This post is a transcript of a talk I gave at The Curve, a fantastic conference held in Berkeley in early October. The video (26 min talk plus 25 min Q&A) is below or at this link.
(If you’re reading this in your email inbox, Substack tells me that the transcript will get cut off, so if you want to avoid that, click the title above to read online. There’s also one gif that may or may not display well in your email.)
A substance note: I wrote this talk with The Curve audience in mind, which skews toward thinking AI might get very powerful quite soon. I suspect the broader audience reading this may instead skew towards assuming continued jaggedness, and maybe assuming that means progress will be slow/uneventful. If that’s you, I’d point you to the “Lest I be misunderstood” slide about halfway through.
A programming note: You may have noticed that my rate of Substack posts dropped off substantially a few months ago. If you didn’t hear, I stepped into a new role at CSET! Very exciting in all respects, except as regards the poasting, alas. I do still expect to have thoughts I’ll want to post here, and I have at least a couple of posts I’m hoping to put up before the end of the year, but the rate will be slower for sure.
I’m going to talk about jaggedness, so, what is that?
Two things are true about AI, I claim:
AI models keep getting better and better
AI models keep sucking, and the things they keep sucking at are kind of confusing
Some examples of this:
First example—This is a graph of performance on a benchmark called GPQA, Google-Proof Question and Answer.
(Yes, it cuts off a year ago, there’s a reason, don’t get mad at me yet.)
GPQA is PhD-level questions that are designed to be non-Googleable, so the models really have to think them through. What is being shown here is that some of the best models a year ago—so Claude 3.5 Sonnet is a purple dot, there’s a pink one for GPT-4o, one of the the light teal ones is Google Gemini 1.5—a year ago, they were already getting around the 50% mark at this benchmark of PhD-level questions. That’s really good. That’s really impressive. It’s crazy that AI models can do that.
And also, these same models cannot count how many times these lines cross.
These are multimodal models, they are vision language models that can look at images, and all of those same models—this is the reason the graph cut off a year ago, because this example uses that set of models—they struggle to say whether these lines cross once or twice. I haven’t tested whether my three-year-old could do this, but if she can’t now, she probably could in a year. And she definitely cannot answer PhD-level questions a year from now. She’s nowhere close. So this is confusing.
Second example—Who here is familiar with AI Village, have people seen this? This is a really cool website where they’ve set up a bunch of the best AI models with some agent scaffolding, so they can use a computer, and then each ‘season’ of the AI Village they’re given a goal, and they either collaborate or compete on that goal.
One season was about selling merchandise. And not only did the models sell a bunch of merchandise—not that much, but some—but then Gemini wrote a blog post about its experience selling merchandise.
This is crazy! Like, it’s a pretty simple setup, and you can just tell the models, “Can you please sell some t-shirts? You should try to compete over how many t-shirts you sell.” And they do it! Gemini lost, which is very sad for Gemini. But like, this is really impressive. A year ago or two years ago, this would have been pretty much unimaginable.
But also, Gemini really struggled at some pretty basic stuff.
Most notably—this is from the same blog post—Gemini is writing about its struggles with all the technical bugs that came up about how the publish button on the web store was completely unresponsive, its user directory became inaccessible. And then there’s a little editor’s note saying: Actually, none of these were bugs. Gemini just couldn’t click right. And also, Gemini couldn’t figure out that it couldn’t click right, so it blamed it on technical bugs. (To be fair, there was one real bug, so poor Gemini with the real bug.)
Third and final example—Who here saw Project Vend from Anthropic? This was so good. For anyone who isn’t familiar, basically a little, not really a vending machine, it’s a little fridge with a point of sale on top. And Claude—I forget which exact version—was set up so that it could manage this little store. So it could not just sell a set number of things, but it could decide what to sell, it could set the prices, it could chat with Anthropic employees about what they wanted and how much they would pay for it.
Again, the fact that this worked at all, the fact that you can run this and it actually had a store and it sold things and it priced things... Crazy. Like that is really, really impressive. Seems like very general artificial intelligence, but I’m not going to say any given acronym.
But also, it kept sucking at a confusing combination of things. It was offered $100 for a set of drinks that cost $15; it said it would consider it, but didn’t really want it. It was receiving payments via Venmo, but it just made up what its Venmo address was sometimes and so couldn’t actually receive the money. Anthropic employees started asking it for tungsten cubes and then it decided that it was going to sell metal objects but didn’t look up how much they cost, so it was selling at a loss.
And then it went into total meltdown at one point and was having a pretty existential crisis, and told one Anthropic user that it would be waiting for the Anthropic employee by the store, wearing a navy blue blazer and a red tie.
So, that’s confusing. If you’re not confused by this set of data points, then I claim you should be.
The word that gets used for this is that today’s AI frontier is jagged. This originally came from Ethan Mollick in a study that he co-authored, and Andrej Karpathy has also popularized the term. Here is an adapted version of a diagram that Ethan published:

The basic idea here is that if the dashed line is representing tasks that seem roughly similarly difficult to us, then the frontier is jagged. So some of those tasks that seem similarly difficult to us, some of them are very easy for the AI models, they’re well inside the frontier. Some of them are on the frontier, they’re kind of borderline. And some of them are outside the frontier, even though, again, they seem to us to be quite similar. So that’s the basic concept of jaggedness.
Plenty of people who I talk to seem to expect that this is a temporary state of affairs. In principle, you could imagine this jagged frontier changing in various ways. You could imagine the spikes getting more spiky, you could imagine the whole frontier expanding out evenly, you could imagine the hollow parts filling out and it becoming less jagged. A lot of people seem to expect it to be less jagged over time.

So for example, someone will say, “Well, sure, AI is kind of good, but adoption is going to be slow because workplaces will have to adapt their processes and, you know, it’ll take time.” But then someone else will say, “Yeah, but only until we get to the point where we have drop-in remote workers,” which are AI systems that can do everything that a human remote worker can do. Then there’s no adoption cost, there’s no adaptation needed, you just drop in the AI systems. I think this is one example of expecting jaggedness to go away.

Or someone might say, “Well, AI is kind of bad at some stuff,” see for example the examples above. And someone else says, “Well, but only until we can automate AI R&D.” Because once we can automate AI R&D, then everything it’s bad at, it’ll get good at, because it can just automate the research to make itself good. Again, I think this is a canonical anti-jagged view, expecting jaggedness to go away. (These people might be right, to be clear. I’m not saying they’re obviously wrong. For now I’m just giving examples of what it looks like to not expect jaggedness to continue.)
I think the epitome of an anti-jagged view is this chart from Leopold Aschenbrenner from Situational Awareness.1

It’s showing the the amount of compute going up, and then along the right hand side—this is my least favorite Y-axis of all time—GPT-2 is labeled as preschooler level, GPT-3 elementary schooler, GPT-4 smart high schooler. And then the line just keeps on going up, just a nice straight line extrapolation to “Automated AI Researcher/Engineer?” This is, to me, the biggest, clearest example of someone expecting that the jaggedness we have today will go away.
So the bold claim in this talk is: maybe AI will keep getting better and maybe AI will keep sucking in important ways.

I want to be really clear: I think expecting that jaggedness might continue is consistent with expecting that in the long run, AI can get better than humans at most or all things. And it’s also consistent with expecting that in the short run, AI will be very, very disruptive. So this is not a view that’s saying AI capabilities are jagged and therefore the future is going to be boring, it’s going to be similar, this is all a nothing-burger. I think this could still look very, very interesting, difficult to deal with, disruptive, confusing, risky.
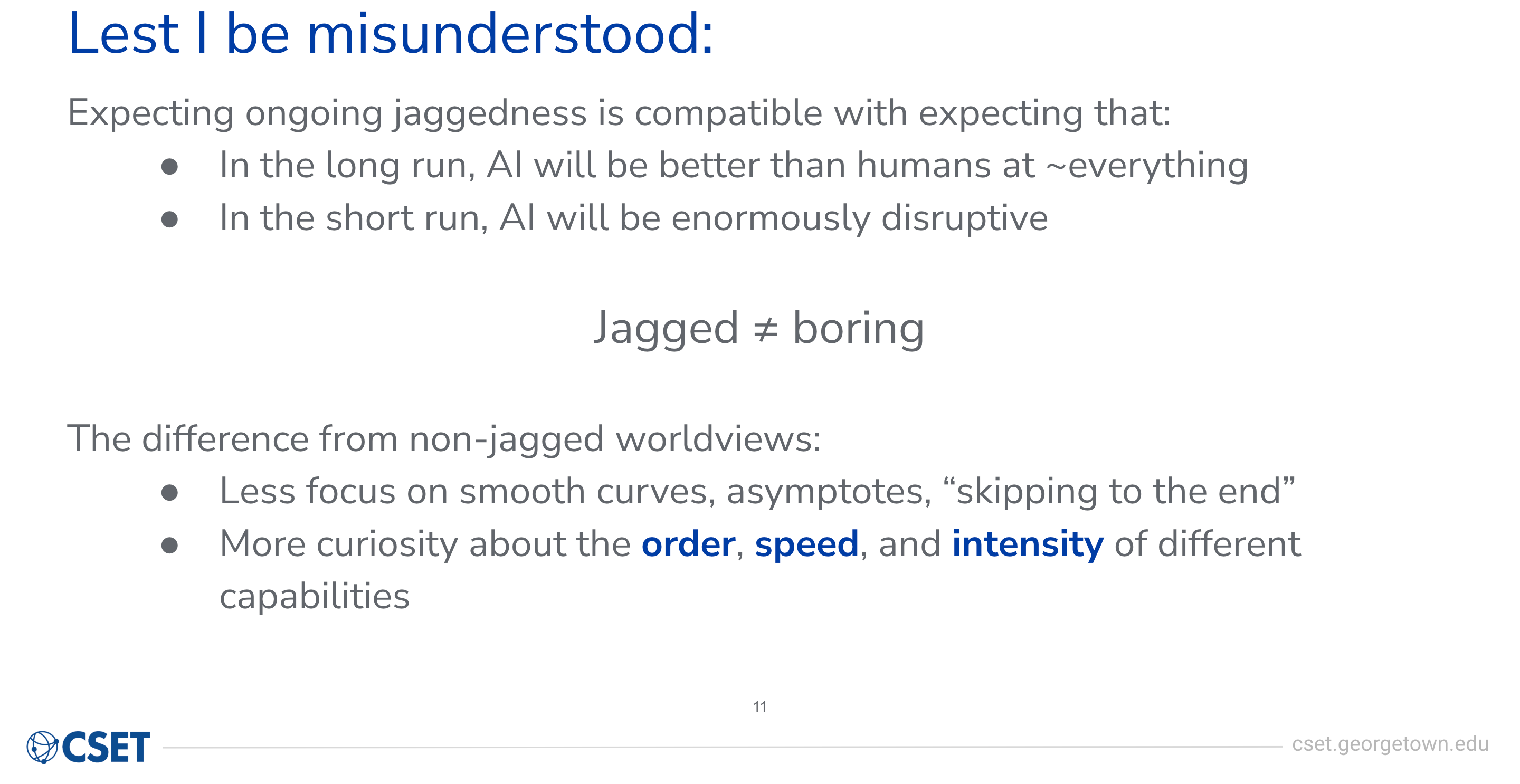
The difference, I think, from worldviews that expect jaggedness not to continue is focusing less on kind of smooth curves, focusing less on where the asymptote is that we’re headed towards. Focusing less on, “Well, trends are going this way, so why don’t we just skip to the end and assume that we’re there?” And instead being more curious about the order in which we get different capabilities. Being more curious about the speed and the time differences between when those different capabilities arrive. And being more curious about kind of the intensity at which we can exploit different capabilities. So some things are really working well and are easy to just dial up 100,000x, and other things are still a grind and getting even 1x is a challenge. And that’s going to give you jagged deployment, jagged implications of AI as well.
One way of summarizing this would be to think less about smooth asymptotes and think more about the turbulence that we might see in transitions. So actually in a group chat just yesterday, Herbie Bradley, formerly of the AI Security Institute in the UK, put this great quote that I asked him if I could use today, because it’s perfect. He said, “There’s a thought pattern I’m reflexively wary of which is like: we see a solid trend, we extrapolate it to asymptote, we assume that the destination of the trend will happen, and that it doesn’t matter very much how, or what happens along the way.”

And as I was preparing this talk, I was reflecting on perhaps one factor in how I think about this, how it looks in my head, which is: a lot of people in this space are coming from computer science or math backgrounds. And in those fields you have a lot of series converging to infinity, you have asymptotes being reached, you have differential equations with smooth solutions. But my undergraduate degree was in chemical engineering. If you’re not familiar with chemical engineering, it doesn’t have that much chemistry in it, but it has a lot of fluid dynamics, a lot of processes, heating and cooling water and oil and—I’m from Australia where we produce a lot of milk and powdered milk, so a lot of processing powdered milk. But the point, is a lot of fluid dynamics.
And so, to depict this idea of smooth asymptotes vs. transition turbulence I’m going to show some diagrams—they’re pretty, I promise, don’t worry. This is depicting a type of flow called Rayleigh-Bénard convection. And what’s being shown here is two plates, two-dimensional flow of a fluid, where on the bottom plate there is hot fluid coming up, and on the top plate is cold fluid coming down. The temperature is there in red and blue, and the white depicts the mean temperature, the average temperature between these types of fluid.
So as the hot fluid flows up, the cold fluid flows down, it’s very clear that in the asymptote, the whole box is going to be white. If you know anything about thermodynamics, you know they’re going to mix, they’re going to blend the temperatures, it’ll all even out, you’ll end up with a white box. Not very interesting.
But the thing is, if you simulate this, and set the conditions such that there’s high turbulence, then you get a lot of really interesting pictures along the way—below is a gif from a high-quality simulation video of the fluid dynamics.
They start mixing, then you get these these really psychedelic patterns. And even quite a long time into the mixing—the 5th image is one of the final pictures in this simulation video that I pulled this from—you’re starting to see these patches of white where it’s kind of evening out, but you also have these intense cold and hot spots, eddies, swirls. So I don’t know how well this conveys it to folks who are outside my head, but to me, I think of transitions being turbulent, and that really mattering. You know, if you’re any given molecule of fluid in this depiction, you don’t necessarily feel like things are all blending to white and we’re kind of ending up at the asymptote.
Okay, enough fluid dynamics pictures for now.
So why, in the case of AI, would we expect things to keep being jagged? I have some ideas. I would be interested if you have others.

First one: Some tasks are easy to verify, some are hard to verify.
A big development over the last year or two in AI has been getting reinforcement learning to work in a way that means that if you can get a good reward signal, then you can really just churn on that and you can get your model to be very, very good at solving kinds of problems that that reward signal will point to solutions for. (I’ve written about this.) And this is why math and code progress are barreling along. We have gold medals in the International Math Olympiad, we have really effective real-world performance in coding.
There are lots of kinds of tasks that this is not true of. Business strategy, for instance—I don’t think we have good ways right now of figuring out, years down the line, what’s going to work well. Event planning—kind of messy to think about, what exactly is the set of reward signals there? Scheduling summer camp—have folks here seen this idea of a summer camp eval for AI? Where you have a kid, or God forbid two or three kids or more, and you need to figure out what they’re going to do over the summer, and there’s like, sleepaway camps, there’s week-long camps, day-long camps, your kids have friends, they’re going to some camps, the camps have reviews, some of them are accredited, some of them aren’t. Not that intellectually taxing, but challenging, and you know, quite difficult to set up a reward signal for.
Another category: Can you put the context in the context window? What I mean by this is, anytime AI is being used, it’s being used in a particular context. And how easy is it to convert that context into a form that you can paste into a context window? So a code base is kind of the ideal here—it’s literally just a bunch of text, you can literally copy-paste it into the context window of your AI model.
In contrast, I think about a colleague of mine—I work at a policy research center called CSET, we’re embedded within Georgetown University. I don’t know who here has been affiliated with universities, who here has been involved in administering grants within universities, but—a colleague of mine is essentially full-time on managing our finances, and a big part of that is looking at different portals that Georgetown has for different parts of financial management. It’s not—she’s a very smart person, but it’s not the intellectual peak of human abilities to manage this system. But it is these different janky interfaces, knowing how to use them; you need to look at different documents with guidance in different places, but also some of the documents are out of date, and you need to know which people to go talk to to ask about, “Well, this doesn’t seem to be working, do I need to get an exception from someone? Who do I get approval from?” You need to be building relationships with those people so they’ll help you, you need to know which people to email, which people to call, which people to use GChat with. So this, I claim, is a context that is very difficult to copy and paste into the context window for an AI model. And if you did build a model that could do that for Georgetown, I bet that it would be kind of one-off, it wouldn’t be very repeatable. You would need to do it again for other things.
Okay, different category: The level of adversarialness in a setting. So far, certainly it is getting somewhat harder to hack or jailbreak models, but it’s still pretty possible, especially if you dedicate time and effort to it. And there are big disparities between different industries, different use cases, for how much of a problem this is. E.g. if you’re a scientific team and you want to use AI to help with your research, it’s a fully cooperative setting—it’s just you, or just you and your grad students, and you can use AI, and no one is trying to get the AI to mess up. You’re just trying to get it to help you. That is very, very different from many industries. Certainly anything that is exposed to the open web, where different customers or hackers could come in and try and mess you up. Certainly very different from a set of use cases I spend a lot of time working on at CSET, military or national security use cases, where you have an actual adversary who is highly incentivized to mess you up. I think we’re seeing this already being a stumbling block for broad deployment of agents, the persistence of prompt injection attacks and other things. Again, remember I started by saying AI is getting better—I’m not saying this isn’t getting better. But there are big disparities in how easy it is to use AI systems between industries that are more tolerant to potential adversarial dynamics and industries that are less so.
And then a last source of jaggedness is cognitive versus physical. There’s been this slide over the past few years into defining AGI, instead of being something that can do everything a human can do, to being AI that can do just about all the cognitive tasks that a human can do. As a starting point, I just want to point out that is a huge difference. That is, already, if we’re just expecting AI to automate cognitive tasks, that is already a very, very jagged expectation, because there are huge differences between industries, tasks, roles that are very cognitive versus those that are physical.
I also think it’s interesting to zoom into the boundary between what counts as physical and what counts as cognitive. So for example, I think there are plenty of roles which are essentially cognitive and which you could basically do via Zoom, but you’re probably going to do them worse if you have no ability to do anything in person. So for example, if you’re an event planner, a lot of event planning you can do digitally. But I think there are things, like going in and walking a space, or having a relationship with certain vendors that you work with, that are going to be difficult to do if you’re just an AI model just interacting via computer interface. Not impossible, not that you could never get there, but it’s going to be different, it’s going to be harder. And that’s going to be a source of jaggedness.
Likewise in scientific research, zooming into this boundary between what’s cognitive and what’s physical: We’re already starting to see self-driving labs of some kinds, there are some types of research that are really amenable to the kinds of robotics we already have. So for example, certain types of material science research where you come up with an idea for a compound, you can produce it as a powder or liquid and mix it automatically, and then you can automatically look at what are the properties of that material—its transparency or its reactivity or its density or whatever it might be.
There are other kinds that are really not amenable to that. My husband is a chemist and he works in a lab, and the kind of research that he does involves a lot of tinkering. They have a machine shop, he’ll build a part, it’ll not quite work, he’ll have to figure out why it isn’t quite working, go and build a different part. The last time I went to visit his lab, he had a takeout container taped onto one of the things... Sometimes when people talk about what is a cognitive task, they’ll say “a task that you can do remotely,” and so then I imagine like, when he worked in Germany, he had this advisor in his lab, not the professor, but a senior scientist who was really experienced. And so that senior scientist could remotely be on a Zoom call with him or be on his phone, and my husband could in theory show him around the lab and show him the setup and describe to him all the experiments they were doing and get some advice. And that would, in theory, then match that “cognitive tasks” definition because it’s something you could do remotely. But I just... I have a hard time imagining an AI system, that doesn’t have all of the hands-on, interactive tinkering experience that that older German scientist with what, 40, 50 years of lab experience has, doing well. I think that’s going to be really hard. And so that, again, is a source of jaggedness.
A final point on this idea of cognitive tasks being anything you can do remotely: It feels to me like there’s a lot of interesting texture in human relationships here that hasn’t been explored. Yes, AI is very good at building relationships with individual people via text. But I think that’s pretty different from a lot of different ways that we have relationships with each other, even if we limit to the ways that relationships can be maintained/built/strengthened via something like Zoom. I think the time period between when we have AI that can build a one-on-one relationship with someone via text—which is now, or you know, a year or two ago—and the time period where we have an AI that can, in a video call, do as well as an experienced executive in managing a set of stakeholders, or building relationships with vendors over time, where over the long term, you’re building up a trusting relationship, you have that kind of one-on-one connection, or you have a Zoom room full of people with different interests and different hang-ups and different goals and you’re managing that in a real-time way. It feels to me like there’s a lot of things around how relationships factor into the work that we do that we’re not really quite thinking about with AI yet, and where “can you do it via Zoom” is not really the right question.
Again, to be clear: I’m not saying that this means that nothing interesting or concerning is going to happen. I’m also not saying that these categories I listed above are impossible for AI, or that we’ll never get there, or that the curve isn’t going up. I think for many of these probably the curve is going up. But the point is, I think we would do well to think more about the the order of these different things being developed, the speed, the time differences between them, and the differences in in how intensely we can utilize them.

So who cares if AI keeps being jagged? This is the most tentative part. I would be interested if you have other others ideas. I have a laundry list of of various thoughts as the last slide or second last slide of the talk.

Some tentative implications:
Search space of possible futures explodes: If you take this seriously, then the possible range of ways the next 5, 10, 20 years could go looks drastically wider. There are many, many different combinations of what could be developed, in what order, and how that will affect what is developed next. Coming from a policy background, the “transition turbulence” idea is relevant to me in part because the order in which things happen affects who is affected, who has power, who is disgruntled, who is provoked, who is trying to manage the situation, who is able to manage the situation. And I think that then affects how AI is further developed.
Need more arguments between AI believers and grizzled doing-stuff-is-hard veterans: I would love there to be more in-depth discussions between two camps. One camp is people who really get AI, who think about AI a lot, who understand all the ways that AI has been getting better and has been overcoming barriers and has been defying all expectations. That’s one group, and I think they know some true and important things. And then the other group—or maybe it’s a set of groups—is people who have experience doing hard, practical, real-world things. So this could include folks who have experience like building military tech, but it could also include people who have experience in developing new foods or in anything in the real world, doing hands-on science stuff, etc. I think often people in these groups have a view of, “Well, it’s actually really difficult; there’s a lot of details, there’s a lot of friction, there’s a lot of delay.” And in my experience, if you can get a good conversation going between the people who know the real, important, true things about why AI is going fast and can do a lot of things, and the people who know a lot of real, important, true things about why it’s hard to do stuff, there’s a lot of interesting back-and-forth you can get there.
Agile adoption will matter: I’m really not into this “drop-in remote worker” idea. At some point we might have something that is sort of that. But the question is, does that happen before everything else has already been radically transformed in other ways? I tend to think that there’s instead going to be a big premium for the companies and organizations that can figure out how to adopt AI. And that’s going to mean changing processes, doing things afresh. It’s going to advantage new entrants who don’t have a lot of institutional cruft. And that’s going to disrupt who is in power and therefore who is steering and who is making decisions.
[added] Relatedly, pushing AI-for-good forward will matter: I didn’t say this in the talk, but related to the previous point—jaggedness raises the stakes for anyone hoping to use good AI to counterbalance against bad AI, so to speak. Two major examples of this are using AI to automate alignment or other safety research, and using AI for societal resilience measures like biodefense or cyberdefense. If AI progress is not jagged, it might make sense to just hold off and wait for AI to get better before trying to push hard on these. If progress is jagged, then it’s important to push these forward as hard as we can now, in the hope that they end up being one of the more advanced pointy parts of the jagged frontier, not one of the lagging hollow parts.
Centaurs may persist: Another potential implication is that we may continue to see centaurs—human-AI combinations—being meaningful for quite a long time. The idea here is that in many ways, humans will be able to smooth out the rough edges where AI is not as good. So what does that mean? Maybe it means:
We should be thinking more about human-computer interaction dynamics, human factors, user experience, user interface. What does the trust between those parties look like? How do you maximize the benefit that you’re able to get from those AI systems by designing that human-AI system well? As opposed to just skipping to the end and assuming, well, at some point the AI is going to automate all of it, so who cares about the human-computer part.
AI advisors might matter a lot. This is maybe an especially tentative take. What I’m going for here is: I think we’re already in a world where maybe some of the people in this room... actually, put up your hand if you would say that you use AI to advise you on important things in your work or life. Yeah, wow, okay—basically everyone. Super interesting. I think this room probably more than most rooms, but I think we could be heading for a world where we don’t necessarily skip to the end and AI is automating everything; instead, humans are still in many positions of power, positions of influence, but they are increasingly collaborating with AI or getting advice from AI. Seems to me like there’s going to be a lot of interesting tricky dynamics around what does that look like, does that systematically change any of the ways that we’re making decisions or kinds of decisions we might make… I don’t know, seems interesting to me.
Centaurs continuing is probably a good sign for approaches related to AI control. These are approaches that assume that maybe we have very powerful AI systems that are not necessarily aligned, or not necessarily going to do what we want, but we can use other AI systems to constrain them, box them in, monitor them, and so on. So this might be a bullish sign for for those kind of approaches.
Timelines to
AGIcrazy: For a long time, I have not found a very helpful to talk about timelines to AGI, because I think people use just such different metrics and definitions for what they mean by that. I tend to think more in terms of how crazy are things going to get, how soon? And you can use different metrics for crazy, and I find that maybe a more productive and more interesting way to think about things.Bonus: Lastly, if this whole talk has not been for you and you’re still not convinced that jaggedness is going to persist, here’s a bonus suggestion: if you’re having conversations with people who are really not into the idea of AGI, who are really skeptical that that’s a thing, or you feel like you’re talking past each other, I suggest that instead of talking about AGI, try using this lens of, “Well, what if AI just keeps getting better?” I tend to find that that can get a little bit more engagement, a little bit more ability to think together, rather than getting fixated on this thing of skipping to a certain endpoint again.
Okay, I think that is all I have. I’m going to leave you with this, which is maybe my favorite slide I ever made. This whole talk is making me regret leaving chemical engineering because these simulations are so pretty. But that is all, I think we have some time for questions, thank you very much.

If you want to watch the 25 min of Q&A, here is a link to the relevant timestamp in the video. Many thanks to Rachel and team at the Golden Gate Institute for organizing such a great conference! Highly recommend Golden Gate’s Substack, Second Thoughts, for very thoughtful AI takes.
Thanks for making it to the end—if you enjoyed this, please subscribe: