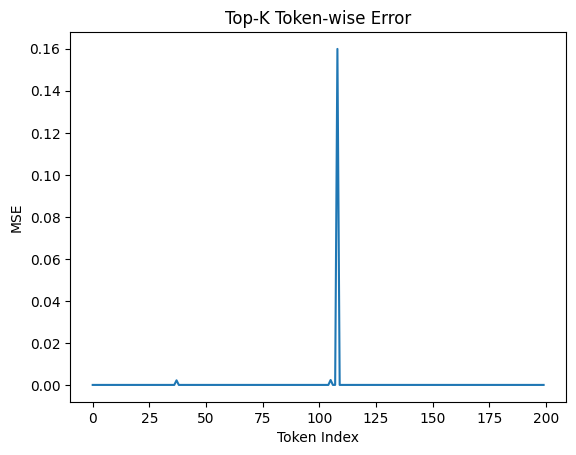
This plot shows the reconstruction error for each token after applying Top-K pruning.
Most tokens exhibit low error, suggesting that pruning works well locally. However, a few tokens show sharp spikes in error, indicating catastrophic failures.
These spikes correspond to tokens whose contribution is:
- not immediately dominant
- but structurally important for downstream attention
Notably, these failures are not predictable from local importance alone.
Pruning fails not uniformly, but selectively and unpredictably.
The SRC Paradigm: A Three-Stage Evolution
To address these limitations, we shift from a heuristic, decision-based paradigm to a structured transformation pipeline.
Instead of deciding which tokens to remove, we aim to approximate their contribution through a sequence of operations:
Selection → Reconstruction → Compression
Selection: The Entropy “Recycle Bin”
How do we decide which tokens to summarize? Instead of magnitude, we look at Information Uncertainty.
We calculate the Shannon Entropy H(P) of the attention weights for each head. If a token has high entropy, it means the model is “diffusing” its focus; the information is less specific and potentially more redundant.
$$H(P) = -\sum_{i} p_i \log(p_i)$$
Tokens with high entropy and low cumulative importance are moved to a “Recycle Bin.” Low-entropy “anchor” tokens are kept in the high-fidelity Active Cache.
Entropy Landscape of Tokens
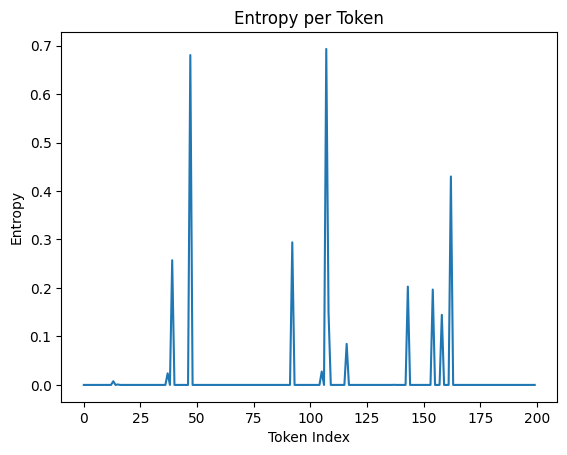
Each point represents the entropy of a token’s attention distribution.
We observe that:
- Some tokens exhibit low entropy (sharp, focused attention)
- Others exhibit high entropy (diffuse, uncertain attention)
Low-entropy tokens tend to act as anchors, concentrating attention and carrying specific semantic meaning.
High-entropy tokens, in contrast, distribute attention broadly and often encode less precise information.
Reconstruction: Solving for the Semantic Essence
Once tokens are in the Recycle Bin, we want to represent them as a single centroid token.
Simply averaging them is insufficient, as it ignores the specific queries that might interact with them.
We instead frame this as an Ordinary Least Squares (OLS) problem.
Our goal is to find a weight matrix $( W )$ that minimizes the reconstruction error of the attention output produced by the binned tokens.
Given a set of reference queries $( Q_{\text{ref}} )$ and the original binned values $( V_{\text{bin}} )$, we solve:
$$[ W^* = \arg\min_{W} \left| Q_{\text{ref}} W - \text{Attn}(Q_{\text{ref}}, K_{\text{bin}}, V_{\text{bin}}) \right|_2^2 ]$$
This formulation ensures that the reconstructed representation preserves the functional contribution of the discarded tokens.
In practice, we solve this analytically using the Moore-Penrose pseudoinverse:
$$[ W = Q_{\text{ref}}^{\dagger} \cdot \text{Attn}(Q_{\text{ref}}, K_{\text{bin}}, V_{\text{bin}}) ]$$
This allows the compressed representation to accurately approximate the original attention outputs while using significantly fewer tokens.
The core OLS logic from the implementation
def summarize_bin_ols(Q_ref, bin_v):
# Solve for weights that reconstruct the original V output
pinv_Q = torch.linalg.pinv(Q_ref)
W_reconstruction = pinv_Q @ bin_v
return W_reconstruction
Compression: Low-Rank Approximation (SVD)
The reconstruction weight matrix $( W )$ is still memory-intensive.
To achieve actual VRAM savings, we compress $( W )$ using Singular Value Decomposition (SVD).
By performing a rank $-( k )$ approximation, we retain only the most significant singular values and their corresponding vectors. This yields a compact representation that captures the dominant structure of the original matrix.
$$ [ W \approx U_k \Sigma_k V_k^T ]$$
This low-rank factorization allows us to interpret each retained component as a synthetic key-value pair, effectively producing a centroid token that acts as a proxy for the entire Recycle Bin.
Importantly, this process filters out low-energy components (noise) while preserving the principal directions (signal) that are most relevant for reconstructing attention outputs.
As a result, we achieve substantial compression without significantly degrading the functional behavior of the attention mechanism.
Evaluation Protocol: FAIR vs REAL
Before presenting results, it is important to distinguish between two evaluation settings.
A naive comparison between methods can be misleading, as different approaches utilize memory differently. In particular, summarization-based methods introduce additional tokens, making direct comparisons with pruning methods non-trivial.
To address this, we evaluate under two complementary regimes:
FAIR: Equal Effective Capacity
In the FAIR setting, we ensure that all methods operate under the same effective KV budget.
For HAE, summarization introduces additional tokens (e.g., centroid tokens). To account for this, we adjust the usable budget:
effective_budget = k_budget − (bin_size − k_rank)
REAL: Actual Memory Usage
In the REAL setting, we measure the true memory footprint of each method without any adjustments.
def kv_memory(K, V):
return (K.numel() + V.numel()) * 4 / (1024 * 1024)
Unlike the FAIR setting, we do not compensate for summarization overhead. This reflects real-world deployment conditions, where every stored token contributes to memory usage.
Results
Memory Evolution Over Time
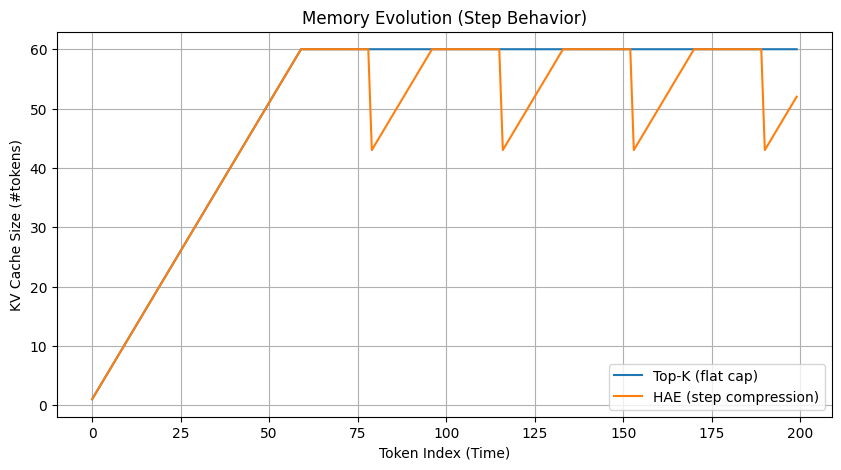
This plot shows the number of KV tokens retained as the sequence progresses.
Two distinct behaviors emerge:
- Top-K (blue) maintains a flat cap, enforcing a strict upper bound on memory
- HAE (orange) exhibits a step-like pattern, where memory grows and is periodically compressed
Interpretation
Top-K follows a static retention policy:
- Once the budget is reached, tokens are continuously evicted
- No information from evicted tokens is preserved
In contrast, HAE follows a dynamic compression policy:
- Tokens are temporarily accumulated
- When the recycle bin fills, they are summarized and compressed
- The cache size drops before growing again
Step Behavior
Each downward step in HAE corresponds to:
Recycle Bin Full → OLS Reconstruction → SVD Compression → Reinsertion
KV Compression Strategies (FAIR)
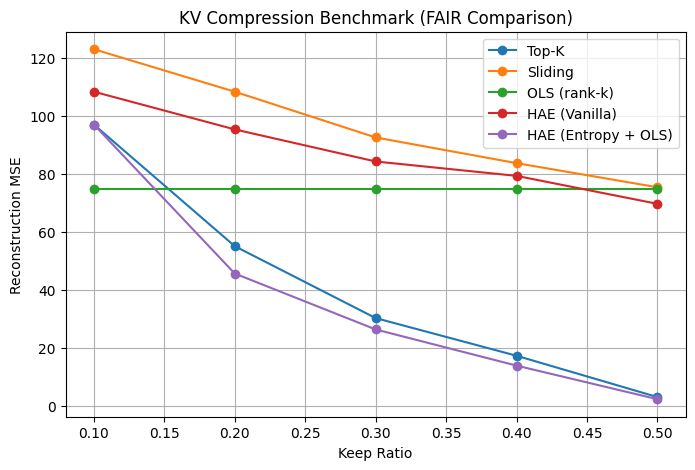
We extend our evaluation to compare multiple KV cache compression strategies under the FAIR setting.
Methods evaluated:
- Top-K: Retains tokens with highest attention importance
- Sliding Window: Keeps only the most recent tokens
- OLS (rank-k): Low-rank approximation without entropy-based selection
- HAE (Vanilla): Entropy-based selection without reconstruction
- HAE (Entropy + OLS): Full SRC pipeline (Selection + Reconstruction + Compression)
1. Full SRC Pipeline Performs Best
Across all memory budgets, HAE (Entropy + OLS) consistently achieves the lowest reconstruction error.
- Significant gains at low keep ratios (≤ 30%)
- Maintains strong performance even under aggressive compression
2. Selection Alone is Not Enough
Comparing:
- HAE (Vanilla) vs
- HAE (Entropy + OLS)
We observe that:
Entropy-based selection improves over naive methods, but reconstruction is critical.
Without OLS, performance degrades significantly, especially at lower budgets.
3. Compression Alone is Insufficient
The OLS (rank-k) baseline remains nearly flat across ratios:
- It does not adapt to token importance
- Lacks query-aware selection
This highlights that:
Compression without selection fails to capture meaningful structure.
4. Sliding Window Performs Poorly
Sliding window exhibits the highest reconstruction error:
- Ignores global dependencies
- Retains tokens purely based on recency
5. Top-K is Strong but Fragile
Top-K performs reasonably well at higher budgets, but:
- Degrades rapidly at low ratios
- Suffers from the selective failure modes observed earlier
FAIR vs REAL: Accuracy and Memory Tradeoff
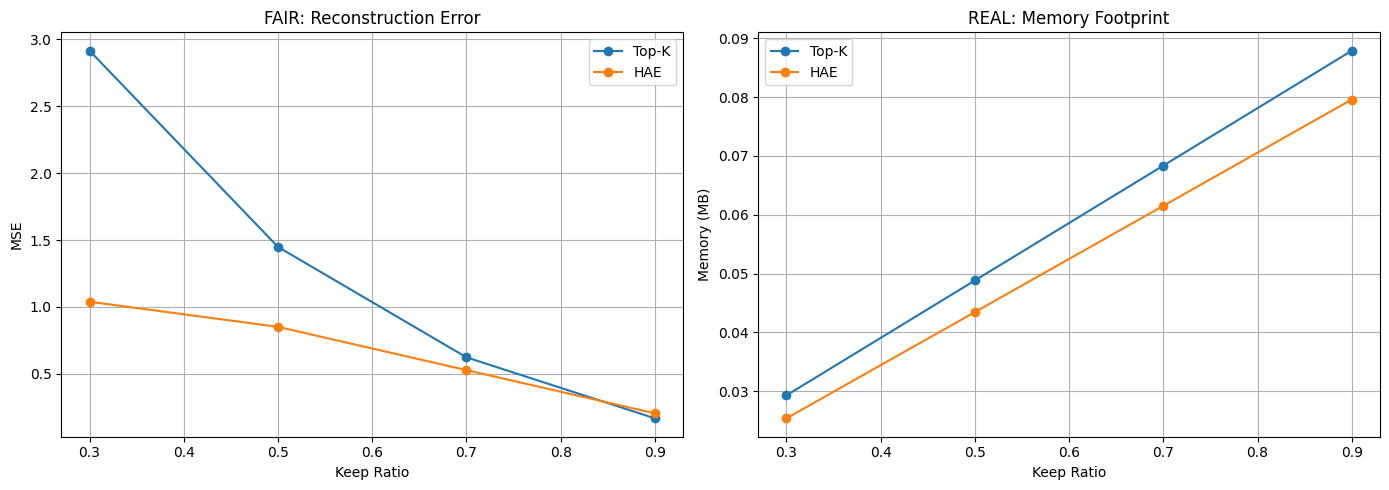
We now evaluate the SRC pipeline across both FAIR and REAL settings, capturing the tradeoff between reconstruction fidelity and memory usage.
FAIR: Reconstruction Error
The left plot shows reconstruction error (MSE) under equal effective capacity.
Across all keep ratios, HAE consistently outperforms Top-K:
- At 30% keep ratio, HAE achieves nearly 3× lower error
- At 50% and 70%, the gap remains significant
- At higher ratios, both methods converge as more tokens are retained
This demonstrates that:
HAE preserves the attention function more effectively under constrained budgets.
REAL: Memory Footprint
The right plot shows the actual memory consumption of each method.
Interestingly, HAE uses:
Less memory than Top-K across all ratios
This occurs because:
- HAE compresses multiple tokens into low-rank representations
- Redundant information is removed rather than explicitly stored
Combined Interpretation
Taken together, the results reveal a key distinction:
Top-K:
- Optimizes for token retention
- Suffers from high reconstruction error at low budgets
HAE:
- Optimizes for functional preservation
- Achieves both lower error and lower memory usage
Rethinking the Objective
These findings challenge a common assumption:
Fewer tokens do not necessarily imply better efficiency.
Instead:
- Memory should be evaluated in terms of information density, not token count
- Compression can outperform pruning in both accuracy and footprint
Conclusion
This research established that the linear scaling of the KV cache can be mitigated through mathematically-guided summarization. The synergy between Hierarchical Attention Entropy and Low-Rank Reconstruction allows the model to “compact” diffused information into a representative centroid rather than simply evicting it.
Our benchmarks on a synthetic Transformer show that this method maintains the semantic “shape” of attention patterns that pruning strategies typically degrade. The primary trade-off observed is the increased calculation time for OLS and SVD steps. Consequently, the next phase of this work involves implementing these operations within custom Triton kernels to amortize latency. By viewing the cache through the lens of reconstruction fidelity rather than just memory capacity, we can develop more sustainable architectures for long-context inference.
The full research notebook open for review
Citation
@misc{hae_kv_cache_2026,
title = {Entropy-Guided KV Cache Summarization via Low-Rank Attention Reconstruction},
author = {Chandra, Jayanth},
year = {2026},
publisher = {Zenodo},
doi = {10.5281/zenodo.19657329},
url = {https://doi.org/10.5281/zenodo.19657329}
}