![]()
📬 Subscribe for release updates — new versions, no spam
Your clusters are talking. This assistant helps you listen.
An AI-powered Kubernetes troubleshooting assistant that lets teams investigate, diagnose, and resolve cluster issues through natural language — via a chat-based web UI or directly inside your IDE (Cursor / Claude Desktop / VS Code via MCP).
Combines live kubectl access with pluggable LLM providers (Gemini, Ollama/local, more coming) for root-cause analysis that turns cryptic Kubernetes failures into clear answers and actionable fix commands.
See it in action
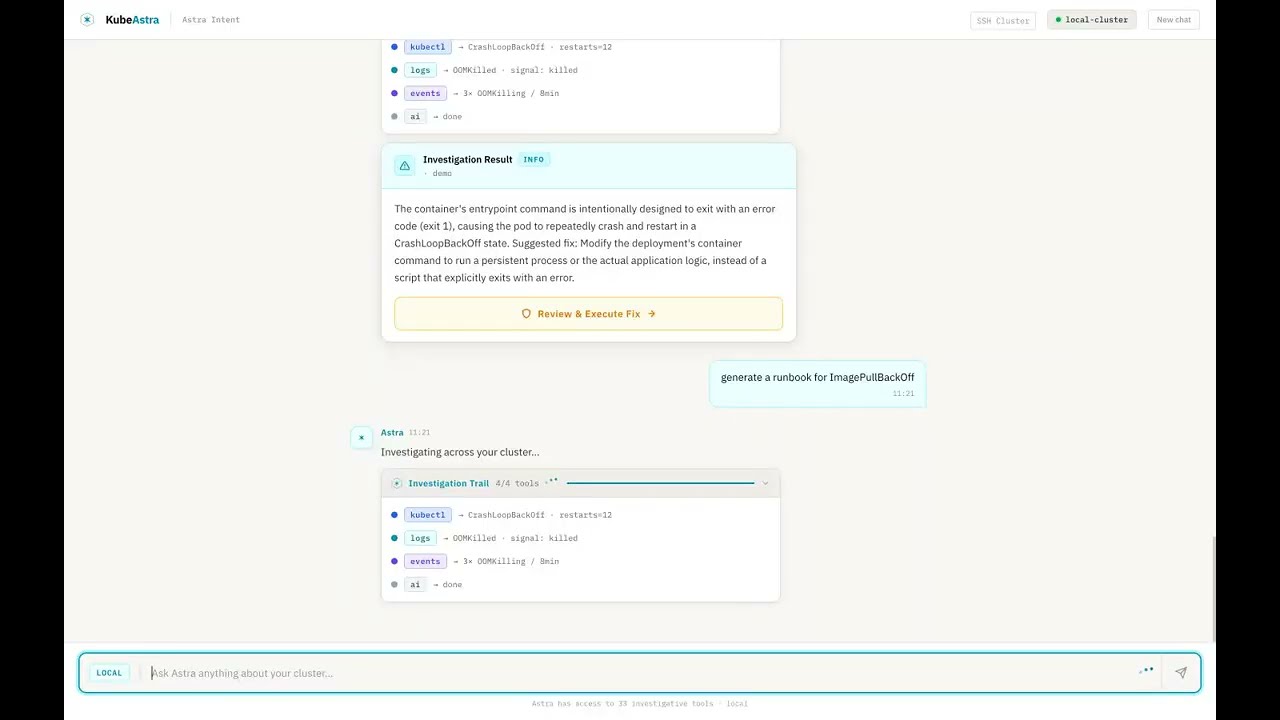
▶ Watch the 90-second demo — Kubeastra walking through 7 real Kubernetes failures (CrashLoopBackOff, OOMKilled, ImagePullBackOff, stuck PVC, unschedulable pod, namespace-wide health, runbook generation).
Want to reproduce it locally?
make demospins up a kind cluster pre-seeded with six broken workloads. Seedemo/README.md.
Why this exists
Every DevOps engineer has been here: a pod is crashlooping at 2 AM, and you're mentally chaining together kubectl get, kubectl describe, kubectl logs, cross-referencing events, checking resource limits, and Googling error messages — all while half asleep.
This tool handles that investigation loop for you:
- Ask in plain English — "Why is payment-service crashing in production?"
- Get root-cause analysis — not just logs, but AI-synthesized explanations of what's wrong and why
- Receive fix commands — ready to run, with safety confirmations for write operations
- Generate runbooks — so your team doesn't debug the same issue twice
- Stay on your own infra — run entirely locally with Ollama, no data leaves your cluster
Key Features
🔗 Connect Any Cluster in Seconds
Four ways to connect — pick what fits your setup:
| Mode | How it works | Best for |
|---|---|---|
| Auto-detect | Reads your local ~/.kube/config and lists available contexts |
Local dev, minikube, kind, Docker Desktop |
| Kubeconfig upload | Paste or upload a kubeconfig file, pick a context | Remote clusters, CI-generated configs |
| SSH | Enter host/user/password — kubectl runs on the remote node over SSH | Air-gapped clusters, bare-metal kubeadm |
| In-cluster | Mounts the ServiceAccount token automatically | When deployed inside the cluster via Helm |
Switch between clusters without restarting. Each session tracks its own connection.
🔍 34 Built-in Kubernetes Tools
Live cluster tools (28) — pod/deployment/service inspection, event streams, multi-namespace discovery, rollout status, kubeconfig context switching, log retrieval with previous-container support, resource-graph topology, deployment-level investigation, namespace-wide health analysis, and safe write operations (delete, scale, restart, patch — all gated behind confirm=true).
AI analysis tools (6) — error analysis with RAG-backed similarity search, curated fix playbooks for 11 error categories, AI-generated runbooks, cluster health reports, post-incident summarization.
🤖 Agentic ReAct Investigation
Unlike single-shot "ask → answer" tools, Kubeastra runs a multi-step ReAct loop — reasoning through complex failures autonomously:
You: Why is checkout-service down?
Agent reasoning:
✓ find_workload — searching across all namespaces
✓ investigate_pod — found CrashLoopBackOff in checkout-svc-7d4f9b
✓ get_pods — checking Redis dependency → ConnectionRefused
✓ describe_pod — Redis pod Pending: unbound PVC
Root cause: PersistentVolumeClaim redis-data is unbound,
preventing Redis from starting, which cascades to checkout-service.
Each reasoning step is visible in real-time via the Investigation Trail — no black box. The agent answers listing questions in a single step and complex debugging in 2-3 steps, with a 90-second wall-clock safety timeout.
🔧 One-Click Fix Execution
When the AI identifies a fix, you get a Review & Execute button with the exact commands:
- Only write operations are suggested (delete pod, rollout restart, scale, patch) — never diagnostic commands you've already seen
- Slide-to-confirm safety gate before any command runs
- Button disappears after execution — no accidental re-runs
- When no safe automated fix exists (e.g., "update your Helm values"), the card shows Manual Steps Required with numbered instructions instead
👥 Collaborative Sessions
- Shareable URLs — click Share to copy a session link (
/chat/:sessionId). Anyone with the URL sees the full investigation history — including the root-cause card, fix commands, and evidence. - Investigation timeline — every ReAct step (tool call, thought, observation) renders as a real-time timeline, not simulated placeholders.
- Session not found — invalid or expired shared links show a clear message instead of a blank page.
- One-click post-mortems — generate a structured post-mortem (summary, timeline, root cause, impact, resolution, action items) from any investigation session via the API.
🗺️ Visual Debugging Canvas
The resource graph is an interactive investigation surface, not just a topology diagram:
- Health-aware nodes — pods, services, deployments, and ingresses colored by health status with pulsing red glow for degraded resources
- Click-to-inspect — click any node to see full metadata in a detail panel
- Hover tooltips — quick metadata preview (phase, restarts, IP, ports, replicas)
- Edge labels — see relationships at a glance: "routes →", "selects →", "manages →"
- MiniMap + zoom/pan — navigate large cluster topologies with ease
💬 Two Ways to Use It
| Web UI | IDE / MCP Integration |
|---|---|
| Chat-based Next.js interface for team-wide troubleshooting | Direct integration into Cursor, Claude Desktop, or any MCP client |
| Connect any cluster (auto-detect, kubeconfig upload, SSH) | Debug without leaving your editor |
| Shareable session URLs with persistent chat history (SQLite) | 34 tools available via stdio or HTTP MCP transport |
| Visual resource graph with click-to-inspect | Same ReAct agent powers both surfaces |
🔌 Pluggable LLM Providers
Pick your LLM — Google Gemini (default, free tier available) or Ollama (fully local — your cluster data never leaves your network). OpenAI and Anthropic Claude adapters coming next.
🛡️ Safety First
- Read-only by default — all
kubectlcommands are validated before execution - Explicit confirmation required for write operations (
delete,scale,restart,patch) via slide-to-confirm - Full audit logging of every command executed
- RBAC-aware — respects your existing Kubernetes permissions
- Input validation — namespace/name/label-selector safety checks prevent injection
- Session isolation — temp kubeconfig files are scoped per session with
0600permissions, sanitized session IDs prevent path traversal, cryptographic session tokens prevent URL guessing - Command allowlist — the execute endpoint only accepts specific kubectl write prefixes; everything else is rejected
🚀 Deploy Anywhere
- Local dev — docker-compose one-liner
- Kind demo cluster —
make demospins up a broken cluster so you can see the tool work in 60 seconds - Production Helm chart — deploy into the same clusters it monitors
- SSH multi-cluster — query any remote kubeadm cluster without copying kubeconfigs
Quick Start
Option 1: Try the demo (60 seconds, no cluster needed)
Prerequisites: Docker Desktop, kind, kubectl
git clone https://github.com/kubeastra/KubeAstra.git
cd KubeAstra
make demoSpins up a local kind cluster with pre-broken workloads (CrashLoop, OOM, ImagePull, stuck PVC) and launches the web UI.
Open http://localhost:3300 and ask "what's broken in the demo namespace?".
The demo generates its own kubeconfig automatically — it does not touch your host's current kubectl context. See
demo/README.mdfor full prerequisites and troubleshooting.
Option 2: Run locally against your own cluster
Prerequisites: a running Kubernetes cluster with kubectl access, and a Google Gemini API key (free tier) or Ollama running locally.
# 1. Configure the backend cp ui/backend/.env.example ui/backend/.env # → set GEMINI_API_KEY (or LLM_PROVIDER=ollama) in .env # 2. Start via docker-compose (kubeconfig mounted read-only) cd ui docker compose up --build # 3. Open http://localhost:3300
Option 3: Use via MCP (Cursor / Claude Desktop)
cd mcp ./setup.sh # creates venv, installs deps, writes MCP config entry
Edit mcp/.env:
GEMINI_API_KEY=your-key-here # or LLM_PROVIDER=ollama ALLOWED_NAMESPACES=prod,staging,default
Restart your IDE — all 34 tools appear as MCP tools.
Option 4: Deploy to Kubernetes via Helm
helm upgrade --install kubeastra helm/kubeastra \ --namespace kubeastra --create-namespace \ --set backend.image.repository=ghcr.io/your-org/kubeastra-backend \ --set frontend.image.repository=ghcr.io/your-org/kubeastra-frontend \ --set secrets.geminiApiKey="YOUR_KEY" \ --set secrets.kubeconfig="$(cat ~/.kube/config | base64 | tr -d '\n')"
How It Works
- Connect your cluster — auto-detect your local kubeconfig, upload one, or enter SSH credentials. The connection is scoped to your session.
- Ask a question — "Why are pods in checkout-service not starting?"
- ReAct investigation — the LLM reasons step-by-step: picks a tool → executes it → observes the result → decides the next action. This continues autonomously (up to 6 iterations, 90-second timeout) until it has enough context to answer. Falls back to a keyword router if no LLM key is set.
- Auto-discovery — if you don't specify a namespace,
find_workloadsearches across all namespaces. Large clusters (thousands of pods) are handled efficiently via text-format parsing instead of JSON. - Live investigation — executes read-only
kubectlcommands against your cluster. Cluster connection flags are injected per-session automatically. - AI synthesis — returns a severity-rated root-cause card with metrics, evidence, and either one-click fix commands or manual steps.
- Persistence — every message, tool call, and result saved to SQLite so you can pick up where you left off.
- Share and collaborate — share the session URL with your team. They see the full investigation including the root-cause card, fix commands, and evidence.
Example Interactions
Quick listing — answered in one tool call, ~5 seconds:
You: what pods are in the jenkins namespace?
Astra: Here are the pods in the jenkins namespace.
┌─────────────────────────┬──────────┬───────┬──────────┐
│ Name │ Status │ Ready │ Restarts │
├─────────────────────────┼──────────┼───────┼──────────┤
│ jenkins-0 │ Running │ 2/2 │ 1 │
│ avatar-agent-1s7k7 │ Pending │ 0/0 │ 0 │
└─────────────────────────┴──────────┴───────┴──────────┘
Deep investigation — multi-step ReAct, ~15 seconds:
You: why is mongo arbiter pod in crashloop?
Investigation Trail: 3/3 tools
✓ kubectl → pod status retrieved
✓ events → events scanned
✓ ai → analysis complete
┌─ CrashLoopBackOff ─────────────────────── CRITICAL ─┐
│ mongodb-arbiter-0 · infrastructure │
│ │
│ The MongoDB arbiter pod is failing to start because │
│ the designated primary host (mongodb-0) is not │
│ available. The arbiter's setup process times out. │
│ │
│ ┌──────────┐ ┌──────────────────┐ ┌───────┐ │
│ │ 360 │ │ CrashLoopBackOff │ │ False │ │
│ │ RESTARTS │ │ STATUS │ │ READY │ │
│ └──────────┘ └──────────────────┘ └───────┘ │
│ │
│ [Review & Execute Fix] │
└──────────────────────────────────────────────────────┘
Fix command: kubectl delete pod mongodb-arbiter-0 -n infrastructure
Configuration
All settings are read from environment variables (or .env):
| Variable | Default | Description |
|---|---|---|
LLM_PROVIDER |
gemini |
gemini or ollama |
GEMINI_API_KEY |
— | Required when LLM_PROVIDER=gemini. Get one free |
GEMINI_MODEL |
gemini-2.5-flash |
Gemini model to use |
OLLAMA_BASE_URL |
http://localhost:11434 |
Ollama server URL |
OLLAMA_MODEL |
llama3.1 |
Ollama model name (must be pulled first) |
ALLOWED_NAMESPACES |
* |
Comma-separated list, or * for all |
KUBECTL_TIMEOUT_SECONDS |
15 |
Per-command timeout |
MAX_LOG_TAIL_LINES |
200 |
Max log lines per request |
ENABLE_RECOVERY_OPERATIONS |
false |
Enables delete_pod, rollout_restart, scale_deployment, apply_patch |
WEAVIATE_URL |
http://localhost:8080 |
Optional RAG vector DB |
Repository Layout
kubeastra/
├── ui/
│ ├── frontend/ # Next.js chat UI
│ │ ├── app/chat/ # Chat page + /chat/:sessionId share routes
│ │ │ ├── page-client.tsx # Main chat component (ReAct rendering, result cards)
│ │ │ └── [sessionId]/ # Shareable session page
│ │ └── components/ # ClusterConnect, ResourceGraph, RootCauseCard, etc.
│ ├── backend/ # FastAPI app + SQLite persistence
│ │ ├── routers/
│ │ │ ├── chat.py # Chat flow, tool dispatch, fix execution
│ │ │ ├── cluster.py # Cluster connection management (4 modes)
│ │ │ └── sessions.py # History, SSH targets, post-mortem API
│ │ ├── react.py # ReAct loop orchestrator
│ │ └── db.py # SQLite with cluster_connections table
│ └── docker-compose.yml
├── mcp/
│ ├── mcp_server/ # MCP server (stdio + HTTP transports)
│ ├── k8s/ # kubectl wrappers, SSH runner, validators
│ ├── ai_tools/ # Error analysis, fix playbooks, runbooks
│ ├── services/ # LLM providers, Weaviate, embeddings
│ └── config/settings.py
├── helm/kubeastra/ # Helm chart
├── demo/ # Kind + broken workloads for `make demo`
└── docs/ # Public documentation
Roadmap
- Gemini + Ollama (local) LLM support
- Demo mode with kind cluster
- Approval flow for write operations
- Deployment-level investigation (
investigate_workload) - Namespace-wide health analysis (
analyze_namespace) - Agentic ReAct investigation loop (multi-step tool calling)
- Shareable session URLs + investigation timeline
- Auto-generated post-mortems from investigation sessions
- Visual debugging canvas (interactive resource graph with health glow, click-to-inspect, tooltips, MiniMap)
- Multi-modal cluster connection (auto-detect, kubeconfig upload, SSH, in-cluster)
- One-click fix execution with safety guards and slide-to-confirm
- Manual steps fallback when no automated fix is available
- Large cluster support (text-format parsing for all-namespaces queries)
- Session security hardening (path traversal prevention, cryptographic session IDs, command allowlists)
- Team playbook engine — investigation templates that codify debugging patterns
- Alert-driven auto-investigation (PagerDuty / OpsGenie / Alertmanager webhooks)
- OpenAI + Anthropic Claude adapters
- Prometheus / Loki / Tempo observability integrations
- "What changed?" view — recent deployments, ConfigMap/Secret mutations
- Real-time collaborative sessions (WebSocket sync + presence indicators)
- Slack bot integration (alert → investigation → findings in channel)
- CNCF Sandbox submission
Contributing
Contributions are welcome — especially the items at the top of the roadmap. See CONTRIBUTING.md for local setup, project layout, and how to add a new tool, and CODE_OF_CONDUCT.md for community guidelines.
Looking for a starter task? Check the good first issue label.
License
Apache 2.0 — see LICENSE for details.