This started as a short blog post but I’m on break and in a transition right now, so I figured there was no better time to write a sprawling manifesto 🤷. Skip to the end for an AI summary if it’s too long (it’s quite long!).
If there’s one mental model that underlies my worldview, drives my politics, and will steer decisions for any company I join, create, or invest in for least the next decade, it’s this: in our complex world, understanding is overrated, and we undervalue rapid, iterative feedback loops with reality.
It’s a thesis about meeting our complex systems where they are. It’s about tuning, nudging, dancing with those systems intricately and adaptively over time and with many precise knobs, rather than pounding them like a drum in one monotonous beat. It’s about starting with something minimal that functions, whether an organism, software platform, organization, or an economy, and growing it over many iterations into something more rich in complexity — rather than designing that complexity, top-down, from disparate parts. It’s a bet on agile practices and OODA loops. It’s a devout faith in the teachings of Mike Tyson: “everyone has a plan until they get punched in the mouth.”
Incredible, non-intuitive things happen when you feed the output of a system back to its inputs. Closed-loop feedback dramatically changes the dynamics: for example, positive feedback explodes into exponential growth, while negative feedback acts as the stable hand of homeostasis. Endless, nested, dynamic feedback loops are a canonical feature of complex systems, and are the reason for their adaptability and robustness.
Feedback is the most powerful force in the universe. Natural selection is feedback between an organism and its environment. Democracy is a feedback loop between governments and the will of the people. Markets are feedback loops between supply and demand.
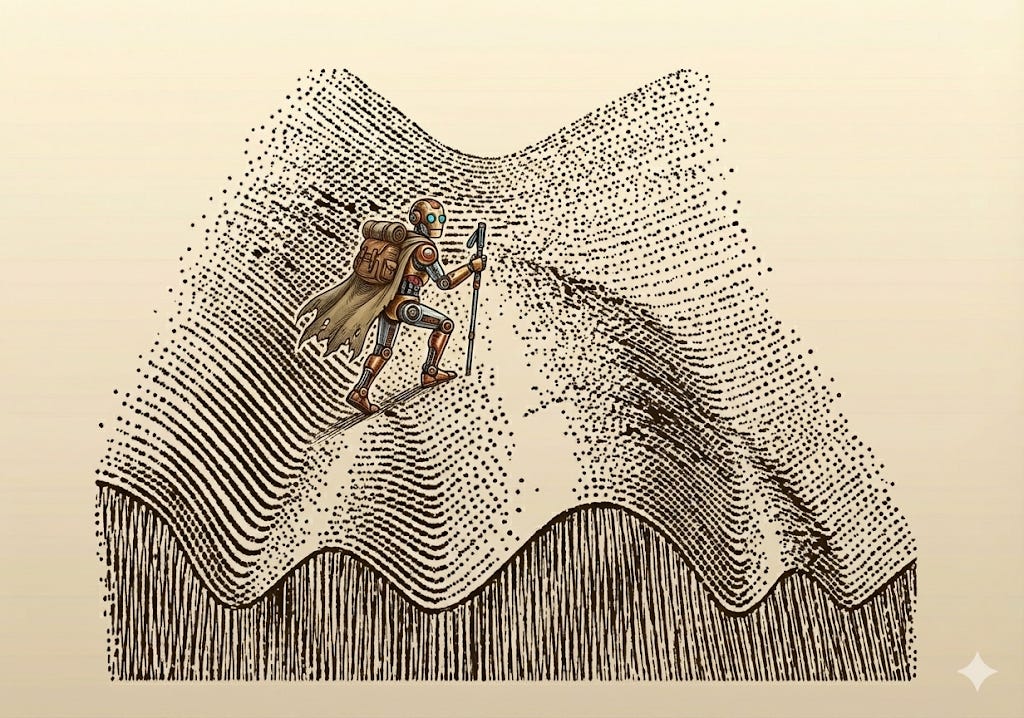
When coupled with memory, feedback acts as a ratchet. With feedback and memory, you can climb a mountain with your eyes closed. Even if you move in random directions, you can find the summit if you can return to your highest point before each next step1. Feedback and memory, when applied to complex systems, enable optimization, learning curves, and exponential behavior.
This mental model goes by many names.
The late philosopher Daniel Dennett coined the phrase “competence without comprehension” to describe how mindless processes—Darwinian evolution, Turing machines—can create complex behaviors (such as consciousness, Dennett’s specialty) without anyone understanding them.
In my view, competence and comprehension are a rebrand of “knowing how” and “knowing that”, which are the yin and yang of epistemology. Competence is intuitive, embodied knowledge; it relies on feedback with physical reality and is embedded within processes. Competence is mastery and optimization. Comprehension is verbal, conceptual knowledge; it floats abstractly and platonically above the world. Comprehension is language, explanation, and mechanistic understanding.
Despite the prevailing opposite narrative, theory lags practice. History is filled with examples where engineering and optimization (competence) ran ahead of science (comprehension). We built steam engines long before we formalized thermodynamics; we flew airplanes before we fully understood aerodynamics. Most of our medicines were found to have beneficial effects long before we knew why. Biology and medicine look more like engineering than science: we optimized first (vaccination, anesthesia, fermentation, antibiotics), and only later did we clarify the underlying theories. Science eventually catches up to generalize our capabilities, but often only after we’ve wedged our foot in the door through trial, error, and tinkering.
Evolution itself is the ultimate example of competence. Natural selection has no foresight, no understanding of chemistry, yet it produced ATP synthase, the ribosome, the immune system. Four billion years of this process has produced solutions we still cannot reverse-engineer. It doesn’t need to understand; it only needs to iterate. Nature does not design, she optimizes.
Frances Arnold won the Nobel Prize for directed evolution, which unleashes evolution’s supreme competence toward useful objectives in protein design. Her lab’s work shows you can optimize and even change the function of proteins by randomly mutating and iterating on measured performance, absent any comprehension.
Generate Biomedicines, where Arnold serves on the Board of Directors, recently made headlines with the first AI drug to reach Phase 3 trials. Their anti-TSLP antibody, GB‑0895, is an AI‑engineered therapy for severe asthma optimized for dosing every six months. The interesting thing about GB-0895 is that it was not ”designed” in one shot by an omniscient model. Instead, it was optimized by generating a bunch of high-likelihood sequences from a powerful base model, measuring the properties of those sequences in the lab across many assays, and then retraining the model and repeating over several rounds. This was the only feasible way to meet the many different objectives of a high-quality drug: ultra‑high affinity, long half‑life, and ease of manufacturing.
Generate supercharges directed evolution by swapping the random walk of mutation for an ultra-competent model in the feedback loop. No human understands the complex mapping between the final protein sequence and these desirable drug properties, and no AI would have predicted this mapping a priori, before rounds of feedback from the lab. Even with the final model in hand, this sequence-to-function relationship is distributed across a vast number of model weights and cannot be fully distilled into human-legible, verbal explanations. The first AI-generated drug to reach Phase 3 was optimized, not designed.
While humans are incredible at tinkering our way toward optimizing our world, we give ourselves far too much credit regarding how much we actually understand it. We seek interpretability. We are pattern-matching machines that find signal where there is only noise. We look for single points of intervention—labeled knobs we can turn to yield a predictable outcome. We anchor our attention near small islands of legibility and ignore the swirling sea of complexity around us.
Friedrich Hayek saw evolutionary processes in our socioeconomic systems. He spent his career arguing that economies emerged from evolutionary processes, not “constructivist” rational design, and that overconfidence in human comprehension of these systems results in disastrous policies. James C. Scott (most famously in Seeing Like a State) also exposed the fallacies of rationalist, top-down central planning of cities and economies. These ideas can be interpreted much more broadly: that the desire for human legibility in any complex system is futile and often disastrous. A legible system is one whose rich complexity has been fully wrung out by ham-fisted regulation, or intentionally omitted through rational design. But legibility is incompatible with functioning economies and living systems. Feedback (“skin in the game” as Nassim Taleb calls it) makes systems complex and illegible, but without it they are fragile and doomed to fail.
The desire for legibility and comprehension manifests as “mechanism” in biology and medicine.
To be clear, mechanistic reductionism has been a triumph and a firehose of discovery in basic biology over the past century. We truly do understand the structure, interactions, and function of molecular components in a vast number of specific subsystems in biology. Genetic knowledge, for example, has been directly applied for therapeutic benefit in some cases (e.g. in monogenic rare diseases, or when there’s strong genetic evidence). We should not stop striving for mechanism where it works.
But what we don’t understand about complex systems far exceeds what we do. Our simplistic mental models don’t survive when we discover that reality has a surprising amount of detail. In biology and medicine, especially, our hard-earned knowledge is extremely context-dependent. As soon as we step off of our islands of reducibility and consider more than a few components, or layer on an additional subsystem, or try to generalize across cell types or species, our ability to predict practically vanishes.
Drug developers know this well. It is an unfair strawman to pretend that scientists and drug hunters genuinely believe they can reason their way to designing a new drug. And yet it’s now hard to imagine drug discovery outside of the paradigm of individual, “well-understood” molecular targets. Partly as a result of reductionism’s successes but mostly due to our incentive structures and regulatory frameworks, we talk about drug development in terms of rational design, even in domains where that approach fails spectacularly.
Jack Scannell and colleagues tallied these failures in their famous 2012 paper coining “Eroom’s Law” (Moore’s Law spelled backwards): the number of new drugs approved per billion US dollars spent on R&D has halved roughly every 9 years since 1950, falling around 80-fold in inflation-adjusted terms. This happened even as our scientific inputs got exponentially better—DNA sequencing, genomics, high-throughput screening, computational chemistry.
It wasn’t always this way. Eroom’s Law was a steady downhill march from an astonishingly productive peak. As James Le Fanu documented in The Rise and Fall of Modern Medicine, the prolific post-war era of drug development was one of rapid feedback and iteration. Clinicians conducted research by hunch and observation rather than detailed mechanistic hypotheses, and our most successful medicines to this day are often poorly understood products of trial and error, of clinical evolution and optimization.
That feedback loop is broken.
Due to the difficulty and expense of clinical trials, drug development now happens in a vacuum, isolated from real-world feedback in patients. Without access to the actual system we want to modulate—human patients—trial and error is too cumbersome and so we lean on mechanistic narratives and invent preclinical proxies with poor predictive validity. Incentives become misaligned: biotech companies and investors exit and move on long before the drug is approved, no longer bearing the consequences of their decisions. Scientists learn the ultimate clinical readout of their research by reading the news headlines, years after they’ve switched jobs.
With rising competitive pressure on the US biotech industry from China, where fast and easy access to human trials has accelerated their drug development timelines, there has been a palpable movement toward regulatory reform. Ruxandra Teslo co-founded the Clinical Trial Abundance project as an attempt to rebuild the critical feedback loop of in-human data, and has been a vocal advocate of the importance of clinical results in a rapid feedback loop. In my opinion, establishing this feedback loop is the key to reinvigorating our stagnating industry.
What role does AI play? Are large language models smart enough to make feedback unnecessary? Frontier AI lab CEOs write about AI curing all disease, and compressing a century of progress into a decade. Might LLMs supercharge comprehension in science, the way that Generate’s lab-in-the-loop protein models supercharged competence? After all, what is illegible to humans may still be legible to the AI, right?
AI is obviously going to accelerate our progress, but I believe that current modeling paradigms are not sufficient.
It won’t be enough to train an LLM on all of the scientific literature and hope that we’ll have all the knowledge we need to cure disease. LLMs were designed for the conceptual space of language. They squeeze the dense firehose of reality into discrete tokens, perform calculations in the conceptual token space, then squeeze back into tokens for output. This process of comprehension has gotten us far, but it doesn’t capture adaptive, real-world competence.
Nor can we build an omniscient simulation of biology and medicine by churning static scientific datasets through a “virtual cell” or multimodal AI architecture2. Our datasets are vast but they are static snapshots, and typically only measuring a single subsystem of the sprawling complexity of the cell. These will be incredibly valuable as foundation models, but on their own they will not be sufficient for developing and testing drugs.
Like Hayek’s criticism of central planning in economics, this not to say that reason and comprehension are not valuable, but only that we need to acknowledge their limits, in both humans and AI. Instead of imposing rational logic on systems we don’t understand, we should build AI that learns from the system through continuous interaction, acquiring competence purely through feedback. Transformative AI will be designed to do—perturb, measure, adapt, iterate, control, and optimize—not just to know.
Those in the know within AI for biology and drug discovery see the importance of “lab-in-the-loop” feedback. Lila Sciences was founded on the premise that we need to “hand the keys to the lab,” through digital and physical automation, to allow models to propose and execute their own experiments in closed loop. Sam Rodriques, CEO of AI for science startup Edison Scientific, concedes that, while language models are great at modeling the way that humans think and communicate about science, experiments and clinical trials remain the bottleneck. OpenAI and Anthropic are both partnering with biology labs as well, signaling the value of experiment.
A parallel debate is taking place in Silicon Valley circles. Many AI luminaries have expressed doubt that LLMs in their current state will achieve significant economic impact. Podcaster Dwarkesh Patel summarizes this critique: they don’t learn “on the job” outside of their limited context window. He argues that this lack of closed-loop feedback will limit their economic impact, since adaptability is probably the most critical component of a job and not likely to exceed humans any time soon3.
The future of AI in biology is not simply to repurpose LLMs as an oracle to reason their way to better explanations. This is the “faster horse” version of our reductionist paradigm. Instead, I believe the next decade in biotech belongs to scientists and companies willing to let go of explanatory models altogether and reframe biology and medicine as a optimization problem. This may require completely different architecture, training, and application of AI methods, and it will absolutely require close contact with reality through rapid iteration and feedback.
The first wave of AI models in biology were predictors. They were trained by applying supervised learning to massive datasets. AlphaFold, for example, was a revolution in predicting protein structures given amino acid sequences. We have had models for classifying images of cells and DNA sequences for at least a decade.
The second wave has been generative: diffusion models, VAEs, language models, and other generative AI methods allow you to sample from a data distribution to generate plausible outputs, optionally conditioned on an input. LLMs and image generation models are of this category, as well as models for protein structure and biological sequence design (RFDiffusion, Chai, EVO, etc.).
Reasoning LLMs allow this generative inference process to unroll recursively over very long stretches for huge gains in accuracy. Reinforcement learning allows us to fine-tune these generative models to be incredibly accurate, especially in domains where the output can be verified to be correct, and those abilities generalize surprisingly well in other domains as well.
I believe that the next wave of AI models in biology might be adaptive controllers and optimizers: models that output perturbations directly in response to readouts, and continuously learn across iterations as the system drifts and as new data arrives.
Importantly, while it is desirable for the optimization algorithm to have an accurate simulation of your system, it is not strictly necessary. If a model is large enough, can run enough trials, and can learn from inputs and outputs, it can master the system purely through interaction—so-called “black-box” optimization.
In fact, counterintuitively, if you build a black-box algorithm that successfully controls something complex, then buried inside that system is necessarily a model of the thing it controls (the Good Regulator theorem). It might be an uninterpretable matrix of weights, but it predicts well enough to optimize the outputs. Therefore we may not have to choose between “real understanding” and “just optimizing.” Competence implies some level of comprehension—just not in a form designed for human consumption. As in LLM interpretability research, we can extract snippets of comprehension post hoc, but only after we have a performant, competent model.
Some architectures for AI-guided optimization already exist, but much more research attention is needed. In most current approaches, the AI/ML model itself is only one component of a larger system. Active learning and Bayesian optimization, for example, typically include a trained model alongside algorithms for sampling new proposals, scoring them using the model, and making principled decisions about which new proposals to test (an “acquisition function”). Some approaches update the model based on new data, others retrain the model on all previous data.
Reinforcement learning directly learns an optimal end-to-end policy from sensor outputs to actuator inputs. This policy is typically static, however, and model weights are not updated with new real-world data gathered after deployment. “Deep” RL using neural networks is data-hungry and typically requires faithful simulations of the system in order to generate enough data for training — one reason games and “verifiable rewards” scenarios are good for RL.
Large language models may eventually be suitable for optimization in a “continual learning” paradigm, but this field is nascent. Rumors suggest that continual learning in LLMs is an area of heavy research in AI labs (see Recursive Language Models for an early example). Watch this field, though, there may be breakthroughs in the next few years.
There is no single model architecture that I’m aware of that achieves all of the properties needed in biology and medicine: adapts continuously (or over arbitrary many discrete iterations), can work with black-box interfaces or simulations, can learn on any scientific data type, handles both small or large data volumes, handles noise and uncertainty, and pushes systems toward multiple desired objectives. Therefore, for now AI guided optimization is resistant to “scaling laws” and bespoke models will have to be customized for each application.
It’s actually remarkable that so many drugs are successful as single interventions in a system as complex as the human body. One explanation is that those were the low-hanging fruit, and we’ve largely exhausted them, but when you look at pairwise combinations the space opens back up. Most cancer trials combine two or more drugs. Trikafta is a combination of three distinct drugs that has transformed the lives of cystic fibrosis patients. Perhaps some of the stagnation in drug development can be alleviated by adding more “knobs” and exploring the combination space.
But what happens when you add a third knob? A fourth? A fifth? You quickly leave the realm of human intuition. No one can optimize doses across a six-dimensional concentration space by reasoning about mechanism. When human understanding is replaced by optimization, though, the situation is inverted. Algorithmically, high-dimensional control might be easier than low-dimensional control.
Consider deep learning, the underlying technology enabling AI. Neural networks are complex webs of artificial neurons, but a foundational insight was that you could optimize over the high-dimensional space of weights by walking down gradients toward your objective.
Complex, highly networked systems are extremely malleable. That same curse of dimensionality that made human understanding impossible is what makes optimization tractable: more (in fact, practically infinite) paths to the summit.
In biology, we can’t calculate gradients over every connection as we can with a deep learning model. But we do have flexible, high-dimensional systems where—given enough control knobs—you may have complete freedom to reach any achievable state through some combination of inputs.
This high dimensionality is why evolution was able to create “endless forms most beautiful.” Very similar sets of component genes, combined differently, produce a human, an orangutan, and a worm. Evolution searched through the vast possibility space using nearly identical components, arriving at radically different destinations depending on how those components are wired together. If blind iteration can find those solutions, AI-guided optimization should navigate the space far more efficiently.
One obvious caveat: this only beats human intuition if you can iterate fast enough and cheaply enough—which is why a great data engine, e.g. high-throughput assays, lab automation or continuous access to patients, is a required prerequisite. To optimize human health, for example, these models will need the Clinical Abundance movement to succeed at restoring feedback loops at the patient level.
The key ingredients to optimization are sensors (assays or measurement systems), actuators (”knobs”), an algorithm for proposing the next inputs to the actuators in response to feedback from the sensors, and a precise definition of one or more objectives.
If I had to compress this AI optimization thesis into a research + company-building playbook, it would look like this:
Build sensors for objectives, not just state.
The largest gains come from measuring what you actually care about—frequently, cheaply, and robustly— and in the real world system. If you can’t measure it, you can’t optimize it.
In biology and medicine we have an abundance of measurement technologies available to us. The optimization approach, however, prioritizes different classes of sensors than those targeted toward better understanding. High-resolution, longitudinal readouts are needed for each objective, rather than snapshots that are static in time. For example, in health care, wearables and apps are a valuable new source of sensors for objectives we care about. Measurements of internal state (e.g., omics, blood panels) can be useful to an algorithm, but only if they can be gathered repeatedly and concurrently with a readout of the objective.
Expand the action space (actuators).
Control theory requires not just good measurement, but actuation—we need knobs to turn. Optimization is impossible if your only interventions are blunt (e.g., single gene knockout or single drug dose). We need richer, safer perturbation toolkits.
In biology and medicine, our “knobs” (drugs, biomolecules, nutrients, electrical/mechanical stimulation, lifestyle) are often slow, dirty, or imprecise. The barrier to this future is as much hardware as it is software: we need higher-frequency, lower-latency actuators to truly close the loop. New “knobs” for biology can be found in emerging technologies such as optogenetics, transcranial magnetic stimulation, liquid handling, microfluidics, electronically controlled dosing, and AI-generated biomolecule sequences.
Automate as soon as you can, but no sooner.
Automation is often thought of as a labor-saving technology, but the greater impact comes from standardizing processes (improving the “memory” of the feedback loop) and improving resolution of actuators. A precise mixture of a dozen reagents is very difficult to pipette by hand, let alone a plate of 96 distinct ratios. Liquid handling becomes essential.
But be careful of automating before you have a working process, over-automating, or investing in brittle integrations that can’t quickly adapt to process changes. Treat automation as a software problem (a topic for another post).
Shrink loop times by orders of magnitude.
Optimization algorithms often show improvement after a few iterations, but they are most powerful after dozens of trials. Pay maniacal attention to reducing cycle times and increasing iterations.
Treat safety as a first-class constraint, not a posterior justification.
In many cases, safety and quality assays can be built in as part of the loop and optimized like any other variable. Optimization algorithms can enforce explicit boundaries that prevent unsafe input values. AI models of toxicity are around the corner, once mature they can be used as a filter within the optimization loop.
Do comprehension after competence.
The optimization mindset doesn’t throw out rationality, but simply relocates it to where it’s most effective. Aim your reasoning on the “outer loop”: what are the most relevant objectives, creative sources of sensors, and cleverly engineered actuators that will speed up the hill climbing?
If the optimizer works, it contains a model of the system and interpretability research might be able to extract human-comprehensible concepts. But don’t expect a complete understanding—recognize our limited ability to reason about the weights of a performant model.
What does an optimization-first biotech company look like?
An optimization-first biotech company doesn’t sell narratives and doesn’t rely on patents. Its success rests on the real-world performance of its products. It might sell a constantly improving bioproduct more complex and finely tuned than previously thought possible. It might deliver optimization services that deeply personalize a patient’s health. It engineers safety as a set of inherent constraints in the optimization algorithm, rather than through post-hoc screening. It manages costs by plugging in COGS as an objective to be minimized.
The optimization mindset—turning many knobs at once, maximizing multiple objectives, running hill-climbing experiments in rapid iteration—is radically different from the current AI paradigm of de novo generation as well as the traditional biopharma approach of changing one variable at a time and hoping for statistical significance4.
Of course, implementing this new paradigm is harder than just building the right AI architecture. It will require feedback loops—data engines, rather than static datasets. These should begin as small, fully-functional, end-to-end loops of sense and response, composed of digital and physical processes that grow in complexity over time.
There are intellectual property advantages to an optimization-first biotech. It shifts the focus from patents—which can be fragile to litigation, evaded by AI-designed fast followers, or sidestepped by China— to processes, which are more safely protected as trade secret and insider knowledge. Processes include the real-world data engine as well as the AI development infrastructure. Patents have a short shelf life relative to development timelines and don’t reward continued investment; processes are an engine that can continuously improve and extend the competitive advantage over rivals.
There are already several examples of optimization-first companies, and more emerging. Generate Biomedicines was a pioneer in optimizing protein sequences for multiple properties. Lila Sciences, as mentioned above, is building automated laboratories where AI agents design experiments, robotic systems execute them, and the results feed back into improved models. As described in MIT Technology Review, Lila’s models use real-time data to vary ingredients and synthesis conditions, iterating toward optimized materials without human intervention in the loop. Polyphron applies closed-loop AI methods to control tissue development. They are leveraging the scalability and universality of algorithmic control toward building an autonomous foundry to engineer implantable human tissues.
I expect to see more startups in this space in the future. I may even build one.
The next decade in biotech will be won by those willing to close the loop. Not by abandoning mechanism—explanation still matters where it works—but by recognizing that in complex systems, competence must come first. For half a century we’ve tried to reason our way to better drugs while slowly dismantling the feedback loops that made the post-war golden age of medicine possible. AI will not rescue us by thinking harder inside static datasets. It will matter because it lets us iterate faster in contact with reality—perturbing systems, measuring what actually matters, updating beliefs, and repeating until performance improves.
The winners will treat AI not as an oracle that generates hypotheses, but as an optimizer that co-evolves with the systems it’s trying to control. They will measure objectives rather than proxies, turn many knobs at once rather than one at a time, shrink loop times by orders of magnitude, and encode safety as a constraint instead of an after-the-fact justification. Understanding will still arrive—but it will be extracted from working systems, not imposed on broken ones. This is not a rejection of science. It is a return to its oldest and most powerful idea: that the world is smarter than our theories about it, and that the fastest path to mastery runs through feedback, not explanation.
Nature does not design. She optimizes. It’s time we did the same.
As I explore new beginnings, I’m very excited about the many ideas emerging in this space. If these ideas resonate with you and you want to chat, please reach out!