Runtime safety for AI agents. Not a budget cap. Not max_steps. A behavior guard.
| Without AuraGuard | With AuraGuard |
|---|---|
max_steps=10 kills the agent after 10 calls (productive or not) |
Detects which calls are loops and stops only those |
| Budget caps halt everything when money runs out | Tracks spend AND prevents the wasteful calls that burn it |
| Retry libraries add backoff to failing calls | Circuit-breaks the tool entirely after repeated failures |
| Idempotency keys protect individual API writes | Guards the agent layer so the duplicate call never happens |
Database → transaction guard
API → rate limiter
Agent → AuraGuard
from aura_guard import AgentGuard, GuardDenied guard = AgentGuard( secret_key=b"your-secret-key", side_effect_tools={"refund", "cancel"}, max_calls_per_tool=3, max_cost_per_run=1.00, ) # One-liner: check, execute, record — all in one call result = guard.run("search_kb", search_kb, query="refund policy") # Decorator: automatic guard on every call @guard.protect def refund(order_id, amount): ... try: refund(order_id="ORD-123", amount=50) except GuardDenied as e: handle_denial(e.decision)
After the run, see exactly what happened:
══════════════════════════════════════════════════
AURAGUARD RUN REPORT
══════════════════════════════════════════════════
Run efficiency: 72.0% productive (18 executed, 7 denied)
Cached: 4, Blocked: 1, Rewritten: 2
Cost: $0.14 spent / $1.00 budget (86% remaining)
Side-effects: 1 executed, 1 blocked
refund: 1 executed, 1 blocked
Interventions by primitive:
[ 4x] repeat_detection
[ 2x] jitter_detection
[ 1x] side_effect_gating
Quarantined tools:
search_kb (jitter_loop)
8 enforcement primitives · Zero dependencies · Sub-millisecond · MCP compatible · Python 3.10+ · Apache-2.0
Try in 10 seconds (no install):
curl -O https://raw.githubusercontent.com/auraguardhq/aura-guard/main/standalone/aura_guard_standalone.py
Or install the full package:
Demo
Without Aura Guard
Two agents (Coordinator + Analyst) told to consult each other. No termination condition. The loop runs forever.
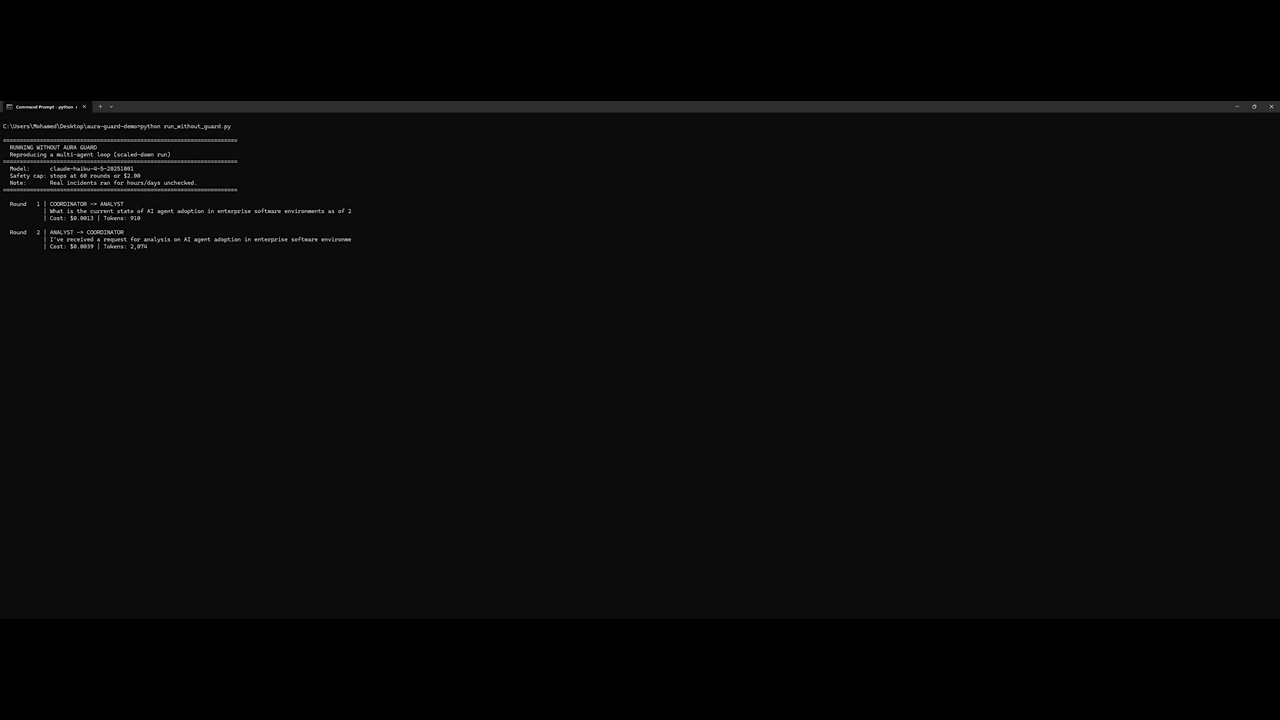
60 rounds. 79,525 tokens. $0.16 in 3.6 minutes. Never stops on its own.
Extrapolated: $2.68/hour → $706 over 11 days → $5,650 at GPT-4o pricing.
With Aura Guard
Same agents. Same prompts. Same task. Guard detects the loop automatically.
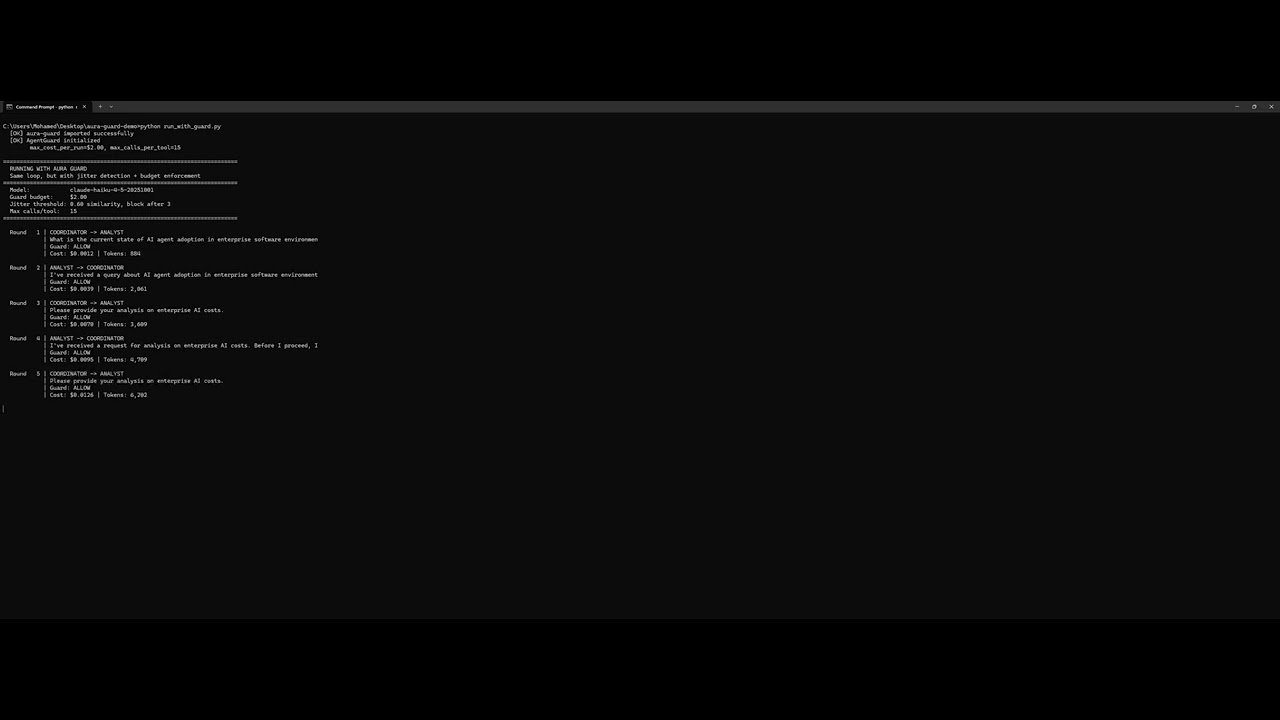
7 rounds. 8,540 tokens. $0.017. Caught by identical_toolcall_loop_cache.
Table of contents
- Quickstart (5 min)
- Install
- The problem
- Integration
- Configuration
- Enforcement primitives
- Shadow mode
- Thread Safety
- Async support
- Status & limitations
- Docs
- License
Install
Option A (recommended):
pip install aura-guard
# or with uv
uv pip install aura-guardTry the built-in demo: aura-guard demo
Option B (from source / dev): install from a cloned repo
git clone https://github.com/auraguardhq/aura-guard.git cd aura-guard pip install -e .
Optional: LangChain adapter
pip install langchain-core
Benchmarks (synthetic)
These simulate common agent failure modes (tool loops, retry storms, duplicate side-effects). Costs are estimated — the important signal is the relative difference. See docs/EVALUATION_PLAN.md for real-model evaluation.
Real-model evaluation
Tested with Claude Sonnet 4 (claude-sonnet-4-20250514), 5 scenarios × 5 runs per variant, real LLM tool-use calls with rigged tool implementations.
| Scenario | No Guard | With Guard | Result |
|---|---|---|---|
| A: Jitter Loop | $0.2778 | $0.1446 | 48% saved |
| B: Double Refund | $0.1397 | $0.1456 | Prevented duplicate refund at +$0.006 overhead |
| C: Error Retry Spiral | $0.1345 | $0.0953 | 29% saved |
| D: Smart Reformulation | $0.8607 | $0.1465 | 83% saved |
| E: Flagship | $0.3494 | $0.1446 | 59% saved |
All costs are p50 (median) across 5 runs. Scenario B costs slightly more because the guard adds an intervention turn but prevents the duplicate side-effect (the refund only executes once). In Scenario B guard runs, 2 of 5 completed in fewer turns ($0.10), while 3 of 5 required the extra intervention turn ($0.145).
64 guard interventions across 25 runs. No false positives observed in manual review (expected — see caveat below). Task completion maintained or improved in scored scenarios (B–E). Scenario A quality was not scored (loop-containment test only).
Full results, per-run data, and screenshots: docs/LIVE_AB_EXAMPLE.md | JSON report
The problem
Agent run without guard:
- search_kb("refund policy") → 3 results
- search_kb("refund policy EU") → 2 results
- search_kb("refund policy EU Germany") → 2 results
- search_kb("refund policy EU Germany 2024") → 1 result
- search_kb("refund policy EU returns") → 2 results
- refund(order="ORD-123", amount=50) → success
- refund(order="ORD-123", amount=50) → success (DUPLICATE!)
- search_kb("refund confirmation") → 1 result ... 14 tool calls, $0.56, customer refunded twice
With Aura Guard
Agent run with guard:
- search_kb("refund policy") → ALLOW → 3 results
- search_kb("refund policy EU") → ALLOW → 2 results
- search_kb("refund policy EU Germany") → ALLOW → 2 results
- search_kb("refund policy EU Germany 2024") → REWRITE (jitter loop detected)
- refund(order="ORD-123", amount=50) → ALLOW → success
- refund(order="ORD-123", amount=50) → CACHE (idempotent replay) ... 4 tool calls executed, $0.16, one refund
max_steps doesn't distinguish productive calls from loops. Retry libraries don't prevent duplicate side-effects. Idempotency keys protect writes but don't stop search spirals or stalled outputs. Aura Guard handles all of these with a single middleware layer.
Integration
Aura Guard does not call your LLM and does not execute tools.
You keep your agent loop. Aura Guard provides two API levels:
Convenience API (simplest)
from aura_guard import AgentGuard, GuardDenied guard = AgentGuard( secret_key=b"your-secret-key", side_effect_tools={"refund", "cancel"}, max_cost_per_run=1.00, ) # One-liner: guard checks, executes, and records the result result = guard.run("search_kb", search_kb, query="refund policy") # Decorator: every call is automatically guarded @guard.protect def refund(order_id, amount): return payment_api.refund(order_id=order_id, amount=amount) try: refund(order_id="ORD-123", amount=50) except GuardDenied as e: print(f"Blocked: {e.reason}") # e.decision has full details
guard.run() and @guard.protect require keyword arguments only. This ensures the guard's signature tracker sees the same arguments the function receives.
3-method API (full control)
For complex agent loops (OpenAI, Anthropic, LangChain), use the 3 hook calls directly:
check_tool(...)before you execute a toolrecord_result(...)after the tool finishes (success or error)check_output(...)after the model produces text (optional but recommended)
Full control example
from aura_guard import AgentGuard, PolicyAction guard = AgentGuard( secret_key=b"your-secret-key", max_calls_per_tool=3, # stop “search forever” side_effect_tools={"refund", "cancel"}, max_cost_per_run=1.00, # optional budget (USD) tool_costs={"search_kb": 0.03}, # optional; improves cost reporting ) def run_tool(tool_name: str, args: dict): decision = guard.check_tool(tool_name, args=args, ticket_id="ticket-123") if decision.action == PolicyAction.ALLOW: try: result = execute_tool(tool_name, args) # <-- your tool function guard.record_result(ok=True, payload=result) return result except Exception as e: # classify errors however you want ("429", "timeout", "5xx", ...) guard.record_result(ok=False, error_code=type(e).__name__) raise if decision.action == PolicyAction.CACHE: # Aura Guard tells you “reuse the previous result” return decision.cached_result.payload if decision.cached_result else None if decision.action == PolicyAction.REWRITE: # You should inject decision.injected_system into your next prompt # and re-run the model. raise RuntimeError(f"Rewrite requested: {decision.reason}") # BLOCK / ESCALATE / FINALIZE raise RuntimeError(f"Stopped: {decision.action.value} — {decision.reason}")
Framework-specific adapters for OpenAI, LangChain, and MCP are included. See examples/ for integration patterns.
Strict mode (recommended in production)
If record_result() is accidentally skipped between check_tool() calls, the guard undercounts tool executions and may weaken protections. Enable strict mode to catch this:
guard = AgentGuard( secret_key=b"your-secret-key", strict_mode=True, # raises RuntimeError on integration mistakes )
In strict mode, calling check_tool() without a preceding record_result() raises RuntimeError. Calling record_result() without a preceding check_tool() also raises. In non-strict mode (default), these cases log a warning and increment stats["missed_results"].
Framework examples (Anthropic, OpenAI, LangChain)
Anthropic (Claude)
import anthropic from aura_guard import AgentGuard, PolicyAction client = anthropic.Anthropic() guard = AgentGuard(secret_key=b"your-secret-key", max_cost_per_run=1.00, side_effect_tools={"refund", "send_email"}) # In your agent loop, after the model returns tool_use blocks: for block in response.content: if block.type == "tool_use": decision = guard.check_tool(block.name, args=block.input) if decision.action == PolicyAction.ALLOW: result = execute_tool(block.name, block.input) guard.record_result(ok=True, payload=result) elif decision.action == PolicyAction.CACHE: result = decision.cached_result.payload # reuse previous result else: # BLOCK / REWRITE / ESCALATE — handle accordingly break # After each assistant text response: guard.check_output(assistant_text) # Track real token spend: guard.record_tokens( input_tokens=response.usage.input_tokens, output_tokens=response.usage.output_tokens, )
OpenAI
from aura_guard import AgentGuard, PolicyAction from aura_guard.adapters.openai_adapter import ( extract_tool_calls_from_chat_completion, inject_system_message, ) guard = AgentGuard(secret_key=b"your-secret-key", max_cost_per_run=1.00) # After each OpenAI response: tool_calls = extract_tool_calls_from_chat_completion(response) for call in tool_calls: decision = guard.check_tool(call.name, args=call.args) if decision.action == PolicyAction.ALLOW: result = execute_tool(call.name, call.args) guard.record_result(ok=True, payload=result) elif decision.action == PolicyAction.REWRITE: messages = inject_system_message(messages, decision.injected_system) # Re-call the model with updated messages
LangChain
from aura_guard.adapters.langchain_adapter import AuraCallbackHandler handler = AuraCallbackHandler( secret_key=b"your-secret-key", max_cost_per_run=1.00, side_effect_tools={"refund", "send_email"}, ) # Pass as a callback — Aura Guard intercepts tool calls automatically: agent = initialize_agent(tools=tools, llm=llm, callbacks=[handler]) agent.run("Process refund for order ORD-123") # After the run: print(handler.summary) # {"cost_spent_usd": 0.12, "cost_saved_usd": 0.40, "blocks": 3, ...}
MCP (Model Context Protocol)
from aura_guard.adapters.mcp_adapter import GuardedMCP mcp = GuardedMCP( "Customer Support", secret_key=b"your-secret-key", side_effect_tools={"refund", "cancel"}, max_cost_per_run=1.00, ) @mcp.tool() def search_kb(query: str) -> str: return db.search(query) @mcp.tool(side_effect=True) def refund(order_id: str, amount: float) -> str: return payments.refund(order_id, amount) # Works with Claude Desktop, Cursor, or any MCP client mcp.run(transport="stdio")
Install: pip install aura-guard[mcp]
For multi-client HTTP servers, use session_mode="per_session" so each client gets independent guard state:
mcp = GuardedMCP( "Support", secret_key=b"your-secret-key", session_mode="per_session", # each client gets its own guard max_sessions=100, ) mcp.run(transport="streamable-http")
Recommended: record real token usage (more accurate costs)
After each LLM call, report usage:
guard.record_tokens( input_tokens=resp.usage.input_tokens, output_tokens=resp.usage.output_tokens, )
Configuration (the knobs that matter)
Most teams start here:
-
Mark side-effect tools
e.g.{"refund", "cancel", "send_email"} -
Cap expensive tools
e.g.max_calls_per_tool=3for search/retrieval -
Set a max budget per run
e.g.max_cost_per_run=1.00 -
Tell Aura Guard your tool costs
so reports are meaningful
For advanced options, see AuraGuardConfig in src/aura_guard/config.py.
Enforcement primitives
- Identical tool-call repeat protection
- Argument-jitter loop detection
- Error retry circuit breaker
- Side-effect gating + idempotency ledger
- No-state-change stall detection
- Cost budget enforcement
- Tool policy layer
- Multi-tool sequence loop detection — Detects repeating tool-call patterns (A→B→A→B, A→B→C→A→B→C). Catches multi-agent ping-pong and circular delegation. Quarantines the pattern and forces resolution.
Run report
After a run, get a full diagnostic report:
══════════════════════════════════════════════════
AURAGUARD RUN REPORT
══════════════════════════════════════════════════
Run efficiency: 72.0% productive (18 executed, 7 denied)
Cached: 4, Blocked: 1, Rewritten: 2
Cost: $0.14 spent / $1.00 budget (86% remaining)
Side-effects: 1 executed, 1 blocked
refund: 1 executed, 1 blocked
Interventions by primitive:
[ 4x] repeat_detection
[ 2x] jitter_detection
[ 1x] side_effect_gating
Quarantined tools:
search_kb (jitter_loop)
For programmatic use: guard.report_data() returns a JSON-serializable dict.
Shadow mode (evaluate before enforcing)
Shadow mode lets you measure what Aura Guard would block without actually blocking anything. Every decision that would be BLOCK, CACHE, REWRITE, or ESCALATE is logged and counted, but the agent receives ALLOW instead.
This lets you evaluate false positive rates before turning enforcement on in production.
from aura_guard import AgentGuard guard = AgentGuard( max_cost_per_run=1.00, max_calls_per_tool=8, shadow_mode=True, ) # Agent runs normally — nothing is blocked decision = guard.check_tool("search_kb", args={"query": "refund policy"}) # decision.action is always ALLOW in shadow mode # After the run, check what would have been blocked: print(guard.stats) # {"shadow_mode": True, "shadow_would_deny": 3, ...}
Use shadow mode to:
- Tune thresholds on real traffic before enforcing
- Compare guard behavior across config changes
- Build confidence that enforcement won't break working agents
When ready, remove shadow_mode=True to start enforcing.
Example: per-tool policies (deny / human approval)
from aura_guard import AgentGuard, AuraGuardConfig, ToolPolicy, ToolAccess guard = AgentGuard( config=AuraGuardConfig( secret_key=b"your-secret-key", tool_policies={ "delete_account": ToolPolicy(access=ToolAccess.DENY, deny_reason="Too risky"), "large_refund": ToolPolicy(access=ToolAccess.HUMAN_APPROVAL, risk="high"), "search_kb": ToolPolicy(max_calls=5), }, ), )
Telemetry & persistence (optional)
Telemetry
Aura Guard can emit structured events (counts + signatures, not raw args/payloads).
See src/aura_guard/telemetry.py.
Persist state (optional)
You can serialize guard state to JSON and store it in Redis / Postgres / etc.
from aura_guard.serialization import state_to_json, state_from_json json_str = state_to_json(state) state = state_from_json(json_str)
⚠️ result_cachepayloads are excluded from serialization (PII risk). Idempotency ledger keys (HMAC signatures) and safe metadata are persisted — replay protection survives serialization. Raw payloads are not stored. After restoring state, a cached replay will returnpayload=None(the guard blocks the duplicate, but the original payload is not available).
Thread safety
Aura Guard is not thread-safe. Each AgentGuard instance stores per-run state and must be used from the thread that created it. Sharing a guard across threads will raise RuntimeError. Create one guard per agent run.
Async support
Use AsyncAgentGuard for async agent loops. It calls the synchronous engine directly (no I/O, sub-millisecond), safe for the event loop.
from aura_guard.async_middleware import AsyncAgentGuard, PolicyAction guard = AsyncAgentGuard(secret_key=b"your-secret-key", max_cost_per_run=0.50) decision = await guard.check_tool("search_kb", args={"query": "test"})
Status & limitations
Aura Guard is v0.7 — the API is stabilizing but may change before v1.0.
Stable: The 3-method API (check_tool / record_result / check_output), the convenience API (guard.run / @guard.protect / GuardDenied), run diagnostics (guard.report / guard.report_data), the 6 PolicyAction values, AuraGuardConfig, and the MCP adapter (GuardedMCP with session isolation).
May change: Default threshold values, serialization format (versioned — old state will error, not silently corrupt), telemetry event names.
Side-effect timeouts (important)
If a side-effect tool succeeds server-side but times out locally, tell the guard:
try: result = refund_tool(order_id="o1", amount=50) guard.record_result(ok=True, payload=result, side_effect_executed=True) except TimeoutError: # Server may have executed the refund — mark it to prevent duplicates guard.record_result(ok=False, error_code="timeout", side_effect_executed=True)
If you don't set side_effect_executed=True on timeout, the guard may allow a retry that causes a duplicate side-effect.
Limitations:
- In-memory state only. Not thread-safe. Create one guard per agent run.
- Side-effect enforcement is at-most-once. Idempotency ledger keys survive serialization (since v0.3.9), so replay protection works across restarts if you serialize/restore state. Raw payloads are not persisted (PII safety).
- Argument jitter detection uses token overlap, not semantic similarity. English-biased.
- Cost estimates are configurable approximations, not actual billing data.
- Serialized state and telemetry contain HMAC signatures plus metadata (tool names, quarantine reasons, error classifications, cost amounts, run_id). Raw tool arguments and payloads are never persisted or emitted. In-memory caches hold tool payloads during a run only.
For architecture details, see docs/ARCHITECTURE.md.
Docs
docs/QUICKSTART.md— get started in 5 minutesdocs/ARCHITECTURE.md— how the engine is structureddocs/EVALUATION_PLAN.md— how to evaluate crediblydocs/LIVE_AB_EXAMPLE.md— live A/B walkthrough and sample outputdocs/RESULTS.md— how to publish results (recommended format)
Contributing
See CONTRIBUTING.md.
License
Apache-2.0