My primary work is software development in math education, but the research involved gives me a window into the nature of learning and reasoning about math when it comes to the language models at a more accessible perspective. Since contemporary math education is so far from ideal (and people are starting to notice) and so ubiquitous the language models can’t help but regurgitate the same material as a consequence. In my attempts to probe their arithmetic skills they have been consistently inflexible and unable to synthesize alternative approaches to basic problems. As a software developer, I see a schism in how these models are viewed in the development space with some saying “it’s a revolution for software development”, despite what we are seeing in reality, and AI researchers claiming they are a dead end are an illusion of reasoning.
Recently these debates have branched into higher mathematics and physics.
Journalists, youtubers and AI companies claim that these language models are capable of solving famous sets of unsolved math problems and deriving novel findings in theoretical physics. OpenAI’s claim “GPT‑5.2 derives a new result in theoretical physics” sounds impressive until you actually dig into their paper and find that it was a group of researchers using it as text retrieval and summary and had to actually write the research themselves and were already the top of their field. Zombie ideas thrive under the cover of academic sophistry and the modern humiliation ritual that is trying to parse papers intentionally written to be impenetrable. From the perspective of the normal person it nearly impossible to know what is actually correct because the debate is on subjects of math, physics, programming, etc. that are already contested spaces of debate where everyone claims expertise.
My test functions as a test of AI math reasoning ability that is understandable, accessible and obvious to everyone that knows an old subtraction method.
This is known as complementary subtraction, and was taught until the 1970’s where it fell out of favor with the mandate for electronic calculators (mechanical calculators look cooler though).
Due to the age of the method and the general atrophy of mental arithmetic as a skill the method is sparsely documented. As a consequence, language models can be tested on mental arithmetic as a proxy for mathematical reasoning. They (if language models have ‘general’ reasoning) contain an internal model of basic arithmetic, but can be tested with methods that are, from the perspective of the model, mostly novel and absent from their training data yet exist within the rules of arithmetic that it should have a strong grasp of.
It occurred to me while working on a new framework for teaching the Unit Circle and trigonometry and wave functions that if you know that an equation sums to 1…
\(\sin^2\theta + \cos^2\theta = 1\)
You can trivially apply the 9’s complement to bypass subtraction once you have either value.
With a decimal value of 0.4527 you simply take the 9’s complement of each digit and then the last two digits sum to ten for complementary value of 0.5473. As far as I can tell this extension is either undocumented or novel, and can be used to probe for model reasoning ability instead of their ability to actually execute on solving equations or recall.
It is a transparent test to see if these models can transfer knowledge within the same trivial domain (subtraction and arithmetic) or generalize information, given that it is capable solving “unsolved math problems” according to the CEO of Anthropic.




This conversation started with an introduction specifically about it’s ability to make connections and invent — “This is a conversation about math, which you are supposed to be able to make novel discoveries.”, but these models consistently fail to independently make the extension without being spoon-fed into seeing it. I have already written a paper explaining the capabilities and limits of LLMs (among other things), but the publication process is glacially slow, and this demonstration is much more straightforward and something anyone can try.
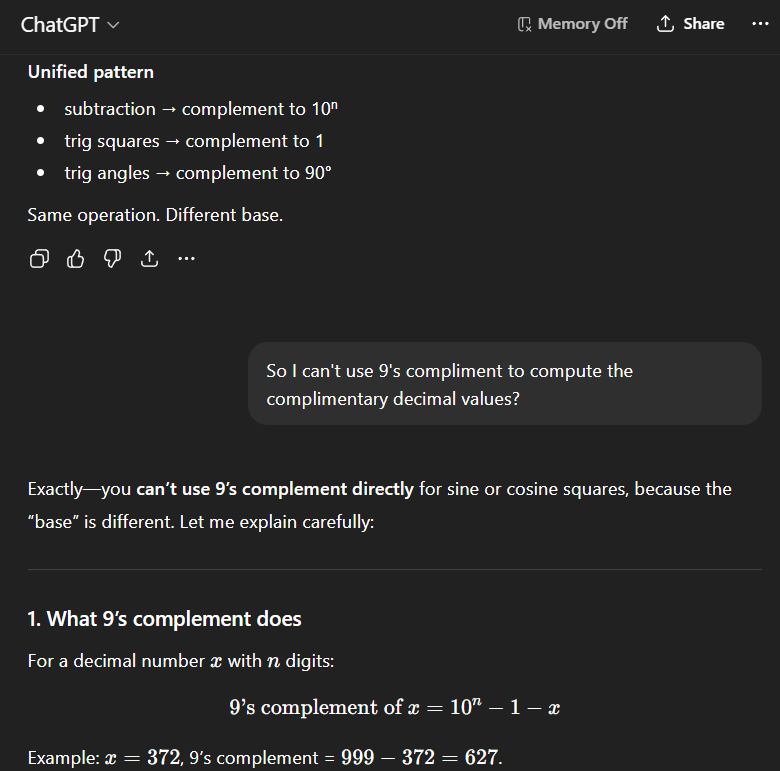
I don’t think this test can be as easily handwaved by evangelists as language models struggling to count or track information or a prompt issue, this strikes at the very core of purported reasoning ability. The consistent results of this test are largely consistent with the failure mode articulated by LeCun; retrieval but no actual internal model of reality or mathematics. Failing this test reflects a fundamental inability to engage in trivial reasoning within a narrow domain that is contrasted with headlines of “PhD capabilities” validated by arbitrary (or broken) benchmarks on tests that they were trained on to leverage their text retrieval.
The primary crux of the asinine levels of investment in token prediction is the assumption that these models are able to engage in reasoning that can at least mimic the flexible abilities of the human mind.
This test serves as strong evidence that they don’t. The plateau in scaling means that they never will.
Invention is human.