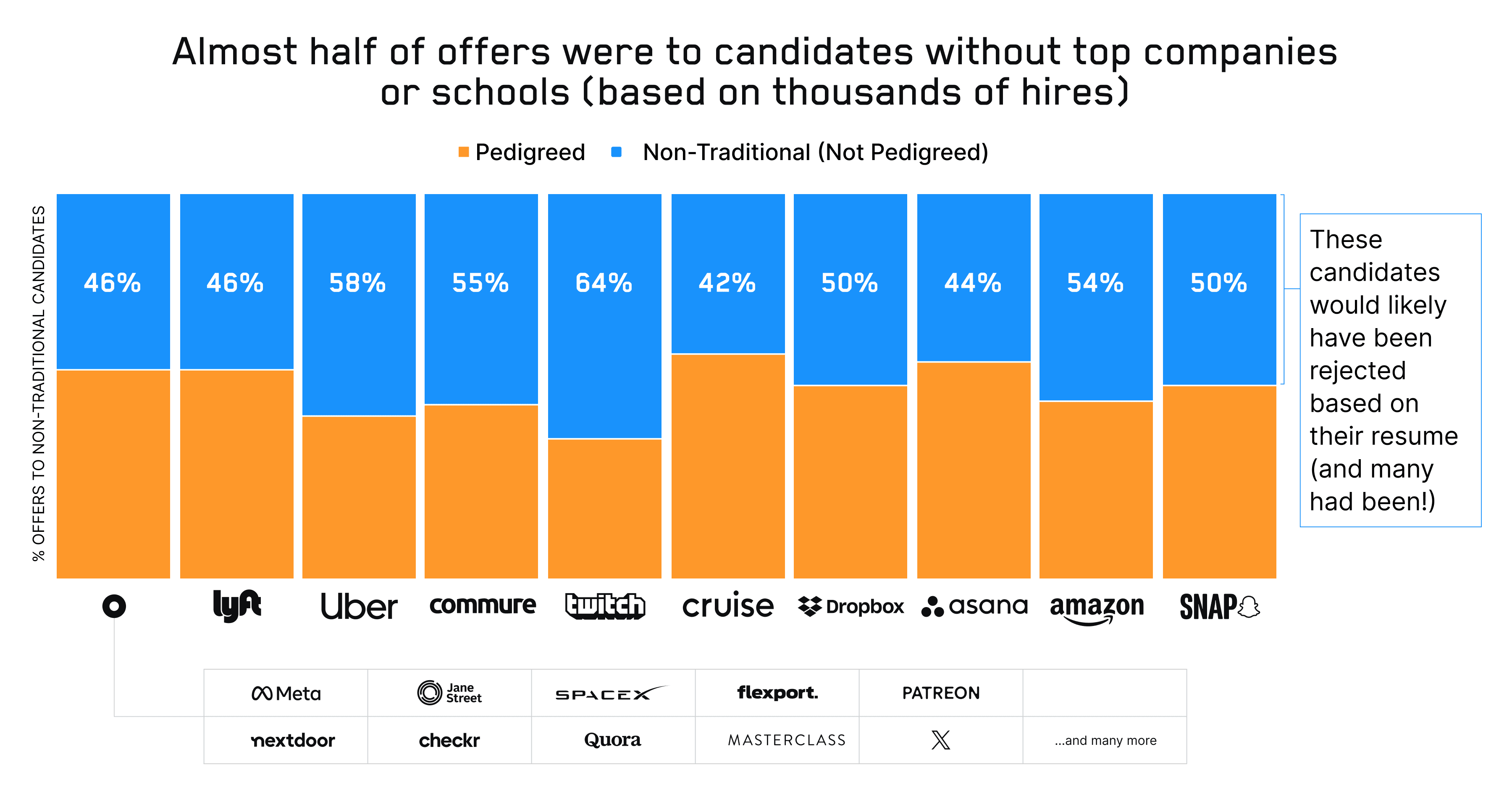
In the last post in our hiring series, I talked about how, for six years, we ran the largest blind eng hiring experiment in history and placed thousands of people at top-tier companies. Our customers included Amazon, Dropbox, Lyft, Uber, Snap, Quora, SpaceX, and many more. 46% of candidates who got offers at these companies didn't have top schools or top companies on their resumes. Despite that, these candidates performed as well (or better than) their pedigreed counterparts, were 2X more likely to accept offers, and stayed at their companies 15% longer.
Of course, it's easy to say that you should hire non-traditional candidates. But how do you separate great ones from mediocre ones, when you can't look at brand names on their resumes for signal?
The short answer is that it's really hard. We spent years figuring it out. But, we now have a predictive model that outperforms both human recruiters and LLMs and can reliably identify strong candidates, regardless of how they look on paper, just from a LinkedIn profile. Not only can it spot diamonds in the rough, but it can also identify candidates who look good but aren't actually good.
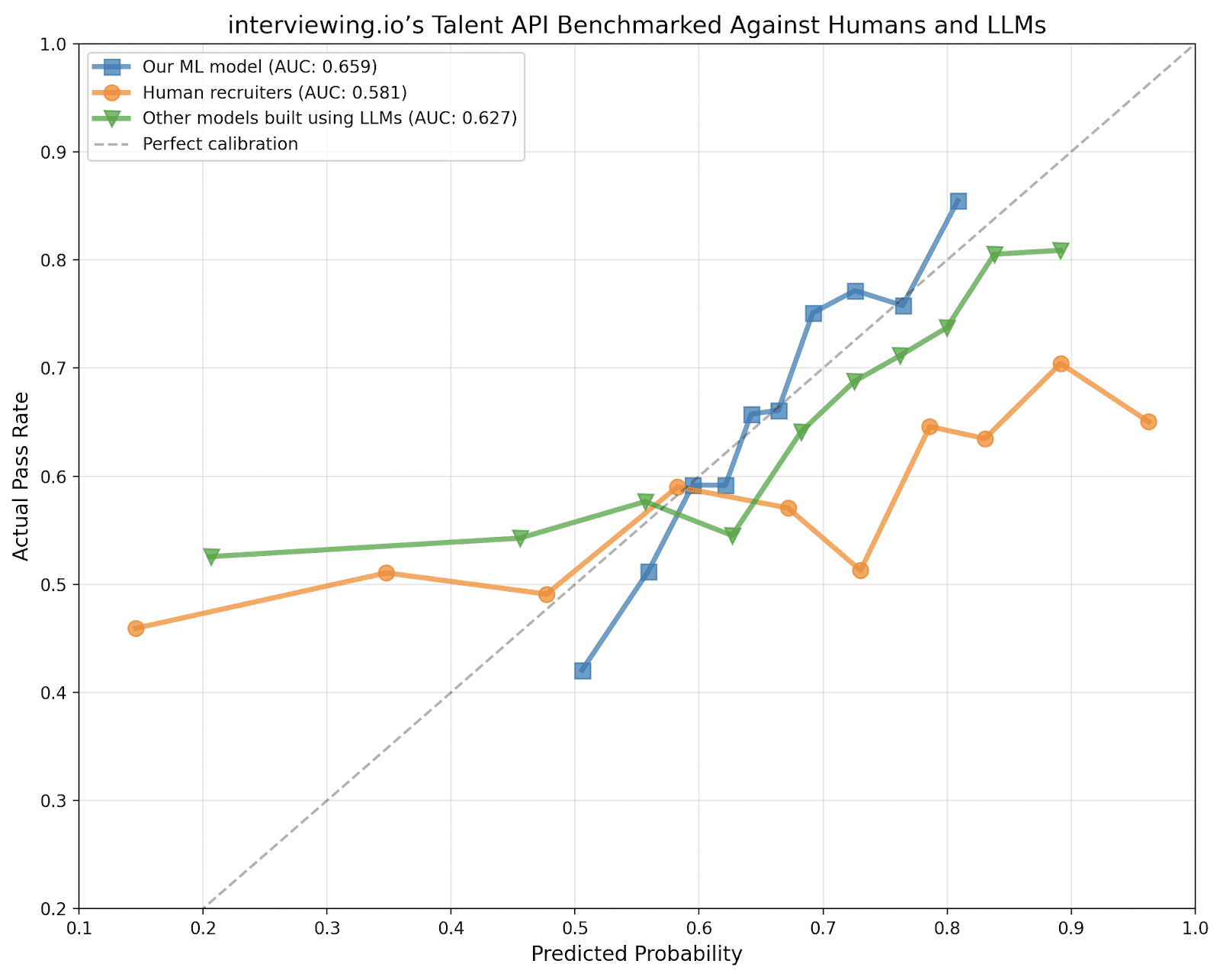
With pilot customers, our model has achieved a first contact to hire conversion rate of 12% (that's ~5X what you'd see in a good hiring process).
In this post, I’ll talk a bit more about our model and some use cases for it on your own pipeline.
Why does your model outperform both humans and LLMs?
My best guess for why our model performs this well comes down to four things:
- Having outcomes data
- Having redundant outcomes data
- Having outcomes data specifically for candidates that wouldn’t normally get the chance to interview (i.e., candidates who don't look good on paper)
- Anonymity
What are outcomes, and why are they important?
Outcomes in the context of hiring are post-hire signals like performance reviews and promotion history. Those are scattered across a bunch of walled garden HR systems and are notoriously hard to get as a result.
Short of on-the-job performance, interview outcomes (which are easier to get) are the next best thing. Whether it’s on-the-job data or interview performance data, the key distinction is that outcomes capture impact and quality, not just optics or activity.
Where an engineer previously worked or went to school are optics. They may correlate with outcomes, but they are the inputs, not the outputs. Similarly, metrics like number of commits, pull requests, or lines of code written are inputs: they reflect effort, not effectiveness.
This distinction matters because even if you had every resume or LinkedIn profile in the world and complete visibility into all engineering activity — say, every private commit on GitHub — you’d still need a way to translate that raw input into outcomes to make it meaningful.1
So what can we do? The most direct path is to start with the data that already exists and already influences hiring decisions: interview performance data. It’s straightforward, it’s easier to get, it doesn’t take as long to create as on-the-job performance data, it bakes outcomes in from the start, and, crucially, it’s the same data companies already use to make hiring decisions!
Fortunately, at interviewing.io, we have a decade of proprietary interview outcome data and ~200k technical interviews (both mock interviews and real ones). Our average user does 3.4 interviews in a single job search, and we have data spanning multiple job searches (sometimes as many as three) for the same person.
We used this data (anonymized, of course) to train our model.
The importance of redundancy
One of the most surprising things I’ve learned from looking at our data is how much variance there is in interview performance. As it turns out, only about 25% of engineers perform consistently from interview to interview. Everyone else is all over the place (and the inconsistency doesn’t go away even when you correct for interviewer strictness).

As a result, having multiple outcomes for the same person, especially across years and multiple job searches is much more useful than having just one interview (or even just one job search).
Selection bias, and the importance of counterfactual data (outcomes for candidates that normally wouldn’t get to interview)
This distinction is probably the most important.
Let’s say you had all the ATS data in the world. That’s great, right, because now you have real interview outcomes, and you even have some redundancy. But you’re still missing a huge swatch of the population: people who got filtered out at the beginning of the process, before they ever got to interview.
Think about it. Who gets to interview? Overwhelmingly, it’s candidates with top companies and top schools on their resume. If that’s all your model ever sees, then of course it’s going to be biased toward those candidates.
But, brands aren’t everything. When we ran our six year blind hiring experiment, we saw that 46% of candidates who got offers at top companies didn't have top schools or top companies on their resumes.2
But despite brands not being the be-all and end-all for hiring, because of the limitations in their training data, other models are heavily biased toward pedigreed candidates.
On the other hand, because we’re a practice platform, and anyone can join, we are the only ones who have performance data for the types of candidates companies wouldn’t normally talk to (but many of whom are still excellent). It’s a much broader, much more representative swath of the eng community.
Why is anonymity important?
Most hiring models—whether built by humans or AI—train on data that's riddled with demographic signals. Names, schools, club memberships, even word choices can encode race, gender, and socioeconomic background. Models learn to associate these signals with success, not because they're actually predictive, but because they're correlated with who got hired in the past.
The history of AI in hiring is littered with cautionary tales about what happens when you don't anonymize your data. The most infamous example is Amazon's infamous AI recruiting tool, which the company developed starting in 2014. The system was trained on resumes submitted to Amazon over a ten-year period (a period during which the company, like most of tech, had hired predominantly men). The result was predictable: the algorithm learned to systematically downgrade women's applications. It penalized resumes containing the word "women's" (as in "women's chess club captain") and devalued candidates who had attended all-women's colleges. Amazon's engineers tried to patch the bias out, but they couldn't be confident they'd caught all of it, and the project was abandoned.
Amazon's failure isn't an isolated incident. A 2024 University of Washington study tested three state-of-the-art LLMs on resume screening. "The researchers varied names associated with white and Black men and women across over 550 real-world resumes and found the LLMs favored white-associated names 85% of the time, female-associated names only 11% of the time, and never favored Black male-associated names over white male-associated names."
Our model sidesteps unfortunate issues like this entirely. Both the inputs (LinkedIn profiles) and the outcomes (interview performance data) are anonymized. By baking anonymity into our training data, we reduce the odds that our model can be biased, inasmuch as one can. We've built fairness in from the ground up rather than trying to bolt it on after the fact.
How we built this model (and what we didn’t do)
Unlike other tools and models out there, our model is trained on just two things:
- Anonymized interview outcome data
- Anonymized LinkedIn profiles of the engineers for whom we have interview outcomes (We decided on LinkedIns rather than resumes because LinkedIns are both standardized and ubiquitous – like opinions and assholes, everyone’s got one.)
It is NOT trained on recruiter preferences or opinions. Just anonymized LinkedIn profiles and interview outcomes. As you saw above, having both inputs and outcomes be anonymized reduces the odds significantly that a model can be biased. In other words, we’ve baked fairness in, inasmuch as one can.
How does the model actually work? It just needs a LinkedIn profile as input. From that profile, it can reliably predict if an engineer will pass technical interviews at top-tier companies. That’s it!
Because the model has both profiles and interview outcomes, it can try to figure out what successful versus unsuccessful profiles look like. We don’t just look at the usual signals: companies, schools, etc. We analyze the text in the profile and compare how people talk about their positions to how the most successful candidates talk about their work. Sometimes the best people have sparse profiles, and that’s OK. We also look at career trajectories, title changes, growth, and distance traveled (where someone ended up in the context of where they started).
Simply put, our model does everything the world’s best recruiters would do, if they had infinite time to read, didn’t have to make snap decisions, and were unburdened by hiring specs, hiring manager pressure to just look at FAANG candidates, or other preferences and biases.
We don’t have a fully built-out product yet, but from what we’ve seen so far, our model is the best thing out there to surface good engineers (rather than engineers that look good).
We know who’s looking because they’re practicing on interviewing.io. The honest truth is that interview practice just isn’t that riveting, and it kinda sucks. We’ve seen time and time again that when people are practicing, it means they’re either already looking or about to start.
How you can use our model
You can use our model in two ways:
- Supplement your top of funnel: Get intros to our most promising users who are interested in your company. The majority of our users are based in the US, and our average user has 8 years of experience. We can filter on whatever deal-breaker criteria is important to you (work authorization, location, etc.),
- Filter your inbound: Use our model to surface the people who are most likely to do well in interviews
So far, our model has a 12% first conversation-to-hire rate. That’s 5X what most top-tier companies are seeing through their own efforts.
Try it out. You can use us as a source of excellent candidates and/or you can use our predictive model to help you surface the best people from your inbound applications. Just fill in this form for early access, and we’ll be in touch.
Footnotes:
-
The same goes for the enormous volumes of AI-assisted coding data that companies like OpenAI and Anthropic are now collecting: without tying those inputs to downstream results, they remain noise. There are a few possible ways to bridge that gap. One is to acquire Applicant Tracking Systems (ATS) to access interview outcome data (though we’ll talk about why the usefulness of ATS data is limited, in a moment). Another is to build robust evaluation layers that score code and commit activity and correlate it with performance signals. Or you could try to aggregate performance review and promotion data across many fragmented HR platforms, though in the long tail of smaller companies, that data barely exists at all. ↩
-
Many years ago, I spent a year personally interviewing engineers at a company called TrialPay. I got a lot of latitude in whom to interview and ended up letting in a lot of candidates who probably wouldn’t have gotten in otherwise. After a year and about 300 data points, the most surprising thing I learned was that typos and grammatical errors on a resume matter more than where someone previously worked, and having attended a top computer science school didn’t matter at all. ↩