
It is well known that data transfer fees in the cloud are a massive contributor to Kafka’s cost footprint. This alone has motivated the proliferation of new diskless architectures including Warpstream, Confluent Freight, StreamNative Ursa, RedPanda Cloud Topics, Bufstream, Tansu, Kafscale and last but definitely not least - OSS Kafka adopting this architecture soon via KIP-1150 Diskless Kafka.
The key selling point1 of this architecture is it eliminates cross-zone replication costs.
What if I told you you could shave off the equivalent of your replication’s cost bill with 1/10th the effort, disruption and risk?
Aligning consumer fetch traffic to go through the same zone can slash your Kafka cluster cost by 50%. Two KIPs (KIP-392 and KIP-881), help achieve this. Both features require minimal effort to set up and carry virtually no risk.
Beware, though, a major gotcha in cloud networking is that public IP usage in the same zone is charged as if it is cross-zone traffic.
Let us lay the foundations for this article by quickly revisiting the regular traffic flows that your Kafka cluster will experience.
A simple conventional2 Kafka cluster will experience the following cross-zone data flows:
2/3rds of the clients’ (producer/consumer) traffic will be served by a broker in another zone.
all replication traffic will cross zones
your (RF=3) replication traffic will be equal to 2x your producer traffic
Let’s imagine a sample small-scale3, 5x fanout4 throughput of 10 MB/s writes and 50 MB/s reads:
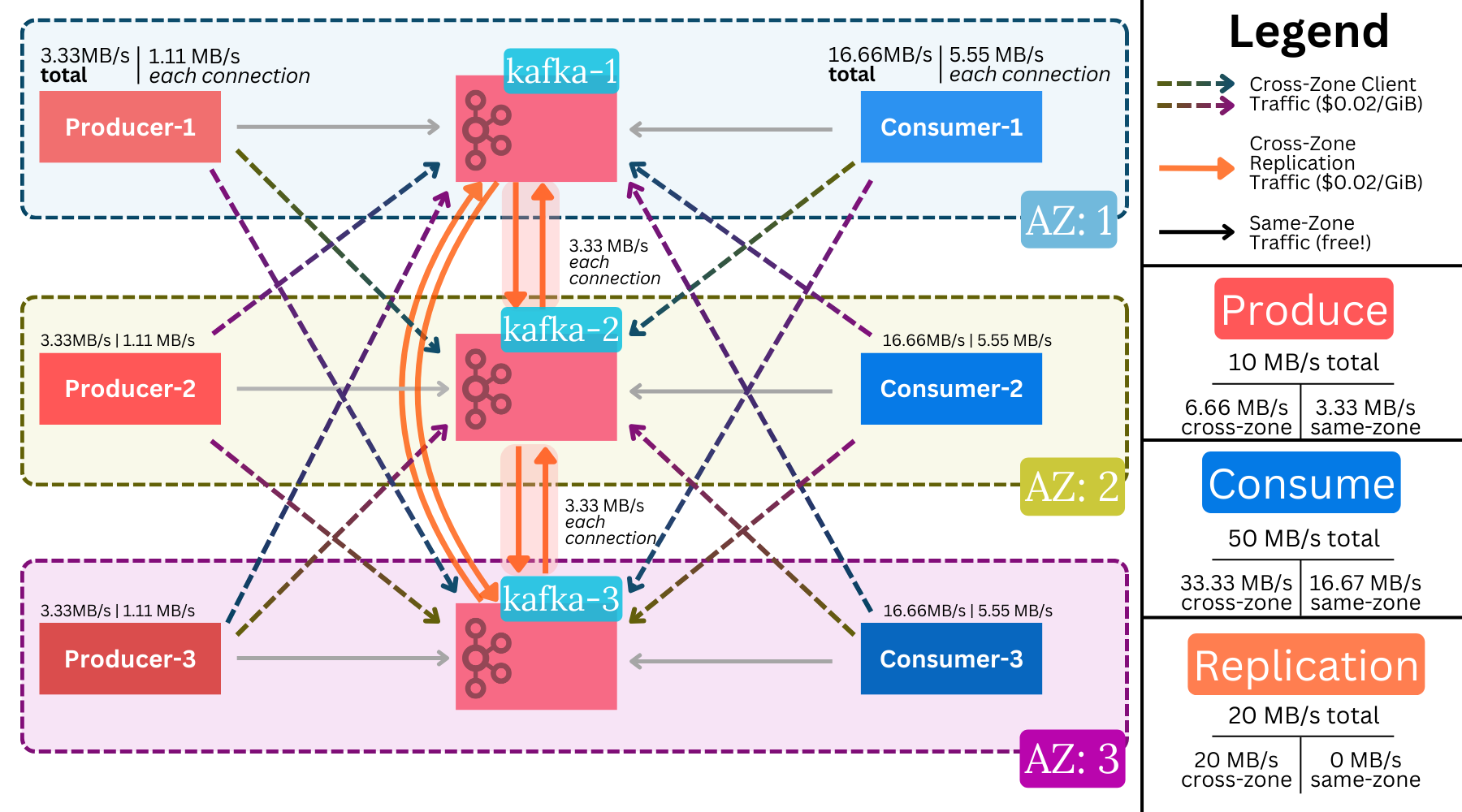
Such a workload will rack up the following networking costs in AWS, priced at $0.02 per GiB5:
16.72 TiB of cross-zone producer write traffic a month6
17121 GiB - $342 a month
$4.1k a year
50.15 TiB of cross-zone replication traffic a month
51354 GiB - $1027 a month
$12.3k a year
83.58 TiB of cross-zone consumer read traffic a month
85586 GiB - $1712 a month
$20.5k a year
Giving this hypothetical workload, a total of $36.9k will go toward data transfer fees perevery year.
What stands out is the consumption cost! At $20.5k, it is more than both the replication and producer combined ($20.5k vs $16.4k).
Here is a chart which portrays the share of total network traffic cost attributable to consumers at different fanout ratios:
The whole point of running Kafka is to have read fanout - multiple consumers reading the same stream.
This aspect, however, turns out to be the most expensive part of it. It does not have to be.
There are two dead-easy ways to completely eliminate this $20.5k cost.
KIP-392, commonly referred to as Fetch From Follower, is an old (2019) Kafka change that allows consumer clients to read from follower brokers.
Previously, a Consumer could only read from the broker that was the partition leader. There was no fundamental reason for this limitation to exist:
Consumers are only ever allowed to see data that is below the high watermark offset. Any record below the high watermark is guaranteed to be replicated across all in-sync followers. The data is therefore guaranteed to be available on any in-sync followers, so it’s not like the leader is serving something others don’t have.
The log is append-only meaning that the data stays final once it’s been replicated (again, the high watermark). There is no risk that some change in the data leads to stale reads.
The Kafka community figured this out and modified the protocol to allow consumption from follower replicas. It works in a very simple way: the consumer clients are extended to define their AZ via the client.rack property. Clients then send this rack metadata in the fetch requests.
Kafka administrators enable KIP-392 by configuring a replica.selector.class on the brokers. The built-in rack selector picks a broker in the same consumer AZ and tells the consumer to send the request there instead. The consumer then connects to that other broker in the same AZ and begins fetching.
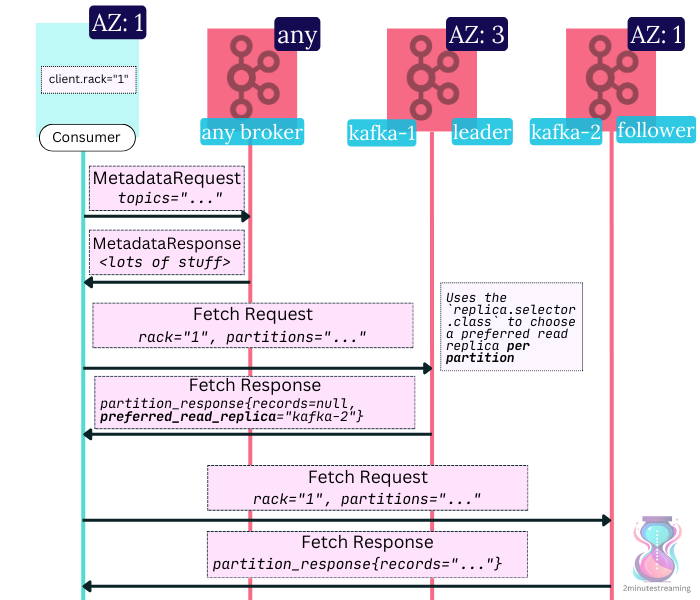
KIP-392 is not a silver bullet. There are two cases where it may fall short:
Broker workload is relatively easy to balance when you assume that consumer clients only connect to leader replicas. Simply spread the leaders evenly across brokers, and it should all balance itself out. Enabling KIP-392 and redirecting consumers to follower brokers throws a wrench in that assumption.
This leader to follower switch happens on the first fetch request. Prior to the consumer sending that first fetch, its consumer group goes through a whole protocol dance7 in order to assign a particular set of partitions to that consumer client. This assignment is configurable, but the default settings opt for a uniform assignment. A uniform assignment simply means that every consumer should have a roughly even number of partitions assigned to them (for balancing purposes). This is a good heuristic for balancing against the client’s exhaustible resources (memory, CPU, disk), but not necessarily against the brokers’ exhaustible resources.
Broker load would only be balanced if we assume that partitions’ leader replicas are evenly distributed across brokers, which they usually are. That way clients (in aggregate) would push uniform throughput to brokers too. This assumption is practically useless if consumers redirect themselves to follower replicas via KIP-392.
The consumer may have been assigned partition leader replica X on broker Y due to broker load distribution concerns, but the out-of-band KIP-392 logic may have re-routed the consumer to follower broker Z in order to optimize for locality. The result would be a potential imbalance of broker load, unless followers are also equally balanced.8
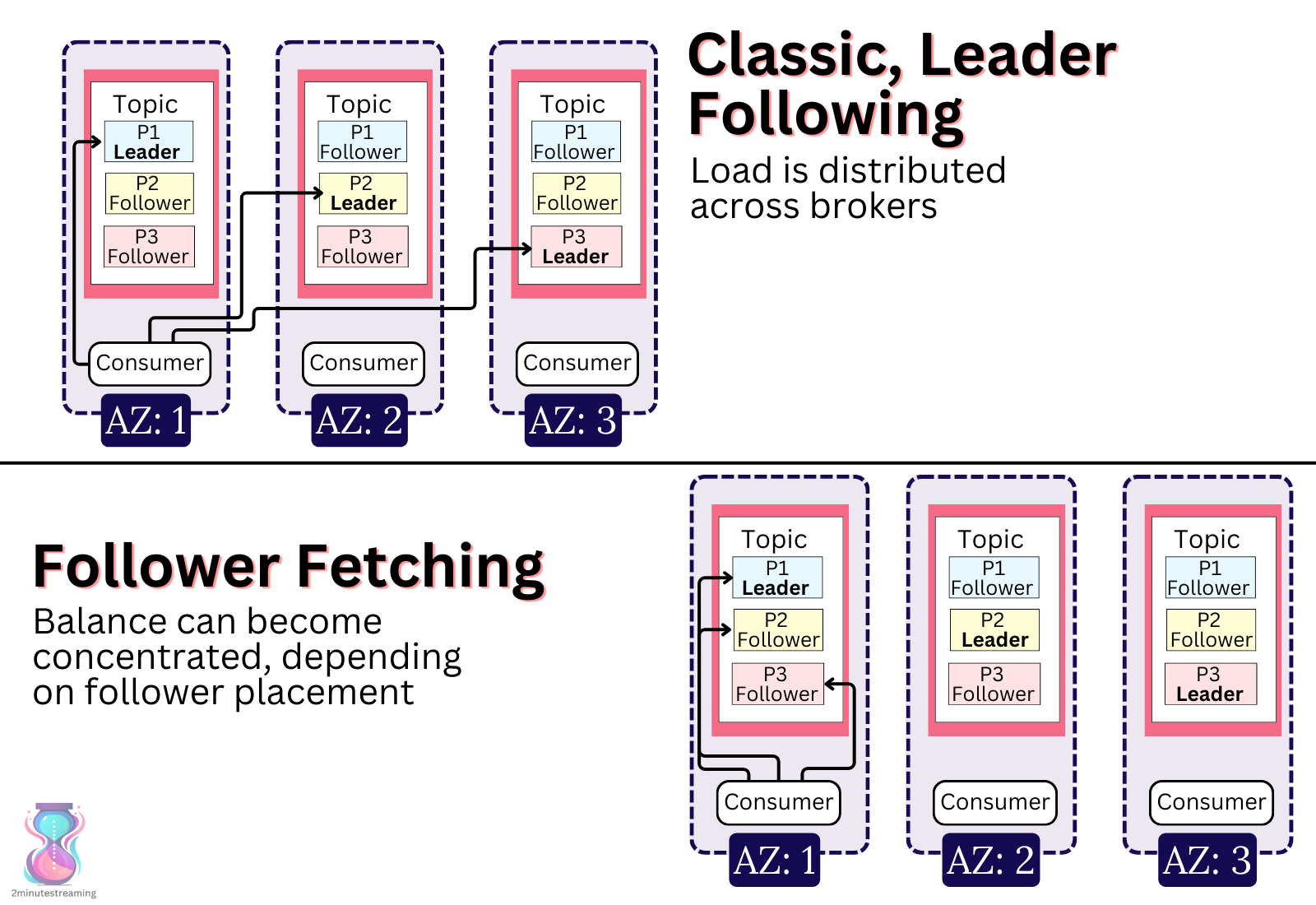
2. Imbalance between RF & AZs
That’s not the only issue. Even if balance is not a concern and consumers are free to read from any broker without concern, there can still be cases where a certain partition can only be accessed through a different Availability Zone.
For example, imagine a Kafka cluster and client set up that is deployed uniformly across 5 AZs. Now imagine some topics in that set up have a replication factor of 3. Every partition will therefore only be hosted in three zones (out of five). This means that for every partition, there would exist a subset of consumer clients that live in two foreign zones. If those consumers are assigned that partition, they would need to cross zones to fetch it.
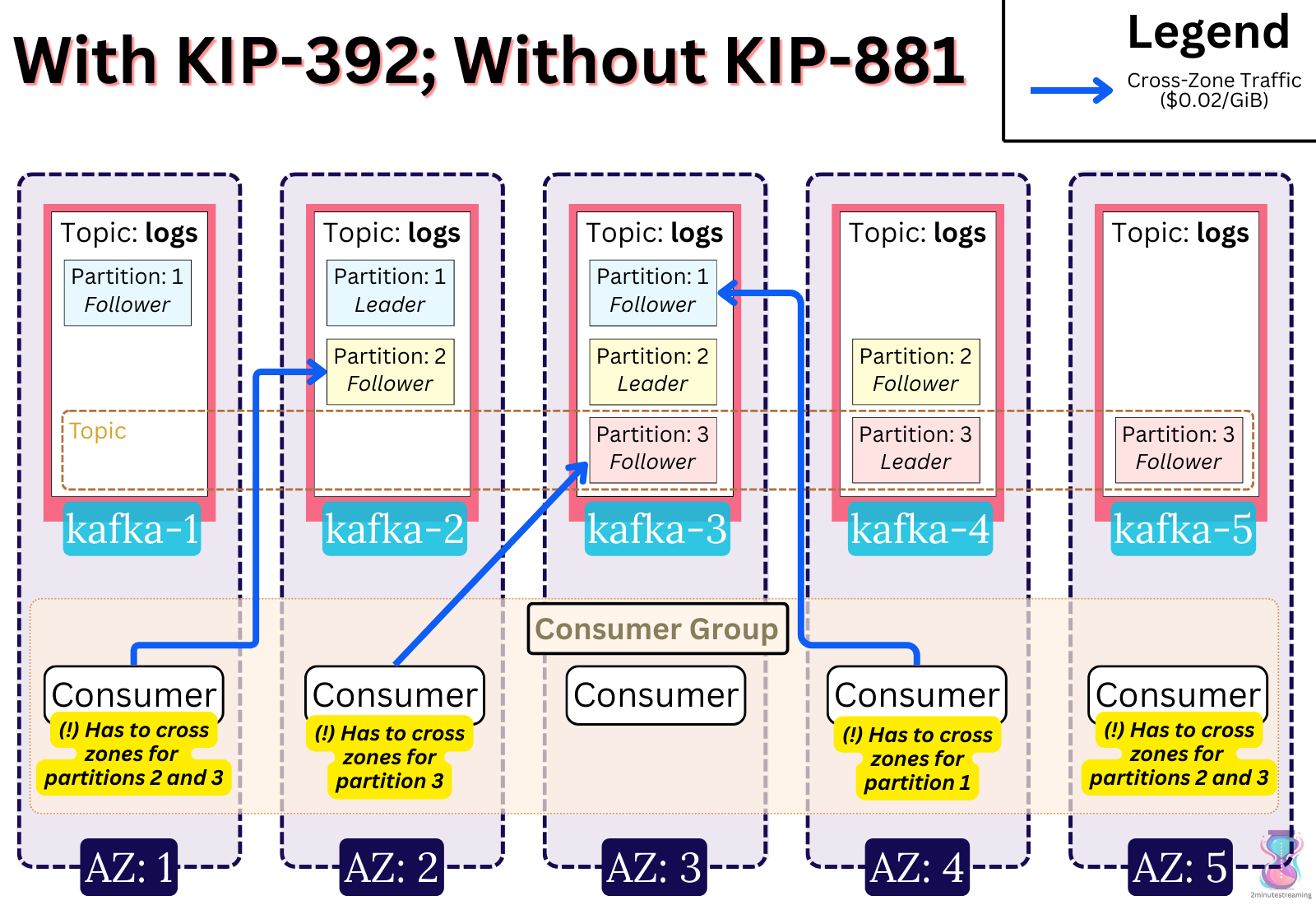
As you can see, in scenarios where there are more AZs than replicas for a partition (NUM_RACK_ID > REPLICATION_FACTOR), even Fetch From Follower cannot fully solve cross-AZ traffic.
The solution?
Surprisingly easy: don’t assign consumers to read from cross-zone partitions.
Assign consumers to local-only partitions. If your consumers and partition leaders are evenly distributed across every zone, it results in a perfect balance!
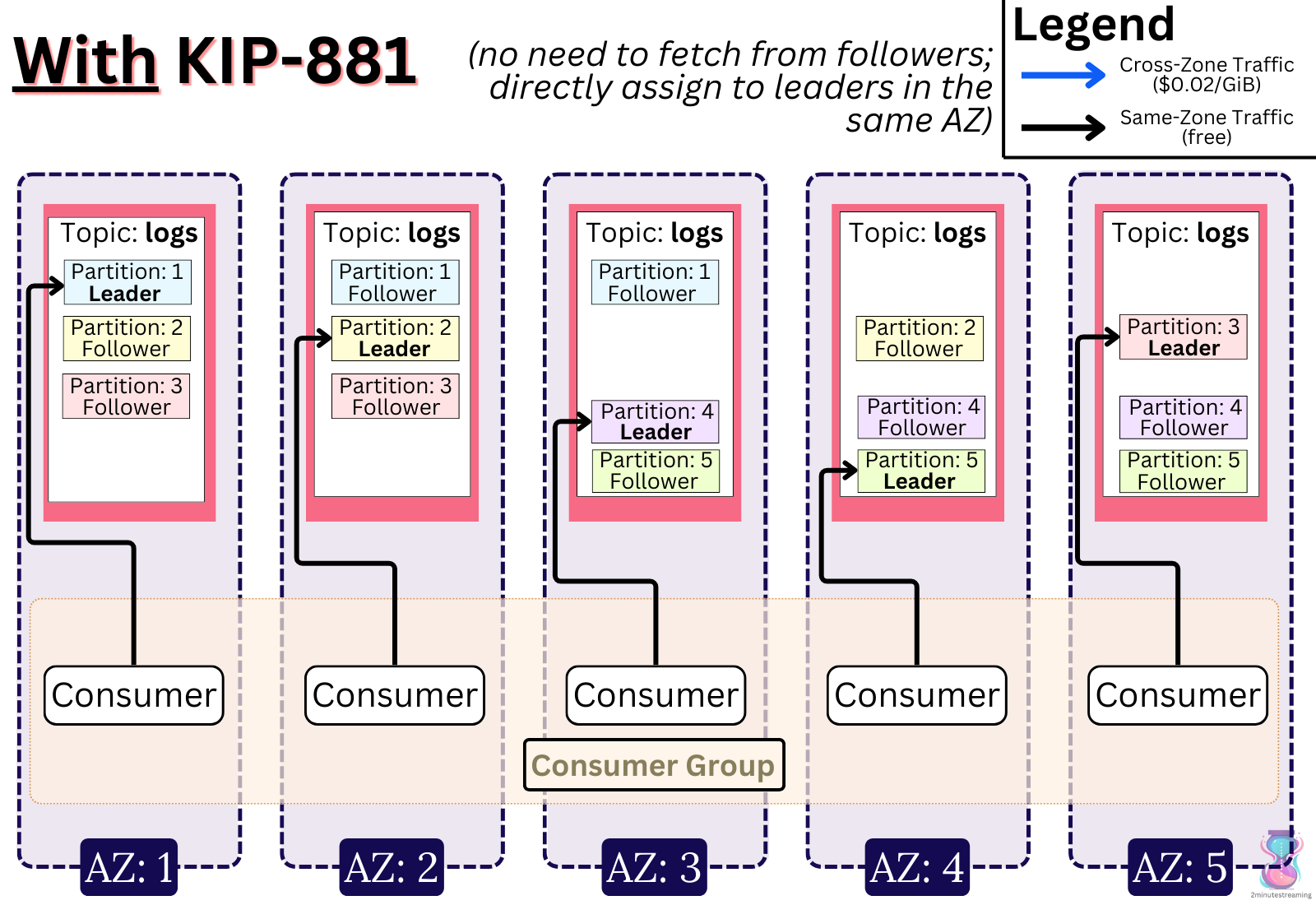
What KIP-881 does to solve this is simple - it propagates the client rack (AZ) information to the pluggable assignor9. This lets the assignor align racks by assigning the right broker (be it follower or leader) to the client in the same AZ. This is a much simpler approach than KIP-392 and achieves the same result!
The current support of KIP-881 is a bit shabby and worth calling out:
In the v1 consumer group protocol, the default assignors are rack-aware and balance racks at secondary priority (the first priority is to balance usage evenly).
In v2, the default assignors do not yet support rack-aware balancing. This is tracked in KAFKA-19387
The takeaway is that if you want to fully ensure your AZ consumption is always in-line via KIP-881, you may need to write your own assignor. Or ask Claude to do it.
In my opinion, this ought to be the default way to align traffic in Apache Kafka. I am surprised we as a community didn’t think of this solution until November 2022 when the KIP was introduced.
It is much simpler and more predictable than KIP-392. It can also all be done on the client-side, which is useful if your managed service provider does not allow you to configure the necessary client-side replica selector for KIP-392.
To enable same-zone fetching, one has to first configure the `client.rack` property on all consumers. Consumers here can (and should) include Connect Workers too. They can often be a large source of unaccounted cross-zone traffic. MirrorMaker2, being a Connect Worker itself, also falls in this category.
Brokers must also be configured with the `broker.rack`, but we assume this is the case already as it’s extremely common.
The rest depends on which KIP you choose to use:
KIP-392: Your brokers must be configured with replica.selector.class=org.apache.kafka.common.replica.RackAwareReplicaSelector and run a minimum Kafka version of 2.4; The rest should “just work”.
KIP-881: Your brokers must run a minimum Kafka version of 3.5; The v1 protocol assignors should then consider racks at a secondary priority. The v2 protocol assignors do not yet support racks. You are free to write your own assignor for either protocol to make use of the racks.
Cloud networking is a complex topic, namely because of the many different combinations of choice. We have three major clouds (AWS, GCP, Azure), two IP types (IPv4, IPv6), two IP scopes (public, private) and a few different routing options (same VPC private IP, VPC peered, Transit Gateway, Private Link, Private Network Interface).
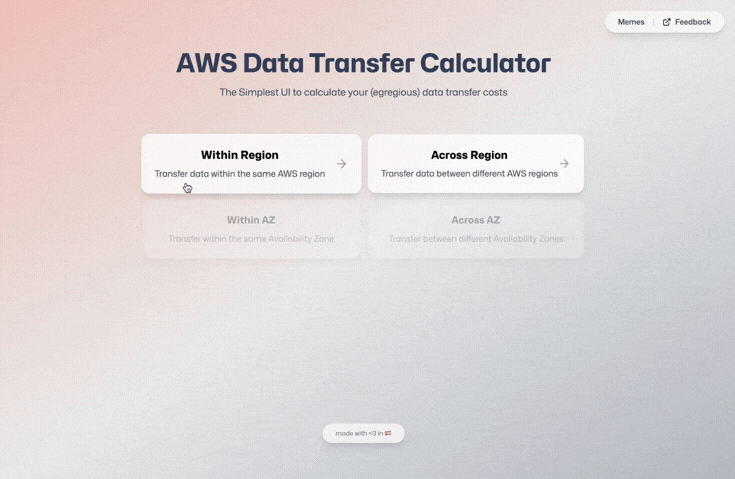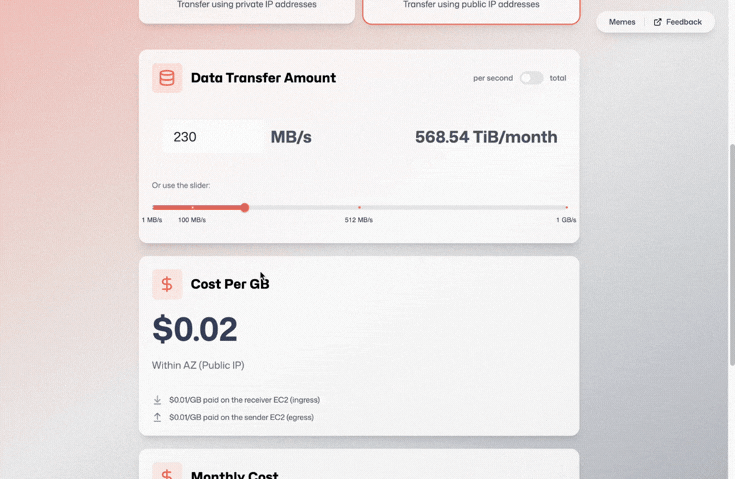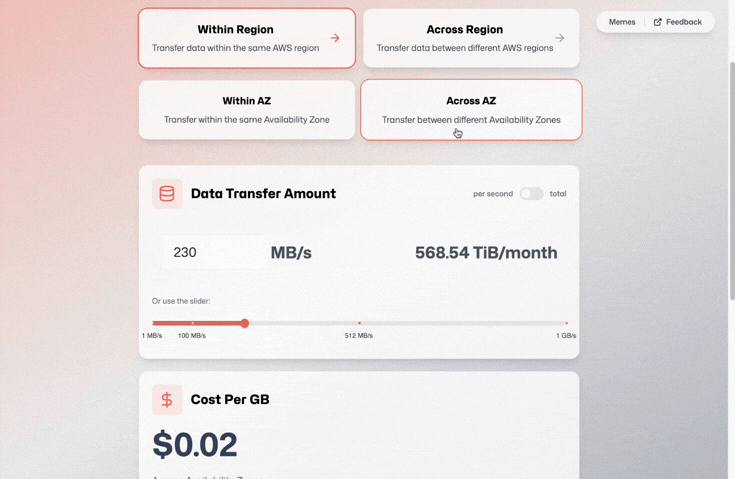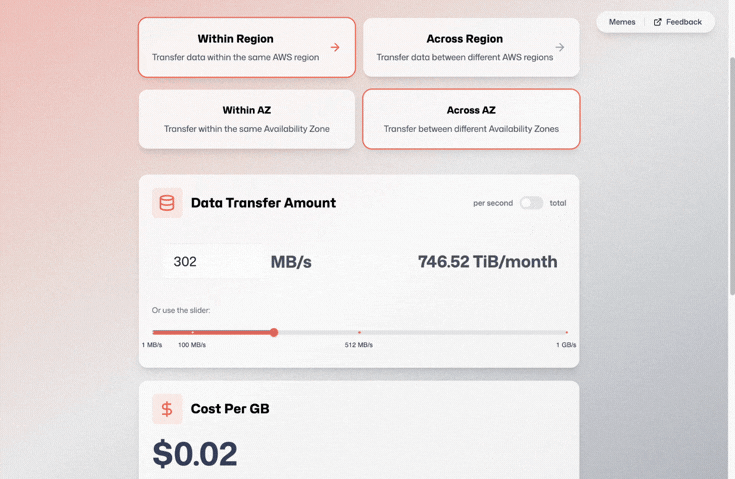
An exhaustive overview would fill a book, but I want to leave you with a simple takeaway from this piece: in AWS, public IPv4 usage in the same zone is charged as if it is cross-zone traffic. For IPv6, cross-VPC connections in the same zone are charged as if they are cross-zone, unless VPC-peered.
The implication therefore is that, if you want to make use of the cost-saving benefits of fetching from the same AZ, you have to fetch through the private IP of the broker. This can be done if the broker and client live in the same VPC (not common), or if they are VPC-peered (more common).
Most other options for accessing the private IP (Private Link, Transit Gateway) cost money in themselves. For more information, see my 2-minute read on AWS networking costs and the little AWS Data Transfer calculator tool I built.
Kafka’s egregious networking costs at relatively low throughput workloads (in select clouds) has prompted the industry to release a bunch of implementations of the new diskless Kafka architecture. What users must remember is that one can get half of the network cost optimization benefit for very little effort by simply aligning consumers to fetch from brokers within their same availability zones.
In this article, we first examined the conventional network traffic flows of a Kafka cluster and how costs rack up. Then, we went over the two different (and complementary!) ways to align consumer traffic within availability zones in Apache Kafka.
Here are the takeaways you should remember from this piece:
In essence, one’s takeaways should be:
Network data transfer costs a lot, and unoptimized consumers make up the majority of it.
Opt for KIP-392 if you want ease of use. It automatically aligns consumer traffic within availability zones by fetching from followers.
Opt for KIP-881 if you have a more complex AZ setup or want finer grained control. It requires more manual work as you may need to write your own assignor, but it should give you much greater control in both aligning traffic and balancing load.
Configure the AZ (racks) on all your consumer clients
Ensure you are using the private IP address when connecting