Scale Python to 1,000 VMs in your cloud in 1 second.
Burla is the fastest, simplest, and most efficient distributed computing framework for Python.
Scale ML pipelines, vector embeddings, AI Inference, and more with a dev cycle that feels local.
Burla only has one function:
from burla import remote_parallel_map my_inputs = list(range(1000)) def my_function(x): print(f"[#{x}] running on separate computer") remote_parallel_map(my_function, my_inputs)
This example runs my_function on 1,000 VMs in less than one second:

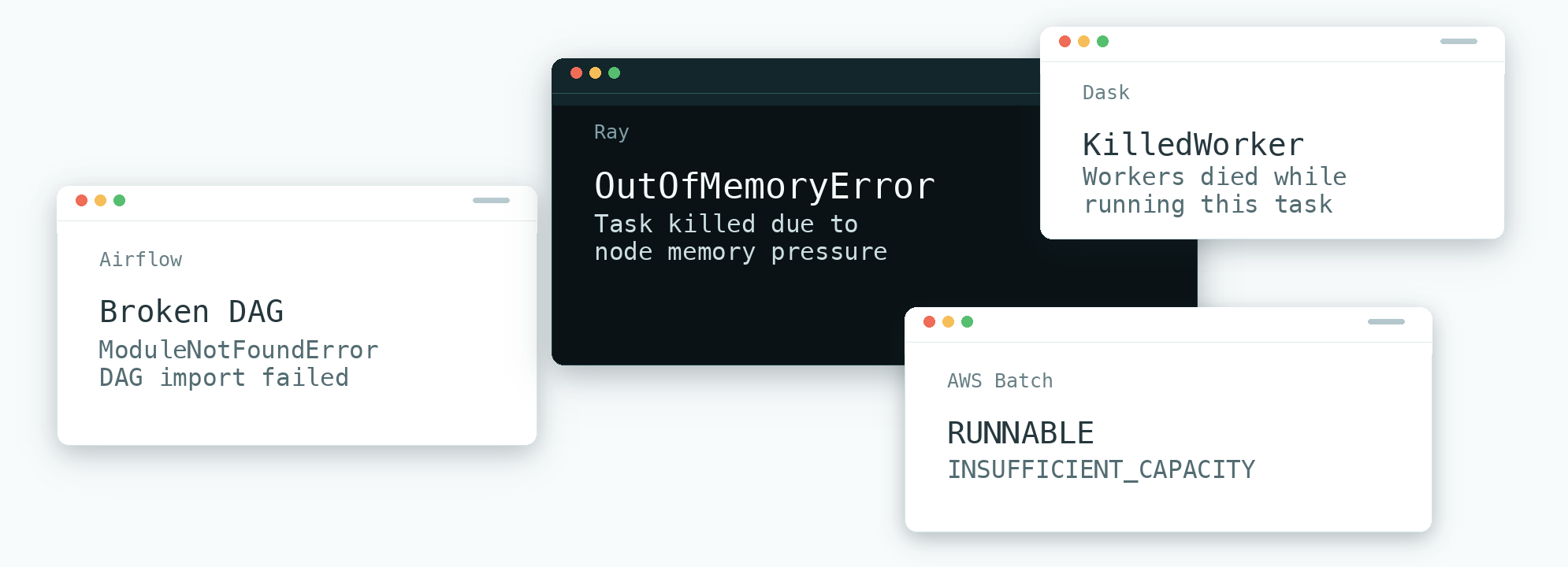
Scalable & efficient pipelines are not straightforward.
Slow deployments, VM reboots, or container rebuilds mean waiting 5-10 minutes with every change.
Errors are vague, and configs are full of secret tradeoffs. 90% resource utilization is a pipe dream.
Burla can scale any workload with a single function.
Easily fan Python in/out across thousands of machines with varying sizes, types, and environments.
Quickly develop pipelines that handle 100+ TB datasets, using simple code anyone can understand.
This code:
remote_parallel_map(process, [...], image="rocker/geospatial:latest") remote_parallel_map(aggregate, [...], func_cpu=64) remote_parallel_map(predict, [...], func_gpu="A100")
Creates a pipeline like:
.png)
With Burla, the same jobs use 50% less compute.
Compared to software like Ray, Dask, or AWS Batch workloads running on Burla require less compute and automatically stay at 90%+ CPU/RAM utilization without taking any longer to finish the job.
This is achieved with adaptive concurrency and horizontal autoscaling. Burla quickly reacts to changes in task resource utilization, and rearranges work during runtime to fill excess capacity.
.png)
This system frequently more than doubles compute efficiency, and eliminates out of memory errors.
Read our blog to learn how it works.
How it works:
Running code in the cloud shouldn't feel any different from running code locally.
return_values = remote_parallel_map(my_function, my_inputs)
When a Python function is run using remote_parallel_map, it runs in the cloud but:
- Anything it prints appears locally (and inside the dashboard).
- Any exceptions are thrown locally.
- Any packages or local modules are (very quickly) cloned on all remote machines.
- Code starts running in under one second! Even with millions of inputs, or thousands of machines.
Burla automatically manages it's own pool of VMs underneath to maximize speed and efficiency.
You can manually add & remove machines from the pool, or let the platform react live to requests.
Everything you need to manage Python at scale.
Monitor your analysis, pipeline, or background job from your phone.
Burla has all the features you need to closely manage logs, output files, and available compute.