Comprehensive Compute Orchestration
Simply aggregate CPUs or GPUs for high performance, low latency, real-time applications.


Built by former forward deployed engineers, backed by top investors, and used by millions.

Universal Orchestration
Run workloads across your own infrastructure or Hathora's global fleet with seamless spillover, intelligent load balancing, and 99.9% uptime built in.

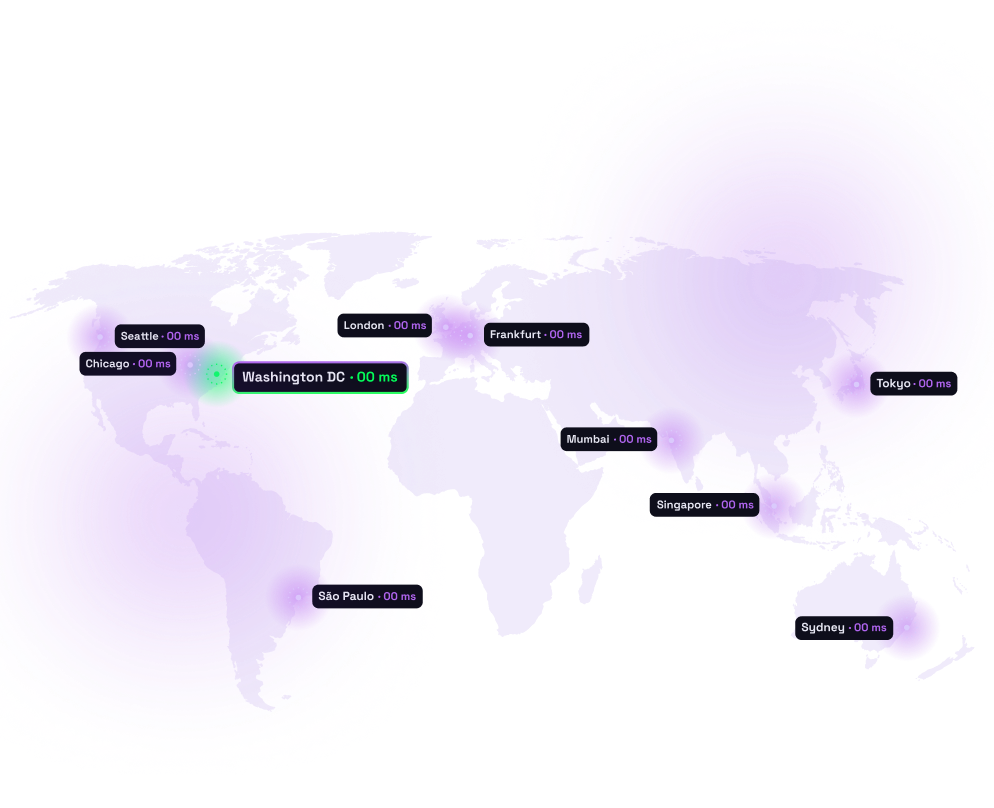
Edge Compute
Deploy compute at the edge to minimize round-trip latency and maximize real-time responsiveness. Automatically route workloads to the closest region for sub-50 ms performance worldwide.
Data Sovereignty
Maintain strict data locality with region-locked deployments that keep workloads and storage within jurisdictional boundaries. Simplify compliance and customer assurance across regions.

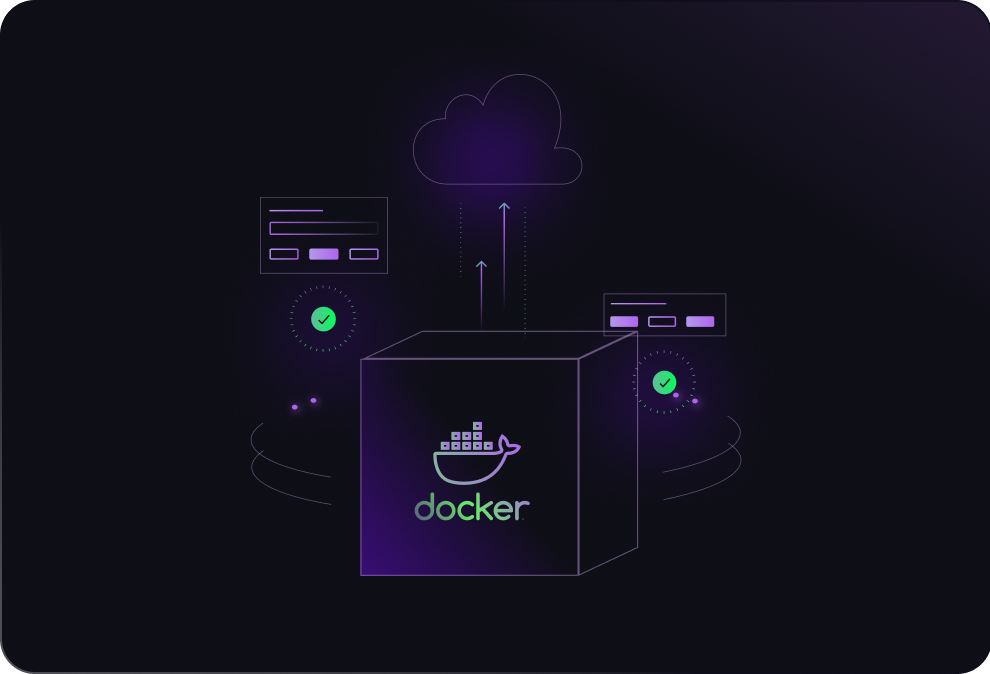
Container Native
Deploy any Docker-based workload with full orchestration, GPU scheduling, and autoscaling out of the box. If it runs in Docker, it runs on Hathora—no re-architecture required.
Universal Orchestration
Run workloads across your own infrastructure or Hathora's global fleet with seamless spillover, intelligent load balancing, and 99.9% uptime built in.
Edge Compute
Deploy compute at the edge to minimize round-trip latency and maximize real-time responsiveness. Automatically route workloads to the closest region for sub-50 ms performance worldwide.
Data Sovereignty
Maintain strict data locality with region-locked deployments that keep workloads and storage within jurisdictional boundaries. Simplify compliance and customer assurance across regions.
Container Native
Deploy any Docker-based workload with full orchestration, GPU scheduling, and autoscaling out of the box. If it runs in Docker, it runs on Hathora—no re-architecture required.
Use cases
![]()
Leverage Hathora's low-latency, low-cost compute platform with a token-in, token-out model and a unified API for deployment, scaling, and observability.
Read our docs
![]()
Leverage Hathora's low-latency, low-cost compute platform with a token-in, token-out model and a unified API for deployment, scaling, and observability.
Implementation & Support

Our team has spent years implementing software directly within customer accounts, and we leverage that expertise at scale for you.

Monitoring and alerting is in our DNA. You will have access to our team to ensure the best possible outcomes for your inference, game servers, and elastic metal implementation.
Unify Your Compute
Get started with unified infrastructure designed for real-time performance and cost savings.
Unify Your Compute
Get started with unified infrastructure designed for real-time performance and cost savings.
