
Local LLMs are more powerful than many people realize. While smaller models are certainly less capable than larger online alternatives, they can leverage tools to identify errors and self-correct, significantly improving accuracy. For many use cases, local models offer a compelling option: no subscription fees and complete privacy since they don't require an internet connection.
Opencode and Pi as Claude Code Alternatives
LLMs don't run in isolation. A harness runner is essential to create context and provide Skills or MCPs. Some harnesses start with a rich initial prompt, while others take a more minimal and modular approach. The model you choose matters most, but your harness selection also influences final results in terms of speed and correctness. A larger context means more guidelines, but it can also mean slower performance and occasional confusion for smaller models.
The Benchmark
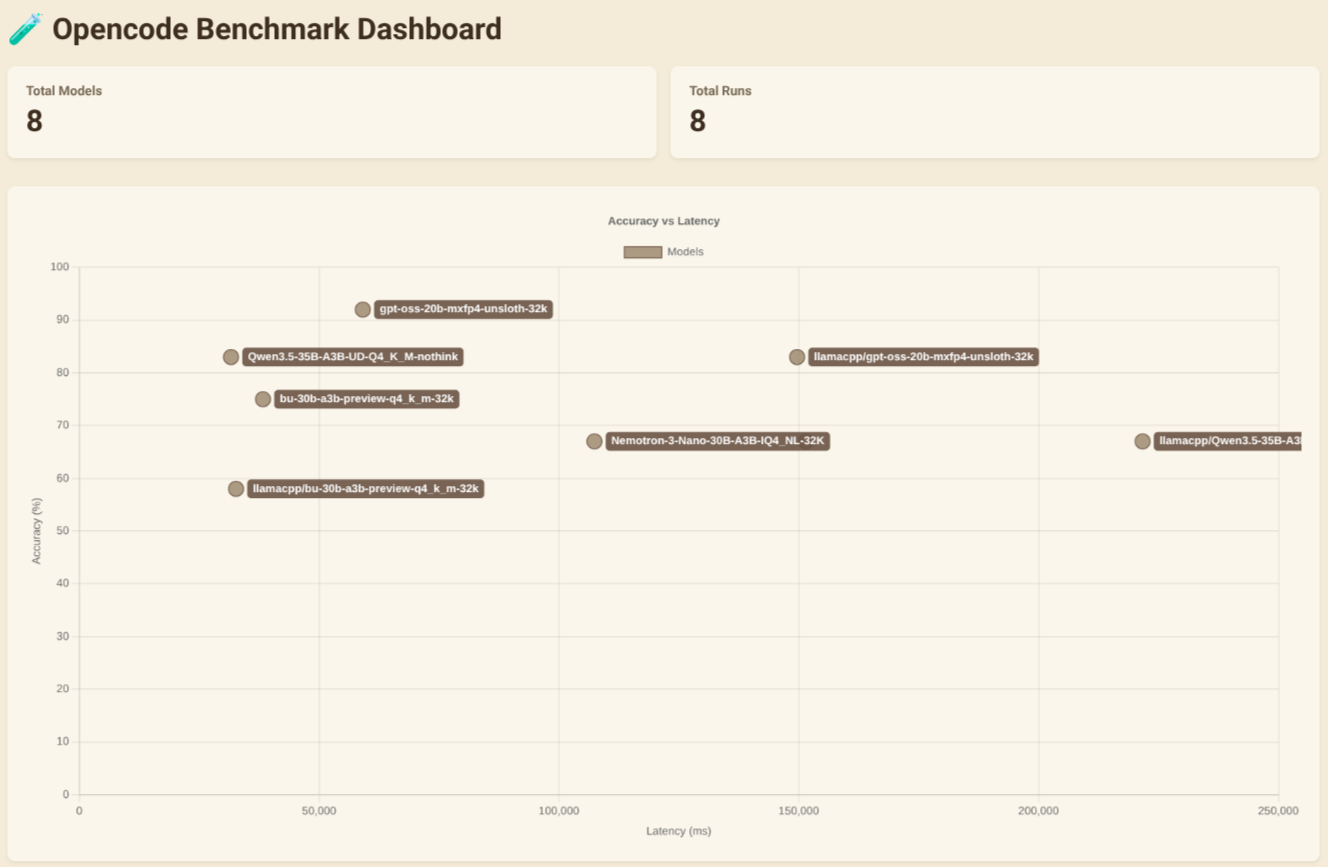
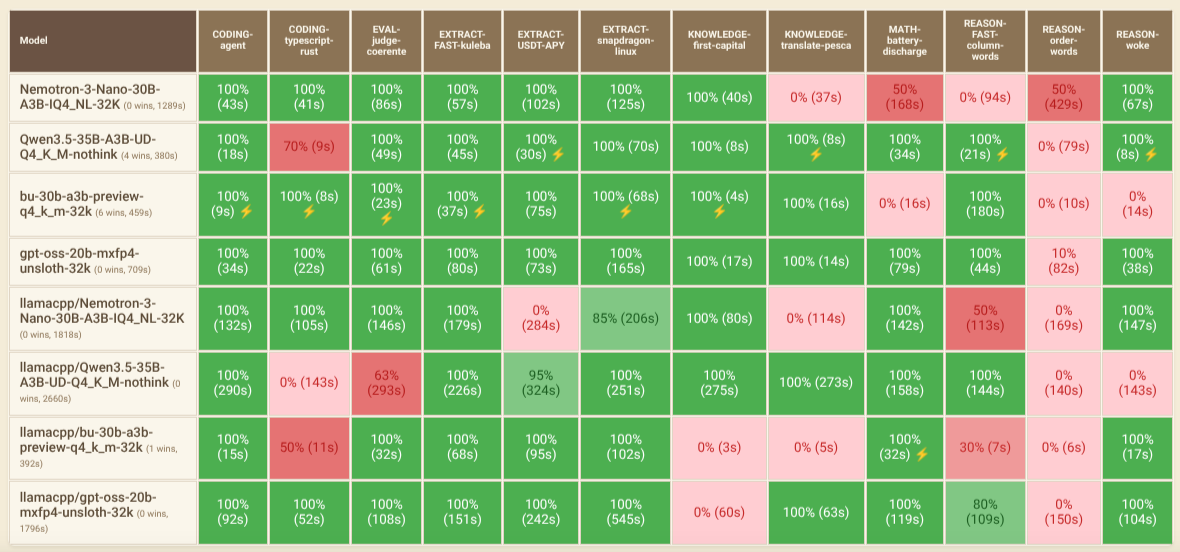
I tested both Opencode and Pi using the Opencode Benchmark Dashboard with various models and custom prompts.
Here's how to run prompts in non-interactive mode:
opencode run --model "llamacpp/bu-30b-a3b-preview-q4_k_m-32k" "scrivi la prima capitale dell'italia"
pi --model bu-30b-a3b-preview-q4_k_m-32k -p "scrivi la prima capitale dell'italia"
Models Tested
- Nemotron-3-Nano-30B-A3B-IQ4_NL-32K
- Qwen3.5-35B-A3B-UD-Q4_K_M-nothink
- bu-30b-a3b-preview-q4_k_m-32k (qwen3-vl family)
- gpt-oss-20b-mxfp4-unsloth-32k
Models with the llamacpp/* prefix were tested with Opencode, while those without it were tested with Pi.
My Key Takeaways
- Larger context sizes typically hurt accuracy and speed, especially when filled with rules not needed to reach the correct answer.
- gpt-oss-20b-mxfp4-unsloth-32k delivered the best results for both accuracy and speed in my tests.
- Qwen3.5-35B-A3B-UD-Q4_K_M-nothink is the best choice if speed matters more than accuracy.
GitHub - anomalyco/opencode: The open source coding agent.
The open source coding agent. Contribute to anomalyco/opencode development by creating an account on GitHub.
![]() GitHubanomalyco
GitHubanomalyco

GitHub - badlogic/pi-mono: AI agent toolkit: coding agent CLI, unified LLM API, TUI & web UI libraries, Slack bot, vLLM pods
AI agent toolkit: coding agent CLI, unified LLM API, TUI & web UI libraries, Slack bot, vLLM pods - badlogic/pi-mono
![]() GitHubbadlogic
GitHubbadlogic
GitHub - grigio/opencode-benchmark-dashboard: Benchmark system for testing opencode with various LLM models, measuring speed (latency) and correctness (accuracy).
Benchmark system for testing opencode with various LLM models, measuring speed (latency) and correctness (accuracy). - grigio/opencode-benchmark-dashboard
![]() GitHubgrigio
GitHubgrigio
