The C++ documentary dropped today, and it is a fine piece of filmmaking and a slightly dishonest piece of history. Not in what it says. In what it lets you assume.
Two and a half hours of the people who were actually in the room: Stroustrup, Stepanov, Sutter, Alexandrescu, a few Bell Labs survivors, somebody from CERN, somebody from a game studio, and about ninety seconds of Hudson River Trading talking about microseconds. The history is genuinely good, and I will give it that before I take anything away. But you come out of it believing two things that are not true, or at least not yet true, and both of them matter if you ship latency-sensitive C++ for a living.
You come away believing C++26 answered the memory-safety regulators. It did not. The headline fix, Profiles, did not ship. And the film asserts a performance-per-watt moat three separate times without ever putting a number on screen. Fine. I will put the number on screen. It is more interesting than the film's version anyway, because it inverts what you would guess.
What the film gets right
Give credit first. The structure the editors chose is the smartest thing in the documentary, and they never say it out loud: C++ has had two winters, not one, with a long boom between them. How it survived the first tells you almost everything about whether it survives the second.
The first winter was around 2000 to 2005. Dot-com crash, Java with a marketing budget C++ never had, executives saying Java would kill C++ in two years. Microsoft building C# so enterprise shops would stop writing every app twice. The film covers all of it. What the film also gets right, and what most people forget, is that none of that was the real threat. The real threat was that the hardware was still bailing everyone out. Clock frequency was still climbing, and as long as it climbed, "performance does not matter, just wait a year" was a defensible engineering position. If your bloated program is slow today, the faster part lands next quarter. In that world an efficient language is a tax nobody volunteers to pay.
Then the lunch counter closed. On May 7, 2004, Intel cancelled Tejas, the Pentium 4 successor that was supposed to run at frightening clock speeds, and its Xeon sibling Jayhawk along with it. The reason was heat. Early 90nm samples at 2.8 GHz were already pulling around 150 watts against roughly 84 for the comparable Prescott part, and the roadmap walked straight into a wall of watts. Intel pivoted to dual core. Single-thread clock plateaued in the 3 to 4 GHz band, and twenty years later that is still where we live. Herb Sutter wrote the obituary, "The Free Lunch Is Over", online in December 2004 and in Dr. Dobb's the following March. If you wanted your program faster after that, the hardware was done doing the work for you.
The winter we never had
Here is the part the film tells through the HRT segment, and the part the trading floor understands in its spine. The "wait a year for double the clock" bargain never applied to us.
When your product is tail latency, not throughput, a faster part next year does nothing for a hot path that is losing the race today. The thing you are optimizing is the time between a packet hitting the NIC and an order leaving it, and no vendor roadmap fixes that number for you. So while the rest of the industry spent the early 2000s deciding performance was solved, the people wiring exchange connectivity were already living in the post-free-lunch world. Our winter never came because our summer was never that warm. The film puts a figure on the modern version: HRT describes over a million lines of C++ across fifteen thousand files, around eighty-four thousand commits in 2025 alone, roughly eight hundred active contributors. That is not nostalgia for a language. That is a bet, renewed every morning, that you can have the abstraction and still own every cycle.
And the end of the free lunch is exactly what saved C++ the first time. Once frequency stopped scaling, the only way left to go faster was parallel, and parallel means you care which language gets the most out of the silicon. The film leans on the phrase performance per watt three times because it is the moat. C++11 landed almost a decade after the C++0x effort started, hauling in move semantics and, more importantly, an actual memory model, the Boehm and Adve work from PLDI 2008 that gave the C family its first formal account of threading. Andrei Alexandrescu had fired the public shot back in August 2004 with a Usenet post titled "Multithreaded programming: is the C++ standardization committee listening?", and for a while the answer was no. C++11 arrived right when the whole industry rediscovered that hardware is finite. That was the boom.
So far the documentary and I agree. Now we stop agreeing.
Where the film changes the subject
The second winter is the memory-safety winter, and the documentary treats it as the next beat in a redemption arc. Crisis arrives, committee rallies, C++26 rides in with reflection and contracts and hardening, roll credits on an optimistic note about the language evolving to meet the needs of programmers. That is the emotional shape of the last twenty minutes.
The crisis half is real and the film does not invent it. In November 2022 the NSA put out a Cybersecurity Information Sheet telling organizations to move off languages with "little or no inherent memory protection, such as C/C++." In December 2023 CISA and eight partner agencies across five countries published "The Case for Memory Safe Roadmaps", telling manufacturers to publish dated plans to get off unsafe code. In February 2024 the White House cyber office followed with "Back to the Building Blocks", naming C and C++ directly. Microsoft and Chromium both report that around 70% of their serious security bugs are memory-safety bugs. Stroustrup himself, in a note to the committee that leaked in 2025, did not pretend it was nothing: the language is under attack, he wrote, and "unless we act now," C++ risks "a painful decline." The US government wants a memory-safety plan by 2026.
That last quote is more honest than the documentary it appears next to. Because the film lets the resolution land while skipping the one fact that ruins the arc: the fix everybody means when they say C++ is getting safe did not make the standard.
The thing the documentary will not tell you about C++26
Profiles is the Stroustrup and Sutter idea of opt-in, statically enforced rule sets for type, bounds, and lifetime safety, switched on per translation unit. It is the answer to the regulators. At the June 2025 meeting in Sofia, the committee sent the framework to a separate whitepaper and pushed the concrete profiles toward C++29 or later. There is no profiles row in the C++26 feature table. The competing Safe C++ borrow-checker proposal was rejected outright. So when the warm music plays over "C++26 looks like a Christmas tree," understand that the one ornament the regulators asked for is not on the tree.
Two smaller things did ship, and they are the ones you can actually measure. First, P2795, erroneous behavior for uninitialized reads, from Thomas Köppe. Reading an uninitialized automatic variable stops being undefined behavior and becomes "erroneous behavior," a careful phrase: the read is still wrong and the compiler is encouraged to diagnose it, but the value is now a fixed implementation-chosen one instead of a license for the optimizer to do anything. GCC 16 implements it; the mechanism underneath is the -ftrivial-auto-var-init=zero you can already use today. Second, P3471, standard-library hardening, from Konstantin Varlamov and Louis Dionne. Out-of-bounds operator[], front() on an empty container, bad iterator arithmetic, all turn from UB into a checked precondition that traps before doing damage. libstdc++ has shipped _GLIBCXX_ASSERTIONS and libc++ has shipped _LIBCPP_HARDENING_MODE for years; C++26 makes it a portable, specified guarantee. Google has said it deployed the equivalent across hundreds of millions of lines at about 0.3% overhead.
That 0.3% is the only number anyone quotes, and it is a fleet-wide average over a codebase that is mostly not your inner loop. The documentary asserts you get abstraction without overhead. The interesting question is not the average across a billion lines. It is what these features cost on the dozen functions where you actually live.
The number the documentary skipped
So I measured it. Threadripper 3960X, Zen 2, the usual isolated core 18 with isolcpus and nohz_full, performance governor, median of 21 runs with the IQR down in the noise. clang 20 with libc++ for the hardening modes, g++ 14 with libstdc++ for _GLIBCXX_ASSERTIONS, and -ftrivial-auto-var-init=zero on both for the init cost, everything at -O3 -march=native. Five small kernels, each indexing through a checked operator[] so the bounds check is genuinely on the path.
Two gates first, because a benchmark you cannot trust is worse than none. Every build variant has to produce a bit-identical checksum on every workload or the run is thrown out. It did. And to prove the hardening is doing something rather than compiling to nothing, a self-test reads one element past the end of a four-element vector: under every hardened build it traps, SIGILL on libc++ and SIGABRT on libstdc++, and under every unhardened build it sails through into UB. So when a number below reads zero percent, that is the optimizer deleting a check it proved it did not need, not a check that was never there.
I wrote the predictions down before running it. I guessed the tight vectorizable loop would get hammered, since a per-element bounds check should wreck autovectorization, and that zero-init would be nearly free, since the code overwrites its buffers anyway. Both guesses were wrong, and being wrong in a reproducible way is the whole reason you write the guess down first.
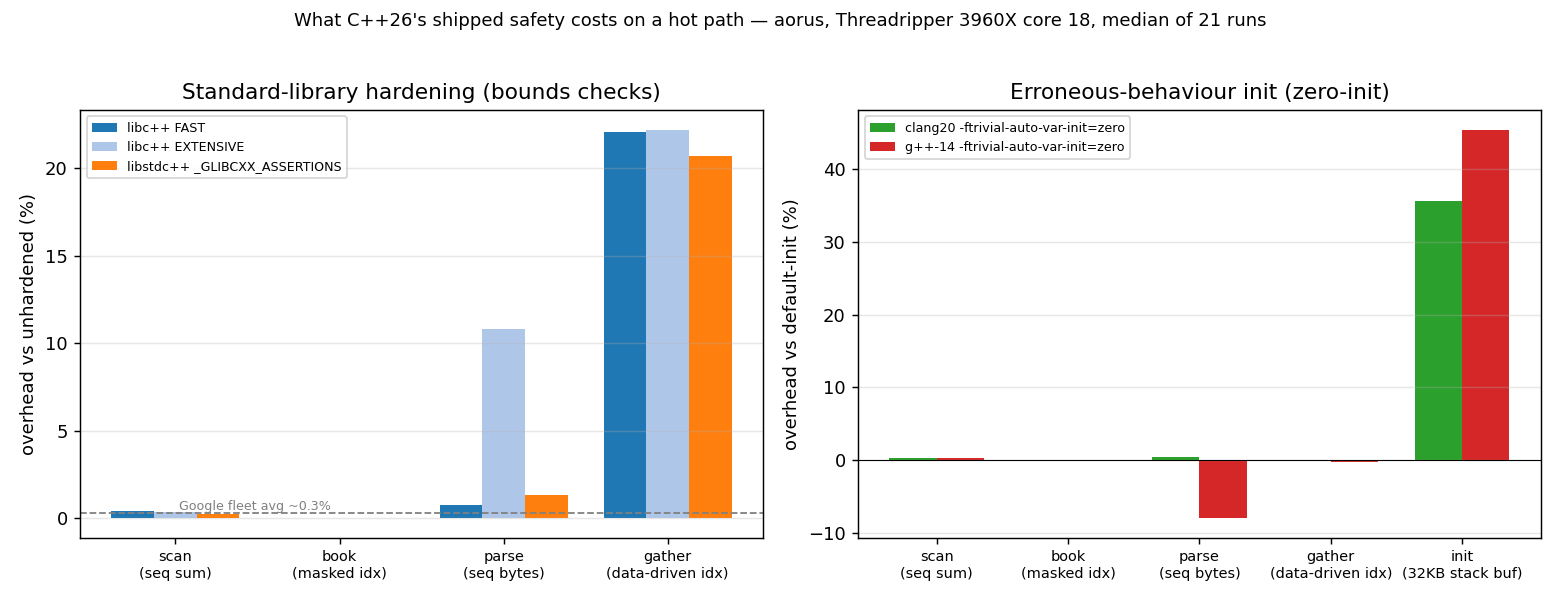
The left panel is hardening. The sequential sum over a vector, the masked order-book index, the byte-at-a-time parse: all of them sit at essentially zero overhead with checks on. The compiler sees the loop counter is bounded by size(), or that a & (L-1) mask forces the index in range, proves the precondition, and removes the check. The bounds check you were taught to fear does not survive the optimizer when the optimizer can do the arithmetic.
Then the fourth bar. The gather kernel, where the index comes from data the compiler cannot reason about:
// indices live in a table; the optimizer cannot bound idx[...] at compile time,
// so the hardened check on v[...] has to stay on the hot path
for (std::size_t i = 0; i < M; ++i)
acc += v[idx[(i + j) & (M - 1)]]; // checked load, runtime index
This is the hash probe. The order-id lookup. The scattered access into a book keyed by something you read off the wire. The compiler has no idea the index is in range, so the check stays, and it costs 22.1% with libc++ FAST, 22.2% with EXTENSIVE, 20.7% with libstdc++ assertions. Two different libraries within a point and a half of each other, which tells you this is a property of the access pattern, not of one vendor's headers. The cruel part is that scattered access is already your slowest code, the code missing in L2 and waiting on memory, and now it also carries a check the compiler cannot hoist. The 0.3% the film would have implied is true on average and irrelevant to that function.
The cheap-sounding feature is the expensive one
The right panel is the one that should bother you, because it is the feature that sounds harmless. Zero-init is free on four of the five kernels. On the fifth it is anything but. The init kernel does the most ordinary thing in the world: put a 32 KB buffer on the stack, fill every byte, sum it, in a hot loop.
static u64 __attribute__((noinline)) init_one(u64 r, const i64* src) {
i64 buf[4096]; // 32 KB automatic buffer
for (std::size_t i = 0; i < 4096; ++i)
buf[i] = src[i] + (i64)r; // every byte written before any read
i64 acc = 0;
for (std::size_t i = 0; i < 4096; ++i)
acc += buf[i];
return (u64)acc;
}
Every byte is written before it is read, so this code was always correct and the verify gate confirms the answer never changes. The buffer never needed zeroing. But -ftrivial-auto-var-init=zero zeroes it anyway, on every call, before your fill loop overwrites all of it, and that dead store is pure tax the optimizer does not always remove. On g++ 14 it costs 45.4%, clean and reproducible. On clang it runs noisier but points the same way, north of 30%. Re-zeroing a large automatic buffer in a hot loop is real memory traffic, and the friendly-sounding feature is the one that lands in your profile.
That is the whole lesson the documentary had room for and skipped. The scary feature, bounds checking, is genuinely free across most of your code and costs a fifth only on the unpredictable accesses. The friendly feature, automatic initialization, is free across most of your code and costs nearly half on a hot function with a big stack buffer. Neither matches the headline in either direction, and neither is something you find out from a committee paper or a feel-good film. You find it out by measuring your own hot path, which has always been the job.
So is it dying
No, and the documentary's optimism is earned by the history even where its honesty about the present is not. C++ does not survive its winters by winning arguments about elegance or by getting a flattering documentary. It survives because when the free lunch ends, whether the lunch was clock speed in 2004 or the fantasy that you rewrite a billion working lines on a regulator's timeline today, the thing that still does the job is the language that hands you the abstraction and the cycles at once. The developer count the film cites went from 9.4 million in 2022 to 16.3 million in 2025. That is not decline.
But do not let the warm ending sell you a resolution that has not shipped. The safety winter is not over, Profiles is not in C++26, and the two features that did land have costs that are zero in most places and brutal in a couple of specific ones. The honest version of the documentary's last act is short: turn on library hardening, build with defined initialization, then go measure what they cost on the functions that matter, because for most of your code the answer is nothing and for the hash probe and the big stack buffer it is not. Knowing which of your functions is which is the part nobody can standardize for you, and no documentary is going to do it either.