One week ago I noticed that the number of unique users was dropping for Jar.Tools.
Initially I thought that it may be Google playing with the keyword ranking again, which may have been the cause of it. I put this problem aside until I saw this:
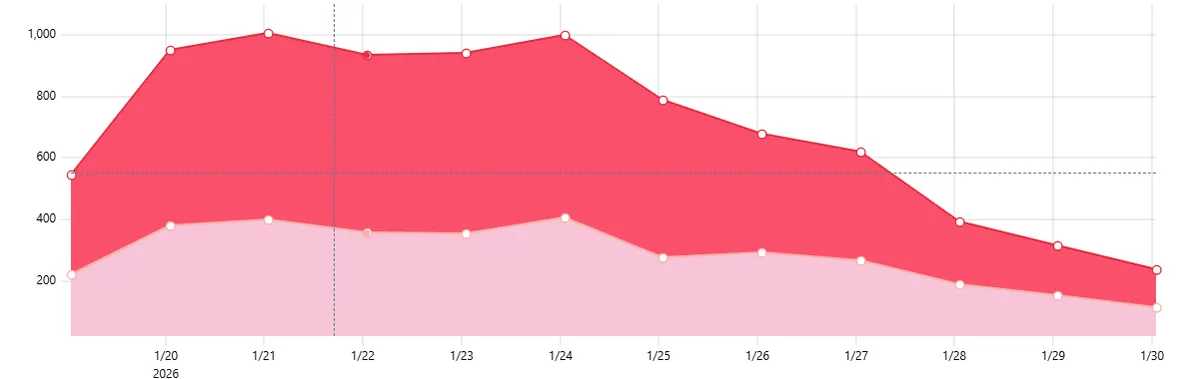 The number of active users per day dropped to a historical minimum and I didn't know what the cause could be, because it was opening correctly on my mobile.
The number of active users per day dropped to a historical minimum and I didn't know what the cause could be, because it was opening correctly on my mobile.
Google ranking vs App problem
It was very easy to rule out Google’s involvement here, it just required looking at the Google Search Console:
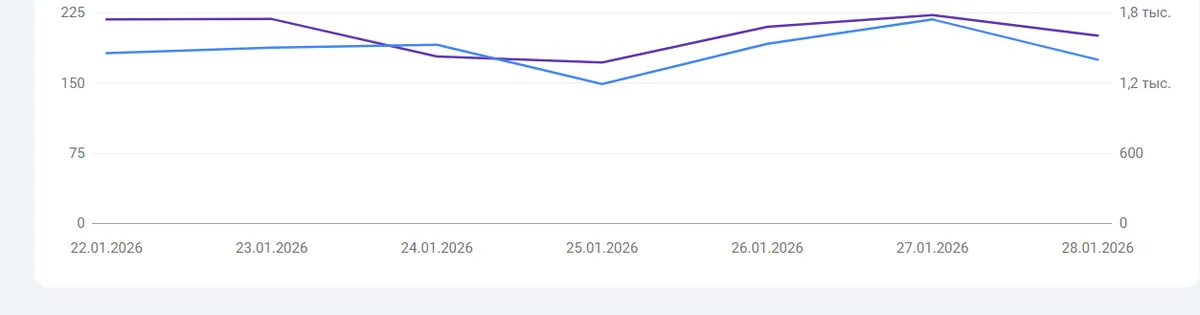 No drops in the Google Search results, which means that users simply were not able to enter the website.
No drops in the Google Search results, which means that users simply were not able to enter the website.
It's been a week without any action from my side, so I had to find the root cause of this issue.
Step 1: Assume It's Your App (and try to disprove it)
My app is a Node/Express service deployed on fly.io host. First suspicion: cold starts or event loop blocking. So I measured actual timings:
curl -o /dev/null -s -w \ "DNS:%{time_namelookup} TCP:%{time_connect} TLS:%{time_appconnect} TTFB:%{time_starttransfer} TOTAL:%{time_total}\n" \ https://example.com
Results were consistently sub-second:
DNS:0.015 TCP:0.20 TLS:0.41 TTFB:0.88 TOTAL:0.88
The health endpoint was trivial:
curl -i https://example.com/health
Always 200, always fast. CPU and memory looked fine. No spikes, no restarts.
Step 2: Check DNS
When failures are user-dependent, region-dependent, and inconsistent, DNS should move to the top of your list. First, I checked basic resolution:
dig +short example.com A dig +short example.com AAAA
Looked fine. Correct IPs. But here's the key lesson:
One resolver telling you the right answer doesn't mean all resolvers do.
So I checked public resolvers:
dig +short example.com A @1.1.1.1 dig +short example.com A @8.8.8.8 dig +short example.com A @9.9.9.9
Most returned the expected hosting IP. But earlier global probes had shown a completely different IP of Namecheap. That should not happen.
Next step:
dig +short NS example.com
This showed the domain was using registrar default nameservers. So I queried them directly:
dig example.com A @ns1.registrar-servers.com dig example.com A @ns2.registrar-servers.com
Now things made sense. Depending on timing and resolver behavior, the domain could resolve differently. Why? Because of a hidden trap I planted few month ago.
The Real Culprit: Registrar URL Redirect
In the registrar's DNS panel, there was:
- A CNAME for the apex pointing to my host (correct)
- And a "URL Redirect Record" for
@
That redirect isn't DNS in the pure sense. It's a forwarding service. Effectively:
- Some resolvers got the real host IP
- Others got the registrar's forwarding IP
- That server then HTTP-redirected to the target
From some regions, that forwarding infrastructure was slow or unreachable. So users were randomly routed either directly to my app (works) or through registrar forwarding (sometimes fails).
From the outside, this looks like a flaky app. In reality, it's split behavior at the DNS/forwarding layer.
URL Redirect Record @ → http://www.jar.tools/
👉 That URL Redirect Record is the culprit.
On Namecheap, a URL Redirect is not DNS — it’s a forwarding service that: resolves your domain to Namecheap IPs (often 162.255.x.x)
So some probes resolve:
jar.tools → Namecheap forwarding IP → redirect
If that forwarding node is slow/unreachable from certain regions:
💥 PageSpeed fails 💥 Global checks show 162.255.119.211 💥 Random “Unable to connect”
Exactly my symptoms
Why It Worked Before
If the redirect record existed all along, why did the issue only appear recently?
The short answer: DNS caching and the way registrar forwarding works.
A registrar "URL redirect" isn't a standard DNS record. It's a forwarding service layered on top of DNS. The registrar resolves your domain to their own IPs and then performs an HTTP redirect to your target.
This creates two possible resolution paths:
- Direct resolution to the intended host
- Resolution to the registrar's forwarding servers
Which path a user hits depends on:
- Cached DNS answers in recursive resolvers
- TTL expiration timing
- How the registrar's DNS system prioritizes forwarding vs normal records
The Timeline of Failure
When the domain was first configured, many resolvers likely cached the "correct" path directly to the app. As long as those caches remained valid, traffic flowed normally.
But DNS caches eventually expire.
Once they did, resolvers had to re-query the authoritative nameservers. At that point, some queries were answered via the registrar's forwarding logic instead of the direct host mapping. Now the domain sometimes resolved to the registrar's forwarding servers rather than the app itself.
That introduced a new dependency: the registrar's HTTP forwarding infrastructure.
Even if that infrastructure is generally reliable, it's:
- Another network hop
- Another system that can rate limit or fail
- Potentially weaker in some regions than a modern edge host or CDN
What Actually Changed
The site didn't "suddenly" break. Instead, a latent misconfiguration became visible as caches expired and more traffic flowed through the forwarding path.
The system didn't change—the probability distribution of which path users took did.
Once the redirect record was removed and DNS pointed only at the hosting provider, the inconsistency disappeared.
The Fix
The fix was simple: delete the URL Redirect Record and keep only real DNS records pointing to the host. After that:
dig A example.com @1.1.1.1 dig A example.com @8.8.8.8
Both returned only the correct IPs. No more registrar IPs. No more forwarding layer. After caches expired, the issue disappeared.
Takeaways
"Works for me" is not a data point. Your resolver cache and geography hide real issues. Always test multiple resolvers and regions. Simplest test for me was my friends and PageSpeed Insights
Registrar panels are production infrastructure. Old redirects, parking records, and defaults can affect live traffic. Review your configs today and keep it tidy