As was mentioned earlier, block algorithm becomes more efficient as word size increases.
General purpose registers are only 64 bit long, so there is nothing more we can do about them.
On the other hand, x86_64 carries dedicated SIMD registers and instructions
with widths of 128, 256 and 512 bits depending on CPU generation.
For example, with 256 bit registers we could create efficient 32×32 transposer
by using log2(32)=5 levels of 2×2 block decomposition.
Alas, working with SIMD extensions is much more challenging than issuing + or >>.
A multitude of high-level instructions allows to do the same thing in different ways
and with different performance results.
Atop of that, availability of SIMD extensions heavily depends on CPU architecture and generation.
Here we will focus on relatively modern generations of x86_64 CPUs.
First let’s do short review of what SIMD extensions x64_64 CPUs offer. The very first widely used SIMD extension for x86 CPUs was MMX ("multimedia extensions"), now already forgotten. It introduced a set of new registers which could be treated as vectors of 8/16/32-bit integers and a dedicated instruction set that allowed to perform operations on the elements of these registers in parallel. As time passed, more and more extensions were added. Newly released extensions expanded register width, increased number of registers or introduced brand new instructions. Extensions below are grouped by target vector width and are listed in historical order:
I will assume that we have access to AVX2 but not the newer extensions. AVX2 gives us access to 256 bit registers and integer instructions. This means that we will be able to create efficient 32x32 transposer by using log2(32)=5 levels of block decomposition.
As before, we will work level by level, row by row.
Every row will be represented by a variable of __m256i type, which we will treat as a vector of type uint8_t[32].
This type is defined in immintrin.h header, shipped with all major compilers (intel, gcc, clang) which support AVX2.
Variable of this type can be naturally mapped to a 256-bit AVX register by the compiler in the same
way as uint64_t variable can be mapped to a general purpose 64-bit register.
The same header also provides the intrinsics to work with these registers.
Each intrinsic is mapped to respective CPU instruction, thus making it unnecessary to manually write assembler code.
In our code we will rely on only three instructions: _mm256_shuffle_epi8, _mm256_blendv_epi8, _mm256_permute2x128_si256.
In addition, two more instructions will be used implicitly: _mm256_load_si256 and _mm256_store_si256.
They move data between memory and 256-bit registers.
We do not need to call them manually since compilers can insert such instructions automatically
on encountering _mm256i r = *ptr; and *ptr = r; respectively.
Semantics of the other three instructions is more complicated and is provided below.
Shuffle. _mm256_shuffle_epi8 instruction accepts a source 256-bit register and a 256-bit control register, and, treating input as a vector of 8-bit values, shuffles them according to the control register, returning the result. Control register specifies for every index (0..31) of the output vector either the index of the source vector where to copy an element from, or carries a special value indicating that target location must be zeroed. Such semantics makes shuffle a very powerful instruction. If this instruction didn’t have any limitations, it would be possible to do any of the following with just single short-running instruction:
In contrast, coding the same operations with general purpose instructions would take a long sequence of mask,
shift and OR instructions.
Alas, _mm256_shuffle_epi8 has one limitation: elements may be shuffled only within every
left and right 128-bit lane but not across the lanes.
It is not possible, for example, to copy an element from src[30] (left lane) to dst[12] (right lane).
So, technically speaking, _mm256_shuffle_epi8 is a pair of independent general shuffle operations applied to left and right 128-bit lanes.
In our algorithm, we will use shuffle instruction in the first four stages (out of five) to reposition elements of the registers holding rows of the matrix from the previous stage. In the first level, we swap adjacent elements, in the second level — adjacent groups of two elements each, and so on. Diagram below demonstrates the application of the shuffle during the third stage, when we swap adjacent groups of four elements each.
Permute.
In the fifth stage of the algorithm we are transposing 2x2 block matrices where each block is 16x16,
effectively meaning that we have to swap lanes.
There is not way in AVX2 to perform general shuffle that requires to move data between lanes with a single instruction.
But since our case is very special one — just swap the lanes — we can do this with another instruction — _mm256_permute2x128_si256.
Given two input data registers a and b and a control register, this instruction allows to construct
a register where each of the two 128-bit lanes takes any of the four options:
a[0:127], a[128:255], b[0:127], b[128:255].
Setting control register to 0x01 makes permute instruction to return a with swapped lanes; b can be anything in our case.
Blend.
Blend
is another highly useful instruction.
It accepts two source registers and a mask, and constructs result where every i-th element
is selected from either src1[i] or src2[i] based on the mask.
In total, a combination of shuffle/permute and blend allows us to build a value consisting of almost
arbitrary selection of elements (remember cross-lane restriction) from two input registers, a and b,
in the following way:
Using this rule we are ready to build 32x32 transposer.
There will be log2(32)=5 levels.
Recall that at each level we build and intermediate matrix where each row is the result
of computations applied to two rows of the matrix from the previous level.
Every such computation can be expressed by the same sequence of operations.
The difference will be in which rows we take as input, which masks we apply, and
on the final level instead of shuffle we have to use permute.
Image below demonstrates how to compute the first two rows on the very first stage,
when we transpose each 2x2 matrix inside 32x32 matrix.
What originally was 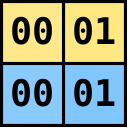 , now becomes
, now becomes 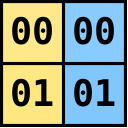 .
And what was
.
And what was  , now becomes
, now becomes  .
At the second stage the same sequence of operations applies, but now we work on pairs of elements.
At the fifth stage we are working on groups of 16 elements, and instead of shuffle we use permute.
.
At the second stage the same sequence of operations applies, but now we work on pairs of elements.
At the fifth stage we are working on groups of 16 elements, and instead of shuffle we use permute.
On the global scale full sequence of computations can be expressed with the following network.
Each vertex corresponds to a 256-bit value that holds entire row of 32 elements of some matrix,
additionally associated with the instruction that was used to compute this value.
Edges encode dependencies which must be computed before we can compute target value itself.
In the first column of vertices we load the rows of the src matrix.
Next five pairs of columns correspond to five stages of the algorithm.
First column in each pair is the result of shuffle (or permute), second column — blendv.
Thus, the values computed in the penultimate column contain the rows of the transposed matrix,
and the final column is dedicated to saving them into the memory that backs dst.
Top vertices standing apart from the remaining network correspond to the loading of 256-bit masks,
which we need to pass to shuffle and blendv.
These masks should be computed beforehand.
Writing code for such complex transposer is not a simple task. Manual coding in entirely unrolled format (as Vec64) is out of the question because it would require to write more than 400 lines of highly repetitive code. Using nested loops (level by level, block by block, row by row) is definitely possible and the transposer would be quite compact, but its performance would be at the mercy of the compiler. For example, its choice which loops to unroll and to what extent will have impact on how well execution units will be loaded. Third alternative is to use code generation with the help of some scripting language, and probably it is the cleanest way to create medium-sized kernels such as ours.
To make use of code generation, we need to explicitly instantiate the above network in terms of vertices and edges. With each vertex we associate a piece of code that consists of executing single vector instruction and writing the result into uniquely-named variable. Arguments of the instructions are the variables associated with the left-adjacent vertices.
One of the benefits of such approach is that it is possible to play with different orderings of the vertices. Any valid topological sorting will produce the same result but performance may vary. Computations may be performed column by column, in a n-ary tree manner, according to a randomly generated topological sorting, or in any other clever way you can think of. A priory it is hard to say which sorting will be better in terms of performance due to microarchitectural details. Still, some general rules can be applied. On the one hand, we would like to generate code that at any step keeps number of already computed and still required in the future values as few as possible. This is because compiler maps each variable to some register, and when it runs out of registers (for AVX2, there are only 16 of them), it has to perform a spill: a piece of code that saves value into stack and restores its back later when it is needed. Obviously, the fewer spills — the better. Another thing we need to consider is that invocations of the same instruction should be spread. Issuing 32 identical instructions one by one is not the best idea, since for each instruction type, there is only a few of the execution units which can handle it. If we issue many identical instructions one by one, other execution units will starve for work. Much better idea is to interleave instructions of different types, raising the chances that they will be executed in parallel.
Long story short, the solution which appears to work well empirically is to perform all computations level-by-level, similar to scalar vectorization. At every step two rows of the matrix from the previous level serve as input and four instructions are applied to them: two shuffles and two blends, thus producing two rows of the next-level matrix. This is repeated level by level, pair of rows by pair of rows. The order in which values are computed according to these rules is denoted by the numbers near the vertices in the network above.
Code-generated 32x32 transposer must be plugged into the overall algorithm, again with carefully
chosen strategy for preloading.
Since we employ code generation, the natural choice is to spread all 16 preload instructions
at equally-long chunks of the generated code.
Why 16?
Recall that we need 4 invocations of the 32x32 transposer to finish single 64x64 block.
Hence during each invocation we need to preload 16 rows of the next block.
There are 393 instructions in total, so we insert preload each 393/16=24 instructions into generated code.
In the code sample, three origin variables correspond to the offsets of the 32x32 submatrices
we are working on: source matrix, destination, and prefetch respectively.
stride values indicate the number of bytes that must be added to a corresponding
pointer to make it point to the same column of the next row.
For our current transposer both strides must be set to N.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
342
343
344
345
346
347
348
349
350
351
352
353
354
355
356
357
358
359
360
361
362
363
364
365
366
367
368
369
370
371
372
373
374
375
376
377
378
379
380
381
382
383
384
385
386
387
388
389
390
391
392
393
394
395
396
397
398
399
400
401
402
403
404
405
406
407
408
409
410
411
412
413
414
415
416
417
418
419
420
421
422
423
424
425
426
427
428
429
void transpose_Vec256_kernel(const uint8_t* src_origin, uint8_t* dst_origin,
const uint8_t* prf_origin,
int src_stride, int dst_stride) {
__m256i shm_1 = SHUFFLE_MASK[0];
__m256i blm_1 = BLENDV_MASK[0];
__m256i rnd_0_0 = *(const __m256i*)(src_origin + 0*src_stride);
__m256i rnd_0_1 = *(const __m256i*)(src_origin + 1*src_stride);
__m256i shf_1_0 = _mm256_shuffle_epi8(rnd_0_0, shm_1);
__m256i shf_1_1 = _mm256_shuffle_epi8(rnd_0_1, shm_1);
__m256i rnd_1_0 = _mm256_blendv_epi8(rnd_0_0, shf_1_1, blm_1);
__m256i rnd_1_1 = _mm256_blendv_epi8(shf_1_0, rnd_0_1, blm_1);
__m256i rnd_0_2 = *(const __m256i*)(src_origin + 2*src_stride);
__m256i rnd_0_3 = *(const __m256i*)(src_origin + 3*src_stride);
__m256i shf_1_2 = _mm256_shuffle_epi8(rnd_0_2, shm_1);
__m256i shf_1_3 = _mm256_shuffle_epi8(rnd_0_3, shm_1);
__m256i rnd_1_2 = _mm256_blendv_epi8(rnd_0_2, shf_1_3, blm_1);
__m256i rnd_1_3 = _mm256_blendv_epi8(shf_1_2, rnd_0_3, blm_1);
__m256i rnd_0_4 = *(const __m256i*)(src_origin + 4*src_stride);
__m256i rnd_0_5 = *(const __m256i*)(src_origin + 5*src_stride);
__m256i shf_1_4 = _mm256_shuffle_epi8(rnd_0_4, shm_1);
__m256i shf_1_5 = _mm256_shuffle_epi8(rnd_0_5, shm_1);
__m256i rnd_1_4 = _mm256_blendv_epi8(rnd_0_4, shf_1_5, blm_1);
__m256i rnd_1_5 = _mm256_blendv_epi8(shf_1_4, rnd_0_5, blm_1);
__m256i rnd_0_6 = *(const __m256i*)(src_origin + 6*src_stride);
__m256i rnd_0_7 = *(const __m256i*)(src_origin + 7*src_stride);
__m256i shf_1_6 = _mm256_shuffle_epi8(rnd_0_6, shm_1);
__m256i shf_1_7 = _mm256_shuffle_epi8(rnd_0_7, shm_1);
_mm_prefetch(prf_origin+0*src_stride, _MM_HINT_NTA);
__m256i rnd_1_6 = _mm256_blendv_epi8(rnd_0_6, shf_1_7, blm_1);
__m256i rnd_1_7 = _mm256_blendv_epi8(shf_1_6, rnd_0_7, blm_1);
__m256i rnd_0_8 = *(const __m256i*)(src_origin + 8*src_stride);
__m256i rnd_0_9 = *(const __m256i*)(src_origin + 9*src_stride);
__m256i shf_1_8 = _mm256_shuffle_epi8(rnd_0_8, shm_1);
__m256i shf_1_9 = _mm256_shuffle_epi8(rnd_0_9, shm_1);
__m256i rnd_1_8 = _mm256_blendv_epi8(rnd_0_8, shf_1_9, blm_1);
__m256i rnd_1_9 = _mm256_blendv_epi8(shf_1_8, rnd_0_9, blm_1);
__m256i rnd_0_10 = *(const __m256i*)(src_origin + 10*src_stride);
__m256i rnd_0_11 = *(const __m256i*)(src_origin + 11*src_stride);
__m256i shf_1_10 = _mm256_shuffle_epi8(rnd_0_10, shm_1);
__m256i shf_1_11 = _mm256_shuffle_epi8(rnd_0_11, shm_1);
__m256i rnd_1_10 = _mm256_blendv_epi8(rnd_0_10, shf_1_11, blm_1);
__m256i rnd_1_11 = _mm256_blendv_epi8(shf_1_10, rnd_0_11, blm_1);
__m256i rnd_0_12 = *(const __m256i*)(src_origin + 12*src_stride);
__m256i rnd_0_13 = *(const __m256i*)(src_origin + 13*src_stride);
__m256i shf_1_12 = _mm256_shuffle_epi8(rnd_0_12, shm_1);
__m256i shf_1_13 = _mm256_shuffle_epi8(rnd_0_13, shm_1);
__m256i rnd_1_12 = _mm256_blendv_epi8(rnd_0_12, shf_1_13, blm_1);
__m256i rnd_1_13 = _mm256_blendv_epi8(shf_1_12, rnd_0_13, blm_1);
__m256i rnd_0_14 = *(const __m256i*)(src_origin + 14*src_stride);
__m256i rnd_0_15 = *(const __m256i*)(src_origin + 15*src_stride);
__m256i shf_1_14 = _mm256_shuffle_epi8(rnd_0_14, shm_1);
__m256i shf_1_15 = _mm256_shuffle_epi8(rnd_0_15, shm_1);
_mm_prefetch(prf_origin+1*src_stride, _MM_HINT_NTA);
__m256i rnd_1_14 = _mm256_blendv_epi8(rnd_0_14, shf_1_15, blm_1);
__m256i rnd_1_15 = _mm256_blendv_epi8(shf_1_14, rnd_0_15, blm_1);
__m256i rnd_0_16 = *(const __m256i*)(src_origin + 16*src_stride);
__m256i rnd_0_17 = *(const __m256i*)(src_origin + 17*src_stride);
__m256i shf_1_16 = _mm256_shuffle_epi8(rnd_0_16, shm_1);
__m256i shf_1_17 = _mm256_shuffle_epi8(rnd_0_17, shm_1);
__m256i rnd_1_16 = _mm256_blendv_epi8(rnd_0_16, shf_1_17, blm_1);
__m256i rnd_1_17 = _mm256_blendv_epi8(shf_1_16, rnd_0_17, blm_1);
__m256i rnd_0_18 = *(const __m256i*)(src_origin + 18*src_stride);
__m256i rnd_0_19 = *(const __m256i*)(src_origin + 19*src_stride);
__m256i shf_1_18 = _mm256_shuffle_epi8(rnd_0_18, shm_1);
__m256i shf_1_19 = _mm256_shuffle_epi8(rnd_0_19, shm_1);
__m256i rnd_1_18 = _mm256_blendv_epi8(rnd_0_18, shf_1_19, blm_1);
__m256i rnd_1_19 = _mm256_blendv_epi8(shf_1_18, rnd_0_19, blm_1);
__m256i rnd_0_20 = *(const __m256i*)(src_origin + 20*src_stride);
__m256i rnd_0_21 = *(const __m256i*)(src_origin + 21*src_stride);
__m256i shf_1_20 = _mm256_shuffle_epi8(rnd_0_20, shm_1);
__m256i shf_1_21 = _mm256_shuffle_epi8(rnd_0_21, shm_1);
__m256i rnd_1_20 = _mm256_blendv_epi8(rnd_0_20, shf_1_21, blm_1);
__m256i rnd_1_21 = _mm256_blendv_epi8(shf_1_20, rnd_0_21, blm_1);
__m256i rnd_0_22 = *(const __m256i*)(src_origin + 22*src_stride);
__m256i rnd_0_23 = *(const __m256i*)(src_origin + 23*src_stride);
__m256i shf_1_22 = _mm256_shuffle_epi8(rnd_0_22, shm_1);
__m256i shf_1_23 = _mm256_shuffle_epi8(rnd_0_23, shm_1);
_mm_prefetch(prf_origin+2*src_stride, _MM_HINT_NTA);
__m256i rnd_1_22 = _mm256_blendv_epi8(rnd_0_22, shf_1_23, blm_1);
__m256i rnd_1_23 = _mm256_blendv_epi8(shf_1_22, rnd_0_23, blm_1);
__m256i rnd_0_24 = *(const __m256i*)(src_origin + 24*src_stride);
__m256i rnd_0_25 = *(const __m256i*)(src_origin + 25*src_stride);
__m256i shf_1_24 = _mm256_shuffle_epi8(rnd_0_24, shm_1);
__m256i shf_1_25 = _mm256_shuffle_epi8(rnd_0_25, shm_1);
__m256i rnd_1_24 = _mm256_blendv_epi8(rnd_0_24, shf_1_25, blm_1);
__m256i rnd_1_25 = _mm256_blendv_epi8(shf_1_24, rnd_0_25, blm_1);
__m256i rnd_0_26 = *(const __m256i*)(src_origin + 26*src_stride);
__m256i rnd_0_27 = *(const __m256i*)(src_origin + 27*src_stride);
__m256i shf_1_26 = _mm256_shuffle_epi8(rnd_0_26, shm_1);
__m256i shf_1_27 = _mm256_shuffle_epi8(rnd_0_27, shm_1);
__m256i rnd_1_26 = _mm256_blendv_epi8(rnd_0_26, shf_1_27, blm_1);
__m256i rnd_1_27 = _mm256_blendv_epi8(shf_1_26, rnd_0_27, blm_1);
__m256i rnd_0_28 = *(const __m256i*)(src_origin + 28*src_stride);
__m256i rnd_0_29 = *(const __m256i*)(src_origin + 29*src_stride);
__m256i shf_1_28 = _mm256_shuffle_epi8(rnd_0_28, shm_1);
__m256i shf_1_29 = _mm256_shuffle_epi8(rnd_0_29, shm_1);
__m256i rnd_1_28 = _mm256_blendv_epi8(rnd_0_28, shf_1_29, blm_1);
__m256i rnd_1_29 = _mm256_blendv_epi8(shf_1_28, rnd_0_29, blm_1);
__m256i rnd_0_30 = *(const __m256i*)(src_origin + 30*src_stride);
__m256i rnd_0_31 = *(const __m256i*)(src_origin + 31*src_stride);
__m256i shf_1_30 = _mm256_shuffle_epi8(rnd_0_30, shm_1);
__m256i shf_1_31 = _mm256_shuffle_epi8(rnd_0_31, shm_1);
_mm_prefetch(prf_origin+3*src_stride, _MM_HINT_NTA);
__m256i rnd_1_30 = _mm256_blendv_epi8(rnd_0_30, shf_1_31, blm_1);
__m256i rnd_1_31 = _mm256_blendv_epi8(shf_1_30, rnd_0_31, blm_1);
__m256i shm_2 = SHUFFLE_MASK[1];
__m256i blm_2 = BLENDV_MASK[1];
__m256i shf_2_0 = _mm256_shuffle_epi8(rnd_1_0, shm_2);
__m256i shf_2_2 = _mm256_shuffle_epi8(rnd_1_2, shm_2);
__m256i rnd_2_0 = _mm256_blendv_epi8(rnd_1_0, shf_2_2, blm_2);
__m256i rnd_2_2 = _mm256_blendv_epi8(shf_2_0, rnd_1_2, blm_2);
__m256i shf_2_1 = _mm256_shuffle_epi8(rnd_1_1, shm_2);
__m256i shf_2_3 = _mm256_shuffle_epi8(rnd_1_3, shm_2);
__m256i rnd_2_1 = _mm256_blendv_epi8(rnd_1_1, shf_2_3, blm_2);
__m256i rnd_2_3 = _mm256_blendv_epi8(shf_2_1, rnd_1_3, blm_2);
__m256i shf_2_4 = _mm256_shuffle_epi8(rnd_1_4, shm_2);
__m256i shf_2_6 = _mm256_shuffle_epi8(rnd_1_6, shm_2);
__m256i rnd_2_4 = _mm256_blendv_epi8(rnd_1_4, shf_2_6, blm_2);
__m256i rnd_2_6 = _mm256_blendv_epi8(shf_2_4, rnd_1_6, blm_2);
__m256i shf_2_5 = _mm256_shuffle_epi8(rnd_1_5, shm_2);
__m256i shf_2_7 = _mm256_shuffle_epi8(rnd_1_7, shm_2);
__m256i rnd_2_5 = _mm256_blendv_epi8(rnd_1_5, shf_2_7, blm_2);
__m256i rnd_2_7 = _mm256_blendv_epi8(shf_2_5, rnd_1_7, blm_2);
__m256i shf_2_8 = _mm256_shuffle_epi8(rnd_1_8, shm_2);
__m256i shf_2_10 = _mm256_shuffle_epi8(rnd_1_10, shm_2);
__m256i rnd_2_8 = _mm256_blendv_epi8(rnd_1_8, shf_2_10, blm_2);
__m256i rnd_2_10 = _mm256_blendv_epi8(shf_2_8, rnd_1_10, blm_2);
_mm_prefetch(prf_origin+4*src_stride, _MM_HINT_NTA);
__m256i shf_2_9 = _mm256_shuffle_epi8(rnd_1_9, shm_2);
__m256i shf_2_11 = _mm256_shuffle_epi8(rnd_1_11, shm_2);
__m256i rnd_2_9 = _mm256_blendv_epi8(rnd_1_9, shf_2_11, blm_2);
__m256i rnd_2_11 = _mm256_blendv_epi8(shf_2_9, rnd_1_11, blm_2);
__m256i shf_2_12 = _mm256_shuffle_epi8(rnd_1_12, shm_2);
__m256i shf_2_14 = _mm256_shuffle_epi8(rnd_1_14, shm_2);
__m256i rnd_2_12 = _mm256_blendv_epi8(rnd_1_12, shf_2_14, blm_2);
__m256i rnd_2_14 = _mm256_blendv_epi8(shf_2_12, rnd_1_14, blm_2);
__m256i shf_2_13 = _mm256_shuffle_epi8(rnd_1_13, shm_2);
__m256i shf_2_15 = _mm256_shuffle_epi8(rnd_1_15, shm_2);
__m256i rnd_2_13 = _mm256_blendv_epi8(rnd_1_13, shf_2_15, blm_2);
__m256i rnd_2_15 = _mm256_blendv_epi8(shf_2_13, rnd_1_15, blm_2);
__m256i shf_2_16 = _mm256_shuffle_epi8(rnd_1_16, shm_2);
__m256i shf_2_18 = _mm256_shuffle_epi8(rnd_1_18, shm_2);
__m256i rnd_2_16 = _mm256_blendv_epi8(rnd_1_16, shf_2_18, blm_2);
__m256i rnd_2_18 = _mm256_blendv_epi8(shf_2_16, rnd_1_18, blm_2);
__m256i shf_2_17 = _mm256_shuffle_epi8(rnd_1_17, shm_2);
__m256i shf_2_19 = _mm256_shuffle_epi8(rnd_1_19, shm_2);
__m256i rnd_2_17 = _mm256_blendv_epi8(rnd_1_17, shf_2_19, blm_2);
__m256i rnd_2_19 = _mm256_blendv_epi8(shf_2_17, rnd_1_19, blm_2);
__m256i shf_2_20 = _mm256_shuffle_epi8(rnd_1_20, shm_2);
__m256i shf_2_22 = _mm256_shuffle_epi8(rnd_1_22, shm_2);
__m256i rnd_2_20 = _mm256_blendv_epi8(rnd_1_20, shf_2_22, blm_2);
__m256i rnd_2_22 = _mm256_blendv_epi8(shf_2_20, rnd_1_22, blm_2);
_mm_prefetch(prf_origin+5*src_stride, _MM_HINT_NTA);
__m256i shf_2_21 = _mm256_shuffle_epi8(rnd_1_21, shm_2);
__m256i shf_2_23 = _mm256_shuffle_epi8(rnd_1_23, shm_2);
__m256i rnd_2_21 = _mm256_blendv_epi8(rnd_1_21, shf_2_23, blm_2);
__m256i rnd_2_23 = _mm256_blendv_epi8(shf_2_21, rnd_1_23, blm_2);
__m256i shf_2_24 = _mm256_shuffle_epi8(rnd_1_24, shm_2);
__m256i shf_2_26 = _mm256_shuffle_epi8(rnd_1_26, shm_2);
__m256i rnd_2_24 = _mm256_blendv_epi8(rnd_1_24, shf_2_26, blm_2);
__m256i rnd_2_26 = _mm256_blendv_epi8(shf_2_24, rnd_1_26, blm_2);
__m256i shf_2_25 = _mm256_shuffle_epi8(rnd_1_25, shm_2);
__m256i shf_2_27 = _mm256_shuffle_epi8(rnd_1_27, shm_2);
__m256i rnd_2_25 = _mm256_blendv_epi8(rnd_1_25, shf_2_27, blm_2);
__m256i rnd_2_27 = _mm256_blendv_epi8(shf_2_25, rnd_1_27, blm_2);
__m256i shf_2_28 = _mm256_shuffle_epi8(rnd_1_28, shm_2);
__m256i shf_2_30 = _mm256_shuffle_epi8(rnd_1_30, shm_2);
__m256i rnd_2_28 = _mm256_blendv_epi8(rnd_1_28, shf_2_30, blm_2);
__m256i rnd_2_30 = _mm256_blendv_epi8(shf_2_28, rnd_1_30, blm_2);
__m256i shf_2_29 = _mm256_shuffle_epi8(rnd_1_29, shm_2);
__m256i shf_2_31 = _mm256_shuffle_epi8(rnd_1_31, shm_2);
__m256i rnd_2_29 = _mm256_blendv_epi8(rnd_1_29, shf_2_31, blm_2);
__m256i rnd_2_31 = _mm256_blendv_epi8(shf_2_29, rnd_1_31, blm_2);
__m256i shm_3 = SHUFFLE_MASK[2];
__m256i blm_3 = BLENDV_MASK[2];
__m256i shf_3_0 = _mm256_shuffle_epi8(rnd_2_0, shm_3);
__m256i shf_3_4 = _mm256_shuffle_epi8(rnd_2_4, shm_3);
_mm_prefetch(prf_origin+6*src_stride, _MM_HINT_NTA);
__m256i rnd_3_0 = _mm256_blendv_epi8(rnd_2_0, shf_3_4, blm_3);
__m256i rnd_3_4 = _mm256_blendv_epi8(shf_3_0, rnd_2_4, blm_3);
__m256i shf_3_1 = _mm256_shuffle_epi8(rnd_2_1, shm_3);
__m256i shf_3_5 = _mm256_shuffle_epi8(rnd_2_5, shm_3);
__m256i rnd_3_1 = _mm256_blendv_epi8(rnd_2_1, shf_3_5, blm_3);
__m256i rnd_3_5 = _mm256_blendv_epi8(shf_3_1, rnd_2_5, blm_3);
__m256i shf_3_2 = _mm256_shuffle_epi8(rnd_2_2, shm_3);
__m256i shf_3_6 = _mm256_shuffle_epi8(rnd_2_6, shm_3);
__m256i rnd_3_2 = _mm256_blendv_epi8(rnd_2_2, shf_3_6, blm_3);
__m256i rnd_3_6 = _mm256_blendv_epi8(shf_3_2, rnd_2_6, blm_3);
__m256i shf_3_3 = _mm256_shuffle_epi8(rnd_2_3, shm_3);
__m256i shf_3_7 = _mm256_shuffle_epi8(rnd_2_7, shm_3);
__m256i rnd_3_3 = _mm256_blendv_epi8(rnd_2_3, shf_3_7, blm_3);
__m256i rnd_3_7 = _mm256_blendv_epi8(shf_3_3, rnd_2_7, blm_3);
__m256i shf_3_8 = _mm256_shuffle_epi8(rnd_2_8, shm_3);
__m256i shf_3_12 = _mm256_shuffle_epi8(rnd_2_12, shm_3);
__m256i rnd_3_8 = _mm256_blendv_epi8(rnd_2_8, shf_3_12, blm_3);
__m256i rnd_3_12 = _mm256_blendv_epi8(shf_3_8, rnd_2_12, blm_3);
__m256i shf_3_9 = _mm256_shuffle_epi8(rnd_2_9, shm_3);
__m256i shf_3_13 = _mm256_shuffle_epi8(rnd_2_13, shm_3);
__m256i rnd_3_9 = _mm256_blendv_epi8(rnd_2_9, shf_3_13, blm_3);
__m256i rnd_3_13 = _mm256_blendv_epi8(shf_3_9, rnd_2_13, blm_3);
__m256i shf_3_10 = _mm256_shuffle_epi8(rnd_2_10, shm_3);
__m256i shf_3_14 = _mm256_shuffle_epi8(rnd_2_14, shm_3);
_mm_prefetch(prf_origin+7*src_stride, _MM_HINT_NTA);
__m256i rnd_3_10 = _mm256_blendv_epi8(rnd_2_10, shf_3_14, blm_3);
__m256i rnd_3_14 = _mm256_blendv_epi8(shf_3_10, rnd_2_14, blm_3);
__m256i shf_3_11 = _mm256_shuffle_epi8(rnd_2_11, shm_3);
__m256i shf_3_15 = _mm256_shuffle_epi8(rnd_2_15, shm_3);
__m256i rnd_3_11 = _mm256_blendv_epi8(rnd_2_11, shf_3_15, blm_3);
__m256i rnd_3_15 = _mm256_blendv_epi8(shf_3_11, rnd_2_15, blm_3);
__m256i shf_3_16 = _mm256_shuffle_epi8(rnd_2_16, shm_3);
__m256i shf_3_20 = _mm256_shuffle_epi8(rnd_2_20, shm_3);
__m256i rnd_3_16 = _mm256_blendv_epi8(rnd_2_16, shf_3_20, blm_3);
__m256i rnd_3_20 = _mm256_blendv_epi8(shf_3_16, rnd_2_20, blm_3);
__m256i shf_3_17 = _mm256_shuffle_epi8(rnd_2_17, shm_3);
__m256i shf_3_21 = _mm256_shuffle_epi8(rnd_2_21, shm_3);
__m256i rnd_3_17 = _mm256_blendv_epi8(rnd_2_17, shf_3_21, blm_3);
__m256i rnd_3_21 = _mm256_blendv_epi8(shf_3_17, rnd_2_21, blm_3);
__m256i shf_3_18 = _mm256_shuffle_epi8(rnd_2_18, shm_3);
__m256i shf_3_22 = _mm256_shuffle_epi8(rnd_2_22, shm_3);
__m256i rnd_3_18 = _mm256_blendv_epi8(rnd_2_18, shf_3_22, blm_3);
__m256i rnd_3_22 = _mm256_blendv_epi8(shf_3_18, rnd_2_22, blm_3);
__m256i shf_3_19 = _mm256_shuffle_epi8(rnd_2_19, shm_3);
__m256i shf_3_23 = _mm256_shuffle_epi8(rnd_2_23, shm_3);
__m256i rnd_3_19 = _mm256_blendv_epi8(rnd_2_19, shf_3_23, blm_3);
__m256i rnd_3_23 = _mm256_blendv_epi8(shf_3_19, rnd_2_23, blm_3);
__m256i shf_3_24 = _mm256_shuffle_epi8(rnd_2_24, shm_3);
__m256i shf_3_28 = _mm256_shuffle_epi8(rnd_2_28, shm_3);
_mm_prefetch(prf_origin+8*src_stride, _MM_HINT_NTA);
__m256i rnd_3_24 = _mm256_blendv_epi8(rnd_2_24, shf_3_28, blm_3);
__m256i rnd_3_28 = _mm256_blendv_epi8(shf_3_24, rnd_2_28, blm_3);
__m256i shf_3_25 = _mm256_shuffle_epi8(rnd_2_25, shm_3);
__m256i shf_3_29 = _mm256_shuffle_epi8(rnd_2_29, shm_3);
__m256i rnd_3_25 = _mm256_blendv_epi8(rnd_2_25, shf_3_29, blm_3);
__m256i rnd_3_29 = _mm256_blendv_epi8(shf_3_25, rnd_2_29, blm_3);
__m256i shf_3_26 = _mm256_shuffle_epi8(rnd_2_26, shm_3);
__m256i shf_3_30 = _mm256_shuffle_epi8(rnd_2_30, shm_3);
__m256i rnd_3_26 = _mm256_blendv_epi8(rnd_2_26, shf_3_30, blm_3);
__m256i rnd_3_30 = _mm256_blendv_epi8(shf_3_26, rnd_2_30, blm_3);
__m256i shf_3_27 = _mm256_shuffle_epi8(rnd_2_27, shm_3);
__m256i shf_3_31 = _mm256_shuffle_epi8(rnd_2_31, shm_3);
__m256i rnd_3_27 = _mm256_blendv_epi8(rnd_2_27, shf_3_31, blm_3);
__m256i rnd_3_31 = _mm256_blendv_epi8(shf_3_27, rnd_2_31, blm_3);
__m256i shm_4 = SHUFFLE_MASK[3];
__m256i blm_4 = BLENDV_MASK[3];
__m256i shf_4_0 = _mm256_shuffle_epi8(rnd_3_0, shm_4);
__m256i shf_4_8 = _mm256_shuffle_epi8(rnd_3_8, shm_4);
__m256i rnd_4_0 = _mm256_blendv_epi8(rnd_3_0, shf_4_8, blm_4);
__m256i rnd_4_8 = _mm256_blendv_epi8(shf_4_0, rnd_3_8, blm_4);
__m256i shf_4_1 = _mm256_shuffle_epi8(rnd_3_1, shm_4);
__m256i shf_4_9 = _mm256_shuffle_epi8(rnd_3_9, shm_4);
__m256i rnd_4_1 = _mm256_blendv_epi8(rnd_3_1, shf_4_9, blm_4);
__m256i rnd_4_9 = _mm256_blendv_epi8(shf_4_1, rnd_3_9, blm_4);
_mm_prefetch(prf_origin+9*src_stride, _MM_HINT_NTA);
__m256i shf_4_2 = _mm256_shuffle_epi8(rnd_3_2, shm_4);
__m256i shf_4_10 = _mm256_shuffle_epi8(rnd_3_10, shm_4);
__m256i rnd_4_2 = _mm256_blendv_epi8(rnd_3_2, shf_4_10, blm_4);
__m256i rnd_4_10 = _mm256_blendv_epi8(shf_4_2, rnd_3_10, blm_4);
__m256i shf_4_3 = _mm256_shuffle_epi8(rnd_3_3, shm_4);
__m256i shf_4_11 = _mm256_shuffle_epi8(rnd_3_11, shm_4);
__m256i rnd_4_3 = _mm256_blendv_epi8(rnd_3_3, shf_4_11, blm_4);
__m256i rnd_4_11 = _mm256_blendv_epi8(shf_4_3, rnd_3_11, blm_4);
__m256i shf_4_4 = _mm256_shuffle_epi8(rnd_3_4, shm_4);
__m256i shf_4_12 = _mm256_shuffle_epi8(rnd_3_12, shm_4);
__m256i rnd_4_4 = _mm256_blendv_epi8(rnd_3_4, shf_4_12, blm_4);
__m256i rnd_4_12 = _mm256_blendv_epi8(shf_4_4, rnd_3_12, blm_4);
__m256i shf_4_5 = _mm256_shuffle_epi8(rnd_3_5, shm_4);
__m256i shf_4_13 = _mm256_shuffle_epi8(rnd_3_13, shm_4);
__m256i rnd_4_5 = _mm256_blendv_epi8(rnd_3_5, shf_4_13, blm_4);
__m256i rnd_4_13 = _mm256_blendv_epi8(shf_4_5, rnd_3_13, blm_4);
__m256i shf_4_6 = _mm256_shuffle_epi8(rnd_3_6, shm_4);
__m256i shf_4_14 = _mm256_shuffle_epi8(rnd_3_14, shm_4);
__m256i rnd_4_6 = _mm256_blendv_epi8(rnd_3_6, shf_4_14, blm_4);
__m256i rnd_4_14 = _mm256_blendv_epi8(shf_4_6, rnd_3_14, blm_4);
__m256i shf_4_7 = _mm256_shuffle_epi8(rnd_3_7, shm_4);
__m256i shf_4_15 = _mm256_shuffle_epi8(rnd_3_15, shm_4);
__m256i rnd_4_7 = _mm256_blendv_epi8(rnd_3_7, shf_4_15, blm_4);
__m256i rnd_4_15 = _mm256_blendv_epi8(shf_4_7, rnd_3_15, blm_4);
_mm_prefetch(prf_origin+10*src_stride, _MM_HINT_NTA);
__m256i shf_4_16 = _mm256_shuffle_epi8(rnd_3_16, shm_4);
__m256i shf_4_24 = _mm256_shuffle_epi8(rnd_3_24, shm_4);
__m256i rnd_4_16 = _mm256_blendv_epi8(rnd_3_16, shf_4_24, blm_4);
__m256i rnd_4_24 = _mm256_blendv_epi8(shf_4_16, rnd_3_24, blm_4);
__m256i shf_4_17 = _mm256_shuffle_epi8(rnd_3_17, shm_4);
__m256i shf_4_25 = _mm256_shuffle_epi8(rnd_3_25, shm_4);
__m256i rnd_4_17 = _mm256_blendv_epi8(rnd_3_17, shf_4_25, blm_4);
__m256i rnd_4_25 = _mm256_blendv_epi8(shf_4_17, rnd_3_25, blm_4);
__m256i shf_4_18 = _mm256_shuffle_epi8(rnd_3_18, shm_4);
__m256i shf_4_26 = _mm256_shuffle_epi8(rnd_3_26, shm_4);
__m256i rnd_4_18 = _mm256_blendv_epi8(rnd_3_18, shf_4_26, blm_4);
__m256i rnd_4_26 = _mm256_blendv_epi8(shf_4_18, rnd_3_26, blm_4);
__m256i shf_4_19 = _mm256_shuffle_epi8(rnd_3_19, shm_4);
__m256i shf_4_27 = _mm256_shuffle_epi8(rnd_3_27, shm_4);
__m256i rnd_4_19 = _mm256_blendv_epi8(rnd_3_19, shf_4_27, blm_4);
__m256i rnd_4_27 = _mm256_blendv_epi8(shf_4_19, rnd_3_27, blm_4);
__m256i shf_4_20 = _mm256_shuffle_epi8(rnd_3_20, shm_4);
__m256i shf_4_28 = _mm256_shuffle_epi8(rnd_3_28, shm_4);
__m256i rnd_4_20 = _mm256_blendv_epi8(rnd_3_20, shf_4_28, blm_4);
__m256i rnd_4_28 = _mm256_blendv_epi8(shf_4_20, rnd_3_28, blm_4);
__m256i shf_4_21 = _mm256_shuffle_epi8(rnd_3_21, shm_4);
__m256i shf_4_29 = _mm256_shuffle_epi8(rnd_3_29, shm_4);
__m256i rnd_4_21 = _mm256_blendv_epi8(rnd_3_21, shf_4_29, blm_4);
__m256i rnd_4_29 = _mm256_blendv_epi8(shf_4_21, rnd_3_29, blm_4);
_mm_prefetch(prf_origin+11*src_stride, _MM_HINT_NTA);
__m256i shf_4_22 = _mm256_shuffle_epi8(rnd_3_22, shm_4);
__m256i shf_4_30 = _mm256_shuffle_epi8(rnd_3_30, shm_4);
__m256i rnd_4_22 = _mm256_blendv_epi8(rnd_3_22, shf_4_30, blm_4);
__m256i rnd_4_30 = _mm256_blendv_epi8(shf_4_22, rnd_3_30, blm_4);
__m256i shf_4_23 = _mm256_shuffle_epi8(rnd_3_23, shm_4);
__m256i shf_4_31 = _mm256_shuffle_epi8(rnd_3_31, shm_4);
__m256i rnd_4_23 = _mm256_blendv_epi8(rnd_3_23, shf_4_31, blm_4);
__m256i rnd_4_31 = _mm256_blendv_epi8(shf_4_23, rnd_3_31, blm_4);
__m256i blm_5 = BLENDV_MASK[4];
__m256i shf_5_0 = _mm256_permute2x128_si256(rnd_4_0, rnd_4_0, 0x01);
__m256i shf_5_16 = _mm256_permute2x128_si256(rnd_4_16, rnd_4_16, 0x01);
__m256i rnd_5_0 = _mm256_blendv_epi8(rnd_4_0, shf_5_16, blm_5);
__m256i rnd_5_16 = _mm256_blendv_epi8(shf_5_0, rnd_4_16, blm_5);
*(__m256i*)(dst_origin + 0*dst_stride) = rnd_5_0;
*(__m256i*)(dst_origin + 16*dst_stride) = rnd_5_16;
__m256i shf_5_1 = _mm256_permute2x128_si256(rnd_4_1, rnd_4_1, 0x01);
__m256i shf_5_17 = _mm256_permute2x128_si256(rnd_4_17, rnd_4_17, 0x01);
__m256i rnd_5_1 = _mm256_blendv_epi8(rnd_4_1, shf_5_17, blm_5);
__m256i rnd_5_17 = _mm256_blendv_epi8(shf_5_1, rnd_4_17, blm_5);
*(__m256i*)(dst_origin + 1*dst_stride) = rnd_5_1;
*(__m256i*)(dst_origin + 17*dst_stride) = rnd_5_17;
__m256i shf_5_2 = _mm256_permute2x128_si256(rnd_4_2, rnd_4_2, 0x01);
__m256i shf_5_18 = _mm256_permute2x128_si256(rnd_4_18, rnd_4_18, 0x01);
__m256i rnd_5_2 = _mm256_blendv_epi8(rnd_4_2, shf_5_18, blm_5);
_mm_prefetch(prf_origin+12*src_stride, _MM_HINT_NTA);
__m256i rnd_5_18 = _mm256_blendv_epi8(shf_5_2, rnd_4_18, blm_5);
*(__m256i*)(dst_origin + 2*dst_stride) = rnd_5_2;
*(__m256i*)(dst_origin + 18*dst_stride) = rnd_5_18;
__m256i shf_5_3 = _mm256_permute2x128_si256(rnd_4_3, rnd_4_3, 0x01);
__m256i shf_5_19 = _mm256_permute2x128_si256(rnd_4_19, rnd_4_19, 0x01);
__m256i rnd_5_3 = _mm256_blendv_epi8(rnd_4_3, shf_5_19, blm_5);
__m256i rnd_5_19 = _mm256_blendv_epi8(shf_5_3, rnd_4_19, blm_5);
*(__m256i*)(dst_origin + 3*dst_stride) = rnd_5_3;
*(__m256i*)(dst_origin + 19*dst_stride) = rnd_5_19;
__m256i shf_5_4 = _mm256_permute2x128_si256(rnd_4_4, rnd_4_4, 0x01);
__m256i shf_5_20 = _mm256_permute2x128_si256(rnd_4_20, rnd_4_20, 0x01);
__m256i rnd_5_4 = _mm256_blendv_epi8(rnd_4_4, shf_5_20, blm_5);
__m256i rnd_5_20 = _mm256_blendv_epi8(shf_5_4, rnd_4_20, blm_5);
*(__m256i*)(dst_origin + 4*dst_stride) = rnd_5_4;
*(__m256i*)(dst_origin + 20*dst_stride) = rnd_5_20;
__m256i shf_5_5 = _mm256_permute2x128_si256(rnd_4_5, rnd_4_5, 0x01);
__m256i shf_5_21 = _mm256_permute2x128_si256(rnd_4_21, rnd_4_21, 0x01);
__m256i rnd_5_5 = _mm256_blendv_epi8(rnd_4_5, shf_5_21, blm_5);
__m256i rnd_5_21 = _mm256_blendv_epi8(shf_5_5, rnd_4_21, blm_5);
*(__m256i*)(dst_origin + 5*dst_stride) = rnd_5_5;
*(__m256i*)(dst_origin + 21*dst_stride) = rnd_5_21;
__m256i shf_5_6 = _mm256_permute2x128_si256(rnd_4_6, rnd_4_6, 0x01);
__m256i shf_5_22 = _mm256_permute2x128_si256(rnd_4_22, rnd_4_22, 0x01);
__m256i rnd_5_6 = _mm256_blendv_epi8(rnd_4_6, shf_5_22, blm_5);
_mm_prefetch(prf_origin+13*src_stride, _MM_HINT_NTA);
__m256i rnd_5_22 = _mm256_blendv_epi8(shf_5_6, rnd_4_22, blm_5);
*(__m256i*)(dst_origin + 6*dst_stride) = rnd_5_6;
*(__m256i*)(dst_origin + 22*dst_stride) = rnd_5_22;
__m256i shf_5_7 = _mm256_permute2x128_si256(rnd_4_7, rnd_4_7, 0x01);
__m256i shf_5_23 = _mm256_permute2x128_si256(rnd_4_23, rnd_4_23, 0x01);
__m256i rnd_5_7 = _mm256_blendv_epi8(rnd_4_7, shf_5_23, blm_5);
__m256i rnd_5_23 = _mm256_blendv_epi8(shf_5_7, rnd_4_23, blm_5);
*(__m256i*)(dst_origin + 7*dst_stride) = rnd_5_7;
*(__m256i*)(dst_origin + 23*dst_stride) = rnd_5_23;
__m256i shf_5_8 = _mm256_permute2x128_si256(rnd_4_8, rnd_4_8, 0x01);
__m256i shf_5_24 = _mm256_permute2x128_si256(rnd_4_24, rnd_4_24, 0x01);
__m256i rnd_5_8 = _mm256_blendv_epi8(rnd_4_8, shf_5_24, blm_5);
__m256i rnd_5_24 = _mm256_blendv_epi8(shf_5_8, rnd_4_24, blm_5);
*(__m256i*)(dst_origin + 8*dst_stride) = rnd_5_8;
*(__m256i*)(dst_origin + 24*dst_stride) = rnd_5_24;
__m256i shf_5_9 = _mm256_permute2x128_si256(rnd_4_9, rnd_4_9, 0x01);
__m256i shf_5_25 = _mm256_permute2x128_si256(rnd_4_25, rnd_4_25, 0x01);
__m256i rnd_5_9 = _mm256_blendv_epi8(rnd_4_9, shf_5_25, blm_5);
__m256i rnd_5_25 = _mm256_blendv_epi8(shf_5_9, rnd_4_25, blm_5);
*(__m256i*)(dst_origin + 9*dst_stride) = rnd_5_9;
*(__m256i*)(dst_origin + 25*dst_stride) = rnd_5_25;
__m256i shf_5_10 = _mm256_permute2x128_si256(rnd_4_10, rnd_4_10, 0x01);
__m256i shf_5_26 = _mm256_permute2x128_si256(rnd_4_26, rnd_4_26, 0x01);
__m256i rnd_5_10 = _mm256_blendv_epi8(rnd_4_10, shf_5_26, blm_5);
_mm_prefetch(prf_origin+14*src_stride, _MM_HINT_NTA);
__m256i rnd_5_26 = _mm256_blendv_epi8(shf_5_10, rnd_4_26, blm_5);
*(__m256i*)(dst_origin + 10*dst_stride) = rnd_5_10;
*(__m256i*)(dst_origin + 26*dst_stride) = rnd_5_26;
__m256i shf_5_11 = _mm256_permute2x128_si256(rnd_4_11, rnd_4_11, 0x01);
__m256i shf_5_27 = _mm256_permute2x128_si256(rnd_4_27, rnd_4_27, 0x01);
__m256i rnd_5_11 = _mm256_blendv_epi8(rnd_4_11, shf_5_27, blm_5);
__m256i rnd_5_27 = _mm256_blendv_epi8(shf_5_11, rnd_4_27, blm_5);
*(__m256i*)(dst_origin + 11*dst_stride) = rnd_5_11;
*(__m256i*)(dst_origin + 27*dst_stride) = rnd_5_27;
__m256i shf_5_12 = _mm256_permute2x128_si256(rnd_4_12, rnd_4_12, 0x01);
__m256i shf_5_28 = _mm256_permute2x128_si256(rnd_4_28, rnd_4_28, 0x01);
__m256i rnd_5_12 = _mm256_blendv_epi8(rnd_4_12, shf_5_28, blm_5);
__m256i rnd_5_28 = _mm256_blendv_epi8(shf_5_12, rnd_4_28, blm_5);
*(__m256i*)(dst_origin + 12*dst_stride) = rnd_5_12;
*(__m256i*)(dst_origin + 28*dst_stride) = rnd_5_28;
__m256i shf_5_13 = _mm256_permute2x128_si256(rnd_4_13, rnd_4_13, 0x01);
__m256i shf_5_29 = _mm256_permute2x128_si256(rnd_4_29, rnd_4_29, 0x01);
__m256i rnd_5_13 = _mm256_blendv_epi8(rnd_4_13, shf_5_29, blm_5);
__m256i rnd_5_29 = _mm256_blendv_epi8(shf_5_13, rnd_4_29, blm_5);
*(__m256i*)(dst_origin + 13*dst_stride) = rnd_5_13;
*(__m256i*)(dst_origin + 29*dst_stride) = rnd_5_29;
__m256i shf_5_14 = _mm256_permute2x128_si256(rnd_4_14, rnd_4_14, 0x01);
__m256i shf_5_30 = _mm256_permute2x128_si256(rnd_4_30, rnd_4_30, 0x01);
__m256i rnd_5_14 = _mm256_blendv_epi8(rnd_4_14, shf_5_30, blm_5);
_mm_prefetch(prf_origin+15*src_stride, _MM_HINT_NTA);
__m256i rnd_5_30 = _mm256_blendv_epi8(shf_5_14, rnd_4_30, blm_5);
*(__m256i*)(dst_origin + 14*dst_stride) = rnd_5_14;
*(__m256i*)(dst_origin + 30*dst_stride) = rnd_5_30;
__m256i shf_5_15 = _mm256_permute2x128_si256(rnd_4_15, rnd_4_15, 0x01);
__m256i shf_5_31 = _mm256_permute2x128_si256(rnd_4_31, rnd_4_31, 0x01);
__m256i rnd_5_15 = _mm256_blendv_epi8(rnd_4_15, shf_5_31, blm_5);
__m256i rnd_5_31 = _mm256_blendv_epi8(shf_5_15, rnd_4_31, blm_5);
*(__m256i*)(dst_origin + 15*dst_stride) = rnd_5_15;
*(__m256i*)(dst_origin + 31*dst_stride) = rnd_5_31;
}
void transpose_Vec256(const Mat& src, Mat* dst) {
const int64_t n = src.n();
for (int64_t rb = 0; rb < n/64; rb++) {
for (int64_t cb = 0; cb < n/64; cb++) {
const uint8_t* src_origin = src.data() + (rb*n+cb)*64;
const uint8_t* prf_origin = next_block(src, rb, cb);
uint8_t* dst_origin = dst->data() + (cb*n+rb)*64;
transpose_Vec256_kernel(src_origin, dst_origin, prf_origin, n, n);
transpose_Vec256_kernel(src_origin+32*n, dst_origin+32, prf_origin+n*16, n, n);
transpose_Vec256_kernel(src_origin+32, dst_origin+32*n, prf_origin+n*32, n, n);
transpose_Vec256_kernel(src_origin+32*n+32, dst_origin+32*n+32, prf_origin+n*48, n, n);
}
}
}
Switching from general purpose instruction set to AVX turned out to be quite complex. But it comes with a benefit of further reduction in running time by 15-30% compared to 64-bit version:
This trend should continue with increase in vector size, provided that performance is not stuck in memory access and that latency of longer-vector instructions is the same as of their shorter counterparts. Unfortunately, vector sizes can’t be increased indefinitely. In the majority of horizontal vector instructions, such as shuffle, every element of the output register depends on every element of the input register. Such logic requires O(log(n)) stages of digital circuitry, which increases latency and hence defeats the purpose of increasing vector size. We already saw that shuffle in fact is not a purely 256-bit horizontal SIMD instruction, but a pair of simultaneously executing 128-bit shuffles. For CPUs, it is quite unrealistic that vector instructions will be increased from 512 (provided by AVX-512) to longer values.