
Your AI Means Nothing Without the Data.
Everyone in data engineering is fighting a hard battle you know nothing about.
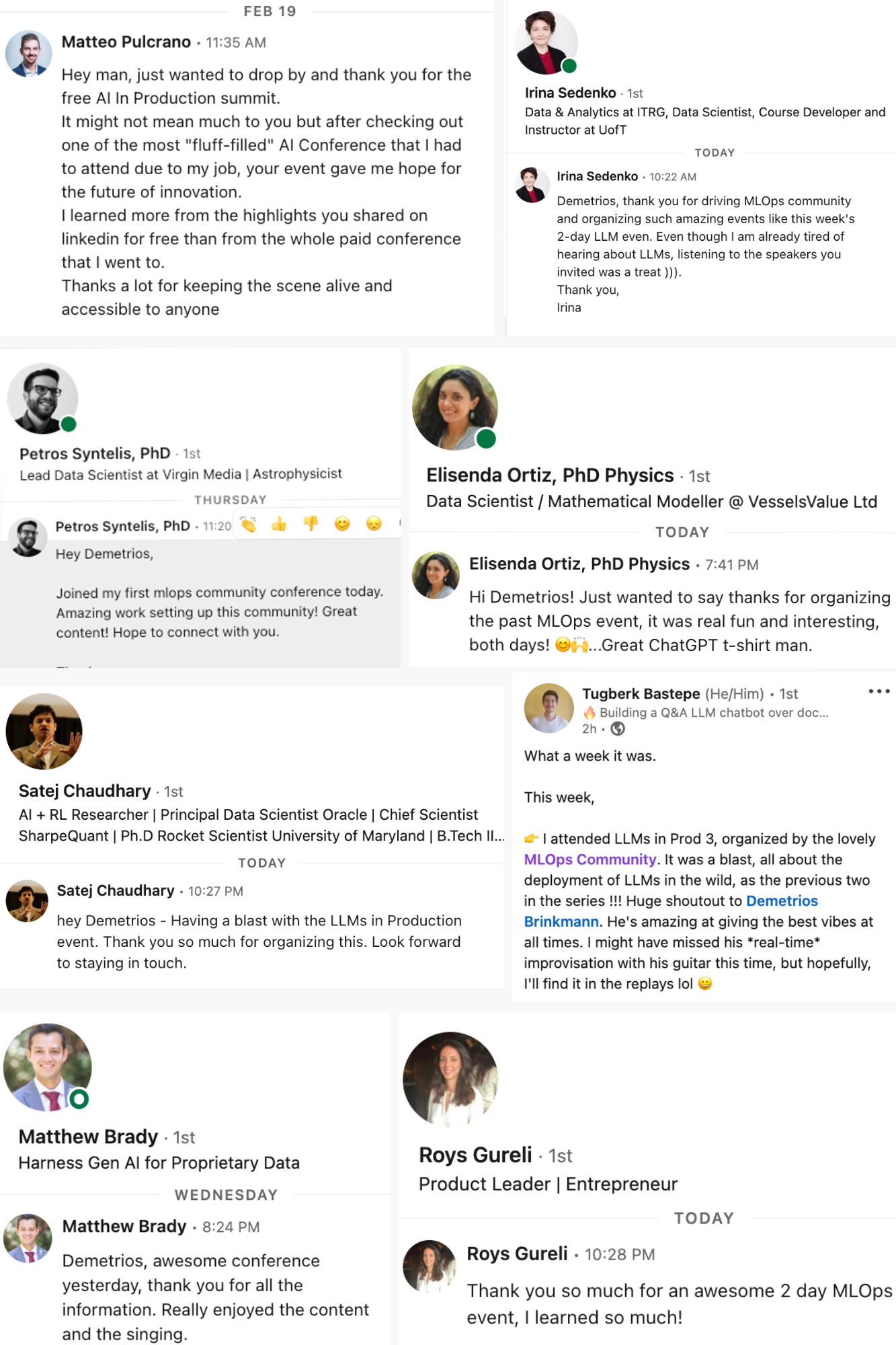
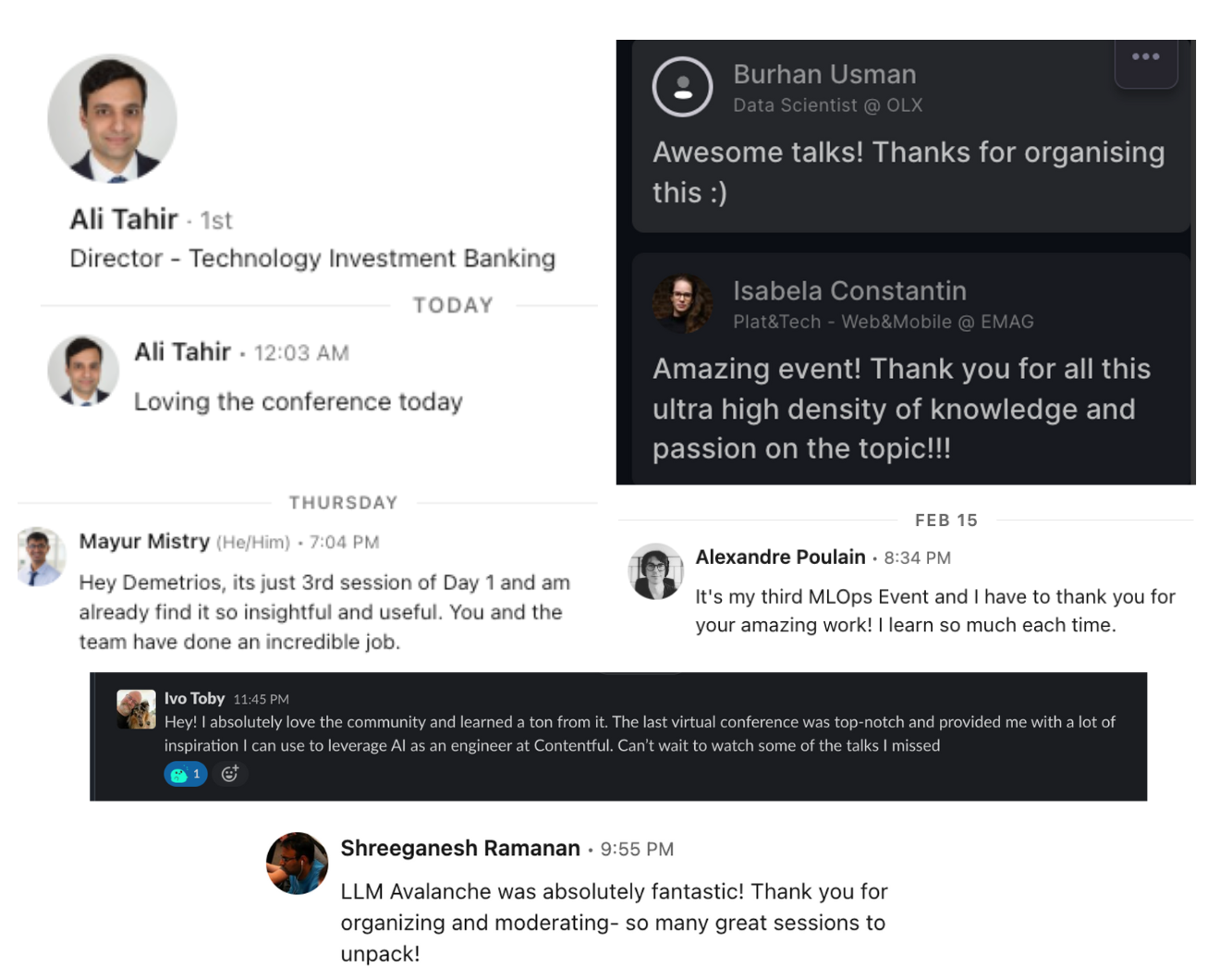
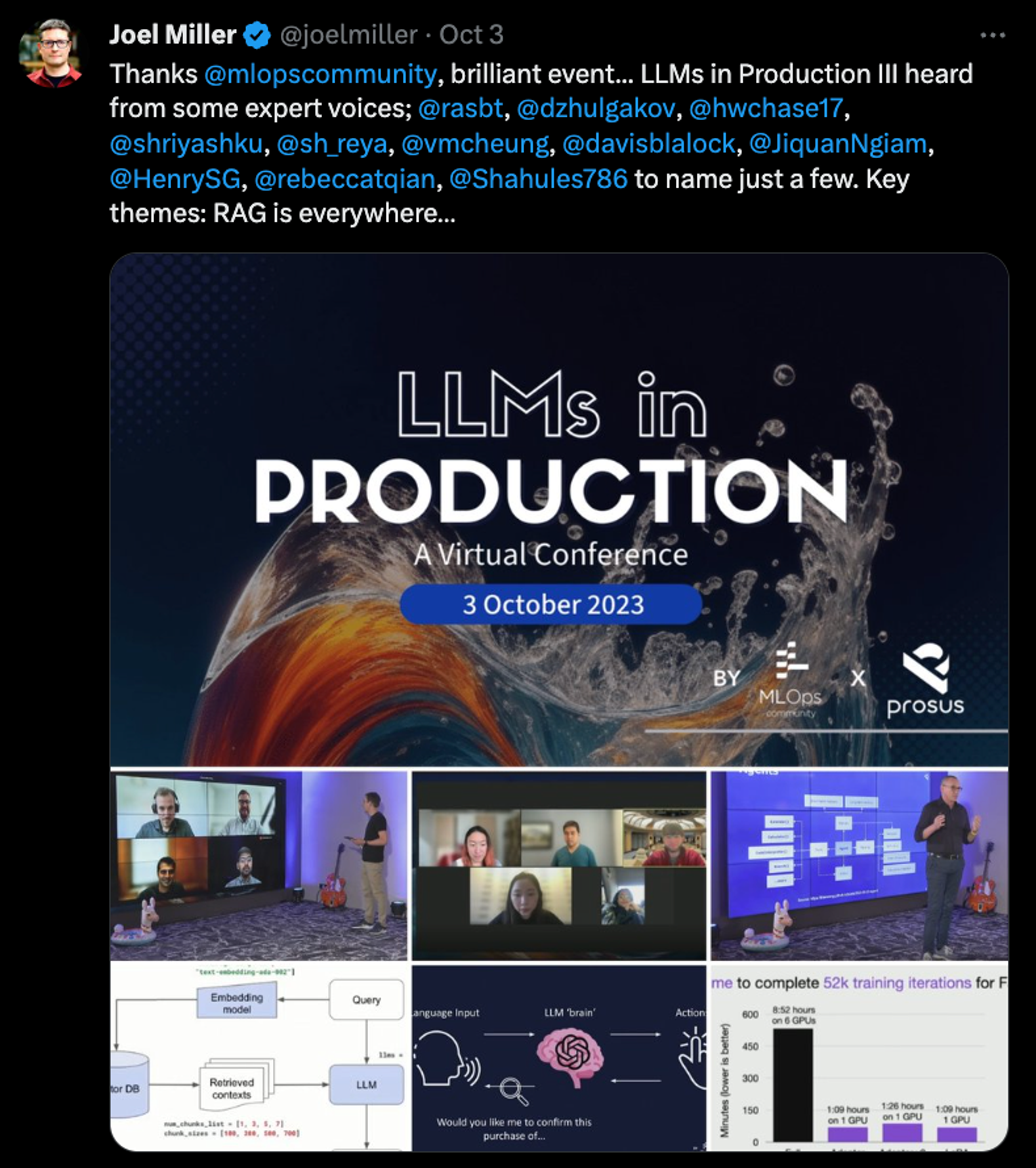
This is a conference at the intersection of Data and AI. It will be fun and educational. Don't believe me? Check out what past guests have said.
Oh yeah, and the speakers are top of their game.
Speakers
Sadie St. Lawrence
Founder / AI Instructor @ Human Machine Collaboration Institute / LinkedIn Learning
Hannes Mühleisen
Co-Founder & CEO @ DuckDB Labs
Sol Rashidi
CEO and Founder @ ExecutiveAI
Tengyu Ma
Co-Founder and CEO @ Voyage AI
Shelby Heinecke
Senior AI Research Manager @ Salesforce
Joe Reis
CEO/Co-Founder @ Ternary Data
Ryan Wolf
Deep Learning Algorithm Engineer @ NVIDIA
Yangqing Jia
Founder @ Lepton AI
Chad Sanderson
CEO & Co-Founder @ Gable
Vinoth Chandar
Founder/CEO @ Onehouse
Miriah Peterson
Data Engineer @ Soypete tech
Benjamin Rogojan
Data Science And Engineering Consultant @ Seattle Data Guy
Michael Del Balso
CEO & Co-founder @ Tecton
Pushkar Garg
Staff Machine Learning Engineer @ Clari Inc.
Simon Whiteley
CTO & Co-Owner @ Advancing Analytics
Shailvi Wakhlu
Founder @ Shailvi Ventures LLC
Aishwarya Joshi
Machine Learning Engineer @ Chime
Aishwarya Ramasethu
AI Engineer @ Prediction Guard
Ciro Greco
Founder and CEO @ Bauplan
Sridhar Natarajan
Senior Software Engineer @ Intuit
Daniela Santisteban
Product Manager - Data Taxonomies @ Numerator
Nikhil Simha
CTO @ Zipline AI
Sri Harsha Yayi
Product Manager @ Intuit
Tobias Macey
Associate Director of Platform and DevOps Engineering @ Massachusetts Institute of Technology (MIT)
Alex Strick van Linschoten
ML Engineer @ ZenML
Demetrios Brinkmann
Chief Happiness Engineer @ MLOps Community
Beverly Wright
VP - Data Science & AI / CAIO @ Wavicle Data Solutions
Rebecca Taylor
Tech lead: Personalization @ Lidl e-commerce
Emily Ekdahl
AI Ops Engineer @ Gusto
Jacopo Himberg
Director, Data @ Wolt
Devon Mittow
Staff Software Engineer @ Lyft
Jose Navarro
MLOps Engineer @ Cleo
Stephen Bailey
Data Engineer @ Whatnot
Mark Freeman
Tech Lead, GTM Engineering @ Gable
Victor Cuadros
Senior Software/Data Engineer @ Microsoft
Akmal Chaudhri
Technical Evangelist @ SingleStore
Jesse Anderson
Managing Director @ Big Data Institute
Mehdi Ouazza
Data Eng & Devrel @ MotherDuck
Michelle Leon
Staff Product Manager @ Databricks
Victoria Bukta
Member of Technical Staff @ Databricks
Christophe Blefari
CTO & Co-founder @ NAO
Daniel Svonava
CEO & Co-founder @ Superlinked
Maggie Hays
Founding Community Product Manager, DataHub @ Acryl Data
Korri Jones
Senior Lead Machine Learning Engineer @ Chick-fil-A, Inc.
Nehil Jain
MLE Consultant @ TBA
Sonam Gupta
Sr. Developer Relations @ aiXplain
Valdimar Eggertsson
AI Developer @ Snjallgögn (Smart Data inc.)
Simba Khadder
Founder & CEO @ Featureform
Jay Chia
Cofounder @ Eventual
Colleen Tartow
Field CTO @ VAST Data
Elena Boiarskaia
Head of Applied Machine Learning @ Snorkel AI
Ben Wilson
Software Engineer, ML @ Databricks
Agenda
Welcome - Data Engineering for AI/ML
Speakers:

11 lessons learned from doing deployments
With over 200+ POCs built and with nearly 40 products in production, Sol walks us through the journey of developing AI products at scale and the 11 Lessons Learned in the journey - spoiler alert, only 30% of the challenges are tech related, 70% are non-tech issues!
Speakers:

Diving into the results of the 2024 Data Teams survey.
Speakers:

Building Data Infrastructure at Scale for AI/ML with Open Data Lakehouses
Data engineers love to solve interesting new problems. Sometimes an existing off-the-shelf tool will suffice; sometimes we have to get creative and come up with new ways to build with our existing toolkit. And, perhaps most rewarding, some use cases call for us to develop something completely new that takes on a life of its own - see Apache Spark, Apache Kafka, and the entire data lakehouse category for somewhat recent examples.
AI and ML engineers find themselves at these crossroads all the time. In this keynote, we will explore how a data lakehouse architecture with Apache Hudi is being used to support real-world predictive ML and vector-based AI use cases across organizations such as NielsenIQ, Notion, and Uber.
We’ll explore how a data lakehouse can be used to ingest data with minute-level freshness and provide a single source of truth for all of an organization’s structured and unstructured data. We’ll show how the lakehouse can be used for feature engineering, to generate accurate training datasets and generate production features. We’ll further explain the role of the lakehouse for GenAI use cases, allowing organizations to operate vector generation pipelines at scale and integrate with vector databases for real-time vector serving.
Speakers:

Going Beyond Two Tier Data Architectures with DuckDB
DuckDB is an in-process analytical data management system. DuckDB is lightweight yet fast and available under the permissive MIT license. DuckDB can be deployed everywhere, from a smart watch to a big iron server. This flexibility has lead to a plethora of new and exciting data architectures, for example on-device processing , SQL lambdas, efficient large-scale pipelines, in-browser SQL, and more.
In this talk, Hannes will give an overview of architectures observed in the wild and some ideas on what would be possible.
Speakers:

Data Infrastructure Cost: Tips to Keep Our CFOs Happy
“Hey Platform team, any idea why the cloud bill is up by X% this term compared to our previous one?”
As platform engineers working at organisations developing or using AI products, that X % amount can be quite high very quickly.
In this talk, I will show some strategies that you can use to reduce the cost of your Data Infrastructure, share the responsibility across product teams and control it overtime.
Speakers:

Building Hyper-Personalized LLM Applications with Rich Contextual Data
In the era of AI-driven applications, personalization is paramount. This talk explores the concept of Full RAG (Retrieval-Augmented Generation) and its potential to revolutionize user experiences across industries. We examine four levels of context personalization, from basic recommendations to highly tailored, real-time interactions. The presentation demonstrates how increasing levels of context - from batch data to streaming and real-time inputs - can dramatically improve AI model outputs. We discuss the challenges of implementing sophisticated context personalization, including data engineering complexities and the need for efficient, scalable solutions. Introducing the concept of a Context Platform, we showcase how tools like Tecton can simplify the process of building, deploying, and managing personalized context at scale. Through practical examples in travel recommendations, we illustrate how developers can easily create and integrate batch, streaming, and real-time context using simple Python code, enabling more engaging and valuable AI-powered experiences.
Speakers:

The Daft distributed Python data engine: multimodal data curation at any scale
It's 2024 but data curation for ML/AI is still incredibly hard. Daft is an open-sourced Python data engine that changes that paradigm by focusing on the 3 fundamental needs for any ML/AI data platform:
-
ETL at terabyte+ scale: with steps that require complex model batch inference or algorithms that can only be expressed in custom Python.
-
Analytics: involving multimodal datatypes such as images and tensors, but with SQL as the language of choice.
-
Dataloading: performant streaming transport and processing of data from cloud storage into your GPUs for model training/inference
In this talk, we explore how other tools fall short of delivering on these hard requirements for any ML/AI data platform. We then showcase a full example of using the Daft Dataframe and simple open file formats such as JSON/Parquet to build out a highly performant data platform - all in your own cloud and on your own data!
Speakers:

How Feature Stores Work: Enabling Data Scientists to Write Petabyte-Scale Data Pipelines for AI/ML
The term "Feature Store" often conjures a simplistic idea of a storage place for features. However, in reality, feature stores are powerful frameworks and orchestrators for defining, managing, and deploying data pipelines at scale. This session is designed to demystify feature stores, outlining the three distinct types and their roles within a broader ML ecosystem. We’ll explore how feature stores empower data scientists to build and manage their own data pipelines, even at petabyte scale, while efficiently processing streaming data, and maintaining versioning and lineage.
Join Simba Khadder, founder and CEO of Featureform, as he moves beyond concepts and marketing talk to deliver real-world, applicable examples. This session will demonstrate how feature stores can be leveraged to define, manage, and deploy scalable data pipelines for AI/ML, offering a practical blueprint for integrating feature stores into ML workflows.
We’ll also dive into the internals of feature stores to reveal how they achieve scalability, ensuring participants leave with actionable insights. You’ll gain a solid grasp of feature stores, equipped to drive meaningful enhancements in your ML platforms and projects.
Speakers:

Guest Roundtable Discussion
DuckDB is fast for analytics, but what can it do for AI?
The need for versatile and efficient search mechanisms has never been more critical. This talk will explore DuckDB's underrated search capabilities and usage within an LLM stack.
Speakers:

From Notebook to Kubernetes: Scaling GenAI Pipelines with ZenML
This lightning talk demonstrates how ZenML, an open-source MLOps framework, enables seamless transition from local development to cloud-scale deployment of generative AI pipelines. We'll showcase a workflow that begins in a Jupyter notebook, with data processing steps run locally, then scales up by offloading intensive training to Kubernetes. The presentation will highlight ZenML's Kubernetes integration and caching features, illustrating how they streamline the development-to-production pipeline for generative AI projects.
Speakers:

LLMs in Financial Services: Personalized Portfolio Recommendation Engines
This session will delve into how LLMs can be leveraged to create highly personalized and efficient portfolio recommendation engines. Using a Kafka stock ticker feed, tick data will be ingested into a database system where we'll query the data using natural language and build a simple chatbot using speech-to-text.
Speakers:

Unified Data + AI Governance with Unity Catalog
In today’s multi-vendor data and AI landscapes, organizations often find themselves struggling with fragmented governance. The proliferation of diverse tools and platforms leads to increased overhead, making it challenging to maintain a unified governance strategy across data and AI assets. This session will explore what a typical multi-vendor organization looks like and highlight the common challenges they face.
We’ll delve into the complexities of the current governance space, focusing on the inefficiencies and risks that arise from tool sprawl. The talk will then introduce Unity Catalog’s mission to simplify and unify governance across diverse data formats and AI assets. Attendees will gain insights into how Unity Catalog’s multi-format, multi-asset approach enables seamless governance, empowering organizations to effectively manage their data and AI resources under a cohesive framework.
Join us to discover how Unity Catalog can transform your organization’s governance strategy, reducing overhead and enhancing control over your data and AI assets.
Speakers:


Musical Entertainment By Yours Truly
Speakers:
Data Scientists & Data Engineers: How the Best Teams Work
There are clear patterns that make the highest functioning data teams work so well together. In this panel we will explore what data scientists and data engineers need to know about each other's responsibilities to speak the same language and align incentives.
Supercharging Your RAG System: Techniques and Challenges
Retrieval-augmented generation is the predominant way to ingest proprietary unstructured data into generative AI systems. First, I will briefly state my view on the comparison between RAG and other competing paradigms such as finetuning and long-context LLMs. Then, I will briefly introduce embedding models and rerankers, two key components responsible for the retrieval quality. I will then discuss a list of techniques for improving the retrieval quality, such as query generation/decomposition and proper evaluation methods. Finally, I will discuss some current challenges in RAG and possible future directions.
Speakers:

Sponsors
September 12, 1:00 PM GMT
![]()
Agentic AI Foundation
September 12, 1:00 PM GMT
![]()
Agentic AI Foundation