Real-time voice AI builders face an impossible challenge. Real-time UX requires sub-500 ms response latency, which limits builders to fast, non-thinking models significantly dumber than the state of the art. However, complex business logic like plan-following and UI control requires frontier-level thinking models. Barring a breakthrough in pre-training, we’re not going to have a model that’s simultaneously fast and smart enough. Builders must use system design to boost the model’s intelligence. One of the most effective design patterns is the finite state machine (FSM). By splitting one monolithic task into multiple subtasks, the FSM expands the AI’s capability far beyond what’s achievable by a standalone model.
What makes the business logic in voice AI complex? A 3-stage real-time voice AI workflow includes speech recognition, output synthesis, and speech generation. The output synthesis stage is where the complex business logic resides.
In this stage, an LLM takes in pre-defined contexts plus transcribed speech from the user, and synthesizes a response. To do so, it must juggle multiple context components, making the synthesis task complex. Because real-time voice AI apps are commonly built to replace humans in specific tasks, they require the following context components:
character prompt: what role is the AI playing, its name, background story, personality, etc.
task background: the circumstances of the conversation
user info: the user’s name, preferences, memories from previous conversations, etc.
task plan: step-by-step plan for this task
For example, a (simplified) context for a job interviewer AI agent looks like this:
character prompt: you are a seasoned web development engineer manager; your name is Jason; you’ve been at your current company for two and a half years
task background: you are interviewing a candidate for the junior software engineer opening on your team; the candidate needs to have strong understanding of HTML, JavaScript, and CSS; the candidate must have experience with React JS
user info: the interviewee is Sam; he graduated from UCLA last year; he interned at Google and Netflix; resume screening showed him as a very strong candidate
task plan: step 1: brief intro, ask about Sam’s background and recent projects he has worked on; step 2: probe his technical prowess by asking about JavaScript fundamentals, async operations, etc. ; step 3: give him a coding problem to test his ability to solve real world problems.
The most obvious and naive approach is to jam all four components into one blob - concatenating the multiple text bodies into one. Most builders choose this approach because it’s simple. However, it only works occasionally. This inconsistency makes it unsuitable for production.
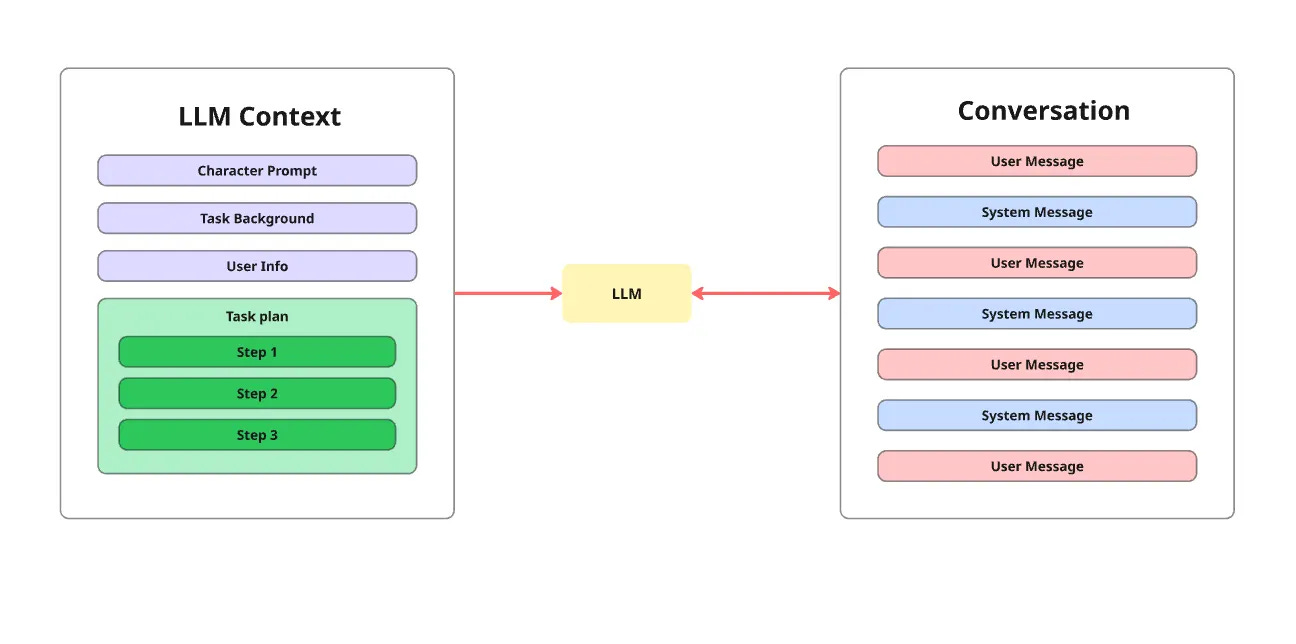
The problem lies in how the LLM processes the monolithic context. In each turn, the attention mechanism generates each token sequentially. It does so by assigning an importance score to each token in the context window, which dictates how much each token affects the output. To execute the task plan correctly, the LLM needs to assign high importance to the current step of the plan and low importance to the rest. This requires the LLM to implicitly deduce the current step.
However, the available low-latency models can’t figure out the current step consistently. And these failures have severe consequences. When the AI gets the current step wrong, the conversation goes off course and renders the product unusable.
Since figuring out the current step is so vital, how can we get more accurate and consistent results? The solution is the finite state machine (FSM) - an oracle that conveys exactly what the current step is. It not only helps the conversation LLM keep track of the steps, but also enables improvements in UI coordination and observability.
Instead of having to look up the current step from the full plan, the conversation LLM gets the current step’s content directly from the FSM. It no longer has access to non-current steps in the task plan, making it impossible to generate output using the wrong steps.
How does the FSM know what the correct step is? Instead of comparing the full conversation with the task plan, it tracks the state of the conversation using the step index. At each conversation turn, the FSM only needs to decide if the current step is finished. It then updates or keeps the conversation state accordingly.
To allow the FSM to judge if a step has been completed, each step in the task plan not only includes instructions for executing this step, but also has another component called success criteria. The instructions and success criteria are co-generated during task plan creation. At the end of each conversation turn, the FSM calls an LLM to judge if the current step is finished based on the success criteria and the conversation content.
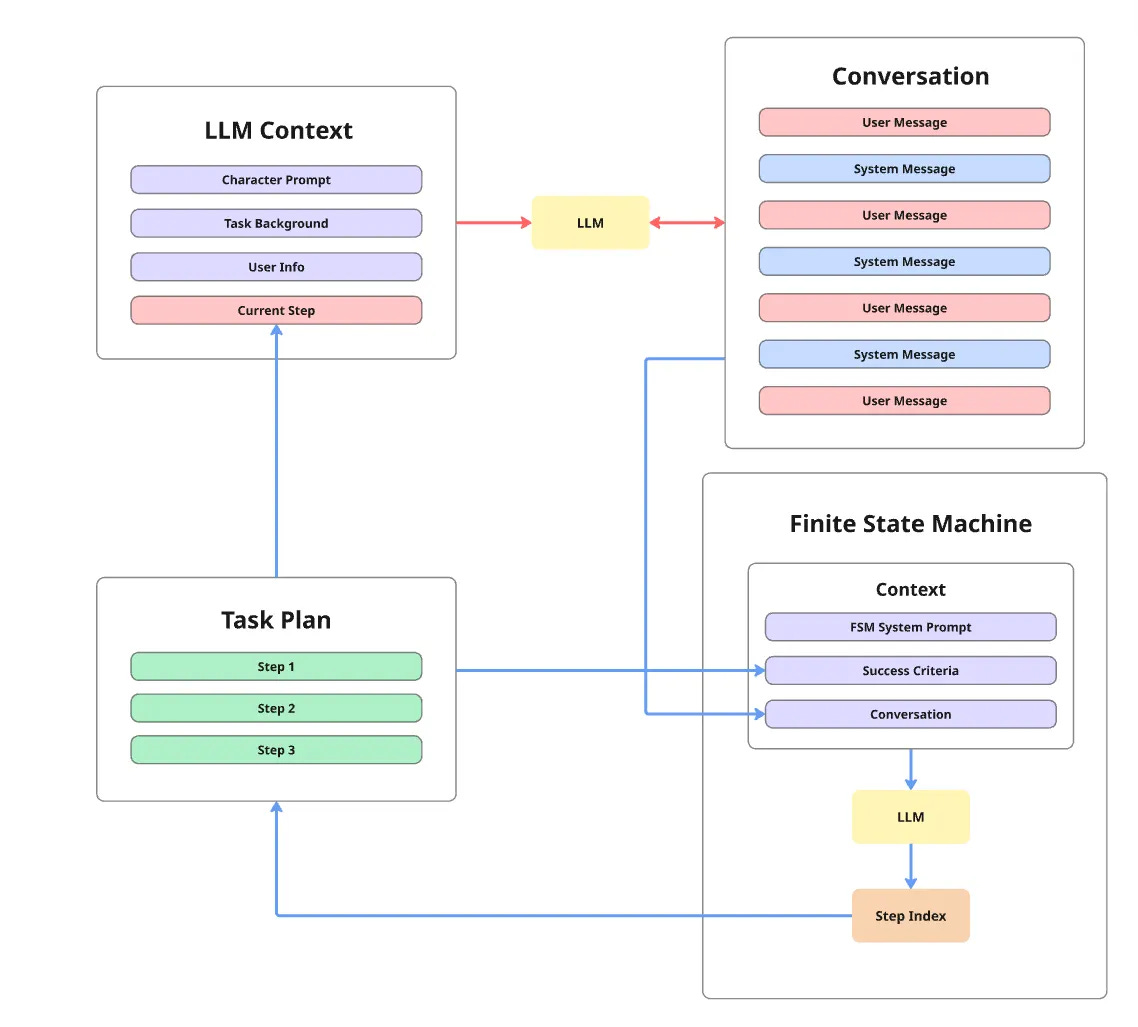
What used to be one monolithic task has been split into two parallel subtasks. The FSM focuses on deciding state transitions. The conversation LLM focuses on synthesizing the output. Because there are multiple LLMs focusing on separate concerns, each LLM’s cognitive load is significantly lower than the monolithic approach.
There are also many side-benefits from having an explicit state for the LLM session. First, the state can be used for UI coordination. With FSM, each step can contain specifications for display elements as metadata. The user’s device then fetches the display elements when the session enters a new state, always ensuring the UI is synced with the conversation.
Having explicit states also leads to better observability. When the conversation LLM gives a problematic output, it’s crucial to know what part of the prompt caused that. Without the FSM, identifying the cause is mere guesswork. With the FSM, we can know that with absolute certainty. Then, we can make precise changes and iterate efficiently.
Given these benefits, where can we use the FSM? It’s applicable to any voice AI use case that requires the AI to follow a step-by-step plan. It’s not useful for pure agentic workloads where an orchestrator decides the actions dynamically and there’s no pre-determined plan. Many voice AI use cases with substantial real-life value fall into the first category: An AI tutor can use an FSM to manage its lesson plan. An AI interviewer can use an FSM to manage the interview plan. AI practice partners - for lawyers to practice depositions, for doctors to practice diagnosis, etc. - can use FSMs to simulate realistic practice subjects.
The FSM does have skeptics, though. A common argument against it is “As models get smarter, real-time voice AI apps can achieve the same performance using a monolith architecture, without FSM. So building a complex FSM will be a waste of time”. This is inaccurate for two reasons. First, the FSM has benefits beyond just allowing the app to use less capable models. It also enables faster iteration during development and other product features such as UI coordination. Second, newer, smarter models can tackle tasks that previously required the FSM using just a monolith architecture. But the goalpost moves - using the smarter models with the FSM allows us to solve even harder tasks that were previously unattainable.
So an FSM is not a patchwork to compensate for current models’ lack of intelligence. It’s a sound architecture that will consistently help build better real-time voice AI products. It passes the most important test in the age of AI: Instead of being replaced by new versions of frontier models, FSM systems get better as models get more capable.